
Pozycjonowanie zduplikowanych treści: jak sprawdzić, czy nie ma zduplikowanych treści
Opublikowany: 2022-06-14Zduplikowana treść może mieć wpływ na to, które strony pojawią się w wynikach wyszukiwania, i zmarnować budżet indeksowania. Na szczęście istnieją sposoby na zidentyfikowanie zduplikowanych treści i usunięcie ich ze swojej witryny lub indeksu Google, aby zapobiec negatywnemu wpływowi na twoją pozycję w rankingu.
Co to jest zduplikowana treść?
Zduplikowana treść ma miejsce, gdy ta sama treść pojawia się w więcej niż jednej lokalizacji z unikalnym adresem URL.
Treść nie musi być dokładnym odpowiednikiem, aby zarejestrować się jako duplikat — może to być również to, co Google nazywa „wyraźnie podobną”. Ta treść jest zasadniczo „wystarczająco bliska”, aby można ją było uznać za zduplikowaną treść, mimo że niektóre teksty mogą się różnić.
Większość właścicieli witryn ciężko pracuje, aby ich treść była świeża i oryginalna, a mimo to w sieci wciąż jest wiele zduplikowanych treści. Czasami właściciele witryn nawet nie są tego świadomi. Więc jak to się dzieje?
Dlaczego dochodzi do zduplikowanych treści?
Większość zduplikowanych treści w sieci pojawia się z powodu indeksowania takich elementów, jak wersje stron do druku, produkty, które znajdują się na kilku różnych adresach URL lub do których prowadzą linki, oraz fora dyskusyjne, które generują komputerową i uproszczoną wersję mobilną tej samej strony .
Ale to nie jedyne sposoby, w jakie możesz zduplikować zawartość swojej witryny. Oto kilka przykładów na to, jak duplikowanie treści może wystąpić wewnętrznie w Twojej witrynie i zewnętrznie w innych witrynach.
Duplikaty generowane wewnętrznie
Znacznie podobne strony produktów
Czasami może mieć sens celowe tworzenie znacznie podobnych stron, zwłaszcza w e-commerce. Załóżmy na przykład, że sprzedajesz ten sam produkt w dwóch różnych krajach. W takim przypadku możesz wybrać dwie prawie identyczne strony, z wyjątkiem jednej, która może wyświetlać cenę w dolarach amerykańskich, a druga w dolarach kanadyjskich.
Innym przykładem są strony produktów, które wydają się bardzo podobne, ponieważ zawierają ten sam tekst, a jedyne rzeczywiste różnice to inne zdjęcie produktu, nazwa produktu i cena produktu.
Systemy zarządzania treścią
Czasami systemy zarządzania treścią tworzą zduplikowane treści, o których możesz nawet nie wiedzieć. Niektóre systemy automatycznie dodają tagi i parametry adresu URL do wyszukiwania, co skutkuje wieloma ścieżkami do dokładnie tej samej treści.
Odmiany adresów URL
Możesz również otrzymać zduplikowaną treść, jeśli masz różne odmiany adresów URL, które zawierają tę samą treść. Jak wspomniano wcześniej, systemy zarządzania treścią mogą to robić samodzielnie i możesz otrzymać dwie odmiany adresów URL, takie jak https://www.website.com/blog1 i https://www.website.com/blogs/blog1 . Inne odmiany adresów URL, takie jak końcowe ukośniki lub adresy URL pisane wielkimi literami, mogą powodować ten sam problem.
Kiedy tak się dzieje, Google może nie wiedzieć, którą stronę należy umieścić w rankingu, a niektóre źródła zewnętrzne mogą linkować do jednej z tych stron, podczas gdy inne linkują do duplikatu, rozbijając w ten sposób wartość linków Twojej strony.
HTTP vs HTTPS i www vs bez www
Większość witryn jest dostępna z lub bez www lub pod adresami URL HTTP lub HTTPS. Jeśli jednak witryna nie została poprawnie skonfigurowana, Google może indeksować strony z więcej niż jednej z nich, co skutkuje zduplikowaniem treści.
Adresy URL przyjazne dla drukarki i mobilne
Strony przystosowane do drukowania lub przystosowane do urządzeń mobilnych hostowane pod innymi adresami URL niż strona oryginalna spowodują zduplikowanie treści, chyba że zostaną prawidłowo zindeksowane.
Identyfikatory sesji
Identyfikatory sesji mogą być cennymi narzędziami do śledzenia odwiedzających witrynę. Zwykle odbywa się to poprzez dodanie długiego ciągu identyfikatora sesji do adresu URL. Ponieważ każdy identyfikator sesji jest unikalny, tworzy to nowy adres URL i duplikuje treść.
Parametry UTM
Parametry mogą śledzić przychodzących gości z różnych źródeł. Podobnie jak identyfikatory sesji, generują unikalne adresy URL, mimo że zawartość strony jest taka sama, tworząc w ten sposób zduplikowaną treść po zindeksowaniu.
Duplikaty wygenerowane zewnętrznie
Treść syndykowana
Syndykowanie treści do innych witryn w sieci może być świetnym sposobem na zwiększenie ruchu w witrynie i wypromowanie tam swojego imienia. Jednak ta treść może nadal wyświetlać się jako zduplikowana treść, jeśli nie jest sformatowana za pomocą odpowiednich kanonicznych tagów nagłówka. Na przykład używanie znaczników kanonicznych w artykułach Medium może uchronić oryginalną treść przed zarejestrowaniem jako duplikat.
Plagiat
Chociaż większość zduplikowanych treści ma charakter niezłośliwy, niektórzy webmasterzy kopiują treści celowo, próbując czerpać korzyści z treści, których sami nie stworzyli.
Pozycjonowanie zduplikowanych treści: dlaczego to ma znaczenie?
Skoro powielanie treści zdarza się tak często, dlaczego ma to znaczenie? Oto pięć sposobów, w jakie może to wpłynąć na twoją dobrą pozycję w wynikach wyszukiwania.
1. Kara Google za zduplikowanie treści
Google nie karze bezpośrednio duplikatów treści — przez większość czasu. Jeśli Google uzna, że zduplikowana treść w Twojej witrynie jest „zwodnicza” i „ma na celu manipulowanie wynikami wyszukiwania”, może podjąć działania, nakładając karę za powielanie treści. Tak więc, mimo że nie zdarza się to często, zgodnie z wytycznymi Google dotyczącymi duplikatów treści, nadal możesz mieć do czynienia z bezpośrednią karą, jeśli zduplikowana treść jest wystarczająco rażąca i uważa się, że została stworzona w złośliwych zamiarach.
Kara Google za powielanie treści jest rzadka, więc bardziej palącym problemem jest związek między powielonymi treściami a SEO.
2. Rozdęcie indeksu
Nadmiar indeksu ma miejsce, gdy roboty wyszukiwarek uzyskują dostęp i indeksują nieistotne lub niskiej jakości treści — takie jak te strony do drukowania, o których wspomniałem. Ma to wpływ na możliwość ustawienia ważnych stron w rankingu, ponieważ wyszukiwarki nie będą wiedzieć, którą wersję treści sugerować użytkownikom, i mogą oceniać inną wersję niż wolisz. Ma to również wpływ na budżet indeksowania.
3. Budżet indeksowania
Google ogranicza czas, jaki spędza na indeksowaniu witryn. Ilość zasobów udostępnianych przez Google do przeszukiwania i indeksowania Twojej witryny to budżet indeksowania. Gdy masz dużo zduplikowanych treści, ryzykujesz marnowanie budżetu na indeksowanie na stronach, które nie są tak ważne.
4. Kanibalizacja słów kluczowych
Jeśli w rankingu znajduje się więcej niż jedna kopia strony, Twoje strony będą konkurować ze sobą o te same słowa kluczowe i widoczność. Wystarczająco trudno jest konkurować ze wszystkimi innymi, dlaczego utrudniać to, rywalizując również ze sobą?
Ostatecznie nie możesz po prostu zignorować problemów z powielonymi treściami SEO. Jeśli to możliwe, staraj się skonsolidować lub usunąć zduplikowane treści.
5. Zmniejszanie kapitału linków
Załóżmy, że Google decyduje się na uszeregowanie dwóch z Twoich znacznie podobnych stron. Skąd wiedzą, czy przypisać całą wartość treści do jednej strony, czy zamiast tego należy podzielić autorytet, sprawiedliwość linków i zaufanie między obie strony? Taka sytuacja może obniżyć wartość SEO Twoich treści, powodując, że będą one słabsze.
Wartość linków twoich linków zwrotnych zostanie również podzielona między dwie strony w zależności od tego, czy inne witryny zdecydują się na link.
Jak sprawdzić duplikaty treści we własnej witrynie?
Znajdowanie duplikatów treści w Twojej witrynie jest bezpłatne i łatwe. Korzystaj z bezpłatnych wersji Screaming Frog i Siteliner, aby metodycznie indeksować swoją witrynę i identyfikować dokładne lub prawie zduplikowane strony.
Jak korzystać z Screaming Frog, aby odkryć zduplikowane treści?
Screaming Frog to robot indeksujący witryny i narzędzie do audytu SEO, które może pomóc w identyfikacji problemów z duplikacją treści w Twojej witrynie. Oto jak używać Screaming Frog do skanowania do 500 adresów URL za darmo.
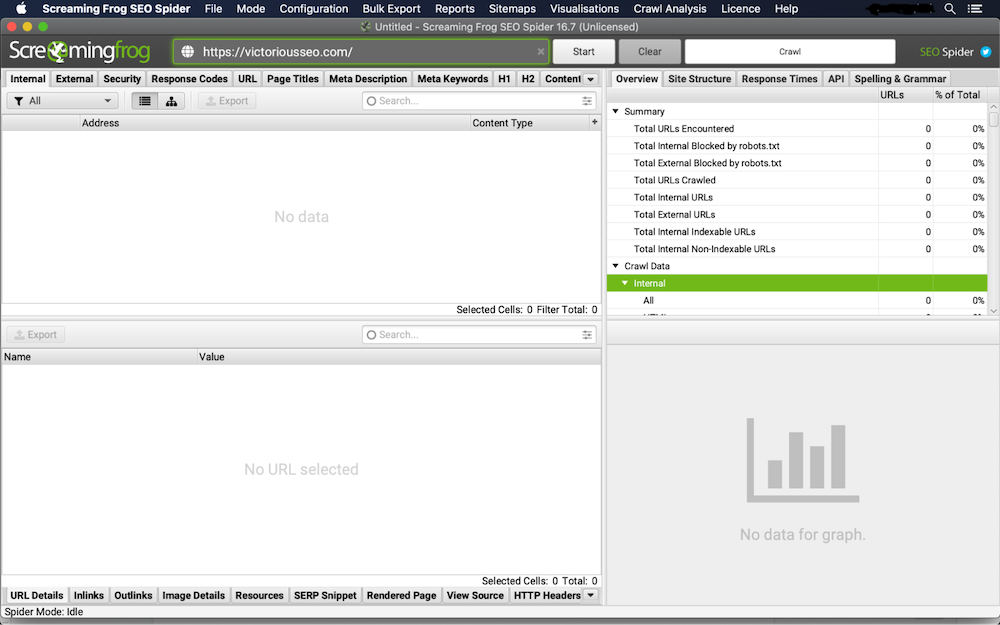
1. Indeksuj swoją witrynę za pomocą SEO Spider
Najpierw pobierz i otwórz Screaming Frog. Wpisz adres URL witryny, którą chcesz zaindeksować w polu „Wprowadź adres URL do Spidera” i kliknij przycisk „Start”.
2. Sprawdź duplikaty w zakładce „Treść”
Kliknij kartę „Treść”, aby sprawdzić dokładne duplikaty i blisko duplikatów. Będziesz mógł zobaczyć dokładne duplikaty w czasie rzeczywistym, ale musisz wykonać „Analizę indeksowania”, aby zobaczyć listę prawie duplikatów.

3. Sprawdź, czy nie ma w pobliżu duplikatów
Kliknij kartę „Analiza indeksowania” na pasku menu i wybierz „Start” z menu rozwijanego.
Po zakończeniu analizy indeksowania zobaczysz wypełnione w pobliżu zduplikowane kolumny. Będziesz wiedział, że to się skończyło, ponieważ pasek postępu „analizy” będzie wskazywał 100%, a filtr prawie zduplikowany nie będzie już wyświetlał komunikatu „wymagana analiza indeksowania”.
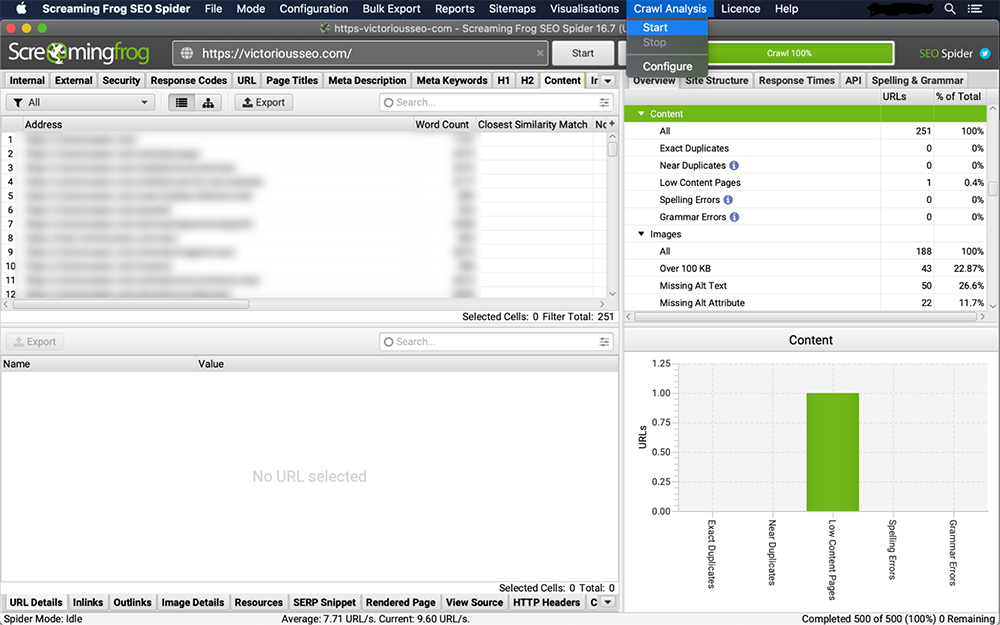
4. Wyświetl duplikaty w zakładce „Treść”
„Najbliższe podobieństwo”, „Nie. Kolumny Blisko duplikatów” i „Adres” zostaną wypełnione po zakończeniu analizy indeksowania.

Filtr „Dokładne duplikaty” wyświetla identyczne strony na podstawie skanu kodu HTML. Ustawiony próg podobieństwa określa, co kwalifikuje się jako „bliskie duplikaty”. Aby zmienić próg, przejdź do 'Config → Spider → Content. Ten próg jest domyślnie ustawiony na 90%, ale możesz go dowolnie zmienić.
Teraz, po zakończeniu skanowania, ręcznie przejrzyj każdą stronę, która pojawia się jako dokładna lub prawie duplikat.
Jak używać Sitelinera do odkrywania zduplikowanych treści
Siteliner to kolejne bezpłatne narzędzie, za pomocą którego możesz przeskanować swoją witrynę (lub dowolną witrynę) w poszukiwaniu duplikatów. Jednak darmowa wersja ograniczy Cię do jednego użycia co 30 dni i ograniczy liczbę wyników do 250 stron. Jeśli potrzebujesz przeprowadzić wiele wyszukiwań lub chcesz zobaczyć więcej wyników, zarejestruj się w wersji premium.
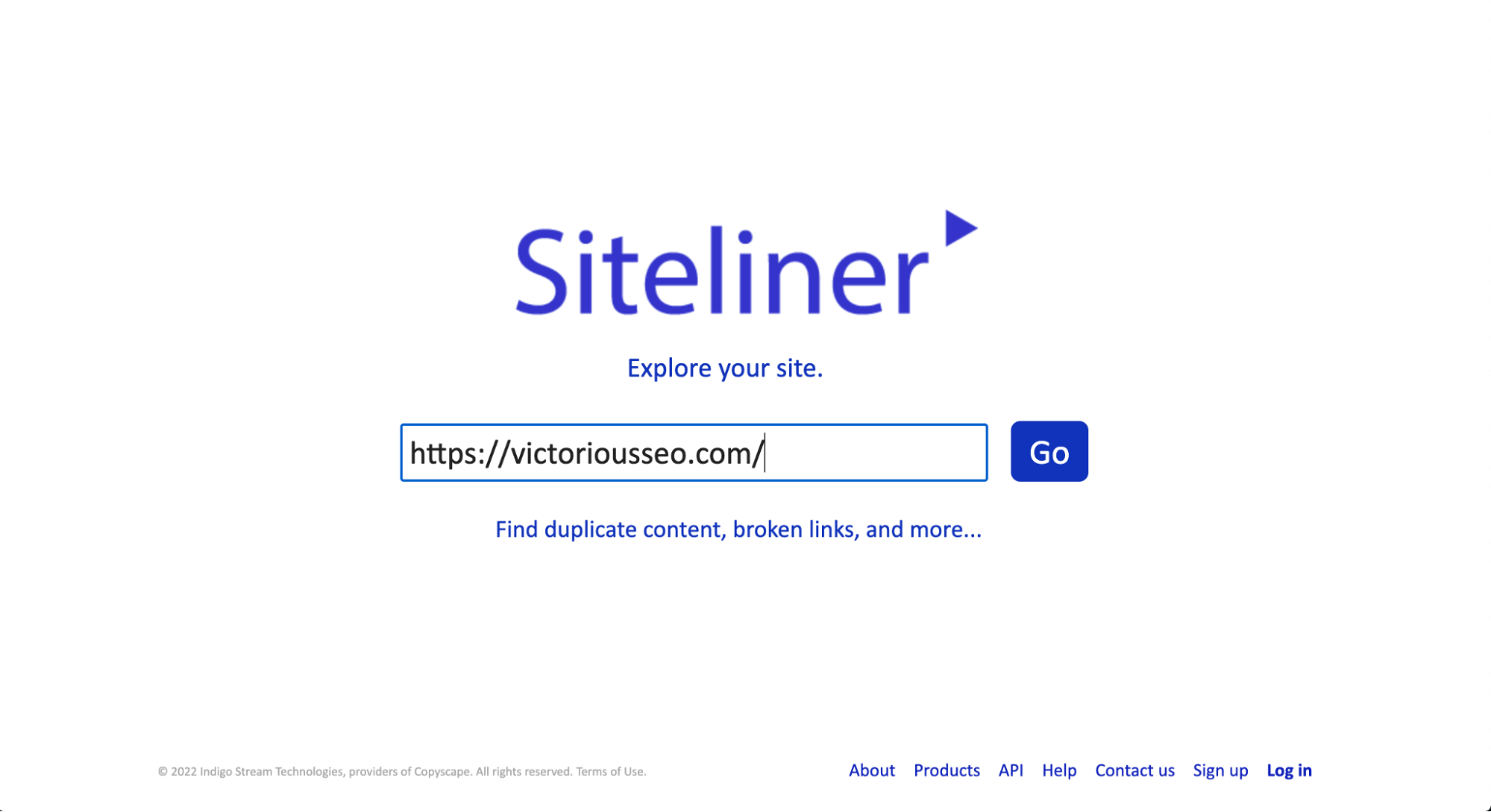
Aby sprawdzić duplikaty treści za pomocą Sitelinera, po prostu wprowadź adres URL, który chcesz wyszukać, w polu wyszukiwania na ich stronie głównej.
Siteliner przeprowadzi następnie przegląd witryny i poinformuje Cię, ile zduplikowanych treści zostało znalezionych i podkreśli, co uważa za najważniejsze problemy. Wyświetli również kilka innych wskaźników, w tym niektóre, które mogą być przydatne dla SEO, takie jak średni czas ładowania strony, linki wewnętrzne i zewnętrzne oraz linki przychodzące.
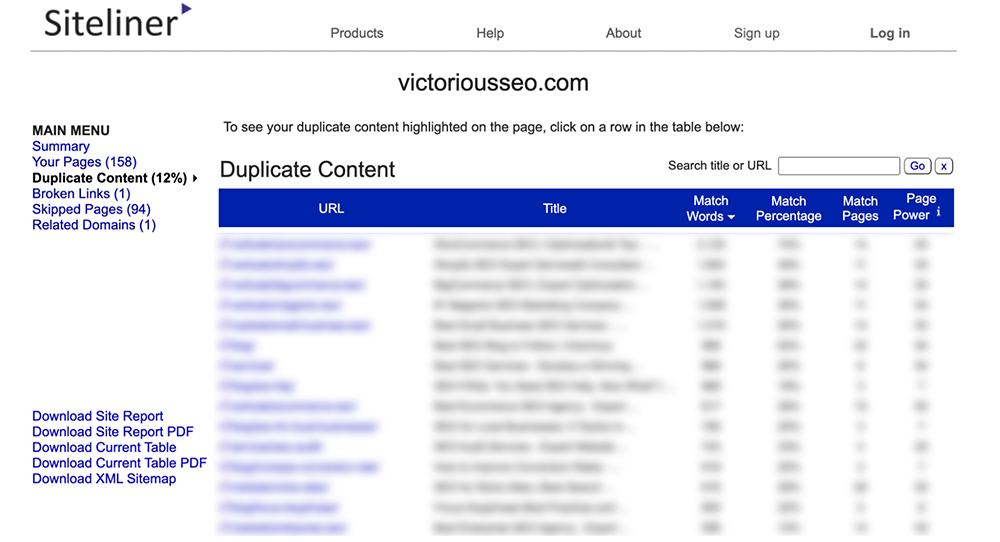
W menu głównym kliknij opcję „Zduplikowana treść”, aby zobaczyć, które strony Linia witryny identyfikuje jako zawierające zduplikowaną treść.
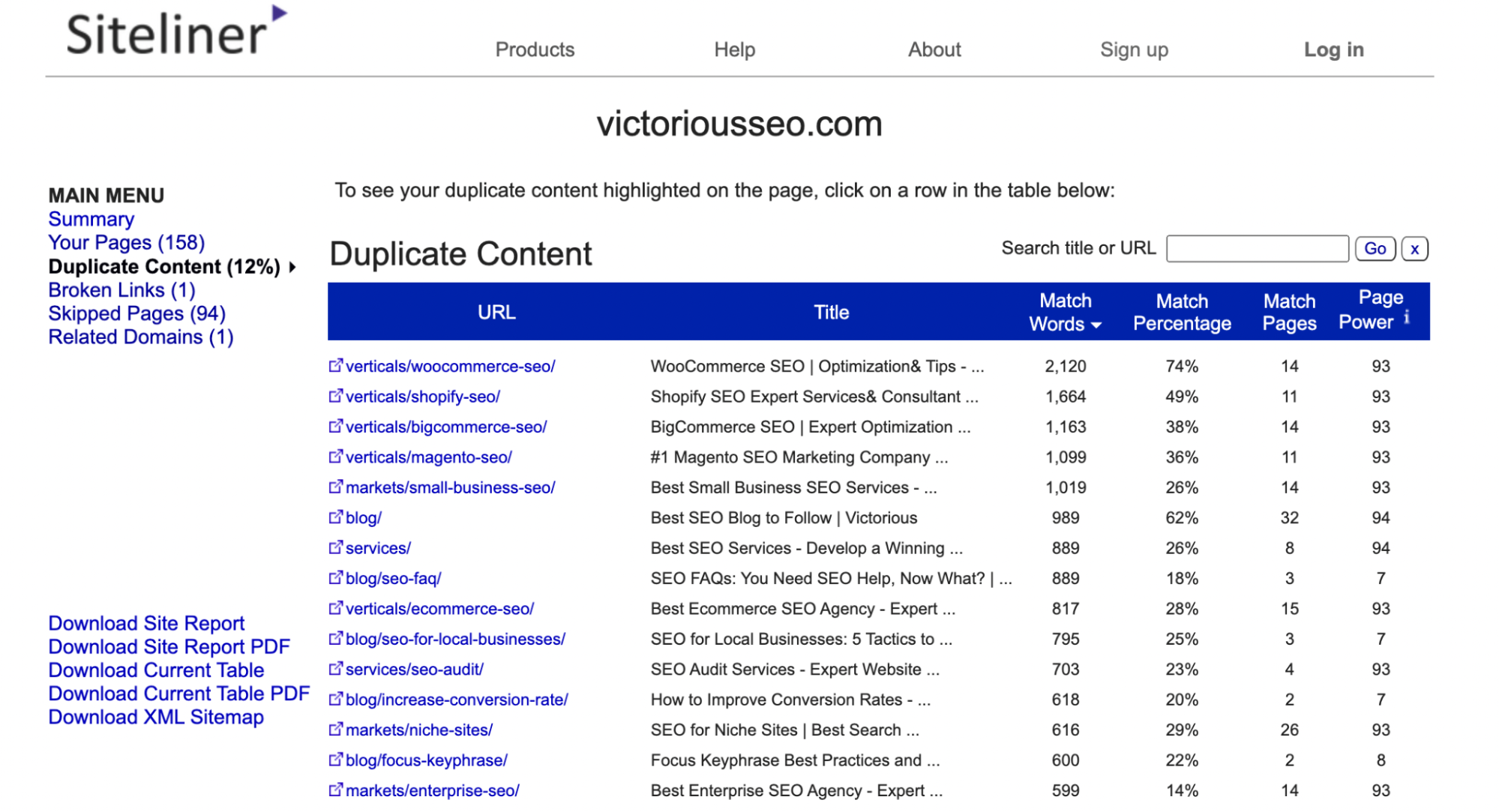
Kliknij poszczególne wiersze, aby zobaczyć, jaki tekst jest oznaczony jako zduplikowany.
Uwaga: linia witryny zidentyfikuje nagłówki i stopki, które pojawiają się na wielu stronach jako zduplikowana treść, więc możesz uzyskać wiele stron o niskim procencie dopasowania, ponieważ każda z nich ma tę samą zawartość menu lub stopki.
Jak sprawdzić, czy ktoś inny skopiował Twoje treści
Istnieją również narzędzia do wyszukiwania zduplikowanych treści, których możesz użyć, aby sprawdzić, czy ktoś inny w sieci skopiował Twoją treść. Copyscape to bezpłatne narzędzie do sprawdzania zawartości witryny, które jest skuteczne i łatwe w użyciu.
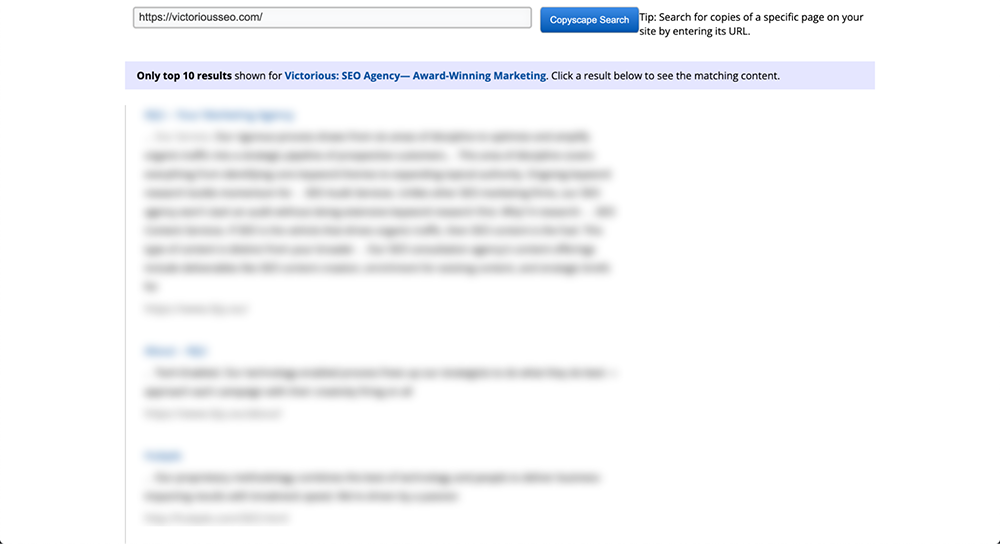
Po prostu wstaw adres URL w polu wyszukiwania i kliknij przycisk „Idź” znajdujący się tuż obok niego. Copyscape przeprowadzi następnie wyszukiwanie w całej sieci, aby sprawdzić, czy podobna treść tekstowa istnieje gdziekolwiek indziej.

Jeśli coś znajdzie, Copyscape zwróci wyniki i uporządkuje je na liście, która wygląda trochę jak wyniki wyszukiwania Google. Dzięki temu możesz łatwo je przewijać i zobaczyć, ile treści zostało skopiowanych. Możesz myśleć o tym trochę jak o sprawdzaniu duplikatów treści Google.
Co możesz zrobić, jeśli zauważysz, że ktoś inny plagiatował Twoje treści?
Najpierw skontaktuj się z właścicielem witryny i poproś go o usunięcie treści lub dodanie linku kanonicznego do oryginalnej treści w Twojej witrynie. Jeśli to nie zadziała, prześlij do Google żądanie usunięcia treści zgodne z ustawą DMCA.
Uwaga: jeśli celowo rozpowszechniasz swoje treści i zezwalasz innym witrynom na ich publikowanie, nadal będą one wyświetlane jako duplikaty. Dlatego ważne jest, aby witryna publikująca zawierała link kanoniczny lub tag noindex na stronie, aby nie konkurowała z własną stroną w rankingach wyszukiwarek.
Jak naprawić zduplikowaną zawartość
Aby rozwiązać problemy ze zduplikowanymi treściami, określ, którą kopię Google ma rozpoznawać jako wersję oryginalną. Musisz także zdecydować, czy chcesz całkowicie usunąć zduplikowane strony, czy po prostu powiedzieć Google, aby ich nie indeksował. W zależności od tego, co zdecydujesz, istnieje kilka różnych sposobów na usunięcie zduplikowanej treści.
Noindex z tagami Meta Robots i Robots.txt
Jednym ze sposobów zminimalizowania wpływu zduplikowanych treści na SEO jest ręczne odindeksowanie wszelkich zduplikowanych stron poprzez modyfikację tagów meta robots. Aby to zrobić, użyj metatagu robots i ustaw jego wartości na „noindex, follow”. Zastosuj ten tag do nagłówka HTML każdej strony, którą chcesz wykluczyć z wyników wyszukiwania.
Metatag robots umożliwia wyszukiwarkom indeksowanie linków na stronie, na której jest stosowany, ale uniemożliwia robotom wyszukiwania uwzględnianie ich w swoich indeksach.
Po co w ogóle pozwalać Google na indeksowanie strony, jeśli nie chcesz jej indeksować? Ponieważ Google wyraźnie ostrzega przed ograniczaniem dostępu do indeksowania wszelkich zduplikowanych treści w Twojej witrynie. Chcą wiedzieć, że tam jest, nawet jeśli nie chcesz, aby go indeksowali.
Tag noindex powinien wyglądać tak po zastosowaniu w kodzie HTML:
<head> [kod] <meta name=”robots” content=”noindex, follow”> [inny kod w razie potrzeby] </head>
Metatag robots to prosty i skuteczny sposób na deindeksowanie zduplikowanych treści i uniknięcie ewentualnych problemów SEO związanych z posiadaniem znacznie podobnych lub dokładnych zduplikowanych stron w Twojej witrynie.
Jeśli masz całe katalogi, których indeksowanie chcesz zablokować Google i innym wyszukiwarkom, edytuj plik robots.txt.
Przekierowania 301
Innym sposobem poradzenia sobie z problemem zduplikowanych treści jest przekierowanie 301. 301 to stałe przekierowania, które przekierowują ruch ze zduplikowanej strony do innego adresu URL. Przekierowania 301 są przyjazne dla SEO i pomagają połączyć wiele stron w jeden adres URL, aby skonsolidować swój kapitał linków.
Gdy używasz przekierowania 301, zduplikowana lub znacznie podobna strona nie będzie już akceptować żadnego ruchu, więc używaj go tylko wtedy, gdy nie masz nic przeciwko, aby zduplikowana strona nie była już dostępna, na przykład podczas przycinania treści. Jeśli nadal chcesz, aby strona była dostępna, użyj metatagu robots, aby ją zindeksować.
Rel kanoniczny
Innym sposobem zarządzania zduplikowaną treścią jest użycie atrybutu rel=canonical do nadawania priorytetów stronom. Umieść atrybut rel=canonical wewnątrz tagu HTML <head>, aby poinformować wyszukiwarki, że dana strona istnieje jako kopia innej strony i że wszystkie linki i moc rankingowa należące do tej strony powinny być przypisane do elementu kanonicznego strona.
Tag rel=canonical wygląda mniej więcej tak po zastosowaniu w kodzie HTML:
<head> [kod] <link href=”URL STRONY Z PRIORYTETEM” rel=”canonical” /> </head>
Możesz także użyć autoreferencyjnego tagu kanonicznego, aby wskazać, że konkretna strona ma być traktowana jako oryginalna wersja.
Usuń adresy URL z mapy witryny XML
Twoja mapa witryny XML powinna zawierać tylko adresy URL, które chcesz zindeksować. Jeśli nie używasz dynamicznego adresu URL, który automatycznie aktualizuje mapę witryny, musisz ręcznie edytować mapę witryny i usunąć wszystkie adresy URL, których nie indeksujesz ani nie przekierujesz.
Usuń adres URL w Google Search Console
Jeśli zdecydujesz się przekierować stronę lub ograniczyć indeksowanie, poproś Google o usunięcie tego adresu URL z indeksu.
Zaloguj się do Google Search Console i wybierz „Usunięcia” z menu po lewej stronie.
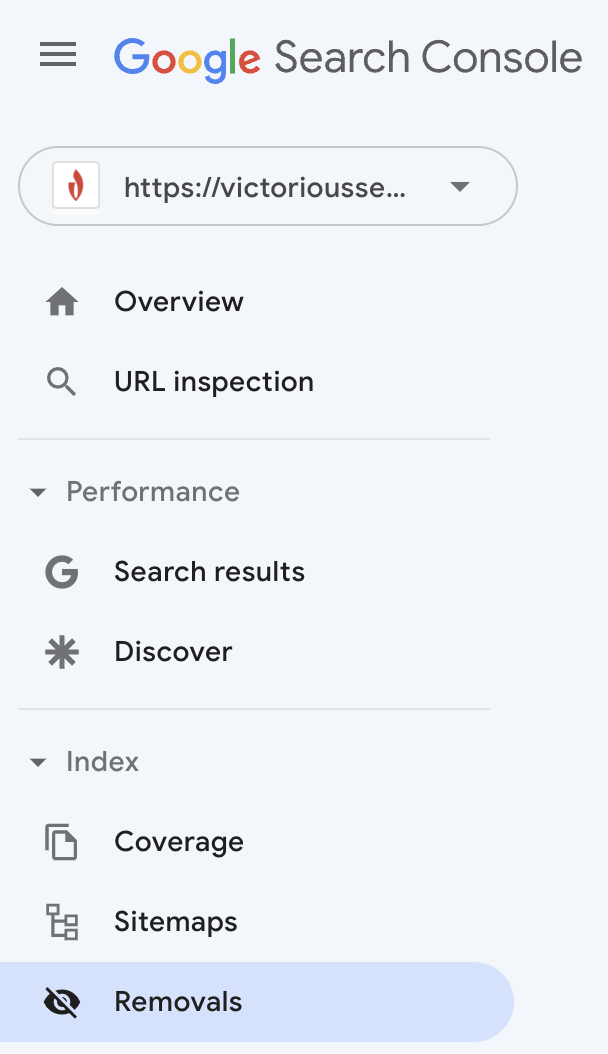
Pojawi się okienko z informacją, że przesłanie adresu URL spowoduje usunięcie go z indeksu Google na zaledwie sześć miesięcy. Po tym czasie, jeśli Google zaindeksuje Twoją witrynę i napotka adres URL, zostanie ona ponownie zindeksowana, chyba że została przekierowana lub zablokowana przez tag robots. Jeśli masz wiele adresów URL, które mają wspólny prefiks, możesz również przesłać prefiks, aby tymczasowo usunąć wszystkie adresy URL z indeksu Google.

Po sześciu miesiącach Google spróbuje ponownie zaindeksować Twoje adresy URL. Jeśli je poprawnie przekierowałeś lub nie zindeksowałeś, nie będą się już pojawiać na stronie wyników wyszukiwania (SERP).
Potrzebujesz pomocy w identyfikacji problemów związanych z SEO?
Chcesz poprawić pozycję swojej witryny w rankingu? Zostań partnerem agencji SEO opartej na danych, która będzie współpracować z Tobą w celu zidentyfikowania technicznych problemów SEO w Twojej witrynie i opracowania zwycięskiej strategii SEO, która pomoże Ci wspiąć się na wyższe poziomy SERP. Zarezerwuj bezpłatną konsultację SEO już dziś i zobacz, co możemy dla Ciebie zrobić!