
SEO de conteúdo duplicado: como verificar se há conteúdo duplicado
Publicados: 2022-06-14Conteúdo duplicado pode afetar quais de suas páginas aparecem nos resultados de pesquisa e desperdiçar seu orçamento de rastreamento. Felizmente, existem maneiras de identificar conteúdo duplicado e removê-lo do seu site ou do índice do Google para evitar que ele afete negativamente sua capacidade de classificação.
O que é conteúdo duplicado?
O conteúdo duplicado ocorre quando o mesmo conteúdo aparece em mais de um local com um URL exclusivo.
O conteúdo não precisa ser uma correspondência exata para ser registrado como duplicado - também pode ser o que o Google chama de "muito semelhante". Esse conteúdo é essencialmente “próximo o suficiente” para ser considerado conteúdo duplicado, mesmo que alguns textos possam ser diferentes.
A maioria dos proprietários de sites trabalha duro para garantir que seu conteúdo seja novo e original, mas ainda há muito conteúdo duplicado na web. Às vezes, os proprietários de sites nem estão cientes disso. Então, como isso acontece?
Por que o conteúdo duplicado acontece?
A maior parte do conteúdo duplicado na Web ocorre devido à indexação de coisas como versões de páginas para impressão, produtos que estão ou estão vinculados por vários URLs diferentes e fóruns de discussão que geram versões para desktop e móveis simplificadas da mesma página .
Mas essas não são as únicas maneiras pelas quais você pode acabar com conteúdo duplicado em seu site. Aqui estão mais alguns exemplos de como o conteúdo duplicado pode ocorrer internamente em seu site e externamente em outros sites.
Duplicatas geradas internamente
Páginas de produtos sensivelmente semelhantes
Às vezes, pode fazer sentido criar intencionalmente páginas sensivelmente semelhantes, especialmente no comércio eletrônico. Por exemplo, suponha que você venda o mesmo produto em dois países diferentes. Nesse caso, você pode optar por ter duas páginas quase idênticas, exceto que uma pode exibir o preço em dólares americanos enquanto a outra exibe em dólares canadenses.
Outro exemplo são as páginas de produtos que parecem consideravelmente semelhantes porque apresentam a mesma cópia, com as únicas diferenças reais sendo uma imagem de produto, nome e preço de produto diferentes.
Sistemas de gerenciamento de conteúdo
Às vezes, os sistemas de gerenciamento de conteúdo criam conteúdo duplicado do qual você pode nem estar ciente. Alguns sistemas adicionam tags e parâmetros de URL para pesquisas automaticamente, resultando em vários caminhos para exatamente o mesmo conteúdo.
Variações de URL
Você também pode acabar com conteúdo duplicado se tiver diferentes variações de URL que apresentam o mesmo conteúdo. Como mencionado anteriormente, os sistemas de gerenciamento de conteúdo podem fazer isso por conta própria, e você pode acabar com duas variações de URL, como https://www.website.com/blog1 e https://www.website.com/blogs/blog1 . Outras variações de URL, como barras à direita ou URLs em maiúsculas, podem causar o mesmo problema.
Quando isso acontece, o Google pode não saber qual página classificar e algumas fontes externas podem vincular a uma dessas páginas, enquanto outras vinculam à duplicata, quebrando o patrimônio do link da sua página no processo.
HTTP vs HTTPS e www vs não-www
A maioria dos sites é acessível com ou sem www ou em URLs HTTP ou HTTPS. No entanto, se você não configurou seu site corretamente, o Google pode indexar páginas de mais de um deles, resultando em conteúdo duplicado.
URLs compatíveis com impressão e dispositivos móveis
Páginas compatíveis com impressão ou dispositivos móveis hospedadas em URLs diferentes da página original resultarão em conteúdo duplicado, a menos que não sejam devidamente indexadas.
IDs de sessão
Os IDs de sessão podem ser ferramentas valiosas para acompanhar os visitantes que acessam seu site. Isso geralmente é feito adicionando uma string de ID de sessão longa ao URL. Como cada ID de sessão é exclusivo, isso cria um novo URL e duplica seu conteúdo.
Parâmetros UTM
Os parâmetros podem rastrear visitantes de várias origens. Como os IDs de sessão, eles geram URLs exclusivos, embora o conteúdo da página seja o mesmo, criando assim conteúdo duplicado se indexado.
Duplicatas geradas externamente
Conteúdo sindicado
Distribuir seu conteúdo para outros sites na web pode ser uma ótima maneira de direcionar mais tráfego para seu site e divulgar seu nome. No entanto, esse conteúdo ainda pode aparecer como conteúdo duplicado se não for formatado com as tags de cabeçalho canônicas adequadas. Por exemplo, usar tags canônicas em artigos do Medium pode proteger seu conteúdo original de ser registrado como duplicado.
Plágio
Embora a maior parte do conteúdo duplicado não seja de natureza maliciosa, alguns webmasters copiam o conteúdo deliberadamente, buscando se beneficiar do conteúdo que eles mesmos não produziram.
SEO de conteúdo duplicado: por que é importante?
Se o conteúdo duplicado acontece com tanta frequência, por que isso importa? Aqui estão cinco maneiras pelas quais isso pode afetar sua capacidade de classificar bem nos resultados de pesquisa.
1. Penalidade de conteúdo duplicado do Google
O Google não penaliza diretamente o conteúdo duplicado — na maioria das vezes. Se o Google acreditar que o conteúdo duplicado em seu site é “enganoso” e “destinado a manipular os resultados do mecanismo de pesquisa”, ele poderá tomar uma ação aplicando uma penalidade de conteúdo duplicado. Portanto, mesmo que isso não aconteça com frequência, de acordo com as diretrizes de conteúdo duplicado do Google, você ainda pode acabar lidando com uma penalidade direta se o conteúdo duplicado for notório o suficiente e acredita-se que tenha sido criado com intenção maliciosa.
Uma penalidade do Google por conteúdo duplicado é rara, então a preocupação mais premente é a relação entre conteúdo duplicado e SEO.
2. Inchaço do Índice
O inchaço do índice acontece quando os rastreadores dos mecanismos de pesquisa acessam e indexam conteúdo sem importância ou de baixa qualidade - como as páginas amigáveis para impressão que mencionei. Isso afeta sua capacidade de classificar suas páginas importantes, pois os mecanismos de pesquisa não saberão qual versão do seu conteúdo sugerir aos usuários e podem classificar uma versão diferente da que você preferiria. Isso também afeta o orçamento de rastreamento.
3. Rastrear orçamento
O Google limita quanto tempo gasta rastreando sites. A quantidade de recursos que o Google fornece para rastrear e indexar seu site é seu orçamento de rastreamento. Quando você tem muito conteúdo duplicado, corre o risco de desperdiçar seu orçamento de rastreamento em páginas que não são tão importantes.
4. Canibalização de palavras-chave
Se mais de uma cópia de uma página estiver classificada, suas páginas competirão entre si pelas mesmas palavras-chave e visibilidade. Já é difícil competir com todos os outros, por que tornar mais difícil competindo com você também?
Em última análise, você não pode simplesmente ignorar os problemas de conteúdo duplicado de SEO. Sempre que possível, tente consolidar ou remover conteúdo duplicado.
5. Equidade de Link Decrescente
Digamos que o Google decida classificar duas de suas páginas sensivelmente semelhantes. Como eles sabem se devem atribuir todo o valor do conteúdo a uma página ou se a autoridade, o valor do link e a confiança devem ser divididos entre as duas páginas? Essa situação pode reduzir o valor de SEO do seu conteúdo, fazendo com que ele tenha um desempenho inferior.
O valor do link de seus backlinks também será dividido entre as duas páginas, dependendo se outros sites optarem por vincular.
Como verificar se há conteúdo duplicado em seu próprio site
Encontrar conteúdo duplicado em seu site é gratuito e fácil. Use versões gratuitas do Screaming Frog e Siteliner para rastrear metodicamente seu site e identificar páginas exatas ou quase duplicadas.
Como usar o Screaming Frog para descobrir conteúdo duplicado
O Screaming Frog é um rastreador de sites e uma ferramenta de auditoria de SEO que pode ajudá-lo a identificar problemas de conteúdo duplicado em seu site. Veja como usar o Screaming Frog para escanear até 500 URLs gratuitamente.
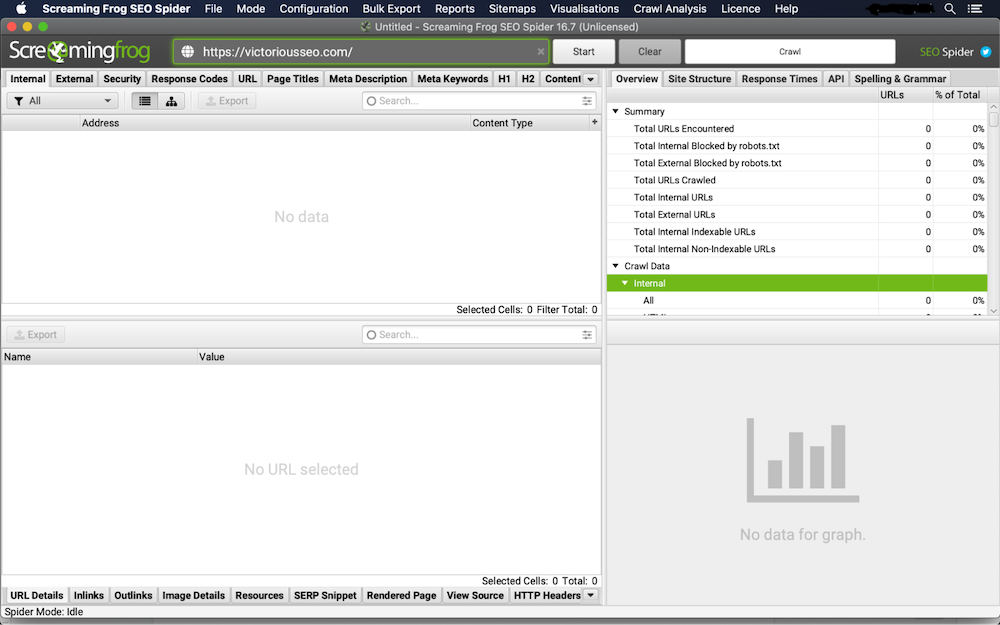
1. Rastreie seu site com SEO Spider
Primeiro, baixe e abra o Screaming Frog. Digite o URL do site que você deseja rastrear no campo 'Enter URL to Spider' e clique em 'Iniciar'.
2. Verifique se há duplicatas na guia "Conteúdo"
Clique na guia 'Conteúdo' para verificar duplicatas exatas e quase duplicadas. Você poderá ver duplicatas exatas em tempo real, mas precisará realizar uma 'Análise de rastreamento' para ver a lista de duplicatas próximas.

3. Verifique se há quase duplicatas
Clique na guia 'Análise de rastreamento' na barra de menu e escolha 'Iniciar' no menu suspenso.
Quando a análise de rastreamento for concluída, você verá as colunas quase duplicadas preenchidas. Você saberá que está concluído porque a barra de progresso da 'análise' mostrará 100% e o filtro quase duplicado não mostrará mais a mensagem 'análise de rastreamento necessária'.
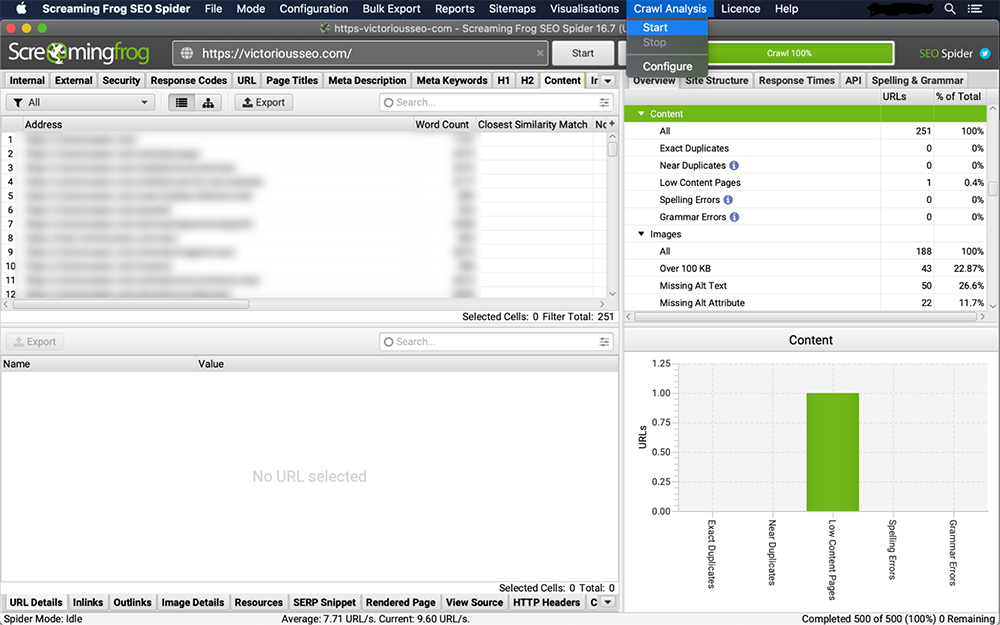
4. Visualize duplicatas na guia 'Conteúdo'
A 'Correspondência de semelhança mais próxima', 'Não. As colunas Near Duplicates' e 'Address' serão preenchidas assim que a análise de rastreamento for concluída.

O filtro 'Duplicações exatas' exibirá páginas idênticas entre si com base em uma verificação de código HTML. O limite de similaridade definido determina o que se qualifica como 'Quase Duplicatas'. Para alterar o limite, vá para 'Config → Spider → Content. Esse limite é definido como 90% por padrão, mas você pode alterá-lo para o que preferir.
Agora que a verificação está concluída, revise manualmente qualquer página que apareça como exata ou quase duplicada.
Como usar o Siteliner para descobrir conteúdo duplicado
O Siteliner é outra ferramenta gratuita que você pode usar para verificar seu site (ou qualquer site) em busca de conteúdo duplicado. No entanto, a versão gratuita limitará você a um uso a cada 30 dias e restringirá o número de resultados a 250 páginas. Se você precisar realizar várias pesquisas ou quiser ver mais resultados, inscreva-se na versão premium.
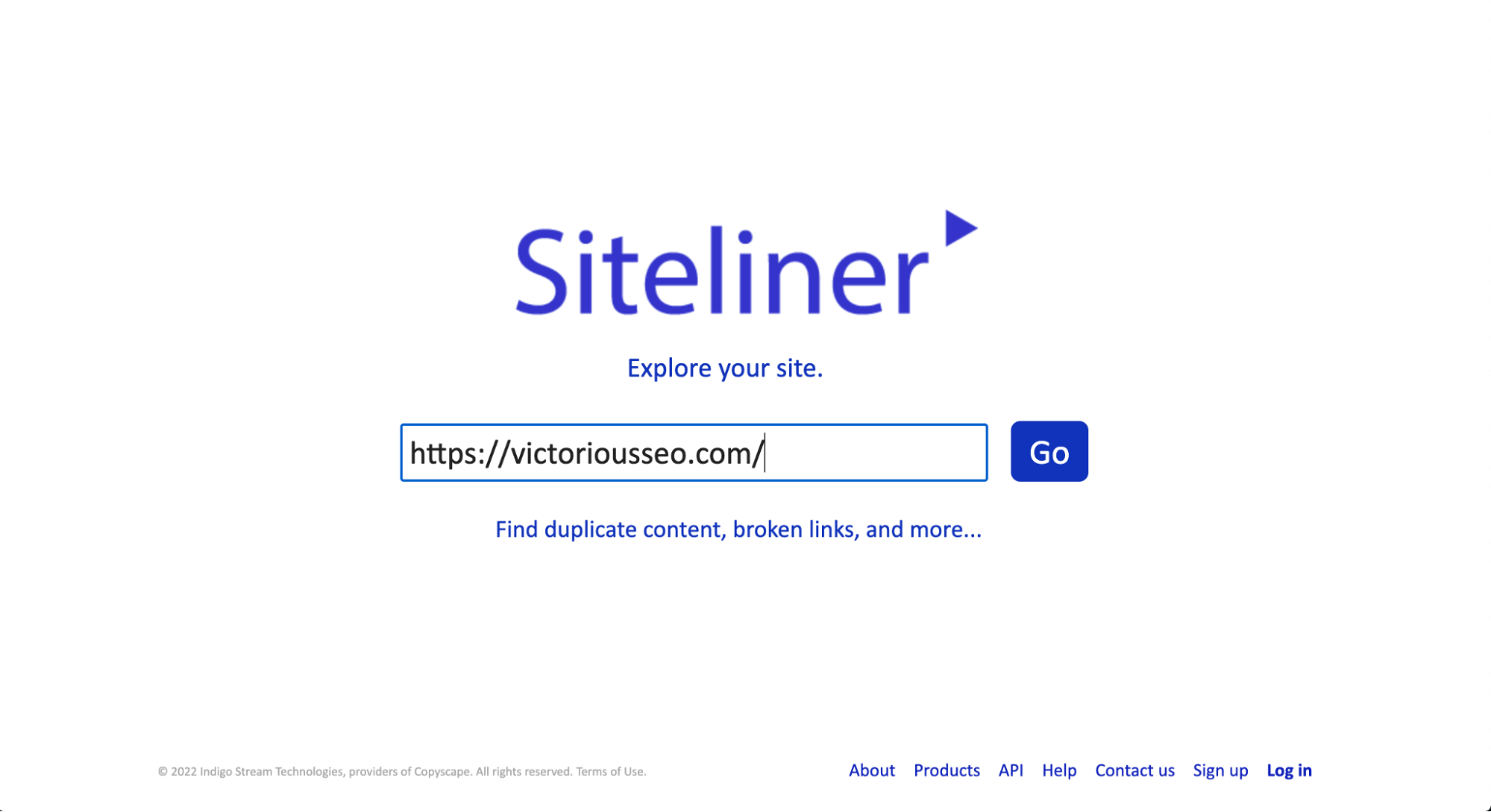
Para verificar se há conteúdo duplicado com o Siteliner, basta inserir o URL que você deseja pesquisar na caixa de pesquisa na página inicial.
O Siteliner fará uma varredura no site e informará quanto conteúdo duplicado foi encontrado e destacará o que ele acredita ser seus principais problemas. Ele também exibirá várias outras métricas, incluindo algumas que podem ser úteis para SEO, como tempo médio de carregamento da página, links internos e externos e links de entrada.
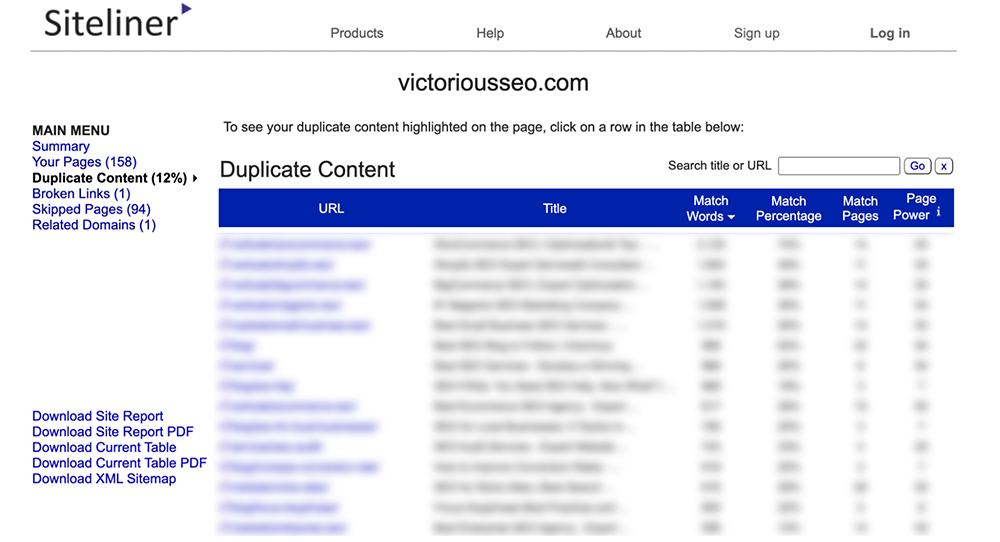
No menu principal, clique em 'Conteúdo duplicado' para ver quais páginas a Siteline identifica como tendo conteúdo duplicado.
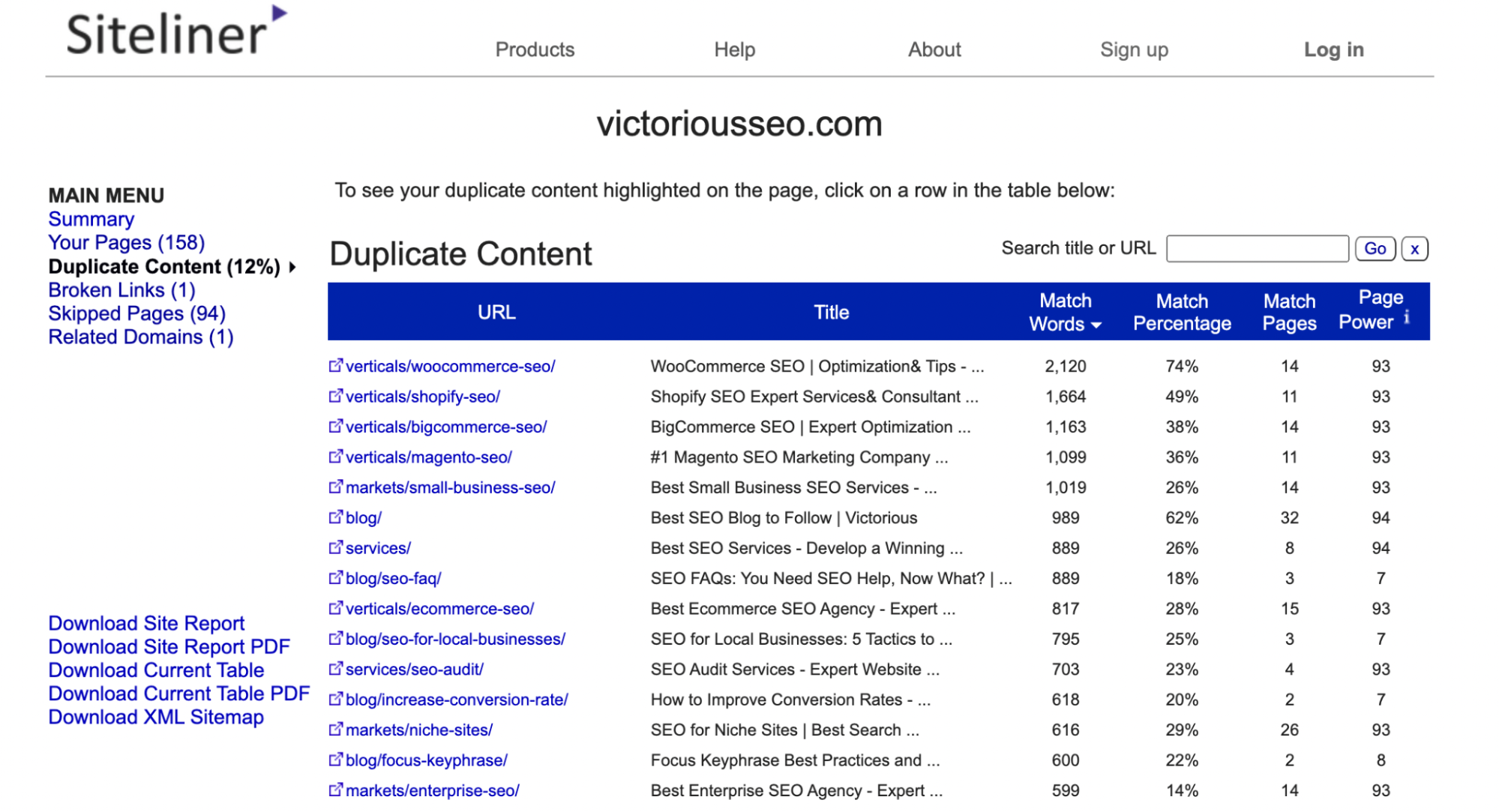
Clique em cada linha individual para ver qual texto está sinalizado como duplicado.
Observação: o siteline identificará cabeçalhos e rodapés que aparecem em várias páginas como conteúdo duplicado, portanto, você pode obter muitas páginas com uma porcentagem de correspondência baixa porque cada uma compartilha o mesmo menu ou conteúdo de rodapé.
Como verificar se outra pessoa copiou seu conteúdo
Também existem ferramentas de pesquisa de conteúdo duplicado que você pode usar para verificar se outra pessoa na Web copiou seu conteúdo. Copyscape é uma ferramenta gratuita de verificação de conteúdo de sites que é eficaz e fácil de usar.
Basta inserir um URL na caixa de pesquisa e clicar no botão 'Ir' ao lado dele. O Copyscape realizará uma pesquisa em toda a web para ver se existe conteúdo de texto semelhante em qualquer outro lugar.

Se encontrar alguma coisa, o Copyscape retornará os resultados e os organizará em uma lista que se parece com os resultados de pesquisa do Google. Isso permite que você navegue facilmente por eles e veja quanto do seu conteúdo foi copiado. Você pode pensar nisso como um verificador de conteúdo duplicado do Google.
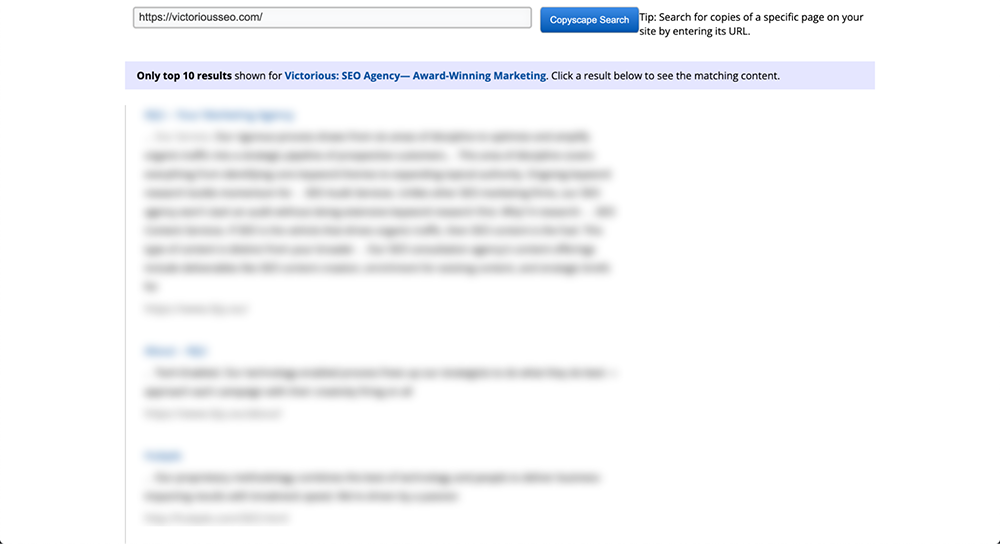
O que você pode fazer se descobrir que outra pessoa plagiou seu conteúdo?
Primeiro, entre em contato com o proprietário do site e peça para remover o conteúdo ou adicionar um link canônico ao conteúdo original em seu site. Se isso não funcionar, envie uma solicitação de remoção de DMCA ao Google.
Observação: se você distribuiu intencionalmente seu conteúdo e permitiu que outros sites o publicassem, ele ainda aparecerá como duplicado. É por isso que é importante exigir que o site de publicação inclua um link canônico ou uma tag noindex na página para evitar que ela concorra com sua própria página nas classificações dos mecanismos de pesquisa.
Como corrigir conteúdo duplicado
Para corrigir problemas de conteúdo duplicado, identifique qual cópia você deseja que o Google reconheça como a versão original. Você também precisará decidir se deseja remover completamente as páginas duplicadas ou se deseja simplesmente dizer ao Google para não indexá-las. Dependendo do que você decidir, existem algumas maneiras diferentes de limpar seu conteúdo duplicado.
Noindex com Meta Robots Tags & Robots.txt
Uma maneira de minimizar o impacto do conteúdo duplicado em seu SEO é desindexar manualmente quaisquer páginas duplicadas modificando suas meta tags de robôs. Para fazer isso, use a tag meta robots e defina seus valores como “noindex, follow”. Aplique essa tag ao cabeçalho HTML de cada página que você deseja excluir dos resultados da pesquisa.
A meta robots tag permite que os mecanismos de pesquisa rastreiem os links na página em que é aplicada, mas impede que os rastreadores de pesquisa os incluam em seus índices.
Por que permitir que o Google rastreie a página se você não quer que ela seja indexada? Porque o Google advertiu explicitamente contra a restrição do acesso de rastreamento a qualquer conteúdo duplicado em seu site. Eles querem saber que está lá, mesmo que você não queira que eles indexem.
Uma tag noindex deve ter esta aparência quando aplicada ao seu código HTML:
<head> [código] <meta name=”robots” content=”noindex, follow”> [outro código se necessário] </head>
A meta robots tag é uma maneira simples e eficaz de desindexar conteúdo duplicado e evitar possíveis problemas de SEO por ter páginas duplicadas sensivelmente semelhantes ou exatas em seu site.
Se você tiver diretórios inteiros que gostaria de bloquear a indexação do Google e de outros mecanismos de pesquisa, edite o arquivo robots.txt.
Redirecionamentos 301
Outra maneira de lidar com um problema de conteúdo duplicado é com um redirecionamento 301. 301s são redirecionamentos permanentes que encaminham o tráfego para fora da página duplicada e para outro URL. Os redirecionamentos 301 são amigáveis para SEO e ajudam você a combinar várias páginas em um único URL para que consolidem o valor do link.
Quando você usa um redirecionamento 301, a página duplicada ou sensivelmente semelhante não aceitará mais tráfego, portanto, use-o apenas quando estiver de acordo com a página duplicada não estar mais acessível, como ao remover conteúdo. Se você ainda quiser que a página seja acessível, use uma meta tag robots para não indexá-la.
Rel Canonical
Outra maneira de gerenciar seu conteúdo duplicado é usar o atributo rel=canonical para priorizar as páginas. Coloque o atributo rel=canonical dentro da tag HTML <head> para informar aos mecanismos de pesquisa que uma página específica existe como uma cópia de outra página e que todos os links e poder de classificação que pertencem a esta página devem ser atribuídos ao canonical página.
Uma tag rel=canonical se parece com isso quando aplicada ao seu código HTML:
<head> [código] <link href=”URL DA PÁGINA PRIORIZADA” rel=”canonical” /> </head>
Você também pode usar uma tag canônica autorreferenciada para indicar que deseja que uma determinada página seja tratada como a versão original.
Remover URLs do seu Sitemap XML
Seu sitemap XML deve incluir apenas URLs que você deseja indexar. Se você não estiver usando um URL dinâmico que atualiza automaticamente o mapa do site, será necessário editar manualmente o mapa do site e remover os URLs que você não indexa ou redireciona.
Remover URL no Google Search Console
Se você optar por redirecionar uma página ou restringir a indexação, solicite que o Google remova esse URL de seu índice.
Faça login no Google Search Console e selecione 'Remoções' no menu à esquerda.
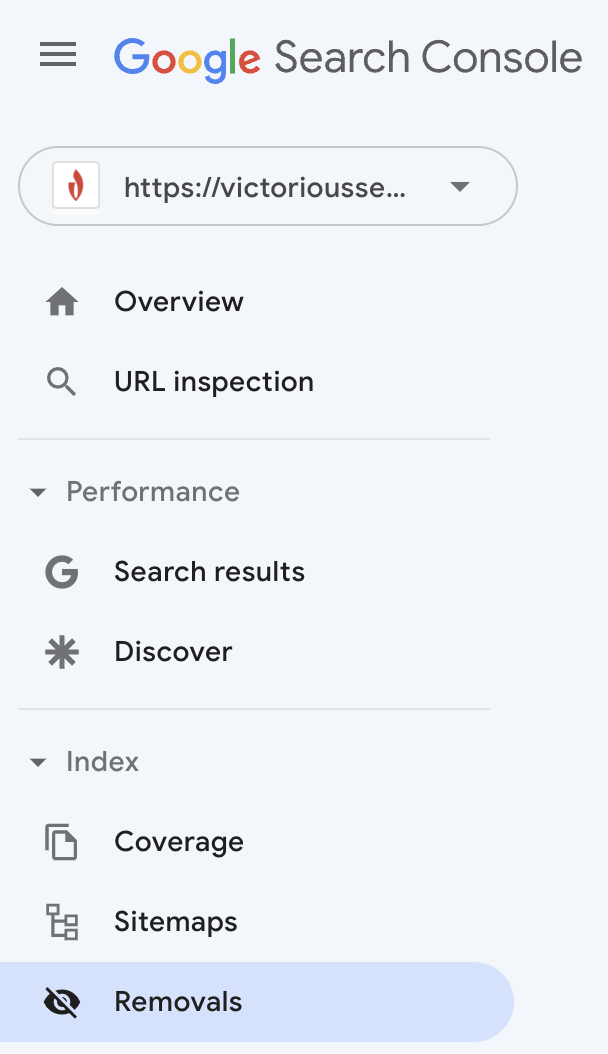
Uma caixa aparecerá informando que o envio de um URL o eliminará do índice do Google por apenas seis meses. Após esse período, se o Google rastrear seu site e encontrar o URL, ele será reindexado, a menos que tenha sido redirecionado ou bloqueado por uma tag robots. Se você tiver vários URLs que compartilham um prefixo, também poderá enviar o prefixo para remover temporariamente todos os URLs do índice do Google.

Após seis meses, o Google tentará rastrear seus URLs novamente. Se você os redirecionou corretamente ou não os indexou, eles não aparecerão mais na página de resultados do mecanismo de pesquisa (SERP).
Precisa de ajuda para identificar problemas de SEO técnico?
Procurando melhorar a capacidade de classificação do seu site? Faça parceria com uma agência de SEO orientada a dados que trabalhará com você para identificar problemas técnicos de SEO em seu site e desenvolver uma estratégia de SEO vencedora para ajudá-lo a subir nas SERPs. Marque uma consulta de SEO gratuita hoje e veja o que podemos fazer por você!