
Duplicate Content SEO: So prüfen Sie auf Duplicate Content
Veröffentlicht: 2022-06-14Doppelte Inhalte können sich darauf auswirken, welche Ihrer Seiten in den Suchergebnissen angezeigt werden, und Ihr Crawl-Budget verschwenden. Glücklicherweise gibt es Möglichkeiten, doppelte Inhalte zu identifizieren und sie entweder von Ihrer Website oder aus dem Google-Index zu entfernen, um zu verhindern, dass sie Ihr Ranking beeinträchtigen.
Was ist doppelter Inhalt?
Duplicate Content tritt auf, wenn derselbe Inhalt an mehr als einem Ort mit einer eindeutigen URL erscheint.
Inhalte müssen nicht exakt übereinstimmen, um als Duplikate registriert zu werden – sie können auch das sein, was Google als „merklich ähnlich“ bezeichnet. Dieser Inhalt ist im Wesentlichen „nahe genug“, um als doppelter Inhalt betrachtet zu werden, auch wenn sich einige Texte unterscheiden können.
Die meisten Website-Eigentümer arbeiten hart daran, sicherzustellen, dass ihre Inhalte frisch und originell sind, und dennoch gibt es immer noch viele doppelte Inhalte im Web. Manchmal sind sich Websitebesitzer dessen nicht einmal bewusst. Wie passiert das?
Warum kommt es zu Duplicate Content?
Die meisten doppelten Inhalte im Web entstehen durch die Indexierung von Dingen wie druckfreundlichen Versionen von Seiten, Produkten, die sich auf mehreren verschiedenen URLs befinden oder mit denen sie verlinkt sind, und Diskussionsforen, die Desktop- und abgespeckte mobile Versionen derselben Seite generieren .
Aber das sind nicht die einzigen Möglichkeiten, wie Sie mit Duplicate Content auf Ihrer Website enden können. Hier sind einige weitere Beispiele dafür, wie Duplicate Content intern auf Ihrer Website und extern auf anderen Websites auftreten kann.
Intern erzeugte Duplikate
Spürbar ähnliche Produktseiten
Manchmal kann es sinnvoll sein, vor allem im E-Commerce bewusst ähnlich aussehende Seiten zu erstellen. Angenommen, Sie verkaufen dasselbe Produkt in zwei verschiedenen Ländern. In diesem Fall können Sie sich dafür entscheiden, zwei nahezu identische Seiten zu haben, außer dass auf einer der Preis in US-Dollar und auf der anderen in Kanadischen Dollar angezeigt wird.
Ein weiteres Beispiel sind Produktseiten, die merklich ähnlich aussehen, weil sie denselben Text enthalten, wobei die einzigen wirklichen Unterschiede ein anderes Produktbild, ein anderer Produktname und ein anderer Produktpreis sind.
Content-Management-Systeme
Manchmal erstellen Content-Management-Systeme doppelte Inhalte, die Ihnen vielleicht gar nicht bewusst sind. Einige Systeme fügen Tags und URL-Parameter für Suchen automatisch hinzu, was zu mehreren Pfaden zu genau demselben Inhalt führt.
URL-Variationen
Sie können auch mit Duplicate Content enden, wenn Sie verschiedene URL-Variationen haben, die denselben Inhalt enthalten. Wie bereits erwähnt, können Content-Management-Systeme dies selbst tun, und Sie erhalten möglicherweise zwei URL-Variationen wie https://www.website.com/blog1 und https://www.website.com/blogs/blog1 . Andere URL-Variationen wie abschließende Schrägstriche oder großgeschriebene URLs können dasselbe Problem verursachen.
In diesem Fall weiß Google möglicherweise nicht, welche Seite zu ranken ist, und einige externe Quellen verlinken möglicherweise auf eine dieser Seiten, während andere auf das Duplikat verlinken, wodurch die Link-Equity Ihrer Seite zerstört wird.
HTTP vs. HTTPS und www vs. nicht-www
Auf die meisten Websites kann mit oder ohne www oder sowohl über HTTP- als auch über HTTPS-URLs zugegriffen werden. Wenn Sie Ihre Website jedoch nicht richtig konfiguriert haben, kann Google Seiten von mehr als einer von ihnen indizieren, was zu doppeltem Inhalt führt.
Druckerfreundliche und für Mobilgeräte optimierte URLs
Druckfreundliche oder für Mobilgeräte optimierte Seiten, die unter anderen URLs als der Originalseite gehostet werden, führen zu doppeltem Inhalt, es sei denn, sie sind ordnungsgemäß noindexed.
Sitzungs-IDs
Sitzungs-IDs können wertvolle Werkzeuge sein, um Besucher nachzuverfolgen, die Ihre Website besuchen. Dies geschieht im Allgemeinen durch Hinzufügen einer langen Sitzungs-ID-Zeichenfolge zur URL. Da jede Sitzungs-ID eindeutig ist, wird dadurch eine neue URL erstellt und Ihr Inhalt dupliziert.
UTM-Parameter
Parameter können eingehende Besucher aus verschiedenen Quellen verfolgen. Wie Sitzungs-IDs generieren sie eindeutige URLs, obwohl der Inhalt der Seite derselbe ist, und erzeugen so doppelte Inhalte, wenn sie indexiert werden.
Extern erzeugte Duplikate
Syndizierter Inhalt
Das Syndizieren Ihrer Inhalte auf anderen Websites im Internet kann eine großartige Möglichkeit sein, mehr Besucher auf Ihre Website zu lenken und Ihren Namen bekannt zu machen. Dieser Inhalt kann jedoch immer noch als doppelter Inhalt angezeigt werden, wenn er nicht mit den richtigen kanonischen Header-Tags formatiert ist. Beispielsweise kann die Verwendung von kanonischen Tags für Medium-Artikel Ihren ursprünglichen Inhalt davor schützen, als Duplikat registriert zu werden.
Plagiat
Während die meisten doppelten Inhalte nicht bösartig sind, kopieren einige Webmaster Inhalte absichtlich, um von Inhalten zu profitieren, die sie nicht selbst erstellt haben.
Duplicate Content SEO: Warum ist das wichtig?
Wenn Duplicate Content so häufig vorkommt, warum spielt es eine Rolle? Hier sind fünf Möglichkeiten, wie sich dies auf Ihre Fähigkeit auswirken kann, in den Suchergebnissen gut zu ranken.
1. Google-Abstrafung für doppelte Inhalte
Google bestraft doppelte Inhalte nicht direkt – meistens. Wenn Google der Meinung ist, dass Duplicate Content auf Ihrer Website „täuschend“ ist und „Suchmaschinenergebnisse manipulieren soll“, kann es Maßnahmen ergreifen, indem es eine Duplicate Content Penalty verhängt. Auch wenn es nicht oft vorkommt, können Sie gemäß den Google-Richtlinien für doppelte Inhalte dennoch mit einer direkten Strafe rechnen, wenn Ihre doppelten Inhalte ungeheuerlich genug sind und vermutlich mit böswilliger Absicht erstellt wurden.
Eine Google-Abstrafung für Duplicate Content ist selten, daher ist die drängendere Sorge die Beziehung zwischen Duplicate Content und SEO.
2. Aufblasen des Index
Index-Bloat tritt auf, wenn Suchmaschinen-Crawler auf unwichtige oder minderwertige Inhalte zugreifen und diese indexieren – wie die druckerfreundlichen Seiten, die ich erwähnt habe. Dies wirkt sich auf Ihre Fähigkeit aus, Ihre wichtigen Seiten zu ranken, da Suchmaschinen nicht wissen, welche Version Ihres Inhalts sie den Benutzern vorschlagen sollen, und möglicherweise eine andere Version ranken, als Sie möchten. Es wirkt sich auch auf das Crawl-Budget aus.
3. Crawl-Budget
Google beschränkt die Zeit, die es mit dem Crawlen von Websites verbringt. Die Menge an Ressourcen, die Google zum Crawlen und Indizieren Ihrer Website bereitstellt, ist Ihr Crawl-Budget. Wenn Sie viele doppelte Inhalte haben, riskieren Sie, Ihr Crawl-Budget auf Seiten zu verschwenden, die nicht so wichtig sind.
4. Stichwort Kannibalisierung
Wenn mehr als eine Kopie einer Seite rankt, konkurrieren Ihre Seiten um die gleichen Keywords und die gleiche Sichtbarkeit. Es ist schwer genug, mit allen anderen zu konkurrieren, warum sollte man es sich noch schwerer machen, indem man auch mit sich selbst konkurriert?
Letztendlich können Sie SEO-Probleme mit doppelten Inhalten nicht einfach ignorieren. Versuchen Sie nach Möglichkeit, Duplicate Content zu konsolidieren oder zu entfernen.
5. Abnehmende Link Equity
Nehmen wir an, Google beschließt, zwei Ihrer bemerkenswert ähnlichen Seiten zu ranken. Woher wissen sie, ob sie den gesamten Wert des Inhalts einer Seite zuschreiben oder ob Autorität, Linkwert und Vertrauen stattdessen auf beide Seiten aufgeteilt werden sollten? Diese Situation kann den SEO-Wert Ihrer Inhalte verringern und zu einer Minderleistung führen.
Der Linkwert Ihrer Backlinks wird auch zwischen den beiden Seiten aufgeteilt, je nachdem, ob andere Websites verlinken.
So überprüfen Sie Ihre eigene Website auf Duplicate Content
Das Auffinden von Duplicate Content auf Ihrer Website ist kostenlos und einfach. Verwenden Sie kostenlose Versionen von Screaming Frog und Siteliner, um Ihre Website methodisch zu crawlen und exakte oder nahezu doppelte Seiten zu identifizieren.
So verwenden Sie Screaming Frog, um doppelte Inhalte aufzudecken
Screaming Frog ist ein Website-Crawler und SEO-Audit-Tool, das Ihnen helfen kann, Probleme mit doppelten Inhalten auf Ihrer Website zu identifizieren. So verwenden Sie Screaming Frog, um bis zu 500 URLs kostenlos zu scannen.
1. Crawlen Sie Ihre Website mit SEO Spider
Laden Sie zuerst Screaming Frog herunter und öffnen Sie es. Geben Sie die URL der Website, die Sie crawlen möchten, in das Feld „URL zu Spider eingeben“ ein und klicken Sie auf „Start“.
2. Suchen Sie auf der Registerkarte „Inhalt“ nach Duplikaten
Klicken Sie auf die Registerkarte „Inhalt“, um nach exakten Duplikaten und Beinahe-Duplikaten zu suchen. Sie können exakte Duplikate in Echtzeit sehen, aber Sie müssen eine „Crawl-Analyse“ durchführen, um die Liste der Beinahe-Duplikate anzuzeigen.

3. Suchen Sie nach Near Duplicates
Klicken Sie in der Menüleiste auf die Registerkarte „Crawling-Analyse“ und wählen Sie im Dropdown-Menü „Start“ aus.
Wenn die Crawl-Analyse abgeschlossen ist, sehen Sie die gefüllten Spalten mit nahezu doppelten Einträgen. Sie wissen, dass es fertig ist, weil der Fortschrittsbalken „Analyse“ 100 % anzeigt und der Filter „Beinahe Duplikate“ nicht mehr die Meldung „Crawling-Analyse erforderlich“ anzeigt.
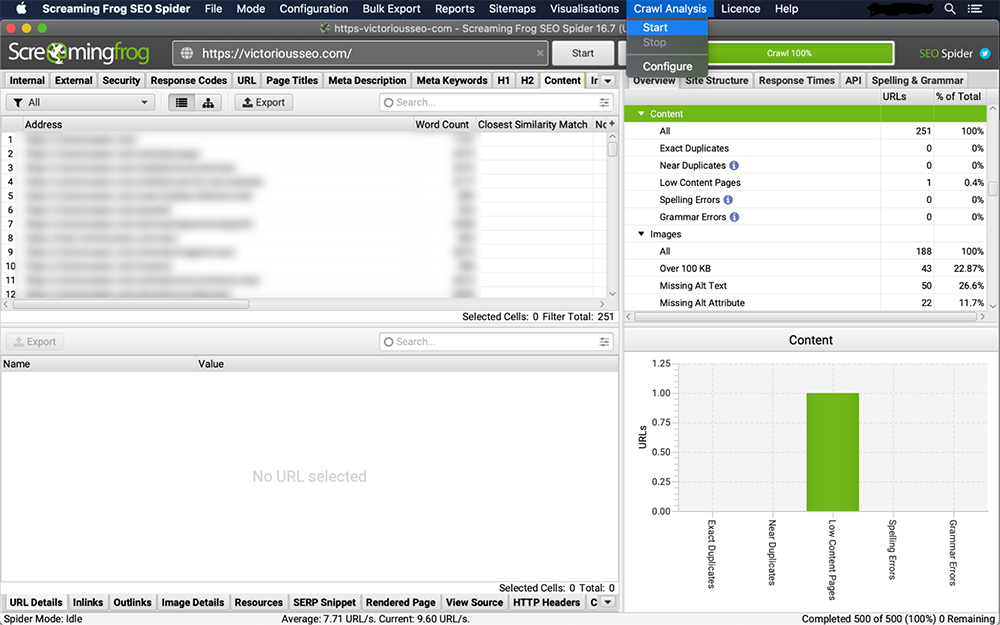
4. Zeigen Sie Duplikate auf der Registerkarte „Inhalt“ an
Die „Übereinstimmung mit der größten Ähnlichkeit“, „Nr. Near Duplicates“ und „Address“-Spalten werden ausgefüllt, sobald die Crawl-Analyse abgeschlossen ist.

Der Filter „Genaue Duplikate“ zeigt Seiten an, die basierend auf einem HTML-Code-Scan identisch sind. Der eingestellte Ähnlichkeitsschwellenwert bestimmt, was als „Beinahe Duplikate“ qualifiziert wird. Um den Schwellenwert zu ändern, gehen Sie zu 'Config → Spider → Content. Dieser Schwellenwert ist standardmäßig auf 90 % eingestellt, Sie können ihn jedoch nach Belieben ändern.
Nachdem der Scan abgeschlossen ist, überprüfen Sie manuell jede Seite, die als exaktes oder nahezu identisches Duplikat angezeigt wird.
So verwenden Sie Siteliner, um doppelte Inhalte aufzudecken
Siteliner ist ein weiteres kostenloses Tool, mit dem Sie Ihre Website (oder jede andere Website) auf doppelte Inhalte scannen können. Die kostenlose Version beschränkt Sie jedoch auf eine Nutzung alle 30 Tage und begrenzt die Anzahl der Ergebnisse auf 250 Seiten. Wenn Sie mehrere Suchen durchführen müssen oder mehr Ergebnisse sehen möchten, melden Sie sich für die Premium-Version an.
Um mit Siteliner nach doppelten Inhalten zu suchen, geben Sie einfach die URL, die Sie suchen möchten, in das Suchfeld auf ihrer Homepage ein.
Siteliner durchsucht dann die Website und teilt Ihnen mit, wie viele doppelte Inhalte gefunden wurden, und hebt hervor, was seiner Meinung nach Ihre wichtigsten Probleme sind. Es zeigt auch mehrere weitere Metriken an, darunter einige, die für SEO nützlich sein können, wie die durchschnittliche Seitenladezeit, interne und externe Links und eingehende Links.
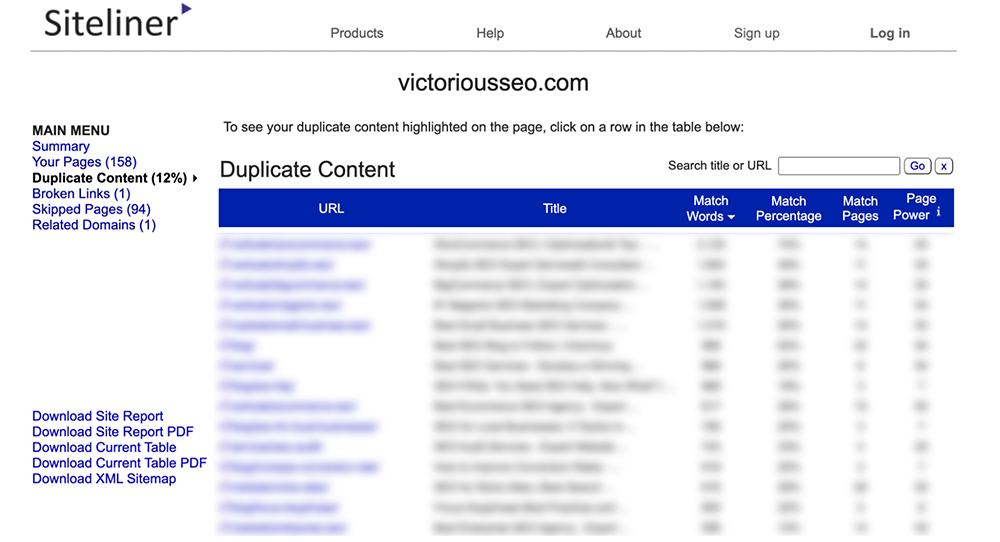
Klicken Sie im Hauptmenü auf „Duplicate Content“, um zu sehen, welche Seiten Siteline als doppelten Inhalt identifiziert.
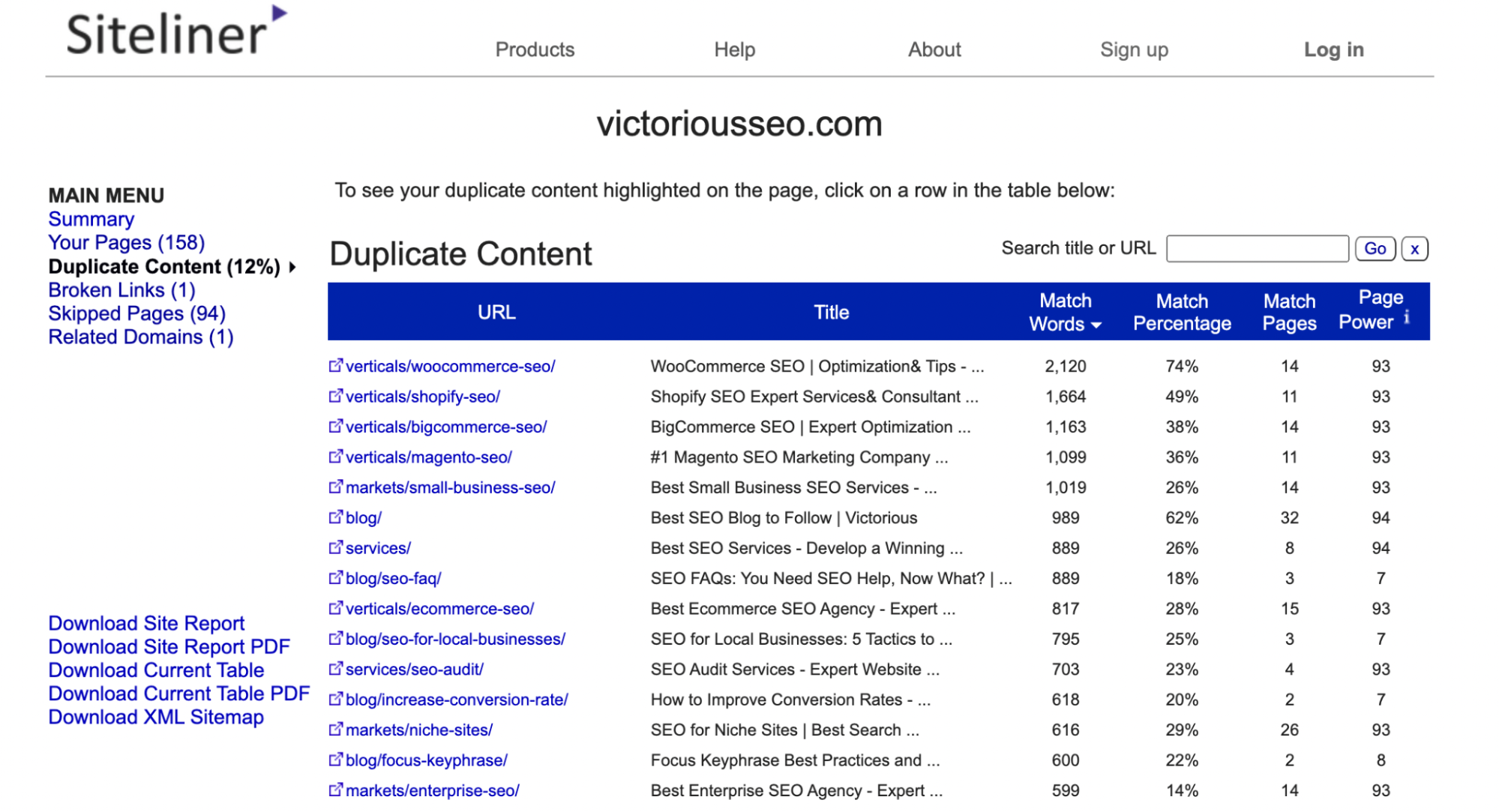
Klicken Sie auf jede einzelne Zeile, um zu sehen, welcher Text als dupliziert gekennzeichnet ist.
Hinweis: Siteline identifiziert Kopf- und Fußzeilen, die auf mehreren Seiten erscheinen, als doppelten Inhalt, sodass Sie möglicherweise viele Seiten mit einem niedrigen Übereinstimmungsprozentsatz erhalten, da sie alle denselben Menü- oder Fußzeileninhalt aufweisen.
So überprüfen Sie, ob jemand anderes Ihre Inhalte kopiert hat
Es gibt auch Tools zur Suche nach doppelten Inhalten, mit denen Sie überprüfen können, ob jemand anderes im Internet Ihre Inhalte kopiert hat. Copyscape ist ein kostenloses Tool zur Inhaltsprüfung von Websites, das effektiv und einfach zu bedienen ist.
Geben Sie einfach eine URL in das Suchfeld ein und klicken Sie direkt daneben auf die Schaltfläche „Los“. Copyscape führt dann eine webweite Suche durch, um zu sehen, ob ähnliche Textinhalte irgendwo anders existieren.

Wenn es etwas findet, gibt Copyscape die Ergebnisse zurück und organisiert sie in einer Liste, die den Suchergebnissen von Google ähnelt. Auf diese Weise können Sie einfach durch sie blättern und sehen, wie viel von Ihrem Inhalt kopiert wurde. Sie können es sich wie einen Google Duplicate Content Checker vorstellen.
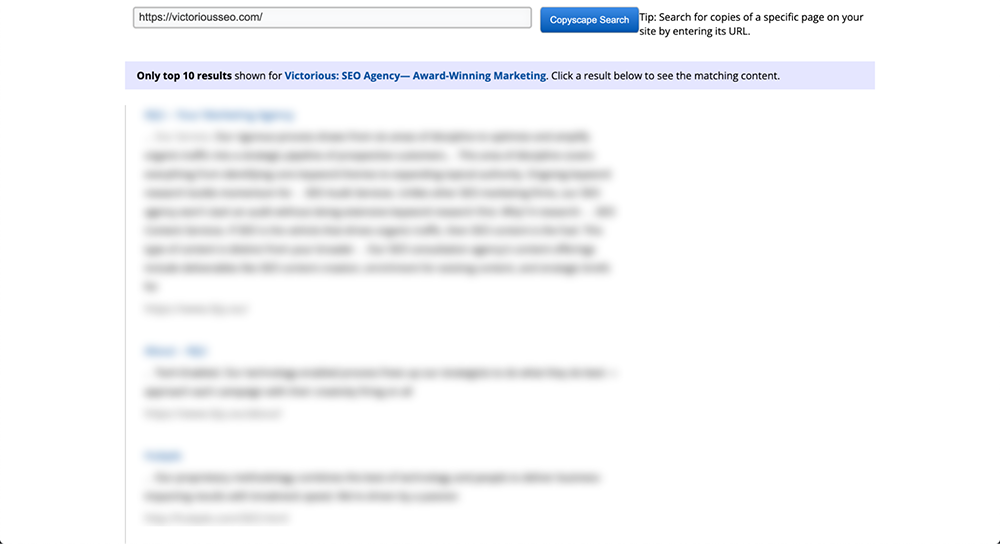
Was können Sie tun, wenn Sie feststellen, dass jemand anderes Ihre Inhalte plagiiert hat?
Wenden Sie sich zunächst an den Eigentümer der Website und bitten Sie ihn, entweder den Inhalt zu entfernen oder einen kanonischen Link zum ursprünglichen Inhalt Ihrer Website hinzuzufügen. Wenn das nicht funktioniert, senden Sie einen DMCA-Deaktivierungsantrag bei Google.
Hinweis: Wenn Sie Ihre Inhalte absichtlich syndiziert und anderen Websites erlaubt haben, sie zu veröffentlichen, werden sie dennoch als Duplikat angezeigt. Aus diesem Grund ist es wichtig, dass die veröffentlichende Website einen kanonischen Link oder ein noindex-Tag auf der Seite einfügt, um zu verhindern, dass sie mit Ihrer eigenen Seite in den Suchmaschinenrankings konkurriert.
So beheben Sie doppelte Inhalte
Um Probleme mit doppelten Inhalten zu beheben, bestimmen Sie, welche Kopie Google als Originalversion erkennen soll. Sie müssen auch entscheiden, ob Sie doppelte Seiten vollständig entfernen möchten oder ob Sie Google einfach anweisen möchten, sie nicht zu indizieren. Je nachdem, wofür Sie sich entscheiden, gibt es verschiedene Möglichkeiten, Ihren doppelten Inhalt zu bereinigen.
Noindex mit Meta Robots Tags & Robots.txt
Eine Möglichkeit, die Auswirkungen von doppelten Inhalten auf Ihre SEO zu minimieren, besteht darin, doppelte Seiten manuell zu deindexieren, indem Sie Ihre Meta-Roboter-Tags ändern. Verwenden Sie dazu das Meta-Robots-Tag und setzen Sie seine Werte auf „noindex, follow“. Wenden Sie dieses Tag auf die HTML-Überschrift jeder Seite an, die Sie aus den Suchergebnissen ausschließen möchten.
Das Meta-Robots-Tag ermöglicht es Suchmaschinen, die Links auf der Seite zu crawlen, auf der es angewendet wird, verhindert jedoch, dass Such-Crawler sie in ihre Indizes aufnehmen.
Warum erlauben Sie Google überhaupt, die Seite zu crawlen, wenn Sie nicht möchten, dass sie indexiert wird? Weil Google ausdrücklich davor gewarnt hat, den Crawl-Zugriff auf doppelte Inhalte auf Ihrer Website einzuschränken. Sie wollen wissen, dass es da ist, auch wenn Sie nicht wollen, dass sie es indexieren.
Ein noindex-Tag sollte so aussehen, wenn es auf Ihren HTML-Code angewendet wird:
<head> [code] <meta name=“robots“ content=“noindex, follow“> [anderer Code, falls erforderlich] </head>
Das Meta-Robots-Tag ist eine einfache und effektive Möglichkeit, doppelte Inhalte zu deindexieren und mögliche SEO-Probleme zu vermeiden, wenn Sie auf Ihrer Website deutlich ähnliche oder exakte doppelte Seiten haben.
Wenn Sie ganze Verzeichnisse haben, die Google und andere Suchmaschinen für die Indexierung blockieren möchten, bearbeiten Sie Ihre robots.txt-Datei.
301-Weiterleitungen
Eine weitere Möglichkeit, mit Duplicate Content umzugehen, ist eine 301-Weiterleitung. 301-Weiterleitungen sind permanente Weiterleitungen, die den Datenverkehr von der doppelten Seite weg und zu einer anderen URL weiterleiten. 301-Weiterleitungen sind SEO-freundlich und helfen Ihnen, mehrere Seiten zu einer einzigen URL zusammenzufassen, damit sie ihren Linkwert festigen.
Wenn Sie eine 301-Weiterleitung verwenden, akzeptiert die doppelte oder deutlich ähnliche Seite keinen Datenverkehr mehr. Verwenden Sie sie also nur, wenn Sie damit einverstanden sind, dass die doppelte Seite nicht mehr zugänglich ist, z. B. beim Pruning von Inhalten. Wenn Sie dennoch möchten, dass die Seite zugänglich ist, verwenden Sie ein Meta-Robots-Tag, um sie zu noindexieren.
Rel kanonisch
Eine andere Möglichkeit, doppelte Inhalte zu verwalten, besteht darin, das Attribut rel=canonical zu verwenden, um Seiten zu priorisieren. Platzieren Sie das Attribut rel=canonical innerhalb des HTML-Tags <head>, um Suchmaschinen mitzuteilen, dass eine bestimmte Seite als Kopie einer anderen Seite existiert und dass alle Links und Ranking-Macht, die zu dieser Seite gehören, tatsächlich dem Canonical zugeschrieben werden sollten Seite.
Ein rel=canonical-Tag sieht in etwa so aus, wenn es auf Ihren HTML-Code angewendet wird:
<head> [code] <link href=“URL DER PRIORISIERTEN SEITE“ rel=“canonical“ /> </head>
Sie können auch ein selbstreferenzierendes kanonisches Tag verwenden, um anzugeben, dass eine bestimmte Seite als Originalversion behandelt werden soll.
Entfernen Sie URLs aus Ihrer XML-Sitemap
Ihre XML-Sitemap sollte nur URLs enthalten, die Sie indexieren möchten. Wenn Sie keine dynamische URL verwenden, die Ihre Sitemap automatisch aktualisiert, müssen Sie Ihre Sitemap manuell bearbeiten und alle URLs entfernen, die Sie nicht indexieren oder umleiten.
URL in der Google Search Console entfernen
Wenn Sie eine Seite umleiten oder die Indexierung einschränken möchten, fordern Sie Google auf, diese URL aus seinem Index zu entfernen.
Melden Sie sich bei Ihrer Google Search Console an und wählen Sie im Menü auf der linken Seite „Entfernungen“ aus.
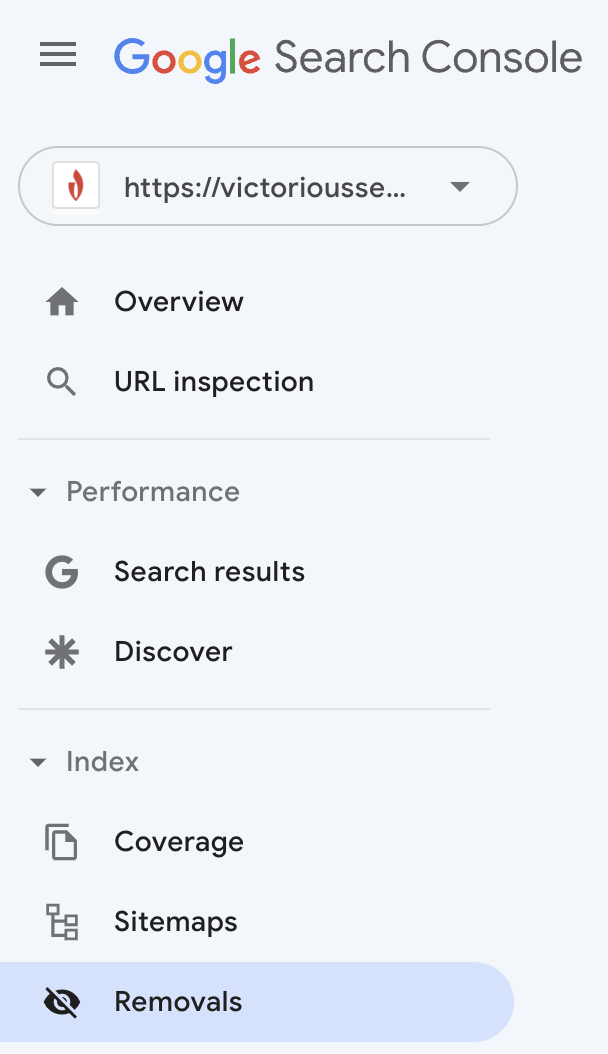
Ein Feld wird eingeblendet, das Sie darüber informiert, dass das Einreichen einer URL diese nur für sechs Monate aus dem Google-Index streicht. Wenn Google nach dieser Zeit Ihre Website crawlt und auf die URL stößt, wird sie neu indiziert, es sei denn, sie wurde umgeleitet oder durch ein Robots-Tag blockiert. Wenn Sie mehrere URLs haben, die ein gemeinsames Präfix haben, können Sie auch das Präfix einreichen, um alle URLs vorübergehend aus dem Google-Index zu entfernen.

Nach sechs Monaten versucht Google erneut, Ihre URLs zu crawlen. Wenn Sie sie ordnungsgemäß umgeleitet oder nicht indexiert haben, erscheinen sie nicht mehr auf der Ergebnisseite der Suchmaschine (SERP).
Benötigen Sie Hilfe bei der Identifizierung von Tech-SEO-Problemen?
Möchten Sie das Ranking Ihrer Website verbessern? Arbeiten Sie mit einer Data-Drive-SEO-Agentur zusammen, die mit Ihnen zusammenarbeitet, um technische SEO-Probleme auf Ihrer Website zu identifizieren und eine erfolgreiche SEO-Strategie zu entwickeln, die Ihnen hilft, die SERPs zu erklimmen. Buchen Sie noch heute eine kostenlose SEO-Beratung und erfahren Sie, was wir für Sie tun können!