
SEO de contenido duplicado: cómo comprobar si hay contenido duplicado
Publicado: 2022-06-14El contenido duplicado puede afectar cuál de sus páginas aparece en los resultados de búsqueda y desperdiciar su presupuesto de rastreo. Afortunadamente, hay formas de identificar contenido duplicado y eliminarlo de su sitio web o del índice de Google para evitar que afecte negativamente su capacidad de clasificación.
¿Qué es el contenido duplicado?
El contenido duplicado ocurre cuando el mismo contenido aparece en más de una ubicación con una URL única.
El contenido no necesita ser una coincidencia exacta para registrarse como duplicado; también puede ser lo que Google llama "apreciablemente similar". Este contenido es esencialmente "lo suficientemente cercano" para ser considerado contenido duplicado, aunque algunos textos pueden diferir.
La mayoría de los propietarios de sitios trabajan arduamente para asegurarse de que su contenido sea nuevo y original y, sin embargo, todavía hay mucho contenido duplicado en la web. A veces, los propietarios de los sitios ni siquiera son conscientes de ello. Entonces, ¿cómo sucede esto?
¿Por qué ocurre el contenido duplicado?
La mayoría del contenido duplicado en la web ocurre debido a la indexación de cosas como versiones de páginas aptas para imprimir, productos que están en o están vinculados a varias URL diferentes y foros de discusión que generan versiones de escritorio y móviles reducidas de la misma página. .
Pero esas no son las únicas formas en que puede terminar con contenido duplicado en su sitio. Aquí hay algunos ejemplos más de cómo el contenido duplicado puede ocurrir internamente en su sitio y externamente en otros sitios.
Duplicados generados internamente
Páginas de productos apreciablemente similares
A veces puede tener sentido crear intencionalmente páginas significativamente similares, especialmente en el comercio electrónico. Por ejemplo, suponga que vende el mismo producto en dos países diferentes. En ese caso, puede elegir tener dos páginas casi idénticas, excepto que una puede mostrar el precio en dólares estadounidenses y la otra en dólares canadienses.
Otro ejemplo son las páginas de productos que parecen apreciablemente similares porque presentan la misma copia, con las únicas diferencias reales que son una imagen, nombre y precio del producto diferentes.
Sistemas de gestión de contenido
A veces, los sistemas de administración de contenido crean contenido duplicado que quizás ni siquiera conozcas. Algunos sistemas agregan etiquetas y parámetros de URL para búsquedas automáticamente, lo que da como resultado múltiples rutas al mismo contenido exacto.
Variaciones de URL
También puede terminar con contenido duplicado si tiene diferentes variaciones de URL que presentan el mismo contenido. Como se mencionó anteriormente, los sistemas de administración de contenido pueden hacer esto por sí solos y puede terminar con dos variaciones de URL como https://www.website.com/blog1 y https://www.website.com/blogs/blog1 . Otras variaciones de URL, como barras diagonales finales o URL en mayúsculas, pueden causar el mismo problema.
Cuando esto sucede, es posible que Google no sepa qué página clasificar y algunas fuentes externas pueden vincular a una de estas páginas mientras que otras vinculan al duplicado, rompiendo la equidad de enlace de su página en el proceso.
HTTP frente a HTTPS y www frente a no www
Se puede acceder a la mayoría de los sitios web con o sin www o en URL HTTP o HTTPS. Sin embargo, si no ha configurado su sitio correctamente, Google puede indexar páginas de más de uno de ellos, lo que genera contenido duplicado.
URL compatibles con impresoras y dispositivos móviles
Las páginas aptas para imprimir o para dispositivos móviles alojadas en direcciones URL diferentes a las de la página original generarán contenido duplicado, a menos que no estén indexadas correctamente.
ID de sesión
Los ID de sesión pueden ser herramientas valiosas para realizar un seguimiento de los visitantes que visitan su sitio. Esto generalmente se hace agregando una cadena larga de ID de sesión a la URL. Debido a que cada ID de sesión es único, esto crea una nueva URL y duplica su contenido.
Parámetros UTM
Los parámetros pueden rastrear a los visitantes entrantes desde varias fuentes. Al igual que los ID de sesión, generan URL únicas aunque el contenido de la página sea el mismo, por lo que se crea contenido duplicado si se indexa.
Duplicados generados externamente
Contenido sindicado
Distribuir su contenido a otros sitios en la web puede ser una excelente manera de atraer más tráfico a su sitio web y dar a conocer su nombre. Sin embargo, este contenido aún puede aparecer como contenido duplicado si no se formatea con las etiquetas de encabezado canónicas adecuadas. Por ejemplo, el uso de etiquetas canónicas en artículos de Medium puede proteger su contenido original para que no se registre como duplicado.
Plagio
Si bien la mayoría del contenido duplicado no es de naturaleza maliciosa, algunos webmasters copian contenido deliberadamente, buscando beneficiarse del contenido que no produjeron ellos mismos.
Contenido duplicado SEO: ¿Por qué es importante?
Si el contenido duplicado ocurre con tanta frecuencia, ¿por qué es importante? Aquí hay cinco formas en que puede afectar su capacidad para clasificarse bien en los resultados de búsqueda.
1. Penalización por contenido duplicado de Google
Google no penaliza directamente el contenido duplicado, la mayoría de las veces. Si Google cree que el contenido duplicado en su sitio es "engañoso" y "tiene la intención de manipular los resultados del motor de búsqueda", entonces puede tomar medidas aplicando una penalización por contenido duplicado. Entonces, aunque no sucede con frecuencia, de acuerdo con las pautas de contenido duplicado de Google, aún puede terminar lidiando con una sanción directa si su contenido duplicado es lo suficientemente atroz y se cree que se creó con intenciones maliciosas.
Una penalización de Google por contenido duplicado es rara, por lo que la preocupación más apremiante es la relación entre el contenido duplicado y el SEO.
2. Hinchazón del índice
La hinchazón del índice ocurre cuando los rastreadores de los motores de búsqueda acceden e indexan contenido sin importancia o de baja calidad, como esas páginas fáciles de imprimir que mencioné. Esto afecta su capacidad para clasificar sus páginas importantes, ya que los motores de búsqueda no sabrán qué versión de su contenido sugerir a los usuarios y pueden clasificar una versión diferente de la que usted preferiría. También afecta el presupuesto de rastreo.
3. Presupuesto de rastreo
Google limita la cantidad de tiempo que dedica a rastrear sitios. La cantidad de recursos que proporciona Google para rastrear e indexar su sitio es su presupuesto de rastreo. Cuando tiene mucho contenido duplicado, corre el riesgo de desperdiciar su presupuesto de rastreo en páginas que no son tan importantes.
4. Canibalización de palabras clave
Si más de una copia de una página está clasificada, sus páginas competirán entre sí por las mismas palabras clave y visibilidad. Ya es bastante difícil competir con todos los demás, ¿por qué hacerlo más difícil compitiendo también contigo mismo?
En última instancia, no puede simplemente ignorar los problemas de contenido duplicado de SEO. Siempre que sea posible, intente consolidar o eliminar el contenido duplicado.
5. Disminución de la equidad del enlace
Digamos que Google decide clasificar dos de sus páginas apreciablemente similares. ¿Cómo saben si deben atribuir todo el valor del contenido a una página o si la autoridad, la equidad de los enlaces y la confianza deben dividirse entre ambas páginas? Esta situación puede reducir el valor SEO de su contenido, lo que hace que tenga un rendimiento inferior.
La equidad de enlace de sus backlinks también se dividirá entre las dos páginas dependiendo de si otros sitios eligen vincularse.
Cómo comprobar si hay contenido duplicado en su propio sitio
Encontrar contenido duplicado en su sitio es gratis y fácil. Use versiones gratuitas de Screaming Frog y Siteliner para rastrear metódicamente su sitio e identificar cualquier página duplicada exacta o casi.
Cómo usar Screaming Frog para descubrir contenido duplicado
Screaming Frog es un rastreador de sitios web y una herramienta de auditoría SEO que puede ayudarlo a identificar problemas de contenido duplicado en su sitio web. Aquí se explica cómo usar Screaming Frog para escanear hasta 500 URL de forma gratuita.
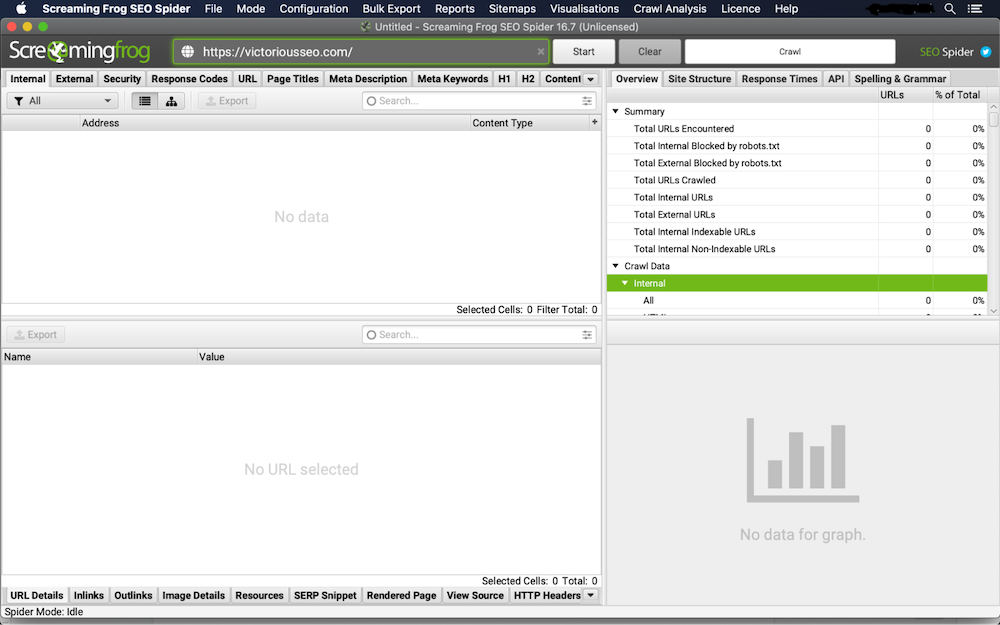
1. Rastrea tu sitio con SEO Spider
Primero, descargue y abra Screaming Frog. Escriba la URL del sitio web que desea rastrear en el campo 'Ingresar URL para Spider' y haga clic en 'Iniciar'.
2. Busque duplicados en la pestaña 'Contenido'
Haga clic en la pestaña 'Contenido' para buscar duplicados exactos y casi duplicados. Podrá ver los duplicados exactos en tiempo real, pero debe realizar un "Análisis de rastreo" para ver la lista de casi duplicados.

3. Buscar casi duplicados
Haga clic en la pestaña "Análisis de rastreo" en la barra de menú y seleccione "Iniciar" en el menú desplegable.
Cuando finalice el análisis de rastreo, verá las columnas casi duplicadas pobladas. Sabrá que ha terminado porque la barra de progreso de 'análisis' mostrará el 100 % y el filtro casi duplicado ya no mostrará el mensaje 'se requiere análisis de rastreo'.
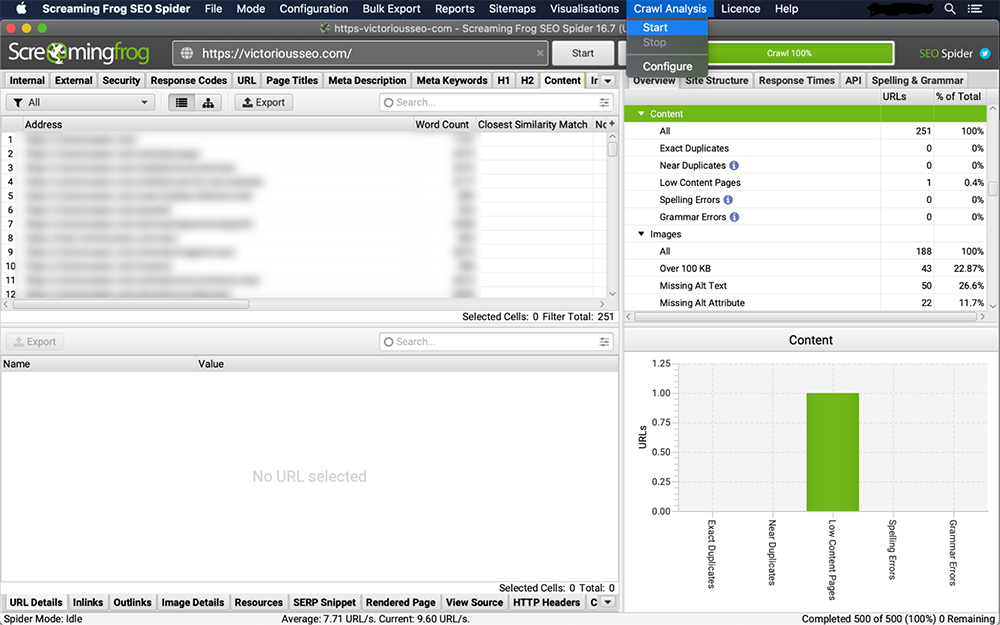
4. Ver duplicados en la pestaña 'Contenido'
La 'coincidencia de similitud más cercana', 'No. Las columnas "Cerca de duplicados" y "Dirección" se completarán una vez que se complete el análisis de rastreo.

El filtro 'Duplicados exactos' mostrará páginas que son idénticas entre sí según un escaneo de código HTML. El umbral de similitud establecido determina lo que califica como 'Cerca de duplicados'. Para cambiar el umbral, vaya a 'Config → Spider → Contenido. Este umbral está establecido en 90 % de forma predeterminada, pero puedes cambiarlo a lo que prefieras.
Ahora que el escaneo está listo, revise manualmente cualquier página que aparezca como un duplicado exacto o casi.
Cómo usar Siteliner para descubrir contenido duplicado
Siteliner es otra herramienta gratuita que puede usar para escanear su sitio web (o cualquier sitio web) en busca de contenido duplicado. Sin embargo, la versión gratuita te limitará a un uso cada 30 días y restringirá el número de resultados a 250 páginas. Si necesita realizar múltiples búsquedas o desea ver más resultados, regístrese en la versión premium.
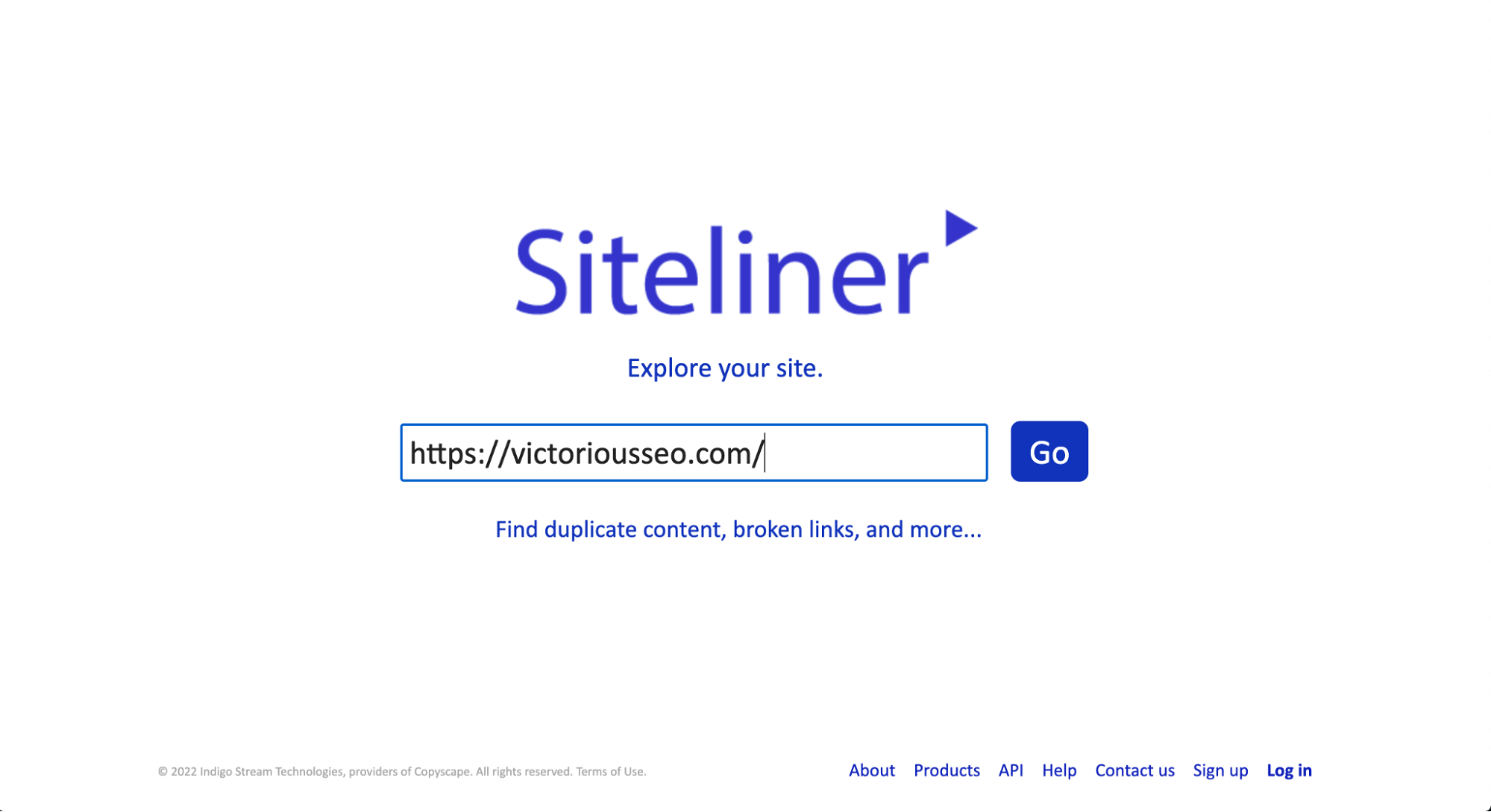
Para verificar si hay contenido duplicado con Siteliner, simplemente ingrese la URL que desea buscar en el cuadro de búsqueda en su página de inicio.
Siteliner luego hará un barrido del sitio y le dirá cuánto contenido duplicado se ha encontrado y resaltará lo que cree que son sus principales problemas. También mostrará varias métricas más, incluidas algunas que pueden ser útiles para SEO, como el tiempo promedio de carga de la página, los enlaces internos y externos y los enlaces entrantes.
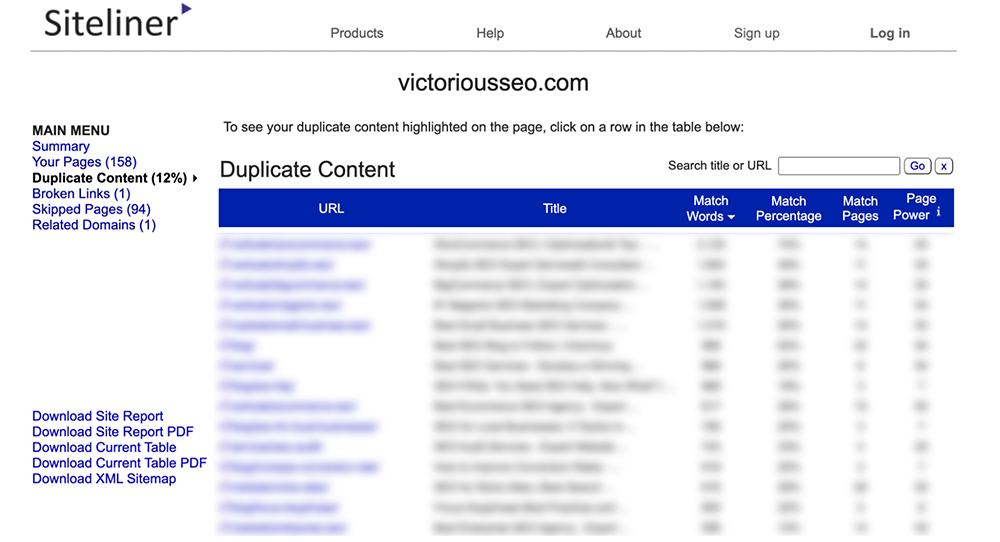
En el menú principal, haga clic en "Contenido duplicado" para ver qué páginas Siteline identifica como que tienen contenido duplicado.
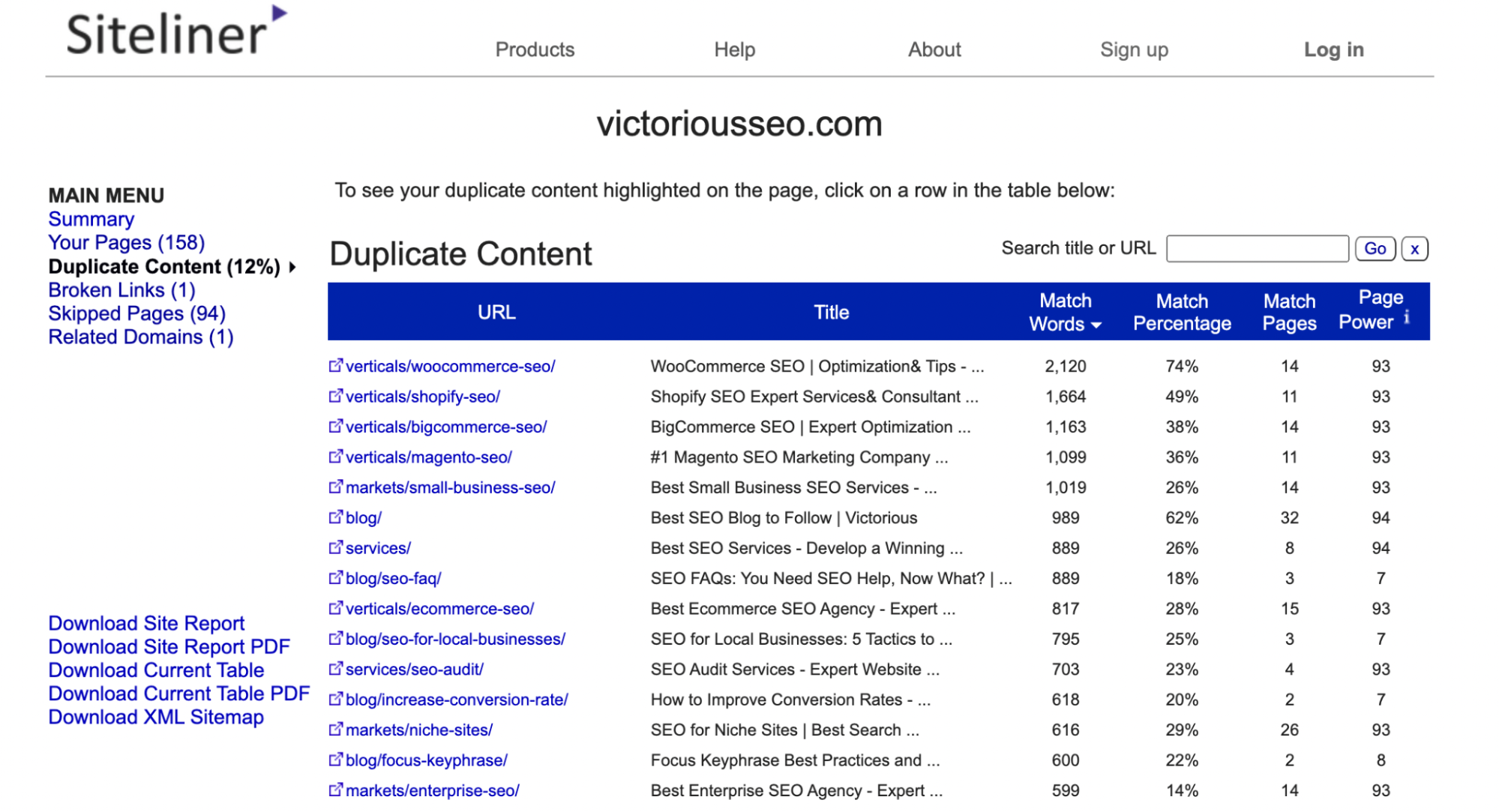
Haga clic en cada línea individual para ver qué texto está marcado como duplicado.
Nota: Siteline identificará los encabezados y pies de página que aparecen en varias páginas como contenido duplicado, por lo que es posible que obtenga muchas páginas con un porcentaje de coincidencia bajo porque cada una comparte el mismo menú o contenido de pie de página.
Cómo verificar si alguien más ha copiado su contenido
También hay herramientas de búsqueda de contenido duplicado que puede usar para verificar si alguien más en la web ha copiado su contenido. Copyscape es una herramienta gratuita de verificación de contenido de sitios web que es efectiva y fácil de usar.
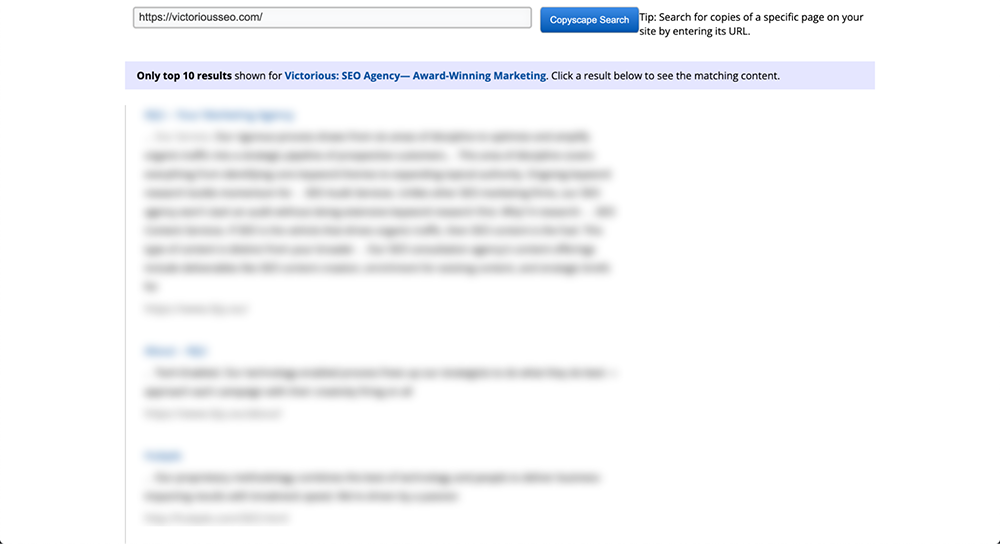
Simplemente inserte una URL en el cuadro de búsqueda y haga clic en el botón "Ir" justo al lado. Copyscape luego realizará una búsqueda en toda la web para ver si existe contenido de texto similar en otro lugar.

Si encuentra algo, Copyscape devolverá los resultados y los organizará en una lista que se parece a los resultados de búsqueda de Google. Esto le permite desplazarse fácilmente por ellos y ver cuánto de su contenido se ha copiado. Puede pensar en ello como un verificador de contenido duplicado de Google.
¿Qué puedes hacer si descubres que alguien más ha plagiado tu contenido?
Primero, comuníquese con el propietario del sitio web y pídale que elimine el contenido o que agregue un enlace canónico al contenido original de su sitio web. Si eso no funciona, envíe una solicitud de eliminación de DMCA con Google.
Nota: si ha sindicado intencionalmente su contenido y ha permitido que otros sitios web lo publiquen, seguirá apareciendo como un duplicado. Por eso es importante exigir que el sitio de publicación incluya un enlace canónico o una etiqueta sin índice en la página para evitar que compita con su propia página en los rankings de los motores de búsqueda.
Cómo arreglar contenido duplicado
Para solucionar problemas de contenido duplicado, identifique qué copia desea que Google reconozca como la versión original. También deberá decidir si desea eliminar las páginas duplicadas por completo o si simplemente desea decirle a Google que no las indexe. Dependiendo de lo que decidas, hay algunas formas diferentes de limpiar tu contenido duplicado.
Noindex con etiquetas Meta Robots y Robots.txt
Una forma de minimizar el impacto del contenido duplicado en su SEO es desindexar manualmente cualquier página duplicada modificando sus etiquetas meta robots. Para hacer esto, use la etiqueta meta robots y establezca sus valores en "noindex, seguir". Aplique esta etiqueta al encabezado HTML de cada página que desee excluir de los resultados de búsqueda.
La etiqueta meta robots permite que los motores de búsqueda rastreen los enlaces en la página en la que se aplica, pero evita que los rastreadores de búsqueda los incluyan en sus índices.
¿Por qué permitir que Google rastree la página si no desea que se indexe? Porque Google ha advertido explícitamente contra la restricción del acceso de rastreo a cualquier contenido duplicado en su sitio. Quieren saber que está ahí, incluso si no quieres que lo indexen.
Una etiqueta noindex debería verse así cuando se aplica a su código HTML:
<head> [código] <meta name=”robots” content=”noindex, follow”> [otro código si es necesario] </head>
La etiqueta meta robots es una forma simple y efectiva de desindexar contenido duplicado y evitar posibles problemas de SEO por tener páginas duplicadas apreciablemente similares o exactas en su sitio web.
Si tiene directorios completos que le gustaría bloquear la indexación de Google y otros motores de búsqueda, edite su archivo robots.txt.
Redirecciones 301
Otra forma de manejar un problema de contenido duplicado es con una redirección 301. Los 301 son redireccionamientos permanentes que desvían el tráfico de la página duplicada hacia otra URL. Los redireccionamientos 301 son compatibles con SEO y lo ayudan a combinar varias páginas en una sola URL para que consoliden su valor de enlace.
Cuando usa una redirección 301, la página duplicada o sensiblemente similar ya no aceptará ningún tráfico, así que úselo solo cuando esté de acuerdo con que la página duplicada ya no sea accesible, como cuando elimine el contenido. Si aún desea que la página sea accesible, use una etiqueta de meta robots para no indexarla.
Rel Canónico
Otra forma de administrar su contenido duplicado es usar el atributo rel=canonical para priorizar las páginas. Coloque el atributo rel=canonical dentro de la etiqueta HTML <head> para decirle a los motores de búsqueda que una página específica existe como una copia de otra página y que todos los enlaces y el poder de clasificación que pertenecen a esta página en realidad deben atribuirse a la canonical. página.
Una etiqueta rel=canonical se parece a esto cuando se aplica a su código HTML:
<head> [código] <link href=”URL DE PÁGINA PRIORIZADA” rel=”canonical” /> </head>
También puede usar una etiqueta canónica autorreferencial para indicar que desea que una página en particular sea tratada como la versión original.
Eliminar URL de su mapa del sitio XML
Su mapa del sitio XML solo debe incluir las URL que desea indexar. Si no está utilizando una URL dinámica que actualice automáticamente su mapa del sitio, deberá editar manualmente su mapa del sitio y eliminar cualquier URL que no indexe o redirija.
Eliminar URL en Google Search Console
Si elige redirigir una página o restringir la indexación, solicite a Google que elimine esa URL de su índice.
Inicie sesión en Google Search Console y seleccione 'Eliminaciones' en el menú de la izquierda.
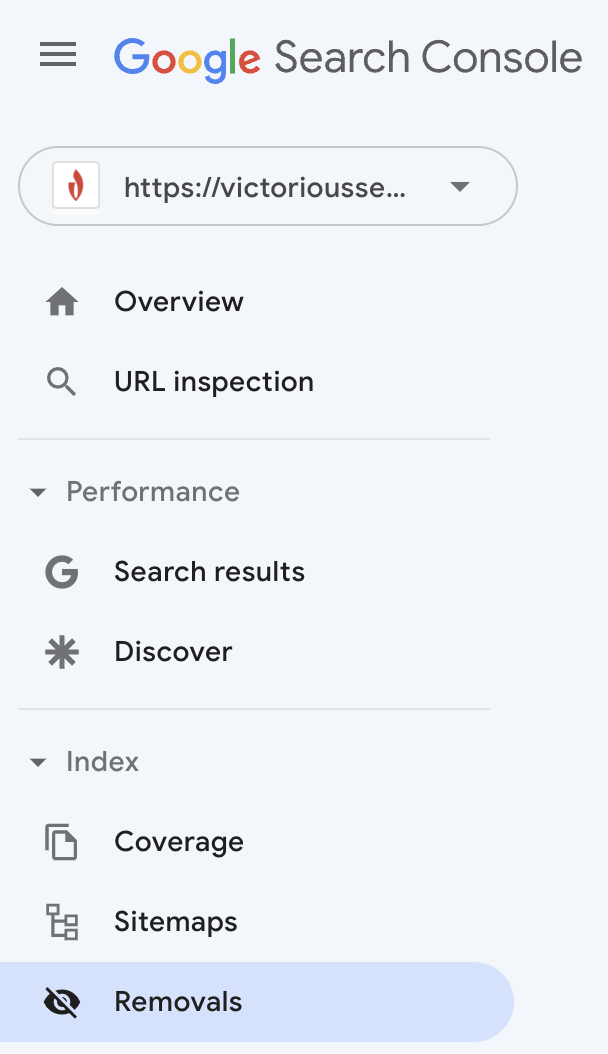
Aparecerá un cuadro que le informará que enviar una URL la eliminará del índice de Google durante solo seis meses. Después de ese tiempo, si Google rastrea su sitio y encuentra la URL, se volverá a indexar a menos que haya sido redirigido o bloqueado por una etiqueta de robots. Si tiene varias URL que comparten un prefijo, también puede enviar el prefijo para eliminar temporalmente todas las URL del índice de Google.

Después de seis meses, Google intentará rastrear sus URL nuevamente. Si los redirigió correctamente o no los indexó, ya no aparecerán en la página de resultados del motor de búsqueda (SERP).
¿Necesita ayuda para identificar problemas de SEO tecnológico?
¿Está buscando mejorar la capacidad de clasificación de su sitio? Asóciese con una agencia de SEO basada en datos que trabajará con usted para identificar problemas técnicos de SEO en su sitio web y desarrollar una estrategia de SEO ganadora para ayudarlo a escalar en los SERP. ¡Reserve una consulta gratuita de SEO hoy y vea lo que podemos hacer por usted!