
重複コンテンツSEO:重複コンテンツをチェックする方法
公開: 2022-06-14重複するコンテンツは、検索結果に表示されるページに影響を与え、クロール予算を浪費する可能性があります。 幸いなことに、重複するコンテンツを特定し、それをWebサイトまたはGoogleのインデックスから削除して、ランク付けの能力に悪影響を与えないようにする方法があります。
重複コンテンツとは何ですか?
重複するコンテンツは、同じコンテンツが一意のURLを持つ複数の場所に表示される場合に発生します。
コンテンツは、重複として登録するために完全に一致する必要はありません。Googleが「かなり類似している」と呼ぶものでもかまいません。 このコンテンツは、一部のテキストが異なる場合でも、本質的に「十分に近い」ため、重複コンテンツと見なされます。
ほとんどのサイト所有者は、コンテンツが新鮮でオリジナルであることを確認するために一生懸命働いていますが、それでもWeb上にはまだ多くの重複コンテンツがあります。 サイトの所有者が気づいていないこともあります。 では、これはどのように起こりますか?
重複コンテンツが発生するのはなぜですか?
Web上のほとんどの重複コンテンツは、印刷に適したバージョンのページ、複数の異なるURLにある、または複数の異なるURLによってリンクされている製品、同じページのデスクトップバージョンと削除されたモバイルバージョンを生成するディスカッションフォーラムなどのインデックス作成が原因で発生します。 。
しかし、それだけがあなたのサイトに重複したコンテンツをもたらす可能性のある方法ではありません。 重複コンテンツがサイトの内部および他のサイトの外部でどのように発生する可能性があるかについて、さらにいくつかの例を示します。
内部で生成された複製
かなり類似した製品ページ
特にeコマースでは、意図的にかなり類似したページを作成することが理にかなっている場合があります。 たとえば、2つの異なる国で同じ商品を販売するとします。 その場合、一方が米ドルで価格を表示し、もう一方がカナダドルで価格を表示する場合を除いて、2つのほぼ同じページを選択できます。
もう1つの例は、同じコピーを備えているためにかなり類似しているように見える製品ページですが、実際の違いは、製品の写真、製品名、および製品の価格が異なることだけです。
コンテンツ管理システム
コンテンツ管理システムは、あなたが気付かないかもしれない重複したコンテンツを作成することがあります。 一部のシステムでは、検索用のタグとURLパラメータが自動的に追加されるため、まったく同じコンテンツへの複数のパスが生成されます。
URLバリエーション
同じコンテンツを特徴とする異なるURLバリエーションがある場合は、コンテンツが重複する可能性もあります。 前述のように、コンテンツ管理システムはそれ自体でこれを行う場合があり、https://www.website.com/blog1とhttps://www.website.com/blogs/blog1のような2つのURLバリエーションが作成される可能性があります。 末尾のスラッシュや大文字のURLなどの他のURLのバリエーションでも、同じ問題が発生する可能性があります。
これが発生すると、Googleはランク付けするページを認識できず、一部の外部ソースがこれらのページの1つにリンクし、他のソースが複製にリンクして、プロセスでページのリンクの公平性を損なう可能性があります。
HTTPとHTTPSおよびwwwと非www
ほとんどのWebサイトには、wwwの有無にかかわらず、またはHTTPまたはHTTPSURLの両方でアクセスできます。 ただし、サイトを正しく構成していない場合、Googleは複数のページのページをインデックスに登録し、コンテンツが重複する可能性があります。
プリンターフレンドリーおよびモバイルフレンドリーURL
元のページとは異なるURLでホストされているプリンタ対応またはモバイル対応のページは、適切にインデックスが作成されていない限り、重複したコンテンツになります。
セッションID
セッションIDは、訪問者がサイトをチェックアウトしていることを追跡するための貴重なツールになります。 これは通常、長いセッションID文字列をURLに追加することによって行われます。 各セッションIDは一意であるため、これにより新しいURLが作成され、コンテンツが複製されます。
UTMパラメータ
パラメータは、さまざまなソースからの着信訪問者を追跡できます。 セッションIDと同様に、ページのコンテンツは同じですが、一意のURLを生成するため、インデックスを作成すると重複するコンテンツが作成されます。
外部で生成された複製
シンジケートコンテンツ
Web上の他のサイトにコンテンツをシンジケートすることは、Webサイトへのトラフィックを増やし、名前を広めるための優れた方法です。 ただし、適切な正規ヘッダータグでフォーマットされていない場合、このコンテンツは重複コンテンツとして表示される可能性があります。 たとえば、Mediumの記事に正規のタグを使用すると、元のコンテンツが重複として登録されないように保護できます。
盗作
ほとんどの重複コンテンツは本質的に悪意のないものですが、一部のWebマスターは、自分で作成していないコンテンツから利益を得ようと、意図的にコンテンツをコピーします。
重複コンテンツSEO:なぜそれが重要なのか?
重複コンテンツが頻繁に発生する場合、なぜそれが重要なのでしょうか。 検索結果で上位にランク付けする能力に影響を与える可能性のある5つの方法を次に示します。
1.Googleの重複コンテンツのペナルティ
Googleは、ほとんどの場合、重複するコンテンツに直接ペナルティを課すことはありません。 Googleが、サイト上の重複コンテンツが「欺瞞的」で「検索エンジンの結果を操作することを意図している」と判断した場合、重複コンテンツペナルティを適用することで措置を講じることがあります。 そのため、頻繁に発生することはありませんが、Googleの重複コンテンツのガイドラインによると、重複コンテンツが十分に悪質で、悪意を持って作成されたと思われる場合は、直接的なペナルティに対処することになります。
重複コンテンツに対するGoogleのペナルティはまれであるため、より差し迫った懸念は重複コンテンツとSEOの関係です。
2.インデックスブロート
インデックスの肥大化は、検索エンジンのクローラーが重要でないコンテンツや低品質のコンテンツにアクセスしてインデックスを作成するときに発生します。 これは、検索エンジンがユーザーに提案するコンテンツのバージョンを認識せず、希望するバージョンとは異なるバージョンをランク付けする可能性があるため、重要なページをランク付けする機能に影響を与えます。 また、クロールの予算にも影響します。
3.クロール予算
Googleは、サイトのクロールに費やす時間を制限しています。 Googleがサイトをクロールしてインデックスに登録するために提供するリソースの量は、クロールの予算です。 重複するコンテンツがたくさんある場合、それほど重要ではないページでクロール予算を浪費するリスクがあります。
4.キーワードの共食い
ページの複数のコピーがランク付けされている場合、ページは同じキーワードと可視性を求めて互いに競合します。 他のみんなと競争するのは十分難しいのですが、なぜ自分自身とも競争することでそれを難しくするのですか?
最終的には、SEOの重複コンテンツの問題を無視することはできません。 可能な限り、重複するコンテンツを統合または削除するようにしてください。
5.リンクエクイティの減少
グーグルがあなたのかなり類似したページの2つをランク付けすることに決めたとしましょう。 コンテンツのすべての価値を1つのページに帰するのか、それとも権限、リンクエクイティ、信頼を両方のページに分割する必要があるのかをどうやって知るのでしょうか。 この状況では、コンテンツのSEO値が低下し、パフォーマンスが低下する可能性があります。
他のサイトがリンクすることを選択したかどうかに応じて、バックリンクのリンクエクイティも2つのページに分割されます。
自分のサイトで重複コンテンツをチェックする方法
サイトで重複するコンテンツを見つけるのは無料で簡単です。 Screaming FrogとSitelinerの無料バージョンを使用して、サイトを系統的にクロールし、正確なページまたは重複しているページを特定します。
スクリーミングフロッグを使用して重複コンテンツを発見する方法
Screaming Frogは、Webサイトの重複コンテンツの問題を特定するのに役立つWebサイトクローラーおよびSEO監査ツールです。 ScreamingFrogを使用して最大500のURLを無料でスキャンする方法は次のとおりです。
1.SEOスパイダーでサイトをクロールする
まず、ScreamingFrogをダウンロードして開きます。 クロールするWebサイトのURLを[スパイダーへのURLを入力]フィールドに入力し、[開始]をクリックします。
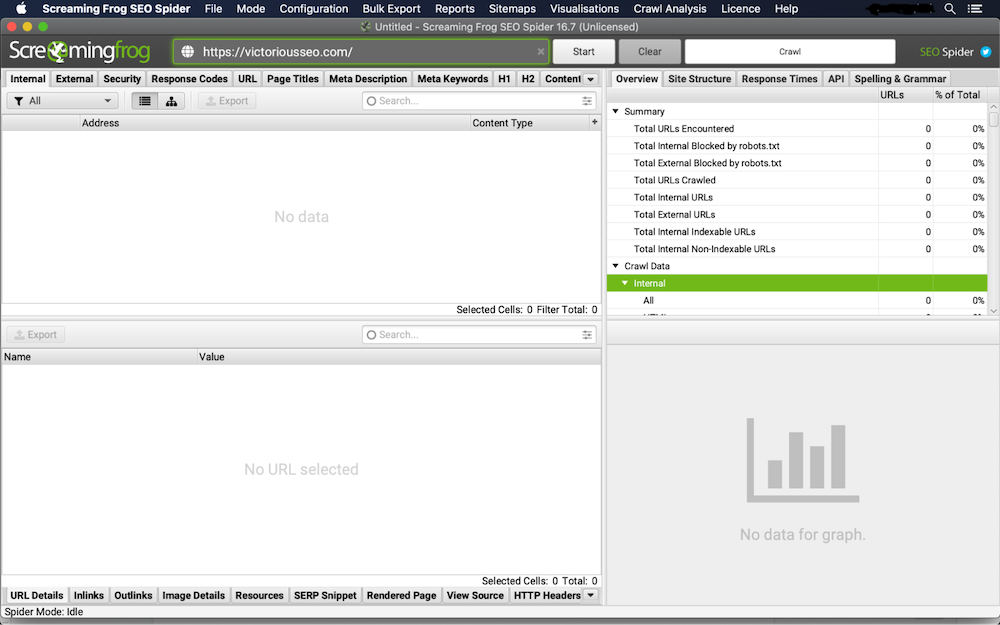
2.[コンテンツ]タブで重複を確認します
[コンテンツ]タブをクリックして、正確な重複とほぼ重複を確認します。 正確な重複をリアルタイムで確認できますが、「クロール分析」を実行して、ほぼ重複のリストを確認する必要があります。

3.ほぼ重複していないか確認します
メニューバーの[クロール分析]タブをクリックし、ドロップダウンメニューから[開始]を選択します。
クロール分析が終了すると、重複する列の近くにデータが入力されているのがわかります。 'analysis'プログレスバーが100%を読み取り、ほぼ重複するフィルターに'crawl analysis required'メッセージが表示されなくなるため、終了したことがわかります。
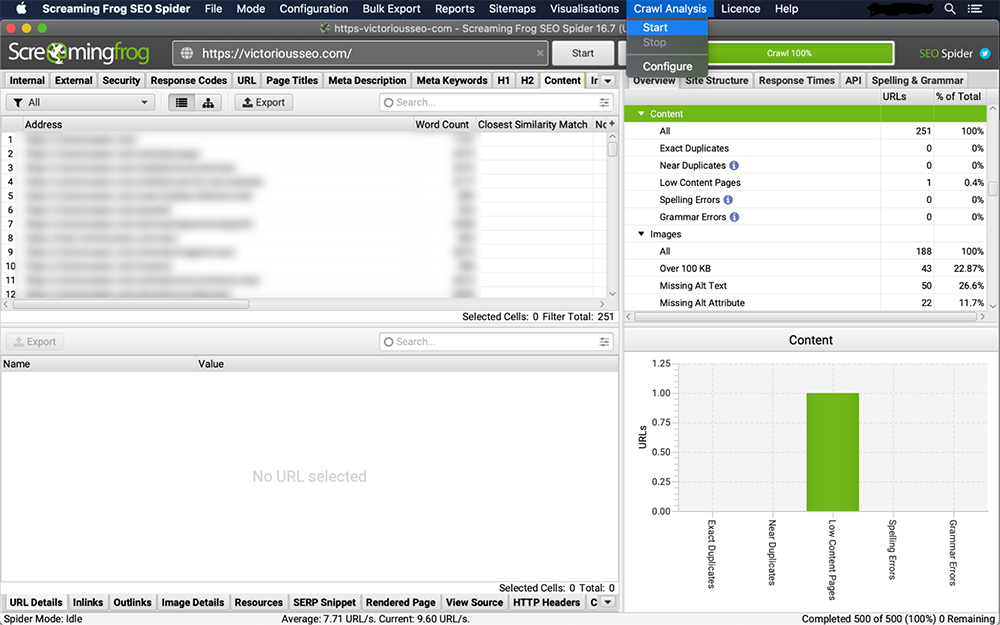
4.[コンテンツ]タブで重複を表示
'最も近い類似性の一致''いいえ。 クロール分析が完了すると、「重複の近く」および「アドレス」列にデータが入力されます。
'Exact Duplicates'フィルターは、HTMLコードスキャンに基づいて互いに同一のページを表示します。 設定された類似性しきい値は、「重複に近い」と見なされるものを決定します。 しきい値を変更するには、「構成」→「スパイダー」→「コンテンツ」に移動します。 このしきい値はデフォルトで90%に設定されていますが、自由に変更できます。

スキャンが完了したので、正確またはほぼ重複してポップアップするページを手動で確認します。
Sitelinerを使用して重複コンテンツを発見する方法
Sitelinerは、重複するコンテンツがないかWebサイト(または任意のWebサイト)をスキャンするために使用できるもう1つの無料ツールです。 ただし、無料版では30日ごとに1回の使用に制限され、結果の数は250ページに制限されます。 複数の検索を実行する必要がある場合、またはより多くの結果を表示したい場合は、プレミアムバージョンにサインアップしてください。
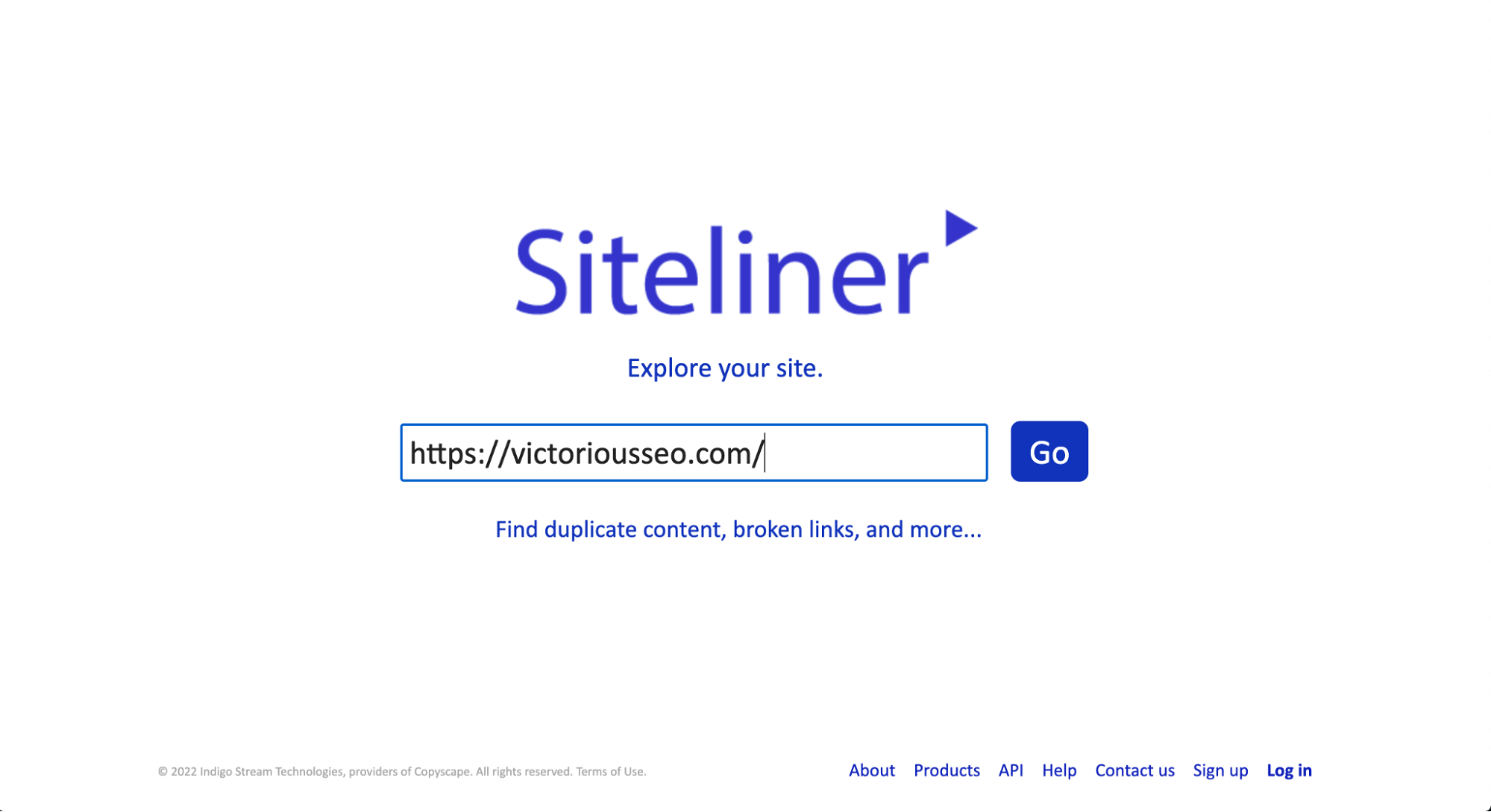
Sitelinerで重複コンテンツをチェックするには、検索するURLをホームページの検索ボックスに入力するだけです。
次に、Sitelinerはサイトのスイープを実行し、重複コンテンツがどれだけ見つかったかを通知し、それがあなたの最大の問題であると信じているものを強調します。 また、平均ページ読み込み時間、内部リンクと外部リンク、インバウンドリンクなど、SEOに役立つ指標を含むいくつかの指標も表示されます。
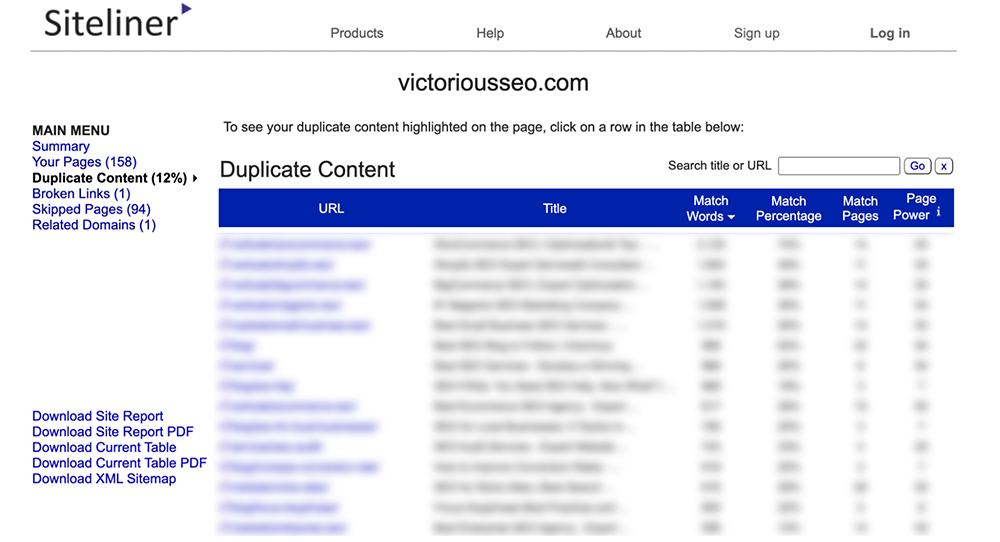
メインメニューの下にある[コンテンツの重複]をクリックして、Sitelineがコンテンツの重複として識別したページを確認します。
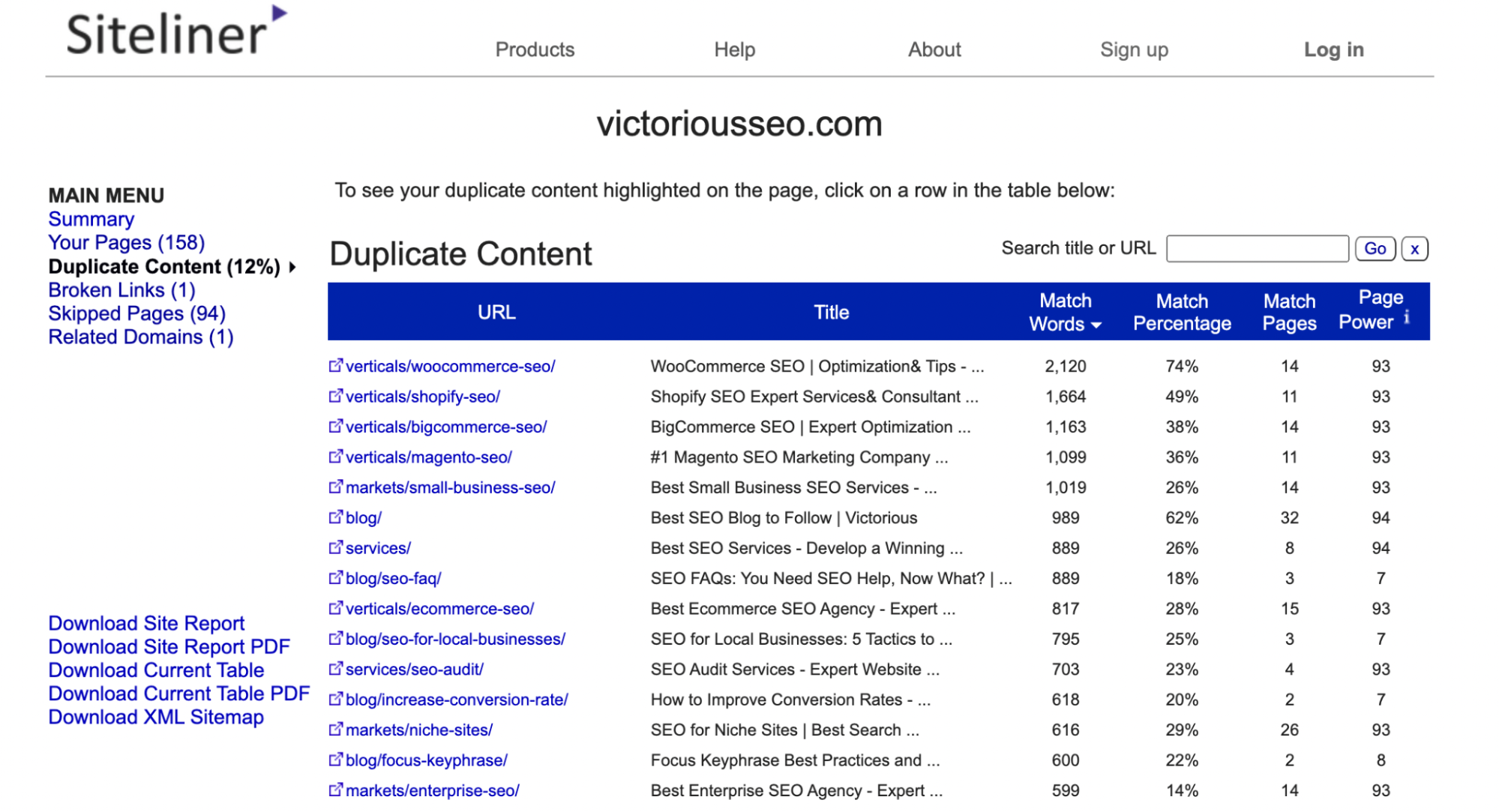
個々の行をクリックして、重複としてフラグが付けられているテキストを確認します。
注: Sitelineは、複数のページに表示されるヘッダーとフッターを重複コンテンツとして識別します。そのため、それぞれが同じメニューまたはフッターコンテンツを共有しているため、一致率が低いページが多数表示される場合があります。
他の誰かがあなたのコンテンツをコピーしたかどうかを確認する方法
Web上の他の誰かがあなたのコンテンツをコピーしたかどうかを確認するために使用できる重複コンテンツ検索ツールもあります。 Copyscapeは、効果的で使いやすい無料のWebサイトコンテンツチェッカーツールです。
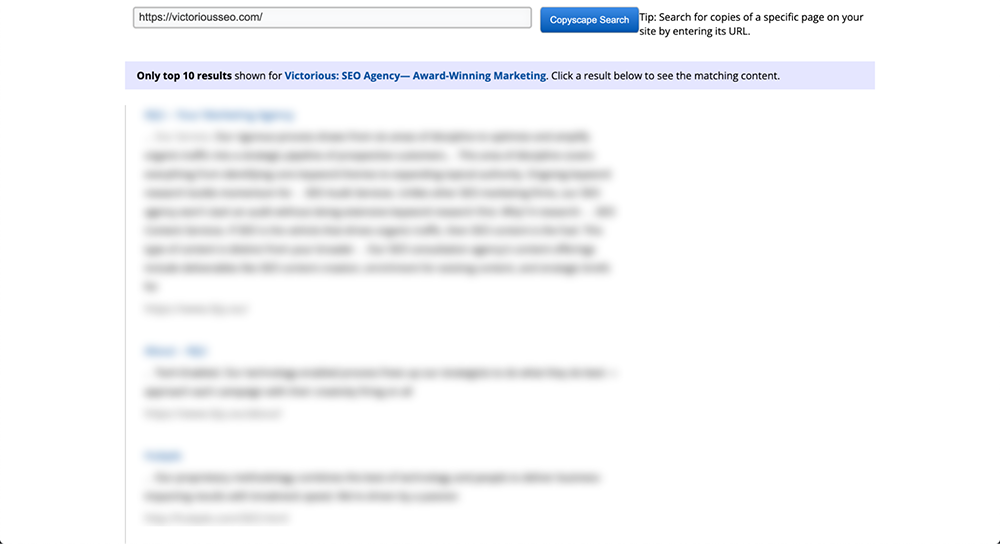
検索ボックスにURLを挿入し、そのすぐ横にある[実行]ボタンをクリックするだけです。 次に、CopyscapeはWeb全体の検索を実行して、同様のテキストコンテンツが他の場所に存在するかどうかを確認します。

何かが見つかった場合、Copyscapeは結果を返し、Googleの検索結果のようなリストにまとめます。 これにより、それらを簡単にスクロールして、コピーされたコンテンツの量を確認できます。 Googleの重複コンテンツチェッカーのようなものと考えることができます。
他の誰かがあなたのコンテンツを盗用しているのを見つけたら、あなたは何ができますか?
まず、Webサイトの所有者に連絡して、コンテンツを削除するか、Webサイトの元のコンテンツへの正規リンクを追加するように依頼します。 それでも問題が解決しない場合は、GoogleにDMCA削除リクエストを送信してください。
注:コンテンツを意図的にシンジケートし、他のWebサイトに公開を許可した場合でも、重複として表示されます。 そのため、検索エンジンのランキングで自分のページと競合しないようにするために、公開サイトに正規リンクまたはnoindexタグをページに含めるように要求することが重要です。
重複コンテンツを修正する方法
重複するコンテンツの問題を修正するには、Googleに元のバージョンとして認識させたいコピーを特定します。 また、重複するページを完全に削除するか、単にGoogleにインデックスを作成しないように指示するかを決定する必要があります。 決定した内容に応じて、重複するコンテンツをクリーンアップする方法がいくつかあります。
メタロボットタグとRobots.txtを使用したNoindex
重複コンテンツがSEOに与える影響を最小限に抑える方法のひとつは、メタロボットタグを変更して重複ページのインデックスを手動で解除することです。 これを行うには、meta robotsタグを使用し、その値を「noindex、follow」に設定します。 このタグを、検索結果から除外する各ページのHTML見出しに適用します。
meta robotsタグを使用すると、検索エンジンはそれが適用されているページ上のリンクをクロールできますが、検索クローラーがそれらをインデックスに含めることはできません。
インデックスに登録したくないのに、なぜGoogleがページをクロールできるようにするのですか? Googleは、サイト上の重複コンテンツへのクロールアクセスを制限しないように明示的に警告しているためです。 あなたが彼らにそれを索引付けさせたくないとしても、彼らはそれがそこにあることを知りたがっています。
HTMLコードに適用すると、noindexタグは次のようになります。
<head> [code] <meta name =” robots” content =” noindex、follow”>[必要に応じて他のコード]</ head>
メタロボットタグは、重複するコンテンツのインデックスを解除し、SEOの問題がウェブサイトにかなり類似した、または正確に重複するページを持つことを回避するためのシンプルで効果的な方法です。
Googleや他の検索エンジンによるインデックス作成をブロックするディレクトリ全体がある場合は、robots.txtファイルを編集します。
301リダイレクト
重複コンテンツの問題を処理する別の方法は、301リダイレクトを使用することです。 301は、トラフィックを重複ページから別のURLに転送する永続的なリダイレクトです。 301リダイレクトはSEOに対応しており、複数のページを1つのURLに結合して、リンクの公平性を統合するのに役立ちます。
301リダイレクトを使用すると、重複ページまたはかなり類似したページはトラフィックを受け入れなくなります。そのため、コンテンツの整理など、重複ページにアクセスできなくなっても問題がない場合にのみ使用してください。 それでもページにアクセスできるようにする場合は、メタロボットタグを使用してインデックスを作成します。
Rel Canonical
重複コンテンツを管理する別の方法は、rel=canonical属性を使用してページに優先順位を付けることです。 <head>HTMLタグ内にrel=canonical属性を配置して、特定のページが別のページのコピーとして存在し、このページに属するすべてのリンクとランキングパワーが実際にはcanonicalに起因することを検索エンジンに通知します。ページ。
rel = canonicalタグをHTMLコードに適用すると、次のようになります。
<head> [code] <link href =” URL OF PRIORITIZED PAGE” rel =” canonical” /> </ head>
自己参照の正規タグを使用して、特定のページを元のバージョンとして処理することを示すこともできます。
XMLサイトマップからURLを削除する
XMLサイトマップには、インデックスを作成するURLのみを含める必要があります。 サイトマップを自動的に更新する動的URLを使用していない場合は、サイトマップを手動で編集し、インデックスを作成しない、またはリダイレクトするURLを削除する必要があります。
Google検索コンソールでURLを削除する
ページをリダイレクトするか、インデックス作成を制限することを選択した場合は、そのURLをインデックスから削除するようGoogleにリクエストしてください。
Google検索コンソールにサインインし、左側のメニューから[削除]を選択します。
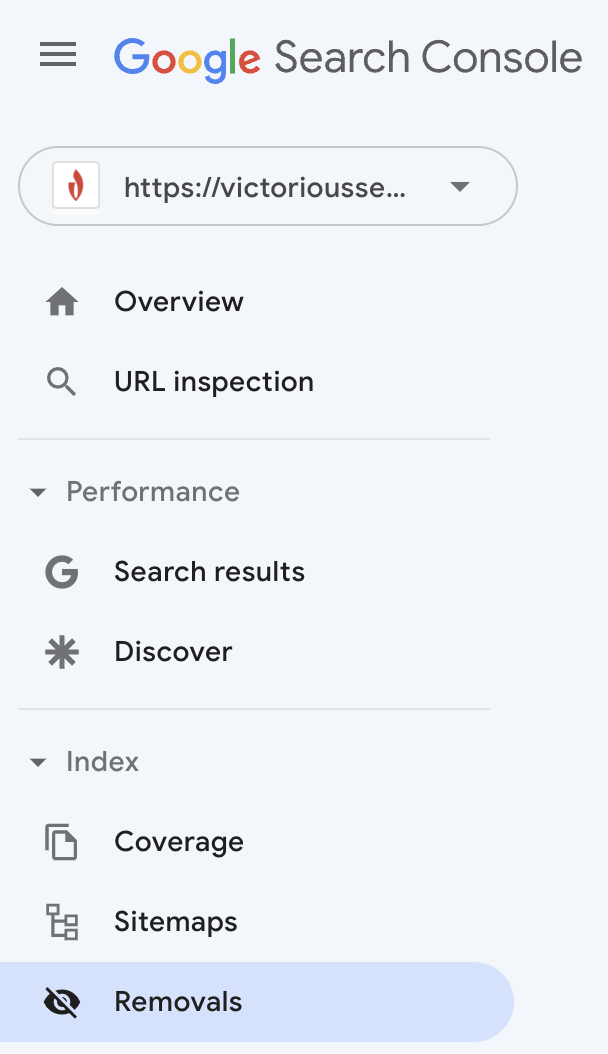
ボックスがポップアップ表示され、URLを送信するとGoogleのインデックスからわずか6か月間URLが削除されることが通知されます。 その後、GoogleがサイトをクロールしてURLを検出した場合、ロボットタグによってリダイレクトまたはブロックされていない限り、インデックスが再作成されます。 プレフィックスを共有する複数のURLがある場合は、プレフィックスを送信して、GoogleのインデックスからすべてのURLを一時的に削除することもできます。

6か月後、GoogleはURLのクロールを再試行します。 それらを適切にリダイレクトまたはインデックス付けしないと、検索エンジンの結果ページ(SERP)に表示されなくなります。
Tech SEOの問題を特定するのに助けが必要ですか?
あなたのサイトのランク付け能力を向上させたいですか? データドライブSEOエージェンシーと提携して、ウェブサイト上の技術的なSEOの問題を特定し、SERPを上るのに役立つ優れたSEO戦略を開発します。 今すぐ無料のSEO相談を予約して、私たちがあなたのために何ができるか見てみましょう!