
高性能应用程序的数据库设计最佳实践
已发表: 2021-07-19要使应用程序具有良好的性能,您需要强大的应用程序服务器、有保证且充足的带宽以及出色的编程工作。 但是有一个方面并不总是被考虑在内,它通常会对任何应用程序的性能产生很大影响:数据库设计。
我们现在将研究数据库设计最佳实践,以确保数据访问不是对应用程序性能产生负面影响的瓶颈。
一个好的数据库设计的目的是什么?
除了提高数据访问性能之外,良好的设计还可以获得其他好处,例如保持数据的一致性、准确性和可靠性,并通过消除冗余来减少存储空间。 良好设计的另一个好处是数据库更易于使用和维护。 任何必须管理它的人只需要查看实体关系图 (ERD) 即可了解其结构。
ERD 是数据库设计的基本工具。 它们可以在三个设计级别创建和可视化:概念、逻辑和物理。
概念设计显示了一个非常概括的图表,仅包含与项目利益相关者就标准达成一致所必需的元素,他们不需要了解数据库的技术细节。 逻辑设计以与数据库无关的方式详细显示实体及其关系。
您可以使用许多工具来促进从 ERD 设计数据库。 其中最好的是DbSchema 、 SqlDBM和Vertabelo 。
数据库架构
DbSchema 允许您直观地设计和管理 SQL、NoSQL 或云数据库。 该工具允许您在计算机上设计架构并将其部署到多个数据库并在 HTML5 图表中生成文档、编写查询以及可视化探索数据等。 它还提供模式同步、随机数据生成和自动完成的 SQL 代码编辑。

SqlDBM
SqlDBM 是最好的数据库图表设计工具之一,因为它提供了一种在任何浏览器中设计数据库的简单方法。 使用它不需要其他数据库引擎或建模工具,尽管 SqlDBM 允许您从现有数据库中导入模式。 它非常适合团队合作,因为它允许您与同事共享设计项目。
维塔贝洛
Vertabelo 是一个在线可视化数据库设计工具,可让您从逻辑上设计数据库并自动导出物理模式。 它可以逆向工程,从现有数据库生成图表,并通过区分所有者、编辑者和查看者的访问权限来控制对图表的访问。
最后,物理设计是向 ERD 添加所有必要细节的设计,以将其转变为特定 DBMS 中的可用数据库,例如 MySQL、MariaDB、MS SQL Server 或任何其他数据库。 让我们看一下在设计 ERD 时要牢记的最佳实践,以使生成的数据库发挥最佳作用。
定义要设计的数据库类型
通常区分两种基本类型的数据库:关系型和维度型。
关系数据库用于对数据执行事务的传统应用程序——也就是说,它们从数据库中获取信息、处理它并存储结果。
另一方面,维度数据库用于创建数据仓库:用于数据分析和数据挖掘以获得洞察力的大型信息存储库。
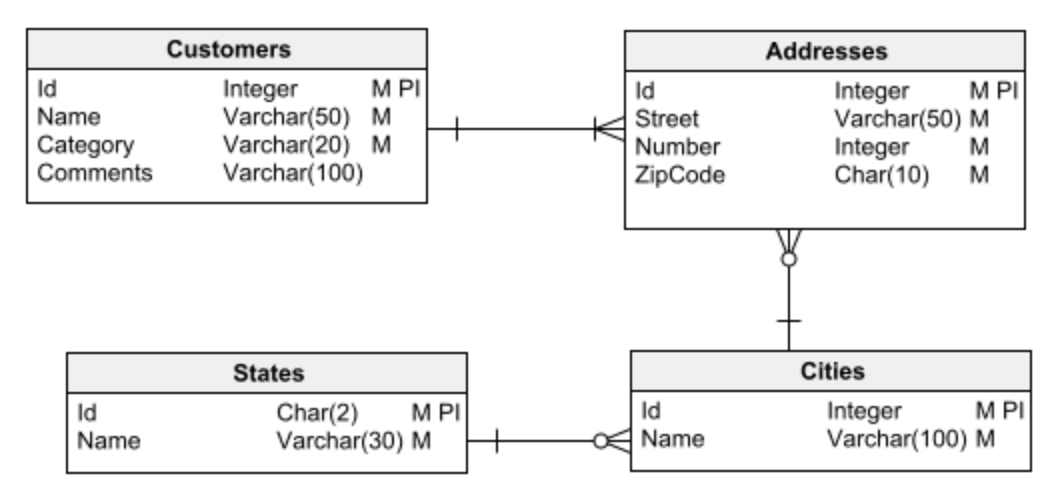
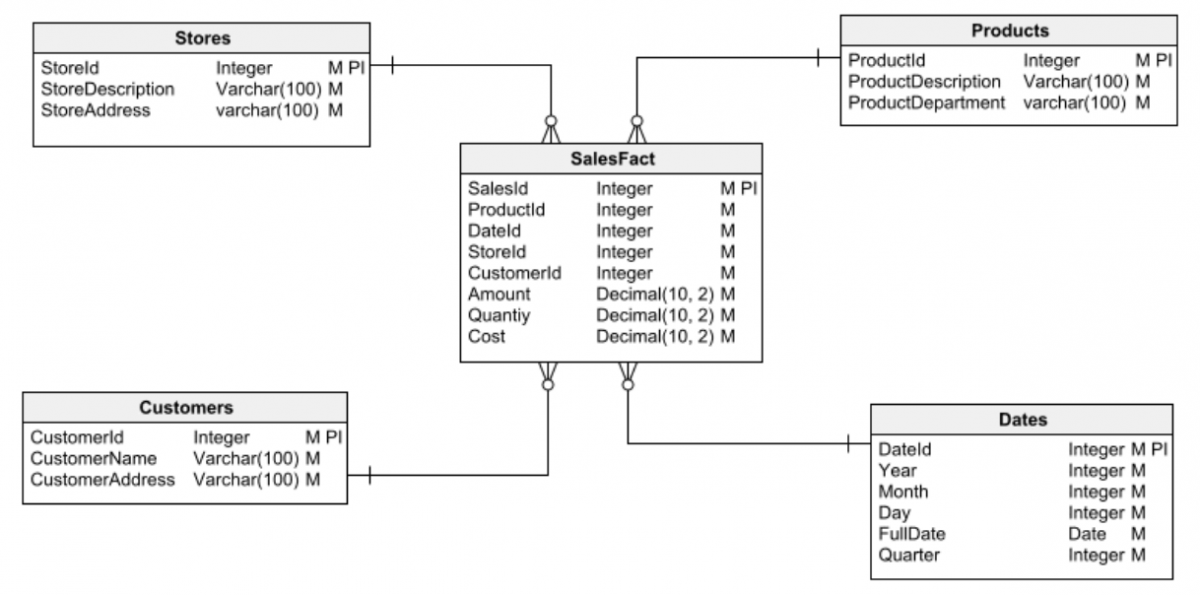
任何数据库设计任务的第一步都是选择两种主要数据库类型之一来使用:关系型或维度型。 在开始设计之前弄清楚这一点至关重要。 否则,您很容易陷入设计错误,最终会导致许多问题并且难以(或不可能)纠正。
采用命名约定
数据库设计中使用的名称是必不可少的,因为一旦在数据库中创建对象,更改其名称可能是致命的。 仅更改名称的一个字母可能会破坏依赖关系、关系甚至整个系统。
这就是为什么使用健康的命名约定至关重要:一组规则可以让您免于尝试 50 种不同的可能性来查找您不记得的对象的名称。
对于命名约定应该如何完成其工作,没有通用指南。 但重要的是在命名数据库中的任何对象之前建立命名约定并永远保持该约定。 命名约定建立了指导方针,例如是使用下划线分隔单词还是直接连接它们,是使用全部大写字母还是大写单词(Camel Case 风格),是使用复数还是单数来命名对象等等。
从概念设计开始,然后是逻辑设计,最后是物理设计。
这是事物的自然规律。 作为设计人员,您可能会倾向于直接在 DBMS 上创建对象以跳过步骤。 但这将阻止您拥有与利益相关者讨论以确保设计满足业务需求的工具。

在概念设计之后,您必须继续进行逻辑设计,以获得足够的文档来帮助程序员理解数据库结构。 保持逻辑设计更新以独立于要使用的数据库引擎是至关重要的。 这样,如果您最终将数据库迁移到不同的引擎,逻辑设计仍然有用。
最后,物理设计可以由程序员自己或 DBA 创建,采用逻辑设计并添加在特定 DBMS 上实现它所需的所有实现细节。
创建和维护数据字典
即使 ERD 清晰且具有描述性,您也应该添加数据字典以使其更加清晰。 数据字典在数据库设计中保持连贯性和一致性,特别是当其中的对象数量显着增长时。
数据字典的主要目的是维护有关数据模型实体及其属性的参考信息的单一存储库。 数据字典应包含所有实体的名称、所有属性的名称、它们的格式和数据类型,以及每个实体的简要说明。
数据字典为构成数据库的所有元素提供了清晰简洁的指南。 这避免了创建表示同一事物的多个对象,这使得当您需要查询或更新信息时很难知道使用哪个对象。
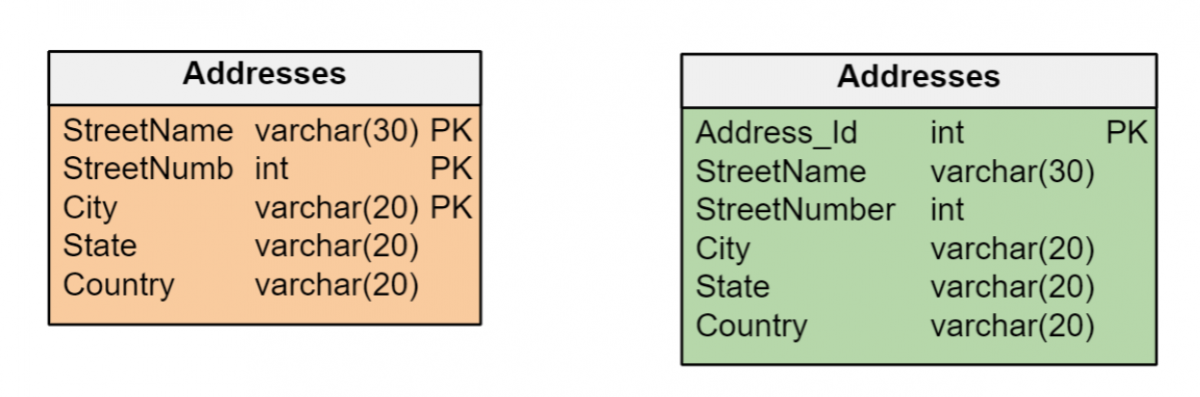
保持一致的主键标准
使用自然键或代理键的决定必须在数据模型中保持一致。 如果数据模型中的实体具有可以作为各自表的主键有效管理的唯一标识符,则无需创建代理键。
但是,实体通常由不同类型的多个属性(日期、数字和/或长字符串)来标识,这对于形成主键可能效率低下。 在这些情况下,最好创建整数类型的代理键,这样可以最大限度地提高索引管理效率。 如果实体缺少唯一标识它的属性,则代理键是唯一的选择。
为每个属性使用正确的数据类型。
某些数据让我们可以选择使用哪种数据类型来表示它们。 例如,日期。 我们可以选择将它们存储在日期类型字段、日期/时间类型字段、varchar 类型字段甚至数字类型字段中。 另一种情况是不用于数学运算但用于识别实体的数字数据,例如驾驶执照号码或邮政编码。
在日期的情况下,使用引擎的数据类型很方便,这使得操作数据更容易。 如果您只需要存储事件的日期而不指定时间,则要选择的数据类型将是简单的 Date; 如果您需要存储某个事件发生的日期和时间,则数据类型应为 DateTime。
使用其他类型(例如 varchar 或 numeric)来存储日期可能很方便,但仅限于非常特殊的情况。 例如,如果事先不知道日期将以何种格式表示,则将其存储为 varchar 会很方便。 如果搜索性能、排序或索引在处理日期类型字段时至关重要,则之前转换为浮点数可能会有所不同。
不涉及数学运算的数字数据应表示为 varchar,在记录中应用格式验证以避免不一致或重复。 否则,您将面临某些数据超出数字字段限制的风险,并迫使您在设计已经投入生产时对其进行重构。
查找表的使用
一些没有经验的设计者可能认为过度使用查找表来规范化设计会使数据库的 ERD 不必要地复杂化,因为它添加了大量的“卫星”表,这些表有时只包含少量元素。 那些认为这一点的人应该明白,使用查找表的好处多于坏处。 如果 ERD 的复杂性或大小是一个问题,有一些 ERD 设计工具可以让您以不同的方式可视化图表,以便理解它们,尽管它们很复杂。
此示例查询说明了在精心设计的数据库中正确使用查找表:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateId在这种情况下,我们使用 Cities 和 States 的查找表。
查找表的好处包括减少数据库的大小、提高搜索性能以及对字段可以包含的有效数据集施加限制等。 对于所有查找表来说,最好包含一个 Bit 或 Boolean 字段来指示表中的记录是正在使用还是已过时。 此字段可用作过滤器,以避免将过时的元素作为应用程序 UI 中的选项。
根据数据库类型进行规范化或反规范化
在用于传统应用程序的关系数据库中,规范化是必须的。 众所周知,标准化通过避免冗余来减少所需的存储空间。 它提高了信息的质量,并提供了多种工具来优化复杂查询的性能。
然而,在其他类型的数据库中,应用了一种称为非规范化的技术。 在用作数据仓库的维度数据库中,非规范化在模式表中添加了某些有用的冗余信息。
尽管它们似乎是相反的概念,但非规范化并不意味着取消规范化。 它实际上是一种在规范化数据模型后应用于数据模型以简化查询编写和报告的优化技术。
在零件中设计物理模型
在软件开发项目中,数据库设计人员向利益相关者展示了一个大型概念模型,其中没有显示实现细节。 反过来,为了与开发人员合作,设计人员必须提供一个物理模型,其中包含每个实体和属性的所有细节。 但是,这两个模型都不需要在项目开始时完全创建。
在应用敏捷方法时,每个开发周期开始时的每个开发人员都会在该周期内处理一个或多个用户故事。 数据库设计人员的工作是为每个开发人员提供一个物理子模型,该子模型仅包含他们工作单元所需的对象。
在每个开发周期结束时,将在该周期中创建的子模型合并,以便完整的物理模型与应用程序的开发并行形成。
善用视图和索引
视图和索引是数据库设计中用于提高应用程序性能的两个基本工具。 视图的使用允许处理简化查询的抽象,隐藏不必要的表细节。 反过来,视图使数据库引擎的查询优化任务更容易,因为它们允许它们预测如何获取数据并选择最佳策略以更快地提供查询结果。
一旦数据库投入生产,索引可以根据用户体验提高慢查询的性能。 但是,索引创建可以作为数据库设计任务的一部分来完成,预测应用程序的需求。
对于创建索引,您需要大致了解每个表的大小(就记录数而言),然后为更大的表创建索引。 要选择要包含在索引中的字段,您必须主要考虑表示外键的字段以及将在搜索中用作过滤器的字段。
当你认为工作已经完成时,是时候重构了。
数据库的设计总是可以改进的。 当由于新需求或新业务需求而没有对数据库进行更改时,这是执行改进设计的重构过程的好机会。 重构的意思很简单:在不影响数据库语义的情况下引入改进设计的更改。
有许多重构技术可以改进数据库的设计,但超出了本文的范围,但最好知道它们的存在以便在需要时使用它们。
每当您需要设计数据库时,手头有此最佳实践列表将使您获得最佳结果,以便应用程序始终保持数据访问的最佳性能。