
Najlepsze praktyki projektowania baz danych dla aplikacji o wysokiej wydajności
Opublikowany: 2021-07-19Aby aplikacja miała dobrą wydajność, potrzebujesz wydajnego serwera aplikacji, gwarantowanej i dużej przepustowości oraz dobrze wykonanej pracy programistycznej. Ale jest jeden aspekt, który nie zawsze jest brany pod uwagę i który zwykle ma duży wpływ na wydajność każdej aplikacji: projekt bazy danych .
Przyjrzymy się teraz najlepszym praktykom projektowania baz danych, aby upewnić się, że dostęp do danych nie jest wąskim gardłem, które negatywnie wpływa na wydajność aplikacji.
Jaki jest cel dobrego projektu bazy danych?
Oprócz poprawy wydajności dostępu do danych, dobry projekt zapewnia inne korzyści, takie jak zachowanie spójności danych, dokładności i niezawodności oraz zmniejszenie przestrzeni dyskowej poprzez eliminację nadmiarowości. Kolejną zaletą dobrego projektu jest to, że baza danych jest łatwiejsza w użyciu i utrzymaniu. Każdy, kto musi nim zarządzać, będzie musiał tylko spojrzeć na diagram relacji encji (ERD), aby zrozumieć jego strukturę.
ERD są podstawowym narzędziem projektowania baz danych. Można je tworzyć i wizualizować na trzech poziomach projektowania: koncepcyjnym , logicznym i fizycznym .
Projekt koncepcyjny przedstawia bardzo zwięzły diagram, zawierający tylko elementy niezbędne do uzgodnienia kryteriów z interesariuszami projektu, którzy nie muszą rozumieć szczegółów technicznych bazy danych. Projekt logiczny pokazuje szczegółowo jednostki i ich relacje, ale w sposób niezależny od bazy danych.
Istnieje wiele narzędzi, których możesz użyć, aby ułatwić projektowanie baz danych z ERD. Wśród najlepszych są DbSchema , SqlDBM i Vertabelo .
Schemat Db
DbSchema umożliwia wizualne projektowanie i zarządzanie bazami danych SQL, NoSQL lub Cloud. Narzędzie umożliwia m.in. zaprojektowanie schematu na komputerze i wdrożenie go w wielu bazach danych oraz generowanie dokumentacji na diagramach HTML5, pisanie zapytań i wizualną eksplorację danych. Oferuje również synchronizację schematów, losowe generowanie danych i edycję kodu SQL z automatycznym uzupełnianiem.

SqlDBM
SqlDBM jest jednym z najlepszych narzędzi do projektowania diagramów baz danych, ponieważ zapewnia łatwy sposób projektowania bazy danych w dowolnej przeglądarce. Żaden inny aparat bazy danych ani narzędzia do modelowania nie są wymagane, aby z niego korzystać, chociaż SqlDBM umożliwia importowanie schematu z istniejącej bazy danych. Jest idealny do pracy zespołowej, ponieważ umożliwia udostępnianie projektów projektowych współpracownikom.
Vertabelo
Vertabelo to narzędzie do wizualnego projektowania baz danych online, które pozwala logicznie zaprojektować bazę danych i automatycznie uzyskać fizyczny schemat. Może odtwarzać inżynierię wsteczną, generować diagramy z istniejących baz danych i kontrolować dostęp do diagramów poprzez różnicowanie uprawnień dostępu dla właścicieli, redaktorów i przeglądających.
Wreszcie, projekt fizyczny to taki, który dodaje do ERD wszystkie niezbędne szczegóły, aby przekształcić go w użyteczną bazę danych w określonym DBMS, takim jak MySQL, MariaDB, MS SQL Server lub jakikolwiek inny. Przyjrzyjmy się najlepszym praktykom, o których należy pamiętać podczas projektowania ERD, aby wynikowa baza danych działała jak najlepiej.
Zdefiniuj typ bazy danych do zaprojektowania
Zwykle wyróżnia się dwa podstawowe typy baz danych: relacyjne i wymiarowe .
Relacyjne bazy danych są wykorzystywane w tradycyjnych aplikacjach, które wykonują transakcje na danych – czyli pobierają informacje z bazy danych, przetwarzają je i przechowują wyniki.
Z drugiej strony, bazy danych wymiarowych są wykorzystywane do tworzenia hurtowni danych: dużych repozytoriów informacji do analizy danych i eksploracji danych w celu uzyskania wglądu.
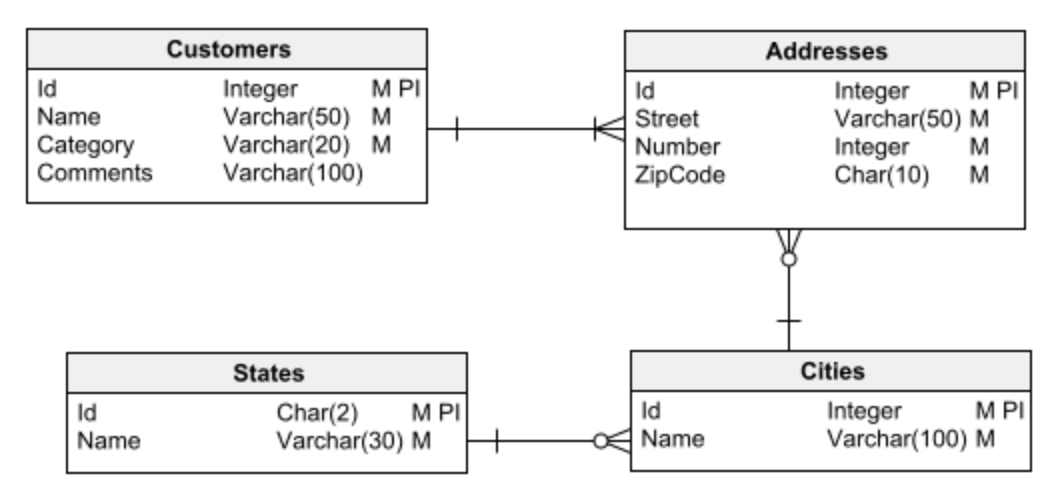
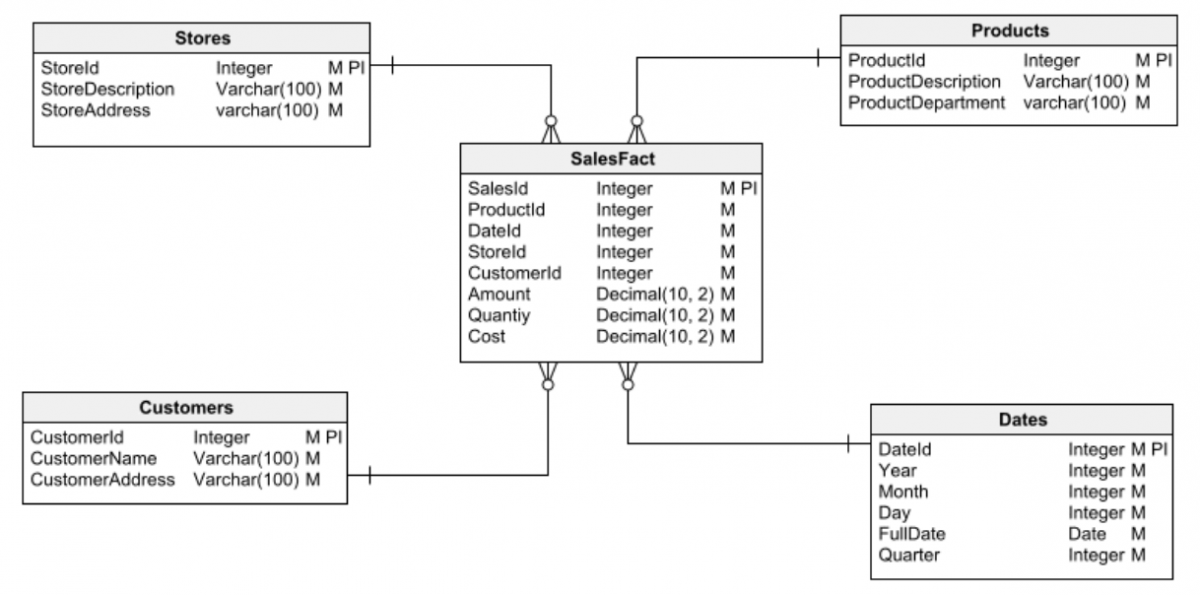
Pierwszym krokiem w każdym zadaniu projektowania bazy danych jest wybór jednego z dwóch głównych typów baz danych do pracy: relacyjnej lub wymiarowej. Przed przystąpieniem do projektowania ważne jest, aby to było jasne. W przeciwnym razie możesz łatwo popaść w błędy projektowe, które ostatecznie doprowadzą do wielu problemów i będą trudne (lub niemożliwe) do naprawienia.
Przyjęcie konwencji nazewnictwa
Nazwy używane w projekcie bazy danych są niezbędne, ponieważ po utworzeniu obiektu w bazie danych zmiana jego nazwy może być fatalna. Zmiana tylko jednej litery nazwy może zerwać zależności, relacje, a nawet całe systemy.
Dlatego tak ważne jest, aby pracować ze zdrową konwencją nazewnictwa: zestawem reguł, które oszczędzą Ci kłopotu z wypróbowaniem 50 różnych możliwości znalezienia nazwy obiektu, którego nie pamiętasz.
Nie ma uniwersalnego przewodnika po tym, czym powinna być konwencja nazewnictwa, aby spełniała swoje zadanie. Ale ważne jest, aby ustalić konwencję nazewnictwa przed nazwaniem dowolnego obiektu w bazie danych i zachowaniem tej konwencji na zawsze. Konwencja nazewnictwa określa wytyczne, takie jak używanie podkreślenia do oddzielania słów lub ich bezpośredniego łączenia, czy używać wszystkich wielkich liter, czy używać wielkich liter (w stylu Camel Case), czy używać słów w liczbie mnogiej lub pojedynczej do nazywania obiektów i tak dalej.
Zacznij od projektu koncepcyjnego, następnie projektu logicznego, a na końcu projektu fizycznego.
Taki jest naturalny porządek rzeczy. Jako projektant możesz ulec pokusie, aby zacząć od tworzenia obiektów bezpośrednio w DBMS, aby pominąć kroki. Uniemożliwi to jednak posiadanie narzędzia do omówienia z interesariuszami, aby upewnić się, że projekt spełnia wymagania biznesowe.
Po projekcie koncepcyjnym musisz przejść do projektu logicznego, aby mieć odpowiednią dokumentację, która pomoże programistom zrozumieć strukturę bazy danych. Ważne jest, aby projekt logiczny był aktualizowany, aby był niezależny od używanego silnika bazy danych. W ten sposób, jeśli ostatecznie zmigrujesz bazę danych do innego silnika, projekt logiczny nadal będzie przydatny.
Wreszcie, fizyczny projekt może być stworzony przez samych programistów lub DBA, biorąc logiczny projekt i dodając wszystkie szczegóły implementacji potrzebne do wdrożenia go w konkretnym DBMS.
Twórz i zarządzaj słownikiem danych
Nawet jeśli ERD jest jasne i opisowe, powinieneś dodać słownik danych, aby był jeszcze bardziej przejrzysty. Słownik danych zachowuje spójność i spójność w projekcie bazy danych, zwłaszcza gdy liczba znajdujących się w niej obiektów znacząco rośnie.
Głównym celem słownika danych jest utrzymanie pojedynczego repozytorium informacji referencyjnych o jednostkach modelu danych i jego atrybutach. Słownik danych powinien zawierać nazwy wszystkich podmiotów, nazwy wszystkich atrybutów, ich formaty i typy danych oraz krótki opis każdego z nich.

Słownik danych zapewnia jasny i zwięzły przewodnik po wszystkich elementach składających się na bazę danych. Pozwala to uniknąć tworzenia wielu obiektów reprezentujących tę samą rzecz, co utrudnia określenie, do którego obiektu należy się odwołać, gdy trzeba wykonać zapytanie lub zaktualizować informacje.
Utrzymuj spójne kryteria dla kluczy podstawowych
Decyzja o użyciu kluczy naturalnych lub kluczy zastępczych musi być spójna w ramach modelu danych. Jeśli jednostki w modelu danych mają unikatowe identyfikatory, którymi można efektywnie zarządzać jako klucze podstawowe odpowiednich tabel, nie ma potrzeby tworzenia kluczy zastępczych.
Jednak często zdarza się, że jednostki są identyfikowane za pomocą wielu atrybutów różnych typów – dat, liczb i/lub długich ciągów znaków – co może być nieefektywne przy tworzeniu kluczy podstawowych. W takich przypadkach lepiej jest tworzyć klucze zastępcze typu liczb całkowitych, które zapewniają maksymalną wydajność w zarządzaniu indeksami. A klucz zastępczy jest jedyną opcją, jeśli encji brakuje atrybutów, które jednoznacznie ją identyfikują.
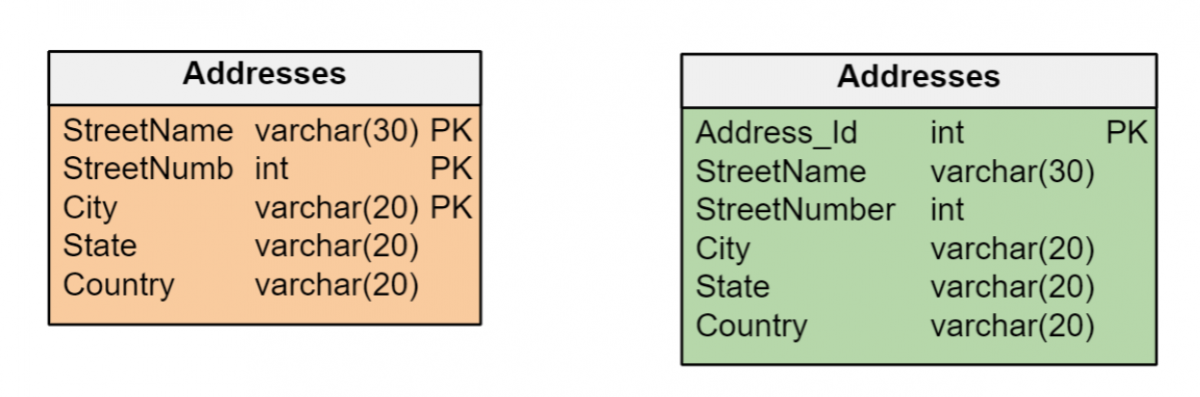
Użyj poprawnych typów danych dla każdego atrybutu.
Niektóre dane dają nam możliwość wyboru typu danych do ich reprezentowania. Na przykład daty. Możemy wybrać przechowywanie ich w polach typu data, pola typu data/godzina, pola typu varchar, a nawet pola typu numerycznego. Innym przypadkiem są dane liczbowe, które nie są wykorzystywane do operacji matematycznych, ale do identyfikacji podmiotu, takiego jak numer prawa jazdy lub kod pocztowy.
W przypadku dat wygodnie jest skorzystać z typu danych silnika, co ułatwia manipulowanie danymi. Jeśli chcesz przechowywać tylko datę zdarzenia bez określania czasu, typem danych do wyboru będzie po prostu Data; jeśli musisz przechowywać datę i godzinę wystąpienia określonego zdarzenia, typem danych powinien być DateTime.
Używanie innych typów, takich jak varchar lub numeryczne, do przechowywania dat może być wygodne, ale tylko w bardzo szczególnych przypadkach. Na przykład, jeśli nie wiadomo z góry, w jakim formacie zostanie wyrażona data, wygodnie jest zapisać ją jako varchar. Jeśli wydajność wyszukiwania, sortowanie lub indeksowanie ma kluczowe znaczenie w obsłudze pól typu daty, poprzednia konwersja na zmiennoprzecinkową może mieć znaczenie.
Dane liczbowe niezwiązane z operacjami matematycznymi należy przedstawiać jako varchar, stosując walidację formatu w nagraniu, aby uniknąć niespójności lub powtórzeń. W przeciwnym razie narażasz się na ryzyko, że niektóre dane przekroczą ograniczenia pól numerycznych i zmuszą Cię do refaktoryzacji projektu, gdy jest już w produkcji.
Korzystanie z tabel przeglądowych
Niektórzy niedoświadczeni projektanci mogą sądzić, że nadmierne użycie tabel przeglądowych do normalizacji projektu może niepotrzebnie skomplikować ERD bazy danych, ponieważ dodaje dużą liczbę „satelitarnych” tabel, które czasami nie zawierają więcej niż garść elementów. Ci, którzy tak myślą, powinni zrozumieć, że korzystanie z tabel przeglądowych ma znacznie więcej zalet niż wad. Jeśli złożoność lub rozmiar ERD stanowi problem, istnieją narzędzia projektowe ERD, które umożliwiają wizualizację diagramów na różne sposoby, aby były zrozumiałe pomimo ich złożoności.
To przykładowe zapytanie ilustruje prawidłowe użycie tabel przeglądowych w dobrze zaprojektowanej bazie danych:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdW tym przypadku używamy tabel wyszukiwania dla miast i stanów.
Korzyści z tabel przeglądowych obejmują między innymi zmniejszenie rozmiaru bazy danych, poprawę wydajności wyszukiwania i nałożenie ograniczeń na poprawny zestaw danych, który może zawierać pole. Dobrą praktyką jest również, aby wszystkie tabele przeglądowe zawierały pole Bit lub pole logiczne, które wskazuje, czy rekord w tabeli jest używany, czy jest przestarzały. To pole może służyć jako filtr, aby uniknąć przestarzałych elementów jako opcji w interfejsie użytkownika aplikacji.
Normalizuj lub denormalizuj zgodnie z typem bazy danych
W relacyjnych bazach danych wykorzystywanych do tradycyjnych aplikacji normalizacja jest koniecznością. Powszechnie wiadomo, że normalizacja zmniejsza wymaganą przestrzeń do przechowywania poprzez unikanie nadmiarowości. Poprawia jakość informacji i udostępnia wiele narzędzi do optymalizacji wydajności w złożonych zapytaniach.
Jednak w innych typach baz danych stosowana jest technika znana jako denormalizacja. W wielowymiarowych bazach danych, używanych jako hurtownie danych, denormalizacja dodaje pewne przydatne, nadmiarowe informacje do tabel schematów.
Chociaż wydają się być pojęciami przeciwstawnymi, denormalizacja nie oznacza cofnięcia normalizacji. W rzeczywistości jest to technika optymalizacji stosowana do modelu danych po znormalizowaniu go w celu uproszczenia pisania zapytań i raportowania.
Projektowanie modeli fizycznych w częściach
W projekcie tworzenia oprogramowania projektant bazy danych przedstawia zainteresowanym stronom wielkoskalowy model koncepcyjny, w którym nie są wyświetlane żadne szczegóły implementacji. Z kolei, aby pracować z programistami, projektant musi dostarczyć fizyczny model ze wszystkimi szczegółami każdej encji i atrybutu. Jednak oba modele nie muszą być w całości tworzone na początku projektu.
Stosując metodyki zwinne, każdy programista na początku każdego cyklu rozwojowego wykorzystuje jedną lub więcej historyjek użytkownika do pracy w trakcie tego cyklu. Zadaniem projektanta bazy danych jest udostępnienie każdemu programiście fizycznego podmodelu, który zawiera tylko te obiekty, których potrzebuje w jednostce pracy.
Pod koniec każdego cyklu rozwojowego podmodele utworzone podczas tego cyklu są łączone, dzięki czemu kompletny model fizyczny nabiera kształtu równolegle do rozwoju aplikacji.
Dobre wykorzystanie widoków i indeksów
Widoki i indeksy to dwa podstawowe narzędzia w projektowaniu baz danych, które poprawiają wydajność aplikacji. Wykorzystanie widoków pozwala na obsługę abstrakcji, które upraszczają zapytania, ukrywając niepotrzebne szczegóły tabel. Z kolei widoki ułatwiają wykonywanie zadań optymalizacji zapytań dla silników baz danych, ponieważ umożliwiają im przewidywanie sposobu pozyskiwania danych i wybieranie najlepszych strategii w celu szybszego dostarczania wyników zapytań.
Indeksy mogą poprawić wydajność powolnego zapytania w oparciu o środowisko użytkownika, gdy baza danych jest już w środowisku produkcyjnym. Jednak tworzenie indeksu można wykonać w ramach zadań projektowych bazy danych, przewidując potrzeby aplikacji.
Aby utworzyć indeksy, musisz mieć przybliżone pojęcie o wielkości każdej tabeli – pod względem liczby rekordów – a następnie utworzyć indeksy dla większych tabel. Aby wybrać pola do uwzględnienia w indeksie, należy wziąć pod uwagę głównie te reprezentujące klucze obce oraz te, które będą używane jako filtry w wyszukiwaniu.
Kiedy myślisz, że praca jest skończona, nadszedł czas na refaktoryzację.
Projekt bazy danych zawsze można ulepszyć. Gdy nie ma zmian w bazie danych ze względu na nowe wymagania lub nowe potrzeby biznesowe, jest to dobra okazja do przeprowadzenia procedur refaktoryzacji usprawniających projekt. Refaktoryzacja oznacza po prostu: wprowadzanie zmian, które ulepszają projekt bez wpływu na semantykę bazy danych.
Istnieje wiele technik refaktoryzacji służących do ulepszenia projektu bazy danych, które wykraczają poza zakres tego artykułu, ale dobrze jest wiedzieć o ich istnieniu, aby móc z nich korzystać w razie potrzeby.
Posiadanie tej listy najlepszych praktyk zawsze pod ręką, gdy trzeba zaprojektować bazę danych, pozwoli uzyskać najlepsze wyniki, dzięki czemu aplikacje zawsze będą zachowywać optymalną wydajność w dostępie do danych.