
Mejores prácticas de diseño de base de datos para aplicaciones de alto rendimiento
Publicado: 2021-07-19Para que una aplicación tenga un buen rendimiento, se necesita un servidor de aplicaciones potente, un ancho de banda amplio y garantizado, y un trabajo de programación bien hecho. Pero hay un aspecto que no siempre se tiene en cuenta y que suele tener un gran impacto en el rendimiento de cualquier aplicación: el diseño de la base de datos .
Ahora veremos las mejores prácticas de diseño de bases de datos para garantizar que el acceso a los datos no sea un cuello de botella que afecte negativamente el rendimiento de la aplicación.
¿Cuál es el propósito de un buen diseño de base de datos?
Además de mejorar el rendimiento del acceso a los datos, un buen diseño logra otros beneficios, como mantener la consistencia, precisión y confiabilidad de los datos y reducir el espacio de almacenamiento al eliminar las redundancias. Otro beneficio de un buen diseño es que la base de datos es más fácil de usar y mantener. Cualquiera que tenga que administrarlo solo necesitará mirar el diagrama entidad-relación (ERD) para comprender su estructura.
Los ERD son la herramienta fundamental del diseño de bases de datos. Se pueden crear y visualizar en tres niveles de diseño: conceptual , lógico y físico .
El diseño conceptual muestra un diagrama muy resumido, con solo los elementos necesarios para acordar criterios con los actores del proyecto, quienes no necesitan entender los detalles técnicos de la base de datos. El diseño lógico muestra las entidades y sus relaciones en detalle pero de forma independiente de la base de datos.
Existen muchas herramientas que puede utilizar para facilitar el diseño de bases de datos a partir de ERD. Entre los mejores se encuentran DbSchema , SqlDBM y Vertabelo .
EsquemaDb
DbSchema le permite diseñar y administrar visualmente bases de datos SQL, NoSQL o en la nube. La herramienta le permite diseñar el esquema en una computadora e implementarlo en múltiples bases de datos y generar documentación en diagramas HTML5, escribir consultas y explorar visualmente los datos, entre otros. También ofrece sincronización de esquemas, generación de datos aleatorios y edición de código SQL con finalización automática.

SqlDBM
SqlDBM es una de las mejores herramientas de diseño de diagramas de bases de datos porque proporciona una manera fácil de diseñar su base de datos en cualquier navegador. No se requiere ningún otro motor de base de datos o herramientas de modelado para usarlo, aunque SqlDBM le permite importar un esquema de una base de datos existente. Es ideal para el trabajo en equipo, ya que te permite compartir proyectos de diseño con compañeros de trabajo.
Vertabelo
Vertabelo es una herramienta de diseño de base de datos visual en línea que le permite diseñar una base de datos de forma lógica y derivar automáticamente el esquema físico. Puede realizar ingeniería inversa, generar diagramas a partir de bases de datos existentes y controlar el acceso a los diagramas al diferenciar los privilegios de acceso para propietarios, editores y lectores.
Finalmente, el diseño físico es el que le agrega al ERD todos los detalles necesarios para convertirlo en una base de datos usable en un DBMS particular, como MySQL, MariaDB, MS SQL Server, o cualquier otro. Echemos un vistazo a las mejores prácticas a tener en cuenta al diseñar un ERD para que la base de datos resultante funcione de la mejor manera.
Definir el tipo de base de datos a diseñar
Se suelen distinguir dos tipos fundamentales de bases de datos: relacionales y dimensionales .
Las bases de datos relacionales se utilizan para aplicaciones tradicionales que ejecutan transacciones en los datos, es decir, obtienen información de la base de datos, la procesan y almacenan los resultados.
Por otro lado, las bases de datos Dimensional se utilizan para la creación de data warehouses: grandes repositorios de información para el análisis de datos y la minería de datos para obtener insights.
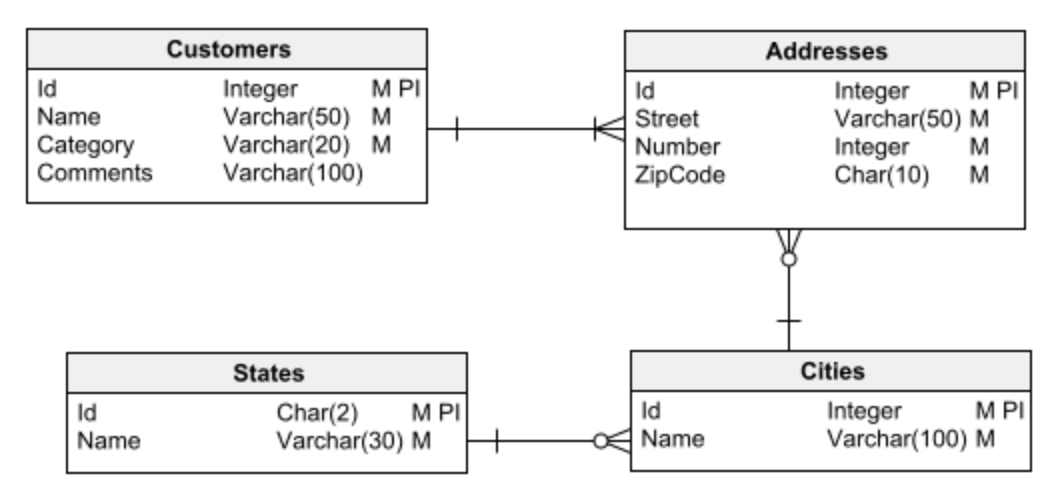
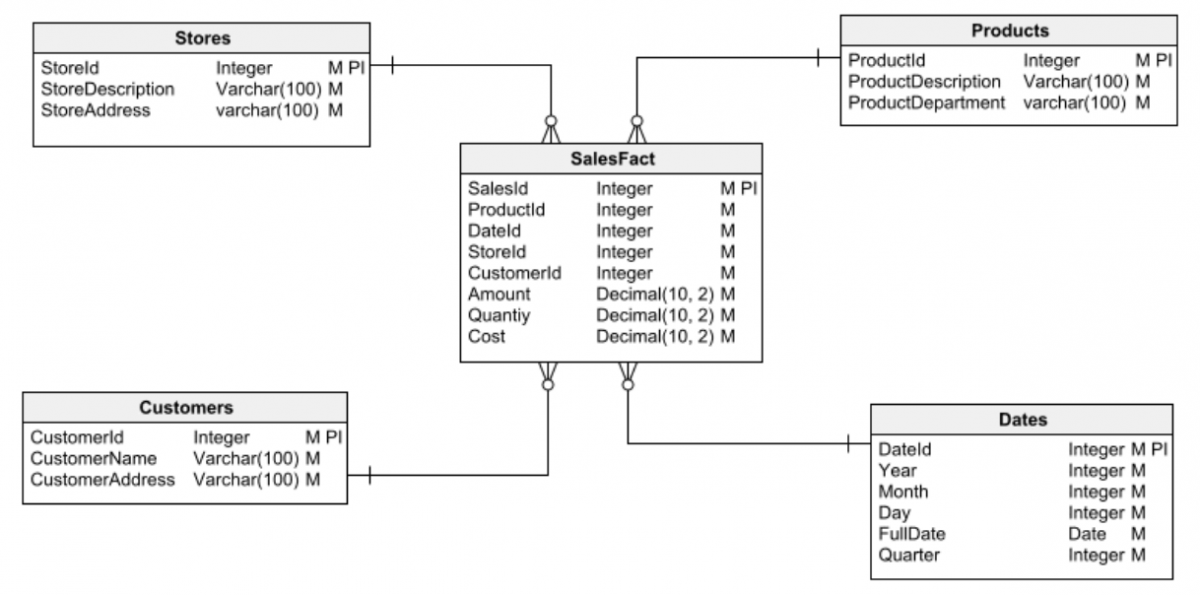
El primer paso en cualquier tarea de diseño de base de datos es elegir uno de los dos tipos principales de base de datos con el que trabajar: relacional o dimensional. Es vital tener esto claro antes de empezar a diseñar. De lo contrario, puede caer fácilmente en errores de diseño que eventualmente conducirán a muchos problemas y serán difíciles (o imposibles) de corregir.
Adopción de una convención de nomenclatura
Los nombres utilizados en el diseño de la base de datos son esenciales porque, una vez que se crea un objeto en una base de datos, cambiar su nombre puede ser fatal. Cambiar solo una letra del nombre puede romper dependencias, relaciones e incluso sistemas completos.
Por eso es fundamental trabajar con una convención de nomenclatura saludable: un conjunto de reglas que le ahorre la molestia de probar 50 posibilidades diferentes para encontrar el nombre de un objeto que no puede recordar.
No existe una guía universal sobre cómo debe ser una convención de nomenclatura para hacer su trabajo. Pero lo importante es establecer una convención de nomenclatura antes de nombrar cualquiera de los objetos en una base de datos y mantener esa convención para siempre. Una convención de nomenclatura establece pautas tales como usar un guión bajo para separar palabras o unirlas directamente, usar letras mayúsculas o mayúsculas (estilo Camel Case), usar palabras en plural o singular para nombrar objetos, etc.
Comienza con el diseño conceptual, luego el diseño lógico y finalmente el diseño físico.
Ese es el orden natural de las cosas. Como diseñador, puede sentirse tentado a comenzar creando objetos directamente en el DBMS para omitir pasos. Pero esto le impedirá tener una herramienta para discutir con las partes interesadas para garantizar que el diseño cumpla con los requisitos comerciales.
Después del diseño conceptual, debe pasar al diseño lógico para tener la documentación adecuada para ayudar a los programadores a comprender la estructura de la base de datos. Es vital mantener actualizado el diseño lógico para que sea independiente del motor de base de datos a utilizar. De esta forma, si finalmente migra la base de datos a un motor diferente, el diseño lógico seguirá siendo útil.
Finalmente, el diseño físico puede ser creado por los propios programadores o por un DBA, tomando el diseño lógico y agregando todos los detalles de implementación necesarios para implementarlo en un DBMS en particular.
Crear y mantener un diccionario de datos
Incluso si un ERD es claro y descriptivo, debe agregar un diccionario de datos para hacerlo aún más claro. El diccionario de datos mantiene la coherencia y la consistencia en el diseño de la base de datos, particularmente cuando la cantidad de objetos que contiene crece significativamente.
El objetivo principal del diccionario de datos es mantener un depósito único de información de referencia sobre las entidades de un modelo de datos y sus atributos. El diccionario de datos debe contener los nombres de todas las entidades, los nombres de todos los atributos, sus formatos y tipos de datos, y una breve descripción de cada uno.

El diccionario de datos proporciona una guía clara y concisa de todos los elementos que componen la base de datos. Esto evita crear múltiples objetos que representen lo mismo, lo que dificulta saber a qué objeto recurrir cuando se necesita consultar o actualizar información.
Mantener criterios coherentes para las claves primarias
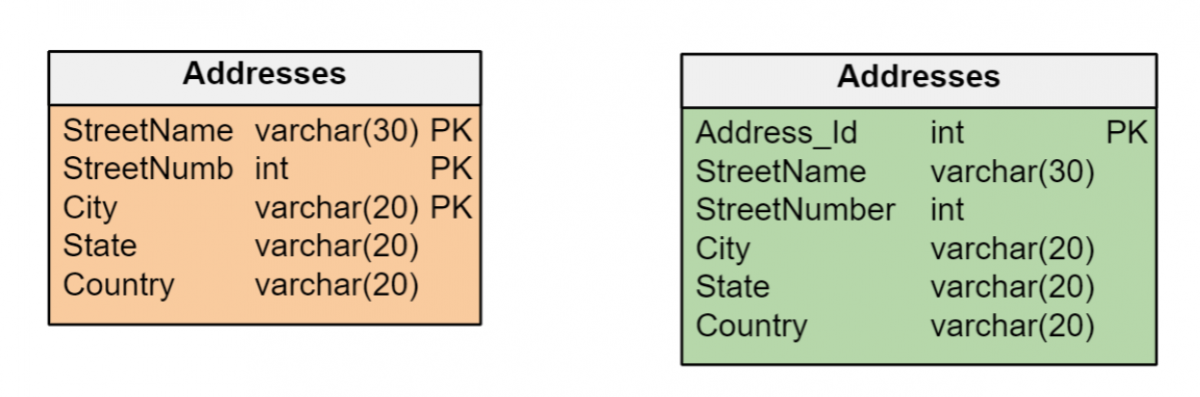
La decisión de usar claves naturales o claves sustitutas debe ser consistente dentro de un modelo de datos. Si las entidades en un modelo de datos tienen identificadores únicos que se pueden administrar de manera eficiente como claves principales de sus respectivas tablas, no es necesario crear claves sustitutas.
Pero es común que las entidades se identifiquen por múltiples atributos de diferentes tipos (fechas, números y/o largas cadenas de caracteres), lo que puede ser ineficiente para formar claves primarias. En estos casos, es mejor crear claves sustitutas de tipo numérico entero, que proporcionan la máxima eficiencia en la gestión de índices. Y la clave sustituta es la única opción si una entidad carece de atributos que la identifiquen de forma única.
Utilice los tipos de datos correctos para cada atributo.
Ciertos datos nos dan la opción de elegir qué tipo de datos usar para representarlos. Fechas, por ejemplo. Podemos optar por almacenarlos en campos de tipo fecha, campos de tipo fecha/hora, campos de tipo varchar o incluso campos de tipo numérico. Otro caso son los datos numéricos que no se usan para operaciones matemáticas sino para identificar una entidad, como un número de licencia de conducir o un código postal.
En el caso de las fechas, es conveniente utilizar el tipo de datos del motor, lo que facilita la manipulación de los datos. Si necesita almacenar solo la fecha de un evento sin especificar la hora, el tipo de dato a elegir será simplemente Fecha; si necesita almacenar la fecha y la hora en que ocurrió un determinado evento, el tipo de datos debe ser DateTime.
Usar otros tipos, como varchar o numeric, para almacenar fechas puede ser conveniente pero solo en casos muy particulares. Por ejemplo, si no se sabe de antemano en qué formato se expresará una fecha, es conveniente almacenarlo como varchar. Si el rendimiento de la búsqueda, la clasificación o la indexación son fundamentales para manejar campos de tipo fecha, una conversión previa a flotante puede marcar la diferencia.
Los datos numéricos que no intervienen en operaciones matemáticas deben representarse como varchar, aplicando validaciones de formato en el registro para evitar inconsistencias o repeticiones. De lo contrario, te expones al riesgo de que algunos datos excedan las limitaciones de los campos numéricos y te obliguen a refactorizar un diseño cuando ya está en producción.
Uso de tablas de consulta
Algunos diseñadores sin experiencia pueden creer que el uso excesivo de tablas de búsqueda para normalizar un diseño puede complicar el ERD de una base de datos innecesariamente porque agrega una gran cantidad de tablas "satélite" que a veces no tienen más que un puñado de elementos. Aquellos que piensen esto deben entender que el uso de tablas de búsqueda tiene muchos más beneficios que desventajas. Si la complejidad o el tamaño de un ERD es un problema, existen herramientas de diseño de ERD que le permiten visualizar los diagramas de diferentes maneras para que se entiendan a pesar de su complejidad.
Esta consulta de muestra ilustra el uso correcto de las tablas de búsqueda en una base de datos bien diseñada:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdEn este caso, estamos usando tablas de búsqueda para ciudades y estados.
Los beneficios de las tablas de búsqueda incluyen la reducción del tamaño de la base de datos, la mejora del rendimiento de la búsqueda y la imposición de restricciones en el conjunto de datos válido que puede contener un campo, entre otros. También es una buena práctica que todas las tablas de búsqueda incluyan un bit o un campo booleano que indique si un registro de la tabla está en uso o está obsoleto. Este campo se puede utilizar como filtro para evitar elementos obsoletos como opciones en la interfaz de usuario de la aplicación.
Normalizar o desnormalizar según el tipo de base de datos
En las bases de datos relacionales utilizadas para aplicaciones tradicionales, la normalización es imprescindible. Es bien sabido que la normalización reduce el espacio de almacenamiento necesario al evitar redundancias. Mejora la calidad de la información y proporciona múltiples herramientas para optimizar el rendimiento en consultas complejas.
Sin embargo, en otro tipo de bases de datos se aplica una técnica conocida como desnormalización. En las bases de datos dimensionales, utilizadas como almacenes de datos, la desnormalización agrega cierta información redundante útil en las tablas de esquema.
Aunque parezcan conceptos opuestos, desnormalizar no significa deshacer la normalización. En realidad, es una técnica de optimización aplicada a un modelo de datos después de normalizarlo para simplificar la redacción de consultas y los informes.
Diseño de modelos físicos por partes
En un proyecto de desarrollo de software, el diseñador de la base de datos presenta un modelo conceptual a gran escala a las partes interesadas, en el que no se muestran detalles de implementación. A su vez, para trabajar con desarrolladores, el diseñador debe proporcionar un modelo físico con todos los detalles de cada entidad y atributo. Sin embargo, no es necesario crear ambos modelos por completo al comienzo del proyecto.
Al aplicar metodologías ágiles, cada desarrollador al comienzo de cada ciclo de desarrollo toma una o más historias de usuario para trabajar durante ese ciclo. El trabajo del diseñador de la base de datos es proporcionar a cada desarrollador un submodelo físico que incluya solo los objetos que necesitan para una unidad de trabajo.
Al final de cada ciclo de desarrollo, los submodelos creados durante ese ciclo se fusionan para que el modelo físico completo tome forma paralelamente al desarrollo de la aplicación.
Hacer un buen uso de las vistas y los índices
Las vistas y los índices son dos herramientas fundamentales en el diseño de bases de datos para mejorar el rendimiento de las aplicaciones. El uso de vistas permite manejar abstracciones que simplifican las consultas, ocultando detalles innecesarios de la tabla. A su vez, las vistas facilitan las tareas de optimización de consultas para los motores de bases de datos, ya que les permiten anticipar cómo se obtendrán los datos y elegir las mejores estrategias para entregar resultados de consultas más rápido.
Los índices pueden mejorar el rendimiento de una consulta lenta según la experiencia del usuario una vez que la base de datos está en producción. Sin embargo, la creación de índices se puede realizar como parte de las tareas de diseño de la base de datos, anticipándose a las necesidades de la aplicación.
Para la creación de índices, debe tener una idea aproximada de la magnitud de cada tabla, en términos de recuento de registros, y luego crear índices para las tablas más grandes. Para elegir los campos a incluir en un índice, se deben considerar principalmente los que representan claves foráneas y los que se utilizarán como filtros en las búsquedas.
Cuando creas que el trabajo está terminado, es hora de refactorizar.
El diseño de una base de datos siempre se puede mejorar. Cuando no hay cambios en la base de datos por nuevos requerimientos o nuevas necesidades del negocio, es una buena oportunidad para realizar refactorizaciones que mejoren el diseño. Refactorizar significa simplemente eso: introducir cambios que mejoren un diseño sin afectar la semántica de la base de datos.
Existen muchas técnicas de refactorización para mejorar el diseño de una base de datos que quedan fuera del alcance de este artículo, pero es bueno conocer su existencia para usarlas cuando sea necesario.
Tener a mano esta lista de mejores prácticas siempre que necesites diseñar una base de datos te permitirá obtener los mejores resultados para que las aplicaciones mantengan siempre un rendimiento óptimo en el acceso a los datos.