
Best Practice für das Datenbankdesign für Hochleistungs-Apps
Veröffentlicht: 2021-07-19Damit eine Anwendung eine gute Leistung erbringt, benötigen Sie einen leistungsstarken Anwendungsserver, eine garantierte und ausreichende Bandbreite und eine gut gemachte Programmierarbeit. Aber es gibt einen Aspekt, der nicht immer berücksichtigt wird und der normalerweise einen großen Einfluss auf die Leistung einer jeden Anwendung hat: das Datenbankdesign .
Wir werden uns nun Best Practices für das Datenbankdesign ansehen, um sicherzustellen, dass der Datenzugriff kein Engpass ist, der sich negativ auf die Anwendungsleistung auswirkt.
Was ist der Zweck eines guten Datenbankdesigns?
Neben der Verbesserung der Datenzugriffsleistung erzielt ein gutes Design weitere Vorteile, wie z. B. die Aufrechterhaltung der Datenkonsistenz, Genauigkeit und Zuverlässigkeit und die Reduzierung des Speicherplatzes durch Eliminierung von Redundanzen. Ein weiterer Vorteil eines guten Designs besteht darin, dass die Datenbank einfacher zu verwenden und zu warten ist. Wer es verwalten muss, braucht nur einen Blick auf das Entity-Relationship-Diagramm (ERD) zu werfen, um seine Struktur zu verstehen.
ERDs sind das grundlegende Werkzeug des Datenbankdesigns. Sie können auf drei Designebenen erstellt und visualisiert werden: konzeptionell , logisch und physisch .
Das konzeptionelle Design zeigt ein sehr zusammengefasstes Diagramm mit nur den Elementen, die notwendig sind, um Kriterien mit den Projektbeteiligten zu vereinbaren, die die technischen Details der Datenbank nicht verstehen müssen. Das logische Design zeigt die Entitäten und ihre Beziehungen im Detail, aber auf datenbankunabhängige Weise.
Es gibt viele Tools, die Sie verwenden können, um das Design von Datenbanken aus ERDs zu erleichtern. Zu den besten gehören DbSchema , SqlDBM und Vertabelo .
DbSchema
Mit DbSchema können Sie SQL-, NoSQL- oder Cloud-Datenbanken visuell entwerfen und verwalten. Mit dem Tool können Sie unter anderem das Schema auf einem Computer entwerfen und in mehreren Datenbanken bereitstellen und Dokumentationen in HTML5-Diagrammen erstellen, Abfragen schreiben und die Daten visuell untersuchen. Es bietet auch Schemasynchronisierung, zufällige Datengenerierung und SQL-Codebearbeitung mit automatischer Vervollständigung.

SqlDBM
SqlDBM ist eines der besten Tools zum Entwerfen von Datenbankdiagrammen, da es eine einfache Möglichkeit bietet, Ihre Datenbank in jedem Browser zu entwerfen. Es sind keine anderen Datenbank-Engines oder Modellierungstools erforderlich, um es zu verwenden, obwohl Sie mit SqlDBM ein Schema aus einer vorhandenen Datenbank importieren können. Es ist ideal für die Teamarbeit, da Sie Designprojekte mit Kollegen teilen können.
Vertabelo
Vertabelo ist ein visuelles Online-Datenbankdesigntool, mit dem Sie eine Datenbank logisch entwerfen und das physische Schema automatisch ableiten können. Es kann Reverse Engineering durchführen, Diagramme aus vorhandenen Datenbanken generieren und den Zugriff auf die Diagramme steuern, indem es die Zugriffsrechte für Eigentümer, Bearbeiter und Betrachter unterscheidet.
Schließlich ist das physische Design dasjenige, das der ERD alle notwendigen Details hinzufügt, um sie in eine verwendbare Datenbank in einem bestimmten DBMS wie MySQL, MariaDB, MS SQL Server oder einem anderen zu verwandeln. Werfen wir einen Blick auf die Best Practices, die beim Entwerfen einer ERD zu beachten sind, damit die resultierende Datenbank optimal funktioniert.
Definieren Sie den zu entwerfenden Datenbanktyp
Normalerweise werden zwei grundlegende Arten von Datenbanken unterschieden: relationale und dimensionale .
Relationale Datenbanken werden für traditionelle Anwendungen verwendet, die Transaktionen auf den Daten ausführen – das heißt, sie erhalten Informationen aus der Datenbank, verarbeiten sie und speichern die Ergebnisse.
Andererseits werden Dimensional-Datenbanken für die Erstellung von Data Warehouses verwendet: große Informationsspeicher für die Datenanalyse und das Data Mining, um Erkenntnisse zu gewinnen.
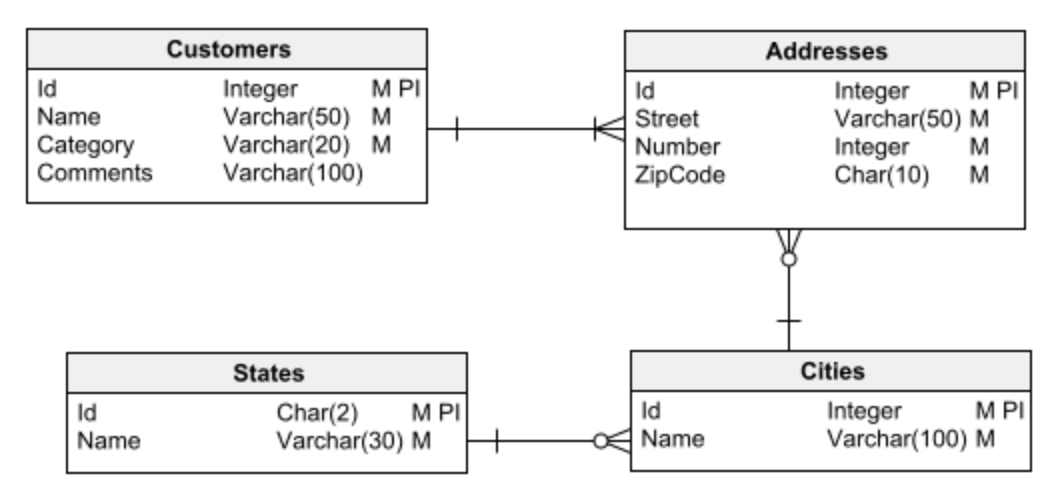
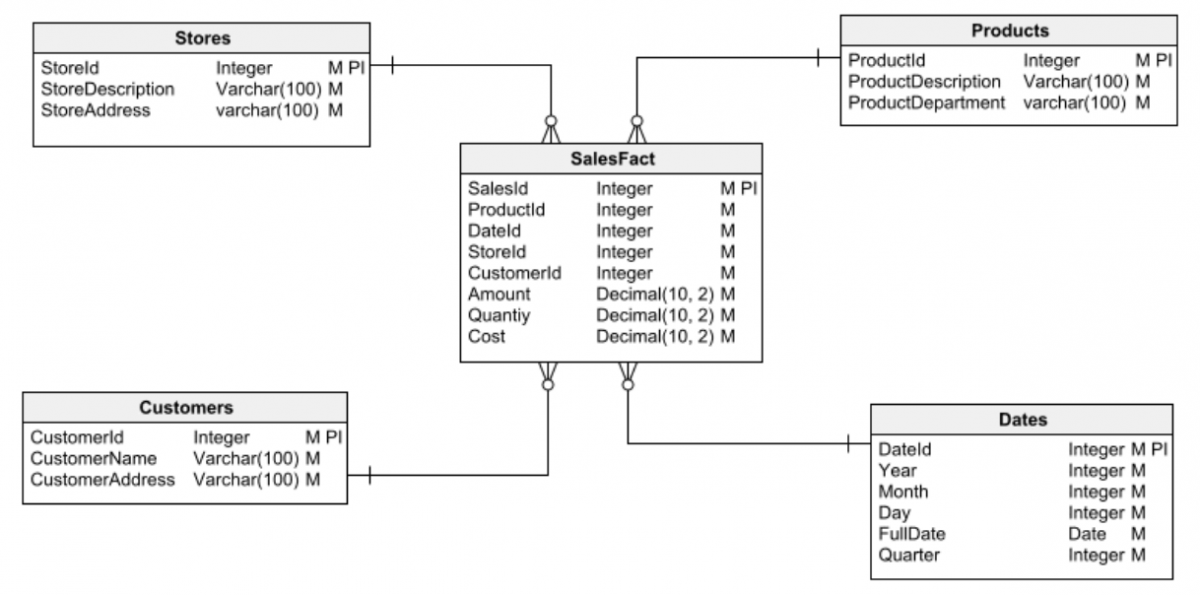
Der erste Schritt bei jeder Datenbankentwurfsaufgabe besteht darin, einen der beiden Hauptdatenbanktypen auszuwählen, mit denen gearbeitet werden soll: relational oder dimensional. Es ist wichtig, dass Sie sich darüber im Klaren sind, bevor Sie mit dem Entwerfen beginnen. Andernfalls können Sie leicht in Designfehler verfallen, die schließlich zu vielen Problemen führen und schwer (oder unmöglich) zu korrigieren sind.
Annahme einer Namenskonvention
Die im Datenbankdesign verwendeten Namen sind von entscheidender Bedeutung, da die Änderung des Namens eines Objekts, sobald es in einer Datenbank erstellt wurde, fatal sein kann. Das Ändern von nur einem Buchstaben des Namens kann Abhängigkeiten, Beziehungen und sogar ganze Systeme zerstören.
Deshalb ist es wichtig, mit einer gesunden Namenskonvention zu arbeiten: ein Regelwerk, das Ihnen die Mühe erspart, 50 verschiedene Möglichkeiten auszuprobieren, um den Namen eines Objekts zu finden, an das Sie sich nicht erinnern können.
Es gibt keinen universellen Leitfaden dafür, wie eine Namenskonvention aussehen sollte, um ihre Aufgabe zu erfüllen. Aber das Wichtigste ist, eine Namenskonvention aufzustellen, bevor Sie irgendwelche Objekte in einer Datenbank benennen, und diese Konvention für immer beizubehalten. Eine Namenskonvention legt Richtlinien fest, z. B. ob ein Unterstrich verwendet werden soll, um Wörter zu trennen oder direkt zu verbinden, ob nur Großbuchstaben verwendet oder Wörter großgeschrieben werden sollen (Camel Case-Stil), ob Plural- oder Singularwörter zum Benennen von Objekten verwendet werden sollen und so weiter.
Beginnen Sie mit dem konzeptionellen Design, dann dem logischen Design und schließlich dem physischen Design.
Das ist die natürliche Ordnung der Dinge. Als Designer könnten Sie versucht sein, damit zu beginnen, Objekte direkt im DBMS zu erstellen, um Schritte zu überspringen. Aber das verhindert, dass Sie über ein Tool verfügen, mit dem Sie mit Stakeholdern diskutieren können, um sicherzustellen, dass das Design den Geschäftsanforderungen entspricht.
Nach dem konzeptionellen Design müssen Sie mit dem logischen Design fortfahren, um über eine angemessene Dokumentation zu verfügen, die den Programmierern hilft, die Datenbankstruktur zu verstehen. Es ist wichtig, das logische Design auf dem neuesten Stand zu halten, um unabhängig von der zu verwendenden Datenbank-Engine zu sein. Wenn Sie die Datenbank schließlich auf eine andere Engine migrieren, ist das logische Design auf diese Weise immer noch nützlich.
Schließlich kann das physische Design von den Programmierern selbst oder von einem DBA erstellt werden, indem das logische Design genommen und alle Implementierungsdetails hinzugefügt werden, die erforderlich sind, um es auf einem bestimmten DBMS zu implementieren.
Erstellen und pflegen Sie ein Datenwörterbuch
Auch wenn ein ERD klar und aussagekräftig ist, sollten Sie ein Datenwörterbuch hinzufügen, um es noch klarer zu machen. Das Datenwörterbuch behält die Kohärenz und Konsistenz im Datenbankdesign bei, insbesondere wenn die Anzahl der darin enthaltenen Objekte erheblich zunimmt.
Der Hauptzweck des Datenwörterbuchs besteht darin, ein einzelnes Repository mit Referenzinformationen über die Entitäten eines Datenmodells und seine Attribute zu verwalten. Das Datenwörterbuch sollte die Namen aller Entitäten, die Namen aller Attribute, ihre Formate und Datentypen sowie jeweils eine kurze Beschreibung enthalten.
Das Datenwörterbuch bietet eine klare und präzise Anleitung zu allen Elementen, aus denen die Datenbank besteht. Dadurch wird vermieden, dass mehrere Objekte erstellt werden, die dasselbe darstellen, was es schwierig macht, zu wissen, auf welches Objekt Sie zurückgreifen müssen, wenn Sie Informationen abfragen oder aktualisieren müssen.

Pflegen Sie konsistente Kriterien für Primärschlüssel
Die Entscheidung, natürliche Schlüssel oder Ersatzschlüssel zu verwenden, muss innerhalb eines Datenmodells konsistent sein. Wenn Entitäten in einem Datenmodell eindeutige Kennungen haben, die effizient als Primärschlüssel ihrer jeweiligen Tabellen verwaltet werden können, müssen keine Ersatzschlüssel erstellt werden.
Aber es ist üblich, dass Entitäten durch mehrere Attribute unterschiedlichen Typs – Daten, Zahlen und/oder lange Zeichenketten – identifiziert werden, was für die Bildung von Primärschlüsseln ineffizient sein kann. In diesen Fällen ist es besser, Ersatzschlüssel vom ganzzahligen numerischen Typ zu erstellen, die maximale Effizienz bei der Indexverwaltung bieten. Und der Ersatzschlüssel ist die einzige Option, wenn einer Entität Attribute fehlen, die sie eindeutig identifizieren.
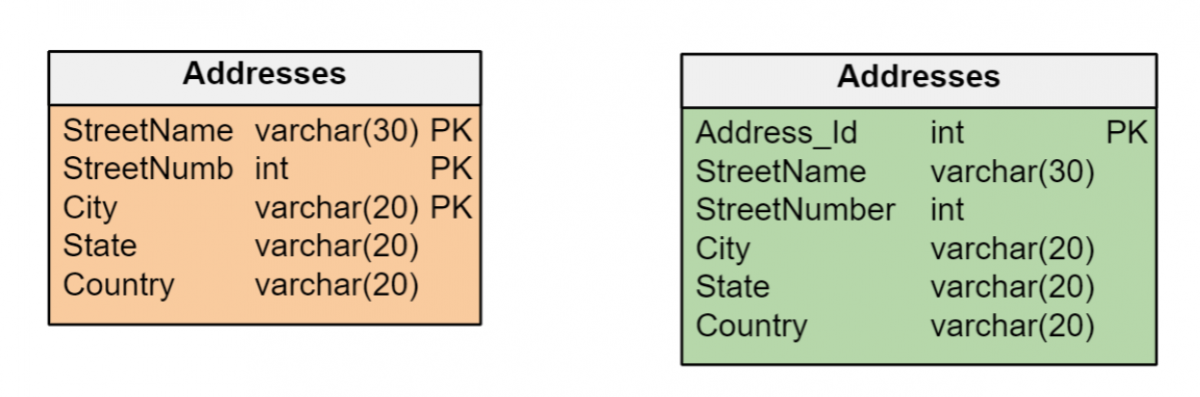
Verwenden Sie für jedes Attribut die richtigen Datentypen.
Bestimmte Daten geben uns die Möglichkeit zu wählen, welchen Datentyp wir verwenden, um sie darzustellen. Datteln zum Beispiel. Wir können sie in Feldern vom Typ Datum, Datum/Uhrzeit, Felder vom Typ Varchar oder sogar Felder vom Typ Numerisch speichern. Ein anderer Fall sind numerische Daten, die nicht für mathematische Operationen, sondern zur Identifizierung einer Entität verwendet werden, wie z. B. eine Führerscheinnummer oder eine Postleitzahl.
Bei Datumsangaben ist es praktisch, den Datentyp der Engine zu verwenden, was die Manipulation von Daten erleichtert. Wenn Sie nur das Datum eines Ereignisses speichern müssen, ohne die Zeit anzugeben, ist der zu wählende Datentyp einfach Datum; Wenn Sie das Datum und die Uhrzeit eines bestimmten Ereignisses speichern müssen, sollte der Datentyp DateTime sein.
Die Verwendung anderer Typen wie varchar oder numerisch zum Speichern von Datumsangaben kann praktisch sein, aber nur in ganz bestimmten Fällen. Wenn beispielsweise nicht im Voraus bekannt ist, in welchem Format ein Datum ausgedrückt wird, ist es praktisch, es als varchar zu speichern. Wenn die Suchleistung, Sortierung oder Indizierung bei der Verarbeitung von Datumsfeldern entscheidend ist, kann eine vorherige Konvertierung in Float einen Unterschied machen.
Numerische Daten, die nicht an mathematischen Operationen beteiligt sind, sollten als varchar dargestellt werden, wobei Formatvalidierungen in der Aufzeichnung angewendet werden, um Inkonsistenzen oder Wiederholungen zu vermeiden. Andernfalls setzen Sie sich dem Risiko aus, dass einige Daten die Beschränkungen der numerischen Felder überschreiten und Sie dazu zwingen, ein Design zu überarbeiten, wenn es sich bereits in der Produktion befindet.
Verwendung von Nachschlagetabellen
Einige unerfahrene Designer glauben möglicherweise, dass die übermäßige Verwendung von Nachschlagetabellen zur Normalisierung eines Designs die ERD einer Datenbank unnötig verkomplizieren kann, da sie eine große Anzahl von „Satelliten“-Tabellen hinzufügt, die manchmal nicht mehr als eine Handvoll Elemente enthalten. Wer so denkt, sollte verstehen, dass die Verwendung von Nachschlagetabellen viel mehr Vor- als Nachteile hat. Wenn die Komplexität oder Größe eines ERD ein Problem darstellt, gibt es ERD-Designtools, mit denen Sie die Diagramme auf unterschiedliche Weise visualisieren können, damit sie trotz ihrer Komplexität verständlich sind.
Diese Beispielabfrage veranschaulicht die korrekte Verwendung von Nachschlagetabellen in einer gut gestalteten Datenbank:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdIn diesem Fall verwenden wir Nachschlagetabellen für Städte und Staaten.
Zu den Vorteilen von Nachschlagetabellen gehören unter anderem die Verringerung der Größe der Datenbank, die Verbesserung der Suchleistung und die Auferlegung von Einschränkungen für den gültigen Datensatz, den ein Feld enthalten kann. Es empfiehlt sich außerdem, dass alle Nachschlagetabellen ein Bit- oder Boolesches Feld enthalten, das angibt, ob ein Datensatz in der Tabelle verwendet wird oder obsolet ist. Dieses Feld kann als Filter verwendet werden, um veraltete Elemente als Optionen in der Benutzeroberfläche der Anwendung zu vermeiden.
Je nach Datenbanktyp normalisieren oder denormalisieren
In relationalen Datenbanken, die für herkömmliche Anwendungen verwendet werden, ist die Normalisierung ein Muss. Es ist allgemein bekannt, dass die Normalisierung den erforderlichen Speicherplatz verringert, indem Redundanzen vermieden werden. Es verbessert die Qualität der Informationen und bietet mehrere Tools zur Optimierung der Leistung bei komplexen Abfragen.
Bei anderen Arten von Datenbanken wird jedoch eine Technik angewendet, die als Denormalisierung bekannt ist. In dimensionalen Datenbanken, die als Data Warehouses verwendet werden, fügt die Denormalisierung bestimmte nützliche redundante Informationen in den Schematabellen hinzu.
Obwohl sie gegensätzliche Konzepte zu sein scheinen, bedeutet Denormalisierung nicht, die Normalisierung rückgängig zu machen. Es ist eigentlich eine Optimierungstechnik, die auf ein Datenmodell angewendet wird, nachdem es normalisiert wurde, um das Schreiben von Abfragen und die Berichterstellung zu vereinfachen.
Entwerfen physikalischer Modelle in Teilen
In einem Softwareentwicklungsprojekt präsentiert der Datenbankdesigner Stakeholdern ein umfassendes konzeptionelles Modell, in dem keine Implementierungsdetails gezeigt werden. Um mit Entwicklern zusammenzuarbeiten, muss der Designer wiederum ein physisches Modell mit allen Details jeder Entität und jedes Attributs bereitstellen. Beide Modelle müssen jedoch nicht zu Beginn des Projekts vollständig erstellt sein.
Bei der Anwendung agiler Methoden übernimmt jeder Entwickler zu Beginn jedes Entwicklungszyklus eine oder mehrere User Stories, mit denen er während dieses Zyklus arbeiten kann. Die Aufgabe des Datenbankdesigners besteht darin, jedem Entwickler ein physisches Untermodell bereitzustellen, das nur die Objekte enthält, die er für eine Arbeitseinheit benötigt.
Am Ende jedes Entwicklungszyklus werden die in diesem Zyklus erstellten Teilmodelle zusammengeführt, sodass das vollständige physikalische Modell parallel zur Entwicklung der Anwendung Gestalt annimmt.
Sichten und Indizes sinnvoll nutzen
Ansichten und Indizes sind zwei grundlegende Tools im Datenbankdesign zur Verbesserung der Anwendungsleistung. Die Verwendung von Ansichten ermöglicht die Handhabung von Abstraktionen, die Abfragen vereinfachen und unnötige Tabellendetails ausblenden. Ansichten wiederum erleichtern Datenbank-Engines die Aufgaben der Abfrageoptimierung, da sie es ihnen ermöglichen, vorherzusehen, wie Daten abgerufen werden, und die besten Strategien auszuwählen, um Abfrageergebnisse schneller bereitzustellen.
Indizes können die Leistung einer langsamen Abfrage basierend auf der Benutzererfahrung verbessern, sobald die Datenbank in Produktion ist. Die Indexerstellung kann jedoch als Teil der Datenbankentwurfsaufgaben durchgeführt werden, wobei die Anforderungen der Anwendung vorweggenommen werden.
Für die Erstellung von Indizes müssen Sie eine ungefähre Vorstellung von der Größe jeder Tabelle haben – in Bezug auf die Anzahl der Datensätze – und dann Indizes für die größeren Tabellen erstellen. Um die Felder auszuwählen, die in einen Index aufgenommen werden sollen, müssen Sie hauptsächlich diejenigen berücksichtigen, die Fremdschlüssel darstellen, und diejenigen, die als Filter in den Suchen verwendet werden.
Wenn Sie denken, dass die Arbeit abgeschlossen ist, ist es an der Zeit, umzugestalten.
Das Design einer Datenbank kann immer verbessert werden. Wenn aufgrund neuer Anforderungen oder neuer Geschäftsanforderungen keine Änderungen an der Datenbank vorgenommen werden, ist dies eine gute Gelegenheit, Refactoring-Verfahren durchzuführen, die das Design verbessern. Refactoring bedeutet einfach Folgendes: Einführen von Änderungen, die ein Design verbessern, ohne die Semantik der Datenbank zu beeinträchtigen.
Es gibt viele Refactoring-Techniken, um das Design einer Datenbank zu verbessern, die den Rahmen dieses Artikels sprengen würden, aber es ist gut, von ihrer Existenz zu wissen, um sie bei Bedarf zu verwenden.
Wenn Sie diese Liste bewährter Verfahren zur Hand haben, wann immer Sie eine Datenbank entwerfen müssen, können Sie die besten Ergebnisse erzielen, sodass die Anwendungen beim Datenzugriff immer eine optimale Leistung aufrechterhalten.