
Prática recomendada de design de banco de dados para aplicativos de alto desempenho
Publicados: 2021-07-19Para que um aplicativo tenha um bom desempenho, você precisa de um servidor de aplicativos poderoso, uma largura de banda garantida e ampla e um trabalho de programação bem feito. Mas há um aspecto que nem sempre é levado em consideração e que costuma ter um grande impacto no desempenho de qualquer aplicação: o design do banco de dados.
Agora, examinaremos as práticas recomendadas de design de banco de dados para garantir que o acesso aos dados não seja um gargalo que afete negativamente o desempenho do aplicativo.
Qual é o propósito de um bom design de banco de dados?
Além de melhorar o desempenho do acesso aos dados, um bom design traz outros benefícios, como manter a consistência, precisão e confiabilidade dos dados e reduzir o espaço de armazenamento ao eliminar redundâncias. Outro benefício de um bom design é que o banco de dados é mais fácil de usar e manter. Qualquer pessoa que precise gerenciá-lo precisará apenas examinar o diagrama entidade-relacionamento (ERD) para entender sua estrutura.
Os ERDs são a ferramenta fundamental do projeto de banco de dados. Eles podem ser criados e visualizados em três níveis de design: conceitual , lógico e físico .
O desenho conceitual mostra um diagrama muito resumido, com apenas os elementos necessários para acordar os critérios com as partes interessadas do projeto, que não precisam entender os detalhes técnicos do banco de dados. O design lógico mostra as entidades e seus relacionamentos em detalhes, mas de maneira independente do banco de dados.
Existem muitas ferramentas que você pode usar para facilitar o design de bancos de dados de ERDs. Entre os melhores estão DbSchema , SqlDBM e Vertabelo .
DbSchemaGenericName
O DbSchema permite projetar e gerenciar visualmente bancos de dados SQL, NoSQL ou Cloud. A ferramenta permite projetar o esquema em um computador e implantá-lo em vários bancos de dados e gerar documentação em diagramas HTML5, escrever consultas e explorar visualmente os dados, entre outros. Ele também oferece sincronização de esquema, geração de dados aleatórios e edição de código SQL com preenchimento automático.

SqlDBM
O SqlDBM é uma das melhores ferramentas de design de diagrama de banco de dados porque fornece uma maneira fácil de projetar seu banco de dados em qualquer navegador. Nenhum outro mecanismo de banco de dados ou ferramentas de modelagem são necessários para usá-lo, embora o SqlDBM permita importar um esquema de um banco de dados existente. É ideal para trabalho em equipe, pois permite compartilhar projetos de design com colegas de trabalho.
Vertabelo
Vertabelo é uma ferramenta de design de banco de dados visual online que permite projetar um banco de dados de forma lógica e derivar automaticamente o esquema físico. Ele pode fazer engenharia reversa, gerar diagramas a partir de bancos de dados existentes e controlar o acesso aos diagramas diferenciando privilégios de acesso para proprietários, editores e visualizadores.
Por fim, o desenho físico é aquele que agrega ao ERD todos os detalhes necessários para transformá-lo em um banco de dados utilizável em um determinado SGBD, como MySQL, MariaDB, MS SQL Server, ou qualquer outro. Vamos dar uma olhada nas práticas recomendadas a serem lembradas ao projetar um ERD para que o banco de dados resultante funcione da melhor maneira possível.
Defina o tipo de banco de dados a ser projetado
Dois tipos fundamentais de banco de dados são geralmente distinguidos: relacional e dimensional .
Os bancos de dados relacionais são usados para aplicativos tradicionais que executam transações nos dados – ou seja, eles obtêm informações do banco de dados, processam e armazenam os resultados.
Por outro lado, os bancos de dados dimensionais são usados para a criação de data warehouses: grandes repositórios de informações para análise de dados e mineração de dados para obter insights.
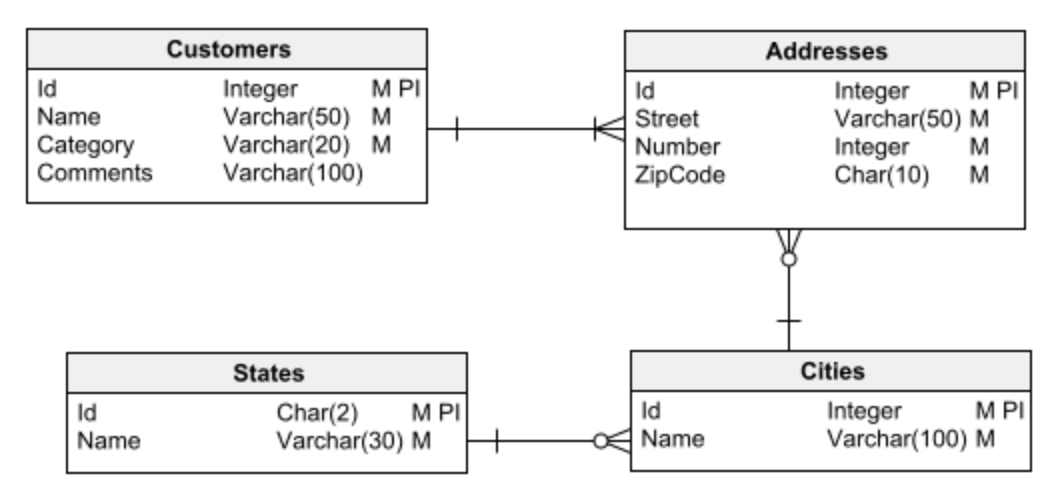
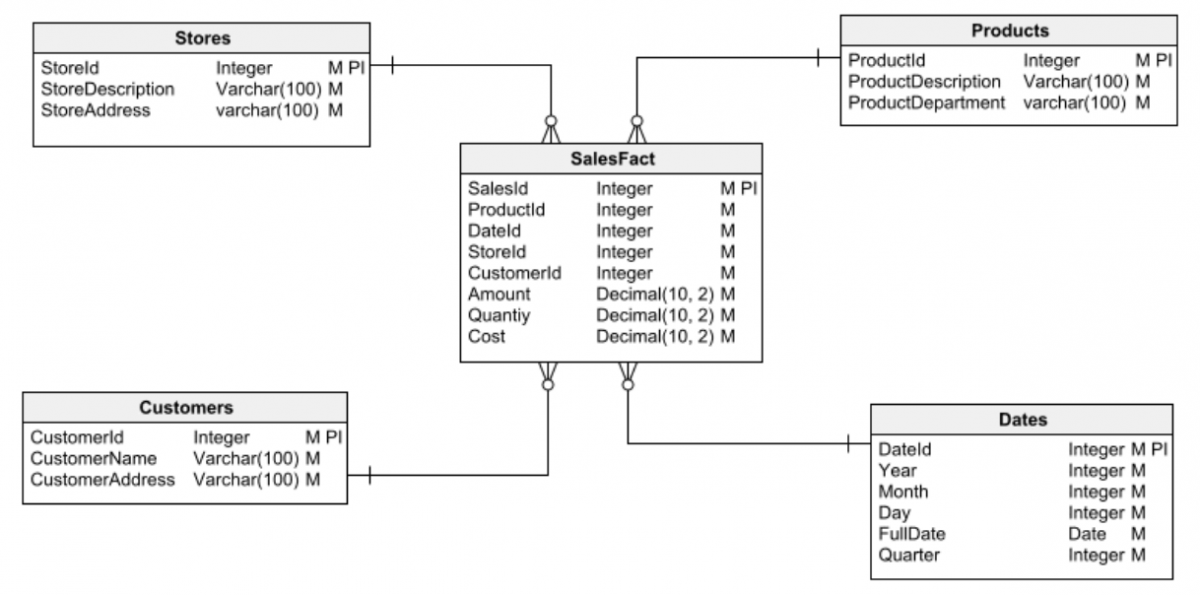
O primeiro passo em qualquer tarefa de projeto de banco de dados é escolher um dos dois principais tipos de banco de dados com o qual trabalhar: relacional ou dimensional. É vital ter isso claro antes de começar a projetar. Caso contrário, você pode facilmente cair em erros de design que eventualmente levarão a muitos problemas e serão difíceis (ou impossíveis) de corrigir.
Adotando uma convenção de nomenclatura
Os nomes usados no design do banco de dados são essenciais porque, uma vez que um objeto é criado em um banco de dados, a alteração de seu nome pode ser fatal. Alterar apenas uma letra do nome pode quebrar dependências, relacionamentos e até sistemas inteiros.
É por isso que é fundamental trabalhar com uma convenção de nomenclatura saudável: um conjunto de regras que poupa o trabalho de tentar 50 possibilidades diferentes para encontrar o nome de um objeto que você não consegue lembrar.
Não há um guia universal para o que uma convenção de nomenclatura deve ser para fazer seu trabalho. Mas o importante é estabelecer uma convenção de nomenclatura antes de nomear qualquer um dos objetos em um banco de dados e manter essa convenção para sempre. Uma convenção de nomenclatura estabelece diretrizes como usar um sublinhado para separar palavras ou juntá-las diretamente, usar todas as letras maiúsculas ou letras maiúsculas (estilo Camel Case), usar palavras no plural ou singular para nomear objetos e assim por diante.
Comece com o projeto conceitual, depois o projeto lógico e, finalmente, o projeto físico.
Essa é a ordem natural das coisas. Como designer, você pode ficar tentado a começar criando objetos diretamente no DBMS para pular etapas. Mas isso impedirá que você tenha uma ferramenta para discutir com as partes interessadas para garantir que o design atenda aos requisitos de negócios.
Após o projeto conceitual, você deve passar para o projeto lógico para ter a documentação adequada para ajudar os programadores a entender a estrutura do banco de dados. É vital manter o design lógico atualizado para ser independente do mecanismo de banco de dados a ser usado. Dessa forma, se você eventualmente migrar o banco de dados para um mecanismo diferente, o design lógico ainda será útil.
Por fim, o projeto físico pode ser criado pelos próprios programadores ou por um DBA, pegando o projeto lógico e adicionando todos os detalhes de implementação necessários para implementá-lo em um determinado SGBD.
Criar e manter um dicionário de dados
Mesmo que um ERD seja claro e descritivo, você deve adicionar um dicionário de dados para torná-lo ainda mais claro. O dicionário de dados mantém coerência e consistência no design do banco de dados, principalmente quando o número de objetos nele cresce significativamente.
O principal objetivo do dicionário de dados é manter um único repositório de informações de referência sobre as entidades de um modelo de dados e seus atributos. O dicionário de dados deve conter os nomes de todas as entidades, os nomes de todos os atributos, seus formatos e tipos de dados e uma breve descrição de cada um.

O dicionário de dados fornece um guia claro e conciso para todos os elementos que compõem o banco de dados. Isso evita a criação de vários objetos que representam a mesma coisa, o que dificulta saber a qual objeto recorrer quando precisar consultar ou atualizar informações.
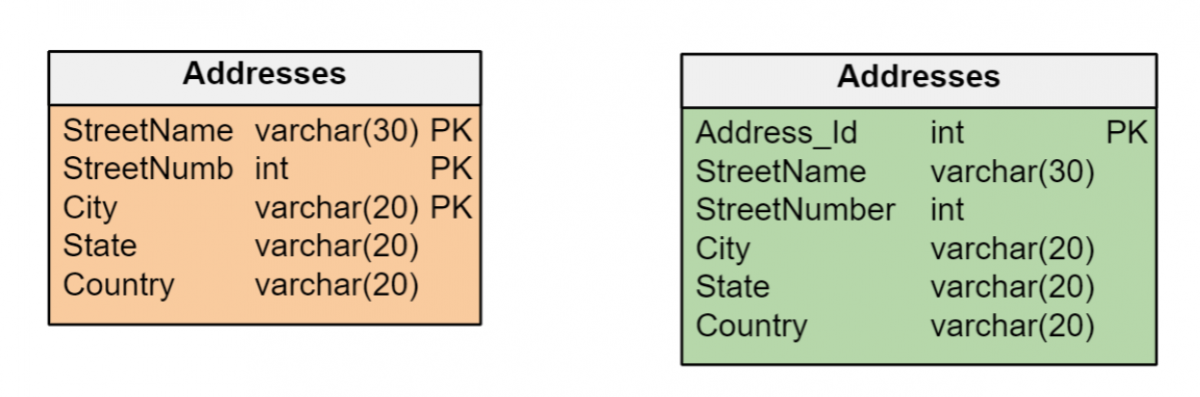
Mantenha critérios consistentes para chaves primárias
A decisão de usar chaves naturais ou chaves substitutas deve ser consistente em um modelo de dados. Se as entidades em um modelo de dados possuem identificadores exclusivos que podem ser gerenciados de forma eficiente como chaves primárias de suas respectivas tabelas, não há necessidade de criar chaves substitutas.
Mas é comum que as entidades sejam identificadas por vários atributos de diferentes tipos – datas, números e/ou longas sequências de caracteres – que podem ser ineficientes para formar chaves primárias. Nesses casos, é melhor criar chaves substitutas do tipo numérico inteiro, que fornecem a máxima eficiência no gerenciamento de índices. E a chave substituta é a única opção se uma entidade não tiver atributos que a identifiquem exclusivamente.
Use os tipos de dados corretos para cada atributo.
Certos dados nos dão a opção de escolher qual tipo de dados usar para representá-los. Datas, por exemplo. Podemos optar por armazená-los em campos do tipo data, campos do tipo data/hora, campos do tipo varchar ou até campos do tipo numérico. Outro caso são os dados numéricos que não são usados para operações matemáticas, mas para identificar uma entidade, como um número de carteira de motorista ou um CEP.
No caso de datas, é conveniente utilizar o tipo de dado do mecanismo, o que facilita a manipulação dos dados. Se você precisar armazenar apenas a data de um evento sem especificar a hora, o tipo de dados a ser escolhido será simplesmente Data; se você precisar armazenar a data e a hora em que um determinado evento ocorreu, o tipo de dados deve ser DateTime.
Usar outros tipos, como varchar ou numeric, para armazenar datas pode ser conveniente, mas apenas em casos muito particulares. Por exemplo, se não for conhecido antecipadamente em qual formato uma data será expressa, é conveniente armazená-la como varchar. Se o desempenho, a classificação ou a indexação da pesquisa forem essenciais no tratamento de campos do tipo data, uma conversão anterior para flutuante pode fazer a diferença.
Dados numéricos não envolvidos em operações matemáticas devem ser representados como varchar, aplicando-se validações de formato no registro para evitar inconsistências ou repetições. Caso contrário, você se expõe ao risco de que alguns dados excedam as limitações dos campos numéricos e o forcem a refatorar um design quando ele já estiver em produção.
Uso de tabelas de pesquisa
Alguns designers inexperientes podem acreditar que o uso excessivo de tabelas de pesquisa para normalizar um design pode complicar o ERD de um banco de dados desnecessariamente porque adiciona um grande número de tabelas “satélite” que às vezes não possuem mais do que um punhado de elementos. Aqueles que pensam isso devem entender que o uso de tabelas de pesquisa tem muito mais benefícios do que desvantagens. Se a complexidade ou tamanho de um ERD for um problema, existem ferramentas de projeto de ERD que permitem visualizar os diagramas de diferentes maneiras para serem entendidos apesar de sua complexidade.
Esta consulta de amostra ilustra o uso correto de tabelas de pesquisa em um banco de dados bem projetado:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdNesse caso, estamos usando tabelas de pesquisa para Cidades e Estados.
Os benefícios das tabelas de pesquisa incluem reduzir o tamanho do banco de dados, melhorar o desempenho da pesquisa e impor restrições ao conjunto de dados válido que um campo pode conter, entre outros. Também é uma boa prática que todas as tabelas de pesquisa incluam um campo Bit ou Booleano que indique se um registro na tabela está em uso ou está obsoleto. Este campo pode ser usado como filtro para evitar elementos obsoletos como opções na interface do usuário do aplicativo.
Normalize ou desnormalize de acordo com o tipo de banco de dados
Em bancos de dados relacionais usados para aplicativos tradicionais, a normalização é obrigatória. É sabido que a normalização reduz o espaço de armazenamento necessário, evitando redundâncias. Melhora a qualidade das informações e fornece várias ferramentas para otimizar o desempenho em consultas complexas.
No entanto, em outros tipos de banco de dados, uma técnica conhecida como desnormalização é aplicada. Em bancos de dados dimensionais, usados como data warehouses, a desnormalização adiciona certas informações redundantes úteis nas tabelas de esquema.
Embora pareçam ser conceitos opostos, a desnormalização não significa desfazer a normalização. Na verdade, é uma técnica de otimização aplicada a um modelo de dados após normalizá-lo para simplificar a gravação e o relatório de consultas.
Projetando modelos físicos em peças
Em um projeto de desenvolvimento de software, o projetista de banco de dados apresenta um modelo conceitual em larga escala para as partes interessadas, no qual nenhum detalhe de implementação é mostrado. Por sua vez, para trabalhar com desenvolvedores, o projetista deve fornecer um modelo físico com todos os detalhes de cada entidade e atributo. No entanto, ambos os modelos não precisam ser completamente criados no início do projeto.
Ao aplicar metodologias ágeis, cada desenvolvedor no início de cada ciclo de desenvolvimento leva uma ou mais histórias de usuário para trabalhar durante esse ciclo. O trabalho do designer de banco de dados é fornecer a cada desenvolvedor um submodelo físico que inclua apenas os objetos necessários para uma unidade de trabalho.
Ao final de cada ciclo de desenvolvimento, os submodelos criados durante esse ciclo são mesclados para que o modelo físico completo tome forma paralela ao desenvolvimento da aplicação.
Fazendo bom uso de visualizações e índices
Visualizações e índices são duas ferramentas fundamentais no design de banco de dados para melhorar o desempenho do aplicativo. O uso de visualizações permite lidar com abstrações que simplificam as consultas, ocultando detalhes desnecessários da tabela. Por sua vez, as visualizações facilitam as tarefas de otimização de consultas para os mecanismos de banco de dados, pois permitem que eles antecipem como os dados serão obtidos e escolham as melhores estratégias para fornecer resultados de consulta mais rapidamente.
Os índices podem melhorar o desempenho de uma consulta lenta com base na experiência do usuário quando o banco de dados estiver em produção. No entanto, a criação do índice pode ser feita como parte das tarefas de design do banco de dados, antecipando as necessidades do aplicativo.
Para a criação de índices, você precisa ter uma ideia aproximada da magnitude de cada tabela – em termos de contagem de registros – e então criar índices para as tabelas maiores. Para escolher os campos a serem incluídos em um índice, deve-se considerar principalmente aqueles que representam chaves estrangeiras e aqueles que serão utilizados como filtros nas buscas.
Quando você pensa que o trabalho está concluído, é hora de refatorar.
O design de um banco de dados sempre pode ser melhorado. Quando não houver alterações no banco de dados devido a novos requisitos ou novas necessidades de negócios, é uma boa oportunidade para realizar procedimentos de refatoração que melhorem o design. Refatorar significa simplesmente isso: introduzir mudanças que melhoram um design sem afetar a semântica do banco de dados.
Existem muitas técnicas de refatoração para melhorar o design de um banco de dados que fogem do escopo deste artigo, mas é bom saber de sua existência para usá-las quando necessário.
Ter esta lista de boas práticas à mão sempre que precisar projetar um banco de dados permitirá obter os melhores resultados para que as aplicações mantenham sempre o desempenho ideal no acesso aos dados.