
高性能アプリのデータベース設計のベスト プラクティス
公開: 2021-07-19アプリケーションが優れたパフォーマンスを発揮するには、強力なアプリケーション サーバー、保証された十分な帯域幅、およびよくできたプログラミング作業が必要です。 ただし、常に考慮されるとは限らず、通常はアプリケーションのパフォーマンスに大きな影響を与える側面が 1 つあります。データベースの設計です。
次に、データベース設計のベスト プラクティスを見て、データ アクセスがアプリケーションのパフォーマンスに悪影響を与えるボトルネックにならないようにします。
優れたデータベース設計の目的は何ですか?
優れた設計は、データ アクセスのパフォーマンスを向上させるだけでなく、データの一貫性、正確性、信頼性を維持し、冗長性を排除してストレージ スペースを削減するなど、他の利点も実現します。 優れた設計のもう 1 つの利点は、データベースの使用と保守が容易になることです。 それを管理する必要がある人は、エンティティ関係図 (ERD) を見るだけで、その構造を理解できます。
ERD は、データベース設計の基本的なツールです。 これらは、概念、論理、および物理の 3 つの設計レベルで作成および視覚化できます。
概念設計は非常に要約された図を示しており、データベースの技術的な詳細を理解する必要のないプロジェクトの利害関係者と基準について合意するために必要な要素のみが示されています。 論理設計では、エンティティとその関係が詳細に示されますが、データベースに依存しない方法で示されます。
ERD からのデータベースの設計を容易にするために使用できる多くのツールがあります。 最良のものの中には、 DbSchema 、 SqlDBM 、およびVertabeloがあります。
Dbスキーマ
DbSchema を使用すると、SQL、NoSQL、またはクラウド データベースを視覚的に設計および管理できます。 このツールを使用すると、コンピューター上でスキーマを設計し、それを複数のデータベースに展開し、HTML5 ダイアグラムでドキュメントを生成し、クエリを記述し、データを視覚的に探索することができます。 また、スキーマの同期、ランダム データ生成、およびオートコンプリートによる SQL コード編集も提供します。

SqlDBM
SqlDBM は、任意のブラウザーでデータベースを簡単に設計できるため、最高のデータベース ダイアグラム設計ツールの 1 つです。 SqlDBM を使用すると、既存のデータベースからスキーマをインポートできますが、他のデータベース エンジンやモデリング ツールを使用する必要はありません。 設計プロジェクトを同僚と共有できるため、チームワークに最適です。
ヴェルタベロ
Vertabelo は、データベースを論理的に設計し、物理スキーマを自動的に導出できる、オンラインのビジュアル データベース設計ツールです。 リバース エンジニアリング、既存のデータベースからのダイアグラムの生成、および所有者、編集者、閲覧者へのアクセス権限を区別することによるダイアグラムへのアクセスの制御が可能です。
最後に、物理設計は、ERD を特定の DBMS (MySQL、MariaDB、MS SQL Server など) で使用可能なデータベースにするために必要なすべての詳細を ERD に追加するものです。 結果として得られるデータベースが最適に機能するように、ERD を設計する際に留意すべきベスト プラクティスを見てみましょう。
設計するデータベースのタイプを定義する
通常、データベースには、リレーショナルとディメンションの 2 つの基本的なタイプが区別されます。
リレーショナル データベースは、データに対してトランザクションを実行する従来のアプリケーションに使用されます。つまり、データベースから情報を取得して処理し、結果を保存します。
一方、ディメンション データベースは、データ ウェアハウスの作成に使用されます。データ ウェアハウスとは、洞察を得るためのデータ分析とデータ マイニングのための大規模な情報リポジトリです。
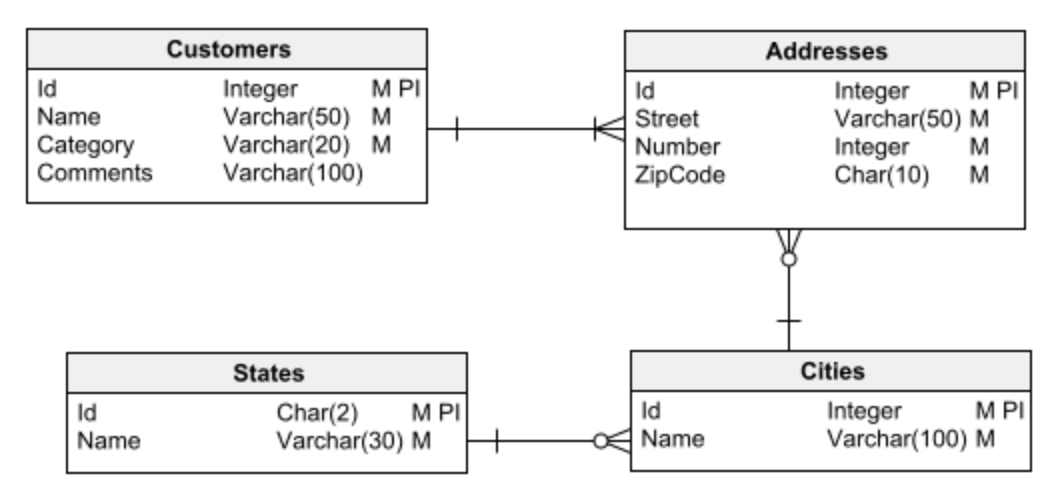
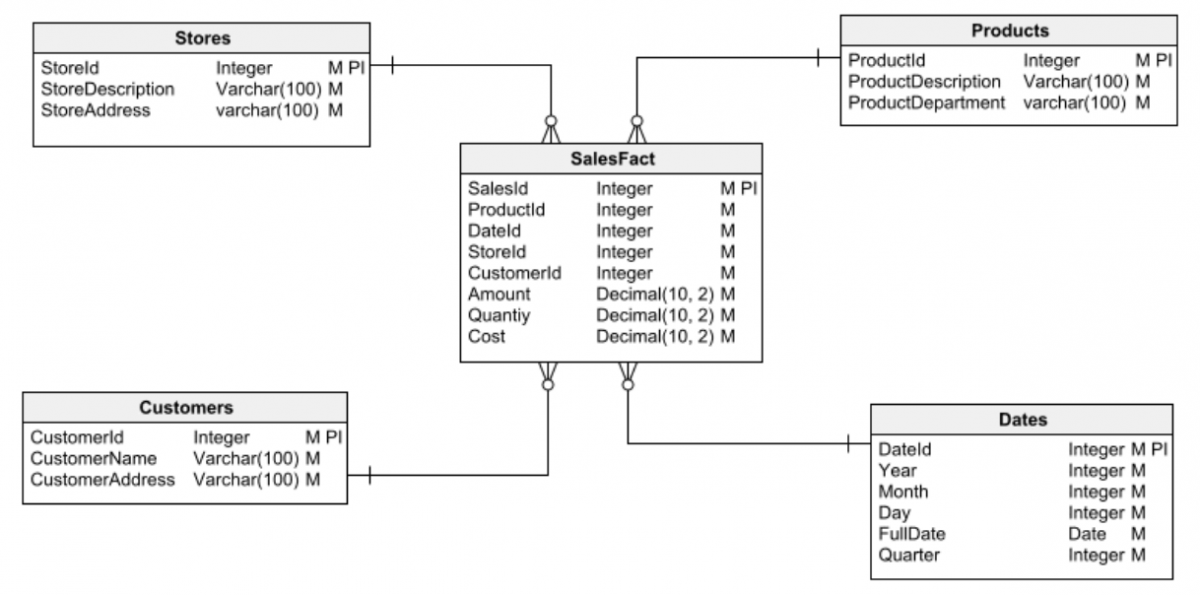
データベース設計タスクの最初のステップは、使用する 2 つの主要なデータベース タイプ (リレーショナルまたはディメンション) のいずれかを選択することです。 設計を開始する前に、これを明確にしておくことが重要です。 そうしないと、最終的に多くの問題につながり、修正が困難 (または不可能) になる設計ミスに簡単に陥る可能性があります。
命名規則の採用
オブジェクトがデータベースに作成されると、その名前を変更すると致命的になる可能性があるため、データベース設計で使用される名前は不可欠です。 名前の 1 文字を変更するだけで、依存関係、関係、さらにはシステム全体が壊れる可能性があります。
そのため、健全な命名規則を使用することが重要です。これは、覚えていないオブジェクトの名前を見つけるために 50 の異なる可能性を試す手間を省くための一連の規則です。
命名規則がその役割を果たすためにどうあるべきかについての普遍的なガイドはありません。 しかし重要なことは、データベース内のオブジェクトに名前を付ける前に命名規則を確立し、その規則を永久に維持することです。 命名規則は、アンダースコアを使用して単語を区切るか直接結合するか、すべて大文字を使用するか単語を大文字にするか (キャメル ケース スタイル)、複数または単数の単語を使用してオブジェクトに名前を付けるかどうかなどのガイドラインを確立します。
概念設計から始め、次に論理設計、最後に物理設計を行います。
それが物事の自然な順序です。 設計者として、手順をスキップするために DBMS で直接オブジェクトを作成することから始めたいと思うかもしれません。 しかし、これでは、設計がビジネス要件を満たしていることを確認するために利害関係者と話し合うためのツールを手に入れることができなくなります。
概念設計の後、プログラマがデータベース構造を理解するのに役立つ適切なドキュメントを作成するために、論理設計に進む必要があります。 使用するデータベース エンジンに依存しないように、論理設計を最新の状態に保つことが重要です。 このようにして、最終的にデータベースを別のエンジンに移行した場合でも、論理設計は引き続き役立ちます。

最後に、プログラマ自身または DBA が物理設計を作成し、論理設計を取得して、特定の DBMS に実装するために必要なすべての実装の詳細を追加します。
データ ディクショナリの作成と維持
ERD が明確で説明的であっても、さらに明確にするためにデータ ディクショナリを追加する必要があります。 データ ディクショナリは、特にデータベース内のオブジェクト数が大幅に増加した場合に、データベース設計の一貫性と一貫性を維持します。
データ ディクショナリの主な目的は、データ モデルのエンティティとその属性に関する参照情報の単一のリポジトリを維持することです。 データ ディクショナリには、すべてのエンティティの名前、すべての属性の名前、それらの形式とデータ型、およびそれぞれの簡単な説明が含まれている必要があります。
データ ディクショナリは、データベースを構成するすべての要素に対する明確で簡潔なガイドを提供します。 これにより、同じものを表す複数のオブジェクトが作成されるのを回避できます。これにより、情報を照会または更新する必要があるときに、どのオブジェクトに頼ればよいかを判断することが難しくなります。
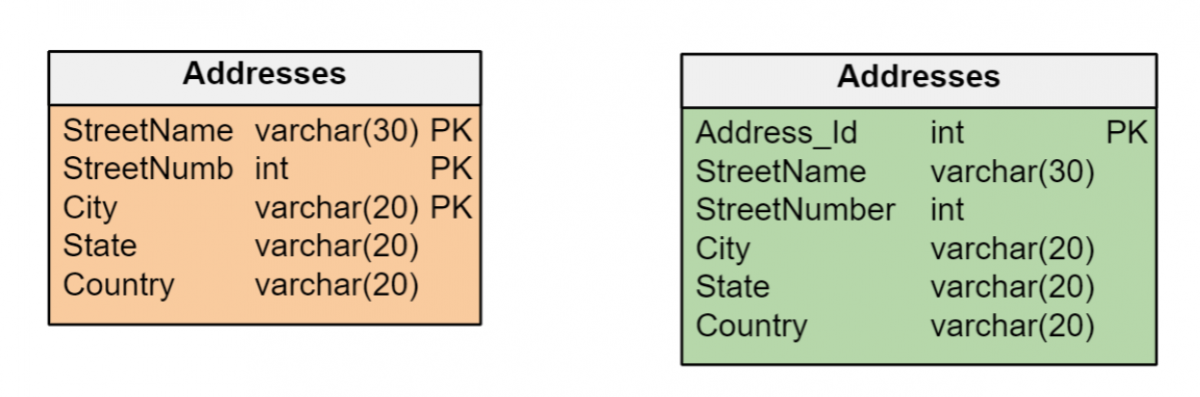
主キーの一貫した基準を維持する
自然キーまたは代理キーのどちらを使用するかの決定は、データ モデル内で一貫している必要があります。 データ モデル内のエンティティに、それぞれのテーブルの主キーとして効率的に管理できる一意の識別子がある場合、代理キーを作成する必要はありません。
しかし、エンティティが異なるタイプの複数の属性 (日付、数字、および/または長い文字列) によって識別されることは一般的です。これは、主キーを形成するのに非効率的である可能性があります。 このような場合は、インデックス管理の効率を最大化する整数型の代理キーを作成することをお勧めします。 また、代理キーは、エンティティを一意に識別する属性がエンティティにない場合の唯一のオプションです。
各属性に正しいデータ型を使用してください。
特定のデータは、それらを表すために使用するデータ型を選択するオプションを提供します。 たとえば、日付。 それらを日付型フィールド、日付/時刻型フィールド、varchar 型フィールド、または数値型フィールドに格納することを選択できます。 もう 1 つのケースは、数値データで、数値演算には使用されませんが、エンティティを識別するために使用されます (運転免許証番号や郵便番号など)。
日付の場合は、エンジンのデータ型を使用すると便利で、データの操作が簡単になります。 時刻を指定せずにイベントの日付のみを保存する必要がある場合、選択するデータ型は単純に Date になります。 特定のイベントが発生した日時を保存する必要がある場合、データ型は DateTime にする必要があります。
varchar や数値などの他の型を使用して日付を格納すると便利な場合がありますが、非常に特殊な場合に限られます。 たとえば、日付がどの形式で表現されるかが事前にわからない場合は、varchar として格納すると便利です。 日付型フィールドの処理で検索のパフォーマンス、並べ替え、またはインデックス作成が重要な場合は、浮動小数点数への以前の変換が違いを生む可能性があります。
数値演算に関係のない数値データは varchar として表現し、記録にフォーマット検証を適用して矛盾や繰り返しを回避する必要があります。 そうしないと、一部のデータが数値フィールドの制限を超えてしまい、既に運用中の設計をリファクタリングせざるを得なくなるというリスクにさらされます。
ルックアップ テーブルの使用
経験の浅い設計者の中には、ルックアップ テーブルを過度に使用して設計を正規化すると、データベースの ERD が不必要に複雑になる可能性があると考える人もいるかもしれません。 これを考える人は、ルックアップ テーブルの使用には、デメリットよりも多くのメリットがあることを理解する必要があります。 ERD の複雑さやサイズが問題になる場合は、さまざまな方法でダイアグラムを視覚化し、その複雑さにもかかわらず理解できるようにする ERD 設計ツールがあります。
このサンプル クエリは、適切に設計されたデータベースでルックアップ テーブルを正しく使用する方法を示しています。
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdこの場合、都市と州のルックアップ テーブルを使用しています。
ルックアップ テーブルの利点には、データベースのサイズの縮小、検索パフォーマンスの向上、フィールドに含めることができる有効なデータ セットへの制限などがあります。 また、すべてのルックアップ テーブルに、テーブル内のレコードが使用中か廃止されたかを示すビット フィールドまたはブール フィールドを含めることをお勧めします。 このフィールドは、アプリケーション UI のオプションとして廃止された要素を避けるためのフィルターとして使用できます。
データベースの種類に応じて正規化または非正規化する
従来のアプリケーションに使用されるリレーショナル データベースでは、正規化は必須です。 正規化によって冗長性が回避され、必要なストレージ容量が削減されることはよく知られています。 情報の品質を向上させ、複雑なクエリのパフォーマンスを最適化するための複数のツールを提供します。
ただし、他のタイプのデータベースでは、非正規化と呼ばれる手法が適用されます。 データ ウェアハウスとして使用される次元データベースでは、非正規化によって特定の有用な冗長情報がスキーマ テーブルに追加されます。
一見正反対の概念に見えますが、非正規化とは正規化を元に戻すという意味ではありません。 これは実際には、クエリの作成とレポート作成を簡素化するためにデータ モデルを正規化した後にデータ モデルに適用される最適化手法です。
部品の物理モデルの設計
ソフトウェア開発プロジェクトでは、データベース設計者が利害関係者に大規模な概念モデルを提示しますが、実装の詳細は示されていません。 次に、開発者と連携するために、設計者は各エンティティと属性のすべての詳細を含む物理モデルを提供する必要があります。 ただし、プロジェクトの開始時に両方のモデルを完全に作成する必要はありません。
アジャイル手法を適用する場合、各開発サイクルの開始時に各開発者は、そのサイクル中に 1 つ以上のユーザー ストーリーを使用します。 データベース設計者の仕事は、作業単位に必要なオブジェクトのみを含む物理サブモデルを各開発者に提供することです。
各開発サイクルの終わりに、そのサイクル中に作成されたサブモデルがマージされ、完全な物理モデルがアプリケーションの開発と並行して形成されます。
ビューとインデックスをうまく活用する
ビューとインデックスは、アプリケーションのパフォーマンスを向上させるためのデータベース設計における 2 つの基本的なツールです。 ビューを使用すると、不要なテーブルの詳細を隠して、クエリを簡素化する抽象化を処理できます。 ビューを使用すると、データがどのように取得されるかを予測し、クエリ結果をより迅速に提供するための最適な戦略を選択できるため、データベース エンジンのクエリ最適化タスクが容易になります。
インデックスは、データベースが本番環境に入ると、ユーザー エクスペリエンスに基づいて低速クエリのパフォーマンスを向上させることができます。 ただし、インデックスの作成は、アプリケーションのニーズを予測して、データベース設計タスクの一部として行うことができます。
インデックスを作成するには、レコード数の観点から各テーブルの大きさを概算してから、より大きなテーブルのインデックスを作成する必要があります。 インデックスに含めるフィールドを選択するには、主に外部キーを表すフィールドと、検索でフィルターとして使用されるフィールドを考慮する必要があります。
作業が完了したと思ったら、リファクタリングの時期です。
データベースの設計はいつでも改善できます。 新しい要件や新しいビジネス ニーズのためにデータベースに変更がない場合は、設計を改善するリファクタリング手順を実行する良い機会です。 リファクタリングとは、単純に、データベースのセマンティクスに影響を与えずに設計を改善する変更を導入することを意味します。
データベースの設計を改善するためのリファクタリング手法は数多くありますが、この記事の範囲を超えていますが、必要に応じて使用できるように、それらの手法の存在を知っておくことをお勧めします。
データベースを設計する必要があるときは常に、このベスト プラクティスのリストを手元に置いておくことで、アプリケーションがデータ アクセスで常に最適なパフォーマンスを維持できるように、最良の結果を得ることができます。