
Best practice per la progettazione di database per app ad alte prestazioni
Pubblicato: 2021-07-19Affinché un'applicazione abbia buone prestazioni, è necessario un potente server delle applicazioni, una larghezza di banda garantita e ampia e un lavoro di programmazione ben fatto. Ma c'è un aspetto che non viene sempre preso in considerazione e che di solito ha un grande impatto sulle prestazioni di qualsiasi applicazione: il design del database .
Esamineremo ora le migliori pratiche di progettazione del database per garantire che l'accesso ai dati non rappresenti un collo di bottiglia che influisca negativamente sulle prestazioni delle applicazioni.
Qual è lo scopo di una buona progettazione di database?
Oltre a migliorare le prestazioni di accesso ai dati, una buona progettazione consente di ottenere altri vantaggi, come mantenere la coerenza, l'accuratezza e l'affidabilità dei dati e ridurre lo spazio di archiviazione eliminando le ridondanze. Un altro vantaggio di una buona progettazione è che il database è più facile da usare e mantenere. Chiunque debba gestirlo dovrà solo guardare il diagramma entità-relazione (ERD) per capirne la struttura.
Gli ERD sono lo strumento fondamentale per la progettazione di database. Possono essere creati e visualizzati a tre livelli di progettazione: concettuale , logico e fisico .
Il progetto concettuale mostra un diagramma molto sintetico, con solo gli elementi necessari per concordare i criteri con gli stakeholder del progetto, che non hanno bisogno di comprendere i dettagli tecnici del database. Il design logico mostra le entità e le loro relazioni in dettaglio ma in modo indipendente dal database.
Esistono molti strumenti che è possibile utilizzare per facilitare la progettazione di database da ERD. Tra i migliori ci sono DbSchema , SqlDBM e Vertabelo .
Schema Db
DbSchema consente di progettare e gestire visivamente database SQL, NoSQL o Cloud. Lo strumento consente di progettare lo schema su un computer e distribuirlo a più database e generare documentazione in diagrammi HTML5, scrivere query ed esplorare visivamente i dati, tra gli altri. Offre inoltre la sincronizzazione degli schemi, la generazione casuale di dati e la modifica del codice SQL con completamento automatico.

SqlDBM
SqlDBM è uno dei migliori strumenti di progettazione di diagrammi di database perché fornisce un modo semplice per progettare il database in qualsiasi browser. Non sono necessari altri motori di database o strumenti di modellazione per utilizzarlo, sebbene SqlDBM consenta di importare uno schema da un database esistente. È ideale per il lavoro di squadra, in quanto consente di condividere progetti di design con i colleghi.
Vertabello
Vertabelo è uno strumento di progettazione di database visivo online che consente di progettare un database in modo logico e derivare automaticamente lo schema fisico. Può eseguire il reverse engineering, generare diagrammi da database esistenti e controllare l'accesso ai diagrammi differenziando i privilegi di accesso a proprietari, editor e visualizzatori.
Infine, il design fisico è quello che aggiunge all'ERD tutti i dettagli necessari per trasformarlo in un database utilizzabile in un particolare DBMS, come MySQL, MariaDB, MS SQL Server o qualsiasi altro. Diamo un'occhiata alle migliori pratiche da tenere a mente quando si progetta un ERD in modo che il database risultante funzioni al meglio.
Definire il tipo di database da progettare
Solitamente si distinguono due tipologie fondamentali di database: relazionale e dimensionale .
I database relazionali vengono utilizzati per le applicazioni tradizionali che eseguono transazioni sui dati, ovvero ottengono informazioni dal database, le elaborano e archiviano i risultati.
I database dimensionali, invece, vengono utilizzati per la creazione di data warehouse: grandi repository di informazioni per l'analisi dei dati e il data mining per ottenere insight.
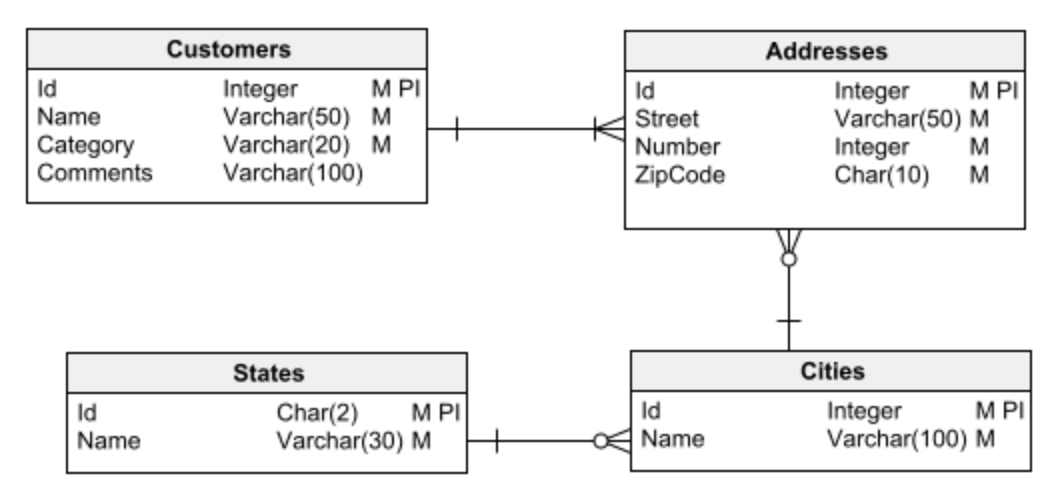
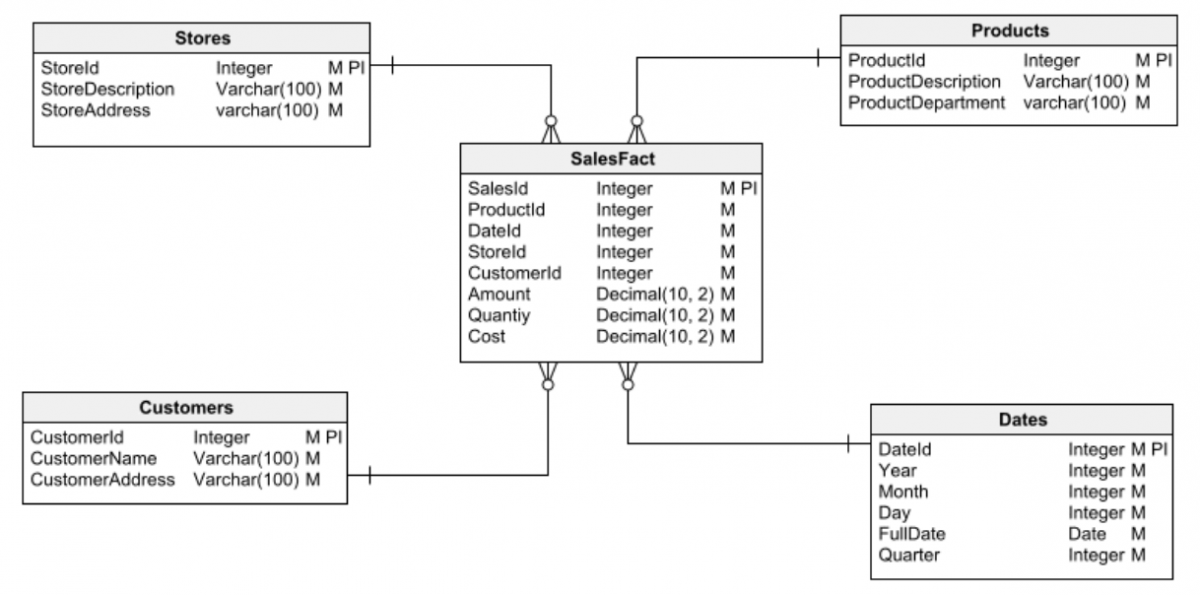
Il primo passaggio in qualsiasi attività di progettazione di database è scegliere uno dei due principali tipi di database con cui lavorare: relazionale o dimensionale. È fondamentale avere questo chiaro prima di iniziare a progettare. Altrimenti, puoi facilmente cadere in errori di progettazione che alla fine porteranno a molti problemi e sarà difficile (o impossibile) da correggere.
Adozione di una convenzione di denominazione
I nomi utilizzati nella progettazione del database sono essenziali perché, una volta creato un oggetto in un database, cambiarne il nome può essere fatale. La modifica di una sola lettera del nome può interrompere dipendenze, relazioni e persino interi sistemi.
Ecco perché è fondamentale lavorare con una sana convenzione di denominazione: un insieme di regole che ti evita la fatica di provare 50 diverse possibilità per trovare il nome di un oggetto che non ricordi.
Non esiste una guida universale su come dovrebbe essere una convenzione di denominazione per svolgere il proprio lavoro. Ma la cosa importante è stabilire una convenzione di denominazione prima di nominare uno qualsiasi degli oggetti in un database e mantenere quella convenzione per sempre. Una convenzione di denominazione stabilisce linee guida come se utilizzare un trattino basso per separare le parole o unirle direttamente, se utilizzare tutte le lettere maiuscole o le parole in maiuscolo (stile Camel Case), se utilizzare parole plurali o singolari per nominare oggetti e così via.
Inizia con il design concettuale, poi il design logico e infine il design fisico.
Questo è l'ordine naturale delle cose. Come designer, potresti essere tentato di iniziare creando oggetti direttamente sul DBMS per saltare i passaggi. Ma questo ti impedirà di avere uno strumento per discutere con le parti interessate per garantire che il design soddisfi i requisiti aziendali.
Dopo la progettazione concettuale, è necessario passare alla progettazione logica per disporre di una documentazione adeguata per aiutare i programmatori a comprendere la struttura del database. È fondamentale mantenere aggiornata la progettazione logica in modo che sia indipendente dal motore di database da utilizzare. In questo modo, se alla fine si migra il database su un motore diverso, la progettazione logica sarà comunque utile.
Infine, il progetto fisico può essere creato dagli stessi programmatori o da un DBA, prendendo il progetto logico e aggiungendo tutti i dettagli implementativi necessari per implementarlo su un particolare DBMS.
Creare e mantenere un dizionario di dati
Anche se un ERD è chiaro e descrittivo, dovresti aggiungere un dizionario di dati per renderlo ancora più chiaro. Il dizionario dei dati mantiene la coerenza e l'uniformità nella progettazione del database, in particolare quando il numero di oggetti in esso contenuto aumenta in modo significativo.
Lo scopo principale del dizionario dei dati è mantenere un unico repository di informazioni di riferimento sulle entità di un modello di dati e sui suoi attributi. Il dizionario dei dati dovrebbe contenere i nomi di tutte le entità, i nomi di tutti gli attributi, i loro formati e tipi di dati e una breve descrizione di ciascuno.

Il dizionario dei dati fornisce una guida chiara e concisa a tutti gli elementi che compongono il database. Ciò evita di creare più oggetti che rappresentano la stessa cosa, il che rende difficile sapere a quale oggetto ricorrere quando è necessario interrogare o aggiornare le informazioni.
Mantenere criteri coerenti per le chiavi primarie
La decisione di utilizzare chiavi naturali o chiavi surrogate deve essere coerente all'interno di un modello di dati. Se le entità in un modello di dati hanno identificatori univoci che possono essere gestiti in modo efficiente come chiavi primarie delle rispettive tabelle, non è necessario creare chiavi surrogate.
Ma è comune che le entità siano identificate da più attributi di tipo diverso – date, numeri e/o lunghe stringhe di caratteri – che possono essere inefficienti per formare chiavi primarie. In questi casi è preferibile creare chiavi surrogate di tipo numerico intero, che garantiscono la massima efficienza nella gestione degli indici. E la chiave surrogata è l'unica opzione se un'entità non dispone di attributi che la identifichino in modo univoco.
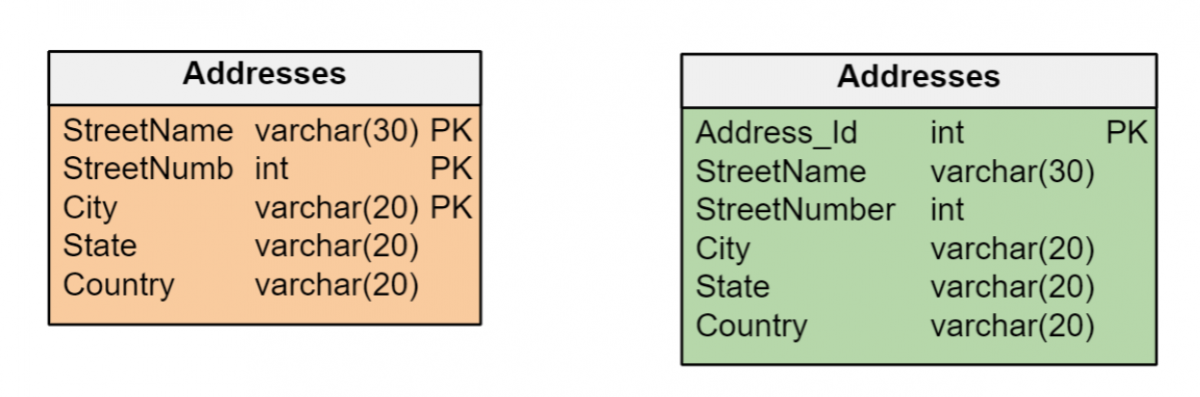
Utilizzare i tipi di dati corretti per ogni attributo.
Alcuni dati ci danno la possibilità di scegliere quale tipo di dati utilizzare per rappresentarli. Date, per esempio. Possiamo scegliere di memorizzarli in campi di tipo data, campi di tipo data/ora, campi di tipo varchar o anche campi di tipo numerico. Un altro caso sono i dati numerici che non vengono utilizzati per operazioni matematiche ma per identificare un'entità, come il numero di una patente o un codice postale.
Nel caso delle date, è conveniente utilizzare il tipo di dati del motore, che semplifica la manipolazione dei dati. Se si vuole memorizzare solo la data di un evento senza specificare l'ora, il tipo di dati da scegliere sarà semplicemente Data; se è necessario memorizzare la data e l'ora in cui si è verificato un determinato evento, il tipo di dati dovrebbe essere DateTime.
L'utilizzo di altri tipi, come varchar o numeric, per memorizzare le date può essere conveniente, ma solo in casi molto particolari. Ad esempio, se non è noto in anticipo in quale formato verrà espressa una data, è conveniente memorizzarla come varchar. Se le prestazioni di ricerca, l'ordinamento o l'indicizzazione sono fondamentali nella gestione dei campi di tipo data, una precedente conversione in float può fare la differenza.
I dati numerici non coinvolti in operazioni matematiche dovrebbero essere rappresentati come varchar, applicando convalide di formato nella registrazione per evitare incongruenze o ripetizioni. In caso contrario, ti esponi al rischio che alcuni dati superino i limiti dei campi numerici e ti costringano a rifattorizzare un progetto quando è già in produzione.
Uso di tabelle di ricerca
Alcuni progettisti inesperti potrebbero ritenere che l'uso eccessivo di tabelle di ricerca per normalizzare un progetto possa complicare inutilmente l'ERD di un database perché aggiunge un gran numero di tabelle "satellitari" che a volte non hanno più di una manciata di elementi. Chi pensa questo dovrebbe capire che l'uso delle tabelle di ricerca ha molti più vantaggi che svantaggi. Se la complessità o la dimensione di un ERD è un problema, esistono strumenti di progettazione ERD che consentono di visualizzare i diagrammi in modi diversi per essere compresi nonostante la loro complessità.
Questa query di esempio illustra l'uso corretto delle tabelle di ricerca in un database ben progettato:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdIn questo caso, utilizziamo tabelle di ricerca per città e stati.
I vantaggi delle tabelle di ricerca includono, tra gli altri, la riduzione delle dimensioni del database, il miglioramento delle prestazioni di ricerca e l'imposizione di restrizioni sul set di dati valido che un campo può contenere. È inoltre buona norma che tutte le tabelle di ricerca includano un campo Bit o Booleano che indica se un record nella tabella è in uso o è obsoleto. Questo campo può essere utilizzato come filtro per evitare elementi obsoleti come opzioni nell'interfaccia utente dell'applicazione.
Normalizza o denormalizza in base al tipo di database
Nei database relazionali utilizzati per le applicazioni tradizionali, la normalizzazione è un must. È noto che la normalizzazione riduce lo spazio di archiviazione richiesto evitando ridondanze. Migliora la qualità delle informazioni e fornisce più strumenti per ottimizzare le prestazioni in query complesse.
Tuttavia, in altri tipi di database viene applicata una tecnica nota come denormalizzazione. Nei database dimensionali, utilizzati come data warehouse, la denormalizzazione aggiunge alcune informazioni utili ridondanti nelle tabelle degli schemi.
Sebbene sembrino concetti opposti, la denormalizzazione non significa annullare la normalizzazione. In realtà è una tecnica di ottimizzazione applicata a un modello di dati dopo averlo normalizzato per semplificare la scrittura e il reporting delle query.
Progettazione di modelli fisici in parti
In un progetto di sviluppo software, il progettista di database presenta un modello concettuale su larga scala alle parti interessate, in cui non vengono mostrati i dettagli di implementazione. A sua volta, per lavorare con gli sviluppatori, il progettista deve fornire un modello fisico con tutti i dettagli di ogni entità e attributo. Tuttavia, non è necessario creare entrambi i modelli completamente all'inizio del progetto.
Quando si applicano metodologie agili, ogni sviluppatore all'inizio di ogni ciclo di sviluppo prende una o più storie utente con cui lavorare durante quel ciclo. Il compito del progettista di database è fornire a ogni sviluppatore un sottomodello fisico che includa solo gli oggetti necessari per un'unità di lavoro.
Alla fine di ogni ciclo di sviluppo, i sottomodelli creati durante quel ciclo vengono uniti in modo che il modello fisico completo prenda forma parallelamente allo sviluppo dell'applicazione.
Fare buon uso di viste e indici
Le viste e gli indici sono due strumenti fondamentali nella progettazione di database per migliorare le prestazioni delle applicazioni. L'uso delle viste consente di gestire astrazioni che semplificano le query, nascondendo i dettagli delle tabelle non necessari. A loro volta, le visualizzazioni semplificano le attività di ottimizzazione delle query per i motori di database poiché consentono loro di anticipare come verranno ottenuti i dati e di scegliere le strategie migliori per fornire i risultati delle query più rapidamente.
Gli indici possono migliorare le prestazioni di una query lenta in base all'esperienza utente una volta che il database è in produzione. Tuttavia, la creazione dell'indice può essere eseguita come parte delle attività di progettazione del database, anticipando le esigenze dell'applicazione.
Per la creazione di indici, è necessario avere un'idea approssimativa della grandezza di ciascuna tabella – in termini di conteggio dei record – e quindi creare indici per le tabelle più grandi. Per scegliere i campi da includere in un indice, devi considerare principalmente quelli che rappresentano chiavi esterne e quelli che verranno utilizzati come filtri nelle ricerche.
Quando pensi che il lavoro sia finito, è tempo di refactoring.
La progettazione di un database può sempre essere migliorata. Quando non ci sono modifiche al database dovute a nuovi requisiti o nuove esigenze aziendali, è una buona opportunità per eseguire procedure di refactoring che migliorano il design. Refactoring significa semplicemente questo: introdurre modifiche che migliorano un design senza intaccare la semantica del database.
Esistono molte tecniche di refactoring per migliorare la progettazione di un database che esulano dallo scopo di questo articolo, ma è bene sapere della loro esistenza per utilizzarle quando necessario.
Avere a portata di mano questo elenco di buone pratiche ogni volta che è necessario progettare un database ti consentirà di ottenere i migliori risultati in modo che le applicazioni mantengano sempre prestazioni ottimali nell'accesso ai dati.