
Рекомендации по проектированию баз данных для высокопроизводительных приложений
Опубликовано: 2021-07-19Чтобы приложение имело хорошую производительность, вам нужен мощный сервер приложений, гарантированная и достаточная пропускная способность, а также хорошо выполненная работа по программированию. Но есть один аспект, который не всегда принимается во внимание и который обычно оказывает большое влияние на производительность любого приложения: дизайн базы данных .
Теперь мы рассмотрим лучшие практики проектирования баз данных, чтобы убедиться, что доступ к данным не является узким местом, отрицательно влияющим на производительность приложений.
Какова цель хорошего дизайна базы данных?
В дополнение к повышению производительности доступа к данным, хороший дизайн дает и другие преимущества, такие как поддержание согласованности, точности и надежности данных, а также сокращение места для хранения за счет устранения избыточности. Еще одно преимущество хорошего дизайна заключается в том, что базу данных проще использовать и обслуживать. Любой, кто должен управлять им, должен будет только взглянуть на диаграмму сущность-связь (ERD), чтобы понять ее структуру.
ERD являются основным инструментом проектирования баз данных. Их можно создавать и визуализировать на трех уровнях проектирования: концептуальном , логическом и физическом .
В концептуальном проекте показана очень обобщенная диаграмма, содержащая только элементы, необходимые для согласования критериев с заинтересованными сторонами проекта, которым не нужно разбираться в технических деталях базы данных. Логический план показывает сущности и их отношения подробно, но независимо от базы данных.
Существует множество инструментов, которые можно использовать для облегчения проектирования баз данных из ERD. Среди лучших — DbSchema , SqlDBM и Vertabelo .
ДбСхема
DbSchema позволяет визуально проектировать и управлять базами данных SQL, NoSQL или Cloud. Инструмент позволяет создавать схему на компьютере и развертывать ее в нескольких базах данных, а также создавать документацию в виде диаграмм HTML5, писать запросы и визуально исследовать данные, среди прочего. Он также предлагает синхронизацию схемы, генерацию случайных данных и редактирование кода SQL с автозавершением.

SqlDBM
SqlDBM — один из лучших инструментов проектирования диаграмм баз данных, поскольку он обеспечивает простой способ проектирования базы данных в любом браузере. Для его использования не требуется никакого другого ядра базы данных или инструментов моделирования, хотя SqlDBM позволяет импортировать схему из существующей базы данных. Он идеально подходит для командной работы, так как позволяет обмениваться дизайн-проектами с коллегами.
Вертабело
Vertabelo — это онлайн-инструмент визуального проектирования баз данных, который позволяет вам логически проектировать базу данных и автоматически получать физическую схему. Он может реконструировать, генерировать диаграммы из существующих баз данных и контролировать доступ к диаграммам, разграничивая привилегии доступа для владельцев, редакторов и зрителей.
Наконец, физический дизайн — это тот, который добавляет к ERD все необходимые детали, чтобы превратить его в пригодную для использования базу данных в конкретной СУБД, такой как MySQL, MariaDB, MS SQL Server или любой другой. Давайте рассмотрим лучшие практики, которые следует учитывать при разработке ERD, чтобы результирующая база данных работала наилучшим образом.
Определите тип базы данных для проектирования
Обычно выделяют два основных типа баз данных: реляционные и многомерные .
Реляционные базы данных используются для традиционных приложений, которые выполняют транзакции с данными, то есть получают информацию из базы данных, обрабатывают ее и сохраняют результаты.
С другой стороны, многомерные базы данных используются для создания хранилищ данных: больших хранилищ информации для анализа данных и интеллектуального анализа данных для получения информации.
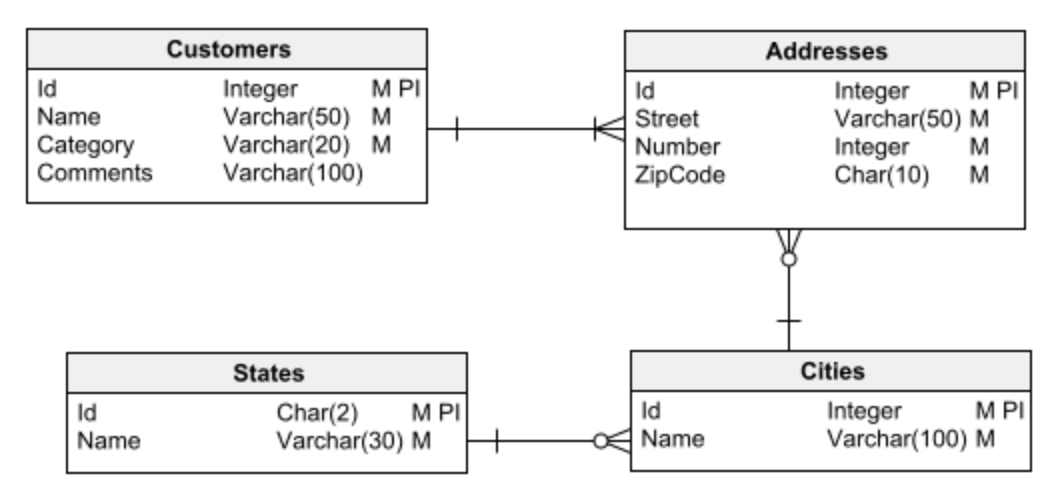
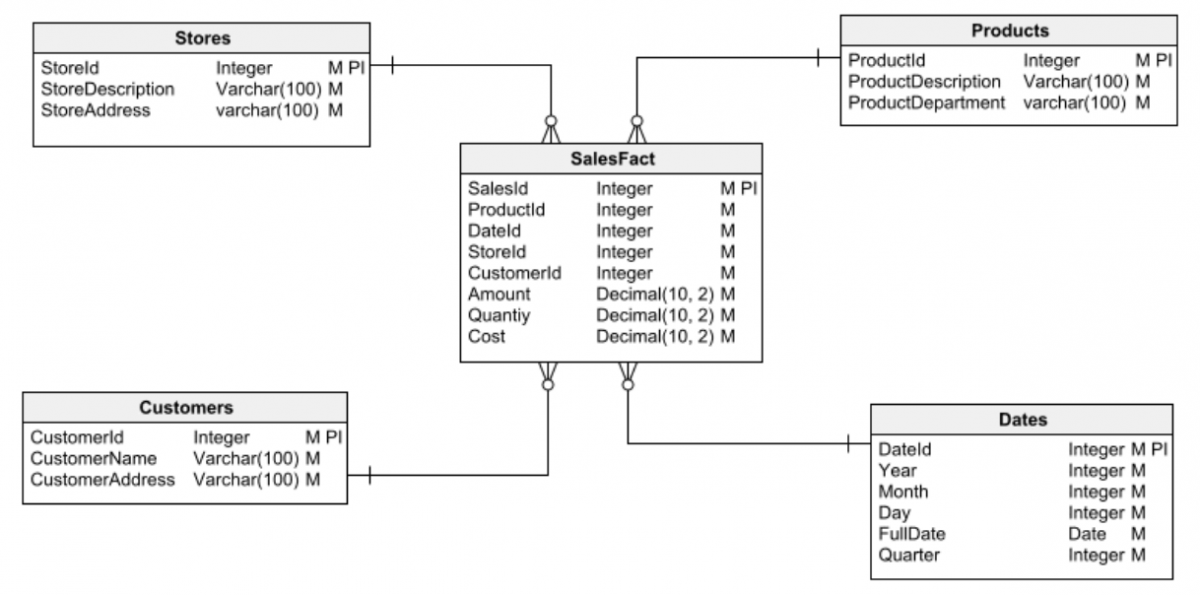
Первым шагом в любой задаче проектирования базы данных является выбор одного из двух основных типов баз данных для работы: реляционная или многомерная. Очень важно иметь это ясно, прежде чем начать проектирование. В противном случае вы можете легко нарваться на ошибки проектирования, которые со временем приведут ко многим проблемам и их будет трудно (или невозможно) исправить.
Принятие соглашения об именах
Имена, используемые при проектировании базы данных, очень важны, поскольку после создания объекта в базе данных изменение его имени может оказаться фатальным. Изменение всего одной буквы имени может нарушить зависимости, отношения и даже целые системы.
Вот почему так важно работать со здоровым соглашением об именах: набором правил, которые избавят вас от необходимости пробовать 50 различных вариантов, чтобы найти имя объекта, который вы не можете вспомнить.
Не существует универсального руководства о том, каким должно быть соглашение об именах, чтобы выполнять свою работу. Но важно установить соглашение об именовании, прежде чем называть любой из объектов в базе данных, и поддерживать это соглашение навсегда. Соглашение об именах устанавливает руководящие принципы, например, использовать ли подчеркивание для разделения слов или для их непосредственного соединения, использовать ли все заглавные буквы или заглавные слова (стиль Camel Case), использовать ли слова во множественном или единственном числе для именования объектов и так далее.
Начните с концептуального проекта, затем логического проекта и, наконец, физического проекта.
Это естественный порядок вещей. У вас, как у дизайнера, может возникнуть соблазн начать с создания объектов непосредственно в СУБД, чтобы пропустить шаги. Но это помешает вам иметь инструмент для обсуждения с заинтересованными сторонами, чтобы убедиться, что дизайн соответствует бизнес-требованиям.
После концептуального проектирования вы должны перейти к логическому проектированию, чтобы иметь адекватную документацию, которая поможет программистам понять структуру базы данных. Крайне важно постоянно обновлять логическую схему, чтобы она не зависела от используемого ядра базы данных. Таким образом, если вы в конечном итоге перенесете базу данных на другой движок, логическая схема все равно будет полезна.
Наконец, физический проект может быть создан самими программистами или администратором баз данных, взяв за основу логический проект и добавив все детали реализации, необходимые для его реализации в конкретной СУБД.
Создание и поддержка словаря данных
Даже если ERD четкий и описательный, вы должны добавить словарь данных, чтобы сделать его еще более понятным. Словарь данных поддерживает согласованность и согласованность структуры базы данных, особенно когда число объектов в нем значительно увеличивается.
Основное назначение словаря данных — поддерживать единый репозиторий справочной информации о сущностях модели данных и ее атрибутах. Словарь данных должен содержать имена всех сущностей, имена всех атрибутов, их форматы и типы данных, а также краткое описание каждого.

Словарь данных предоставляет четкое и краткое руководство по всем элементам, из которых состоит база данных. Это позволяет избежать создания нескольких объектов, представляющих одно и то же, что затрудняет определение того, к какому объекту обращаться, когда вам нужно запросить или обновить информацию.
Поддерживать согласованные критерии для первичных ключей
Решение об использовании естественных ключей или суррогатных ключей должно быть согласовано с моделью данных. Если сущности в модели данных имеют уникальные идентификаторы, которыми можно эффективно управлять как первичными ключами соответствующих таблиц, нет необходимости создавать суррогатные ключи.
Но обычно сущности идентифицируются несколькими атрибутами разных типов — датами, числами и/или длинными строками символов — что может быть неэффективным для формирования первичных ключей. В этих случаях лучше создавать суррогатные ключи целочисленного числового типа, которые обеспечивают максимальную эффективность в управлении индексами. А суррогатный ключ — единственный вариант, если объект не имеет атрибутов, однозначно идентифицирующих его.
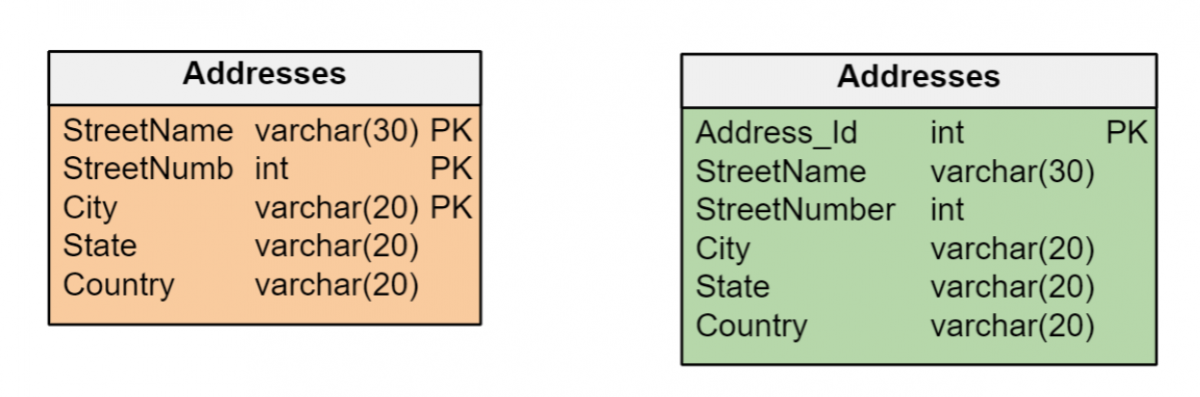
Используйте правильные типы данных для каждого атрибута.
Определенные данные дают нам возможность выбирать, какой тип данных использовать для их представления. Даты, например. Мы можем хранить их в полях типа даты, полях типа даты/времени, полях типа varchar или даже полях числового типа. Другим случаем являются числовые данные, которые используются не для математических операций, а для идентификации сущности, например номер водительского удостоверения или почтовый индекс.
В случае с датами удобно использовать тип данных движка, что упрощает манипулирование данными. Если вам нужно сохранить только дату события без указания времени, выберите тип данных просто Дата; если вам нужно сохранить дату и время, когда произошло определенное событие, тип данных должен быть DateTime.
Использование других типов, таких как varchar или numeric, для хранения дат может быть удобным, но только в особых случаях. Например, если заранее неизвестно, в каком формате будет выражена дата, ее удобно хранить как varchar. Если производительность поиска, сортировка или индексация имеют решающее значение при обработке полей типа даты, предыдущее преобразование в число с плавающей запятой может иметь значение.
Числовые данные, не задействованные в математических операциях, должны быть представлены в виде varchar, применяя проверки формата в записи, чтобы избежать несоответствий или повторений. В противном случае вы подвергаете себя риску того, что некоторые данные превышают ограничения числовых полей и вынуждают вас проводить рефакторинг проекта, когда он уже находится в производстве.
Использование таблиц поиска
Некоторые неопытные проектировщики могут полагать, что чрезмерное использование таблиц поиска для нормализации проекта может излишне усложнить ERD базы данных, поскольку при этом добавляется большое количество «вспомогательных» таблиц, которые иногда содержат не более нескольких элементов. Те, кто так думает, должны понимать, что использование таблиц поиска имеет гораздо больше преимуществ, чем недостатков. Если сложность или размер ERD является проблемой, существуют инструменты проектирования ERD, которые позволяют вам визуализировать диаграммы по-разному, чтобы их можно было понять, несмотря на их сложность.
Этот пример запроса иллюстрирует правильное использование таблиц поиска в хорошо спроектированной базе данных:
SELECT StreetName, StreetNumber, Cities.Name AS City, States.Name AS State FROM Addresses INNER JOIN Cities ON Cities.CityId = Addresses.CityId INNER JOIN States ON States.StateId = Addresses.StateIdВ этом случае мы используем таблицы поиска для городов и штатов.
Преимущества таблиц поиска включают, среди прочего, уменьшение размера базы данных, повышение производительности поиска и наложение ограничений на допустимый набор данных, который может содержать поле. Также рекомендуется включать во все таблицы поиска битовое или логическое поле, указывающее, используется ли запись в таблице или устарела. Это поле можно использовать в качестве фильтра, чтобы избежать использования устаревших элементов в качестве параметров пользовательского интерфейса приложения.
Нормализация или денормализация в зависимости от типа базы данных
В реляционных базах данных, используемых для традиционных приложений, нормализация является обязательной. Хорошо известно, что нормализация уменьшает требуемое пространство для хранения, избегая избыточности. Он повышает качество информации и предоставляет несколько инструментов для оптимизации производительности сложных запросов.
Однако в других типах баз данных применяется метод, известный как денормализация. В многомерных базах данных, используемых в качестве хранилищ данных, денормализация добавляет некоторую полезную избыточную информацию в таблицы схемы.
Хотя эти понятия кажутся противоположными, денормализация не означает отмену нормализации. На самом деле это метод оптимизации, применяемый к модели данных после ее нормализации для упрощения написания запросов и отчетов.
Проектирование физических моделей по частям
В проекте разработки программного обеспечения разработчик базы данных представляет заинтересованным сторонам крупномасштабную концептуальную модель, в которой не показаны детали реализации. В свою очередь, для работы с разработчиками дизайнер должен предоставить физическую модель со всеми подробностями каждой сущности и атрибута. Однако нет необходимости полностью создавать обе модели в начале проекта.
При применении гибких методологий каждый разработчик в начале каждого цикла разработки берет одну или несколько пользовательских историй для работы в течение этого цикла. Задача проектировщика базы данных состоит в том, чтобы предоставить каждому разработчику физическую подмодель, включающую только те объекты, которые ему нужны для рабочей единицы.
В конце каждого цикла разработки подмодели, созданные в течение этого цикла, объединяются, так что полная физическая модель приобретает форму параллельно с разработкой приложения.
Правильное использование представлений и индексов
Представления и индексы — это два основных инструмента проектирования баз данных для повышения производительности приложений. Использование представлений позволяет обрабатывать абстракции, которые упрощают запросы, скрывая ненужные детали таблицы. В свою очередь, представления упрощают задачи оптимизации запросов для механизмов баз данных, поскольку позволяют им предвидеть, как будут получены данные, и выбирать наилучшие стратегии для более быстрой доставки результатов запросов.
Индексы могут повысить производительность медленных запросов на основе взаимодействия с пользователем, когда база данных находится в рабочей среде. Однако создание индекса может быть выполнено как часть задач по проектированию базы данных, предвосхищая потребности приложения.
Для создания индексов вам необходимо иметь приблизительное представление о величине каждой таблицы с точки зрения количества записей, а затем создавать индексы для больших таблиц. Чтобы выбрать поля для включения в индекс, вы должны учитывать в основном те, которые представляют внешние ключи, и те, которые будут использоваться в качестве фильтров при поиске.
Когда вы думаете, что работа закончена, пора проводить рефакторинг.
Дизайн базы данных всегда можно улучшить. Когда в базу данных не вносятся изменения из-за новых требований или новых потребностей бизнеса, это хорошая возможность провести процедуры рефакторинга, улучшающие дизайн. Рефакторинг означает просто следующее: внесение изменений, улучшающих структуру, не влияющих на семантику базы данных.
Существует множество методов рефакторинга для улучшения структуры базы данных, которые выходят за рамки этой статьи, но полезно знать об их существовании, чтобы использовать их при необходимости.
Имея под рукой этот список лучших практик всякий раз, когда вам нужно спроектировать базу данных, вы сможете получить наилучшие результаты, чтобы приложения всегда поддерживали оптимальную производительность при доступе к данным.