
ETL คืออะไร: สุดยอดคู่มือ101
เผยแพร่แล้ว: 2022-05-25ยิ่งบริษัทเก็บรวบรวมข้อมูลจากแหล่งต่างๆ มากเท่าใด ความสามารถในการวิเคราะห์ วิทยาศาสตร์ข้อมูล และการเรียนรู้ของเครื่องก็จะยิ่งมากขึ้นเท่านั้น แต่พร้อมกับโอกาส ความกังวลก็เพิ่มขึ้นที่เกี่ยวข้องกับการประมวลผลข้อมูล ท้ายที่สุด ก่อนเริ่มสร้างรายงานและค้นหาข้อมูลเชิงลึก ข้อมูลดิบและข้อมูลที่ต่างกันทั้งหมดต้องได้รับการประมวลผล: ล้าง ตรวจสอบ แปลงเป็นรูปแบบเดียว และรวมเข้าด้วยกัน กระบวนการและเครื่องมือ Extract , Transform และ Load (หรือ ETL) ใช้สำหรับงานเหล่านี้ ในบทความนี้ เราจะวิเคราะห์โดยละเอียดว่า ETL คืออะไรและเหตุใดนักวิเคราะห์และนักการตลาดจึงต้องการเครื่องมือ ETL
สารบัญ
- ETL คืออะไรและเหตุใดจึงสำคัญ
- ประวัติโดยย่อว่า ETL เกิดขึ้นได้อย่างไร
- กระบวนการ ETL ทำงานอย่างไร
- ขั้นตอนที่ 1. ดึงข้อมูล
- ขั้นตอนที่ 2 แปลงข้อมูล
- ขั้นตอนที่ 3 โหลดข้อมูล
- ข้อดีของ ETL
- ความท้าทายของ ETL
- ETL กับ ELT — อะไรคือความแตกต่าง?
- เคล็ดลับ 5 ข้อเพื่อความสำเร็จในการใช้งาน ETL
- วิธีการเลือกเครื่องมือ ETL
- ETL/ELT และ OWOX BI
- ประเด็นที่สำคัญ
ETL คืออะไรและเหตุใดจึงสำคัญ
แยก, แปลง, โหลดเป็นกระบวนการรวมข้อมูลที่รองรับการวิเคราะห์ที่ขับเคลื่อนด้วยข้อมูลและประกอบด้วยสามขั้นตอน:
- ข้อมูลถูกดึงมาจากแหล่งต้นฉบับ
- ข้อมูลจะถูกแปลงเป็นรูปแบบที่เหมาะสมสำหรับการวิเคราะห์
- ข้อมูลถูกโหลดลงในที่จัดเก็บ Data Lake หรือระบบธุรกิจอัจฉริยะ
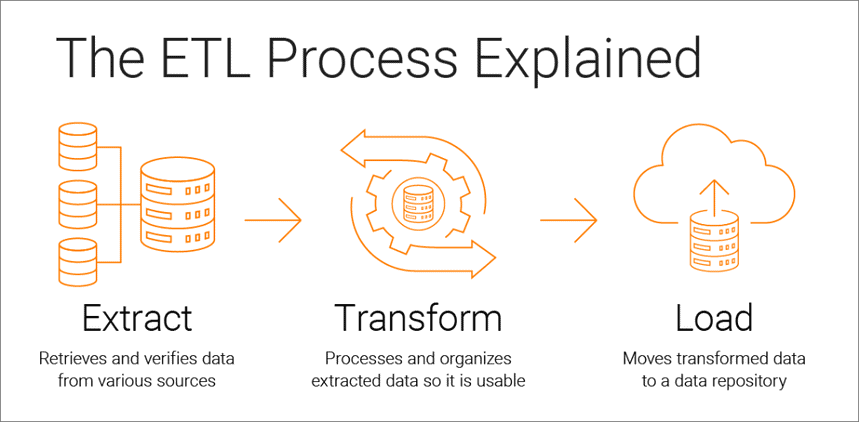
เครื่องมือ ETL ช่วยให้บริษัทรวบรวมข้อมูลประเภทต่างๆ จากหลายแหล่งและรวมข้อมูลดังกล่าวเพื่อทำงานร่วมกับข้อมูลดังกล่าวในที่จัดเก็บแบบรวมศูนย์ เช่น Google BigQuery, Snowflake หรือ Azure
กระบวนการแยก แปลง และโหลดเป็นพื้นฐานสำหรับการวิเคราะห์ข้อมูลที่ประสบความสำเร็จ และสร้างแหล่งข้อมูลที่เชื่อถือได้เพียงแหล่งเดียว เพื่อให้มั่นใจถึงความสอดคล้องและความเกี่ยวข้องของข้อมูลทั้งหมดของบริษัทของคุณ
เพื่อให้มีประโยชน์มากที่สุดสำหรับผู้มีอำนาจตัดสินใจ ระบบการวิเคราะห์ของธุรกิจจะต้องเปลี่ยนแปลงเมื่อธุรกิจเปลี่ยนไป ETL เป็นกระบวนการปกติ และระบบวิเคราะห์ของคุณจะต้องยืดหยุ่น เป็นอัตโนมัติ และมีเอกสารประกอบอย่างดี
ประวัติโดยย่อว่า ETL เกิดขึ้นได้อย่างไร
ETL ได้รับความนิยมในปี 1970 เมื่อบริษัทต่างๆ เริ่มทำงานกับที่เก็บหรือฐานข้อมูลหลายแห่ง ด้วยเหตุนี้ จึงจำเป็นต้องรวมข้อมูลทั้งหมดนี้อย่างมีประสิทธิภาพ
ในช่วงปลายทศวรรษ 1980 เทคโนโลยีการจัดเก็บข้อมูลปรากฏขึ้นซึ่งเสนอการเข้าถึงข้อมูลจากระบบที่แตกต่างกันหลายระบบ แต่ปัญหาคือฐานข้อมูลจำนวนมากต้องการเครื่องมือ ETL เฉพาะผู้จำหน่าย ดังนั้น แผนกต่างๆ จึงมักเลือกเครื่องมือ ETL ที่แตกต่างกันเพื่อใช้กับโซลูชันการจัดเก็บข้อมูลที่แตกต่างกัน สิ่งนี้นำไปสู่ความจำเป็นในการเขียนและปรับสคริปต์สำหรับแหล่งข้อมูลต่างๆ อย่างต่อเนื่อง ปริมาณข้อมูลและความซับซ้อนที่เพิ่มขึ้นนำไปสู่กระบวนการ ETL อัตโนมัติที่หลีกเลี่ยงการเข้ารหัสด้วยตนเอง
กระบวนการ ETL ทำงานอย่างไร
กระบวนการ ETL ประกอบด้วยสามขั้นตอน: แยก แปลง และโหลด ลองมาดูที่แต่ละของพวกเขา
ขั้นตอนที่ 1. ดึงข้อมูล
ในขั้นตอนนี้ ข้อมูลดิบ (ที่มีโครงสร้างและบางส่วน) จากแหล่งต่างๆ จะถูกแยกและวางในพื้นที่ระดับกลาง (ฐานข้อมูลชั่วคราวหรือเซิร์ฟเวอร์) สำหรับการประมวลผลในภายหลัง
แหล่งที่มาของข้อมูลดังกล่าวอาจเป็น:
- เว็บไซต์
- อุปกรณ์มือถือและแอพพลิเคชั่น
- ระบบ CRM/ERP
- อินเทอร์เฟซ API
- บริการด้านการตลาด
- เครื่องมือวิเคราะห์
- ฐานข้อมูล
- สภาพแวดล้อมบนคลาวด์ ไฮบริด และในองค์กร
- ไฟล์แบน
- สเปรดชีต
- เซิร์ฟเวอร์ SQL หรือ NoSQL
- อีเมล
- เครื่องมือถ่ายโอนข้อมูล Internet of Things (IoT) เช่น ตู้จำหน่ายสินค้าอัตโนมัติ ตู้เอทีเอ็ม และเซ็นเซอร์สินค้าโภคภัณฑ์
ข้อมูลที่รวบรวมจากแหล่งต่างๆ มักจะต่างกันและนำเสนอในรูปแบบต่างๆ: XML, JSON, CSV และอื่นๆ ดังนั้น ก่อนแยกข้อมูล คุณต้องสร้างแผนผังข้อมูลเชิงตรรกะที่อธิบายความสัมพันธ์ระหว่างแหล่งข้อมูลและข้อมูลเป้าหมาย
ในขั้นตอนนี้ จำเป็นต้องตรวจสอบว่า:
- ระเบียนที่แยกออกมาตรงกับข้อมูลต้นทาง
- สแปม/ข้อมูลที่ไม่ต้องการจะเข้าสู่การดาวน์โหลด
- ข้อมูลเป็นไปตามข้อกำหนดการจัดเก็บปลายทาง
- มีข้อมูลที่ซ้ำกันและกระจัดกระจาย
- กุญแจทั้งหมดอยู่ในสถานที่
สามารถดึงข้อมูลได้สามวิธี:
- การดึงข้อมูลบางส่วน — แหล่งที่มาจะแจ้งให้คุณทราบถึงการเปลี่ยนแปลงข้อมูลล่าสุด
- การดึงข้อมูลบางส่วนโดยไม่มีการแจ้งเตือน — แหล่งข้อมูลบางแห่งไม่มีการแจ้งเตือนการอัปเดต อย่างไรก็ตาม พวกเขาสามารถชี้ไปที่บันทึกที่มีการเปลี่ยนแปลงและให้ข้อความที่ตัดตอนมาจากบันทึกดังกล่าว
- การแยกข้อมูลทั้งหมด — บางระบบไม่สามารถระบุได้ว่าข้อมูลใดที่มีการเปลี่ยนแปลงเลย ในกรณีนี้ ทำได้เฉพาะการสกัดแบบสมบูรณ์เท่านั้น ในการดำเนินการดังกล่าว คุณจะต้องมีสำเนาของการอัปโหลดล่าสุดในรูปแบบเดียวกัน เพื่อค้นหาและทำการเปลี่ยนแปลง
ขั้นตอนนี้สามารถทำได้ด้วยตนเองโดยนักวิเคราะห์หรือโดยอัตโนมัติ อย่างไรก็ตาม การดึงข้อมูลด้วยตนเองใช้เวลานานและอาจนำไปสู่ข้อผิดพลาดได้ ดังนั้น เราขอแนะนำให้ใช้เครื่องมือเช่น OWOX BI ที่ทำให้กระบวนการ ETL เป็นอัตโนมัติและให้ข้อมูลคุณภาพสูงแก่คุณ
ขั้นตอนที่ 2 แปลงข้อมูล
ในขั้นตอนนี้ ข้อมูลดิบที่รวบรวมในพื้นที่ระดับกลาง (ที่เก็บข้อมูลชั่วคราว) จะถูกแปลงเป็นรูปแบบเดียวกันที่ตรงกับความต้องการของธุรกิจและข้อกำหนดของการจัดเก็บข้อมูลเป้าหมาย วิธีการนี้ — โดยใช้ตำแหน่งที่จัดเก็บระดับกลางแทนการอัพโหลดข้อมูลโดยตรงไปยังปลายทางสุดท้าย — ช่วยให้คุณสามารถย้อนกลับข้อมูลได้อย่างรวดเร็วหากมีสิ่งผิดปกติเกิดขึ้นกะทันหัน
การแปลงข้อมูลสามารถรวมถึงการดำเนินการต่อไปนี้:
- การทำความสะอาด — ขจัดความไม่สอดคล้องและความไม่ถูกต้องของข้อมูล
- การทำให้เป็นมาตรฐาน — แปลงประเภทข้อมูลทั้งหมดให้อยู่ในรูปแบบเดียวกัน: วันที่ สกุลเงิน ฯลฯ
- การขจัดข้อมูลซ้ำซ้อน — ยกเว้นหรือละทิ้งข้อมูลที่ซ้ำซ้อน
- การตรวจสอบ — ลบข้อมูลที่ไม่ได้ใช้และแฟล็กผิดปกติ
- จัดเรียงแถวหรือคอลัมน์ของข้อมูลใหม่
- การทำแผนที่ — รวมข้อมูลจากสองค่าเป็นหนึ่งหรือในทางกลับกัน แยกข้อมูลจากค่าหนึ่งเป็นสอง
- การเสริม — ดึงข้อมูลจากแหล่งอื่น
- การจัดรูปแบบข้อมูลลงในตารางตามสคีมาของการจัดเก็บข้อมูลเป้าหมาย
- การตรวจสอบคุณภาพข้อมูลและการตรวจสอบการปฏิบัติตามข้อกำหนด
- งานอื่นๆ — ใช้กฎเพิ่มเติม/ทางเลือกใดๆ เพื่อปรับปรุงคุณภาพข้อมูล ตัวอย่างเช่น ถ้าชื่อและนามสกุลในตารางอยู่ในคอลัมน์ที่ต่างกัน คุณสามารถรวมเข้าด้วยกันได้
การเปลี่ยนแปลงอาจเป็นส่วนที่สำคัญที่สุดของกระบวนการ ETL ช่วยให้คุณปรับปรุงคุณภาพข้อมูลและมั่นใจได้ว่าข้อมูลที่ประมวลผลแล้วจะถูกส่งไปยังที่จัดเก็บข้อมูลที่เข้ากันได้อย่างสมบูรณ์และพร้อมสำหรับการใช้ในการรายงานและงานทางธุรกิจอื่นๆ
จากประสบการณ์ของเรา บางบริษัทยังไม่ได้เตรียมข้อมูลให้พร้อมสำหรับธุรกิจและสร้างรายงานเกี่ยวกับข้อมูลดิบ ปัญหาหลักของวิธีนี้คือการดีบักและเขียนข้อความค้นหา SQL ใหม่ไม่รู้จบ ดังนั้น เราขอแนะนำว่าอย่าละเลยขั้นตอนนี้
OWOX BI รวบรวมข้อมูลดิบจากแหล่งต่างๆ โดยอัตโนมัติ และแปลงเป็นรูปแบบที่เหมาะกับรายงาน คุณได้รับชุดข้อมูลสำเร็จรูปที่แปลงเป็นโครงสร้างที่ต้องการโดยอัตโนมัติ โดยคำนึงถึงความแตกต่างที่สำคัญสำหรับนักการตลาด คุณไม่จำเป็นต้องใช้เวลาในการพัฒนาและสนับสนุนการเปลี่ยนแปลงที่ซับซ้อน เจาะลึกโครงสร้างข้อมูล และใช้เวลาหลายชั่วโมงเพื่อค้นหาสาเหตุของความคลาดเคลื่อน
ขั้นตอนที่ 3 โหลดข้อมูล
ณ จุดนี้ ข้อมูลที่ประมวลผลจากพื้นที่จัดเตรียมจะถูกอัปโหลดไปยังฐานข้อมูลเป้าหมาย ที่เก็บข้อมูล หรือ Data Lake ไม่ว่าจะในเครื่องหรือในคลาวด์
ซึ่งช่วยให้สามารถเข้าถึงข้อมูลที่พร้อมสำหรับธุรกิจสำหรับทีมต่างๆ ภายในบริษัทได้อย่างสะดวก
มีตัวเลือกการอัปโหลดหลายแบบ:
- โหลดเริ่มต้น — เติมตารางทั้งหมดในที่จัดเก็บข้อมูลเป็นครั้งแรก
- ภาระที่เพิ่มขึ้น — เขียนข้อมูลใหม่เป็นระยะตามความจำเป็น ในกรณีนี้ ระบบจะเปรียบเทียบข้อมูลขาเข้ากับข้อมูลที่มีอยู่แล้ว และสร้างระเบียนเพิ่มเติมเฉพาะเมื่อตรวจพบข้อมูลใหม่เท่านั้น วิธีนี้ช่วยลดต้นทุนการประมวลผลข้อมูลโดยการลดปริมาณข้อมูล
- อัปเดตแบบเต็ม — ลบเนื้อหาตารางและโหลดตารางใหม่ด้วยข้อมูลล่าสุด
คุณสามารถดำเนินการแต่ละขั้นตอนเหล่านี้โดยใช้เครื่องมือ ETL หรือด้วยตนเองโดยใช้โค้ดที่กำหนดเองและการสืบค้น SQL
ข้อดีของ ETL
1. ETL ช่วยประหยัดเวลาของคุณและช่วยให้คุณหลีกเลี่ยงการประมวลผลข้อมูลด้วยตนเอง
ประโยชน์ที่ใหญ่ที่สุดของกระบวนการ ETL คือช่วยให้คุณรวบรวม แปลง และรวบรวมข้อมูลโดยอัตโนมัติ คุณสามารถประหยัดเวลาและความพยายาม และขจัดความจำเป็นในการนำเข้าบรรทัดจำนวนมากด้วยตนเอง

2. ETL ทำให้ง่ายต่อการทำงานกับข้อมูลที่ซับซ้อน
เมื่อเวลาผ่านไป ธุรกิจของคุณต้องจัดการกับข้อมูลที่ซับซ้อนและหลากหลายจำนวนมาก เช่น เขตเวลา ชื่อลูกค้า รหัสอุปกรณ์ สถานที่ตั้ง ฯลฯ เพิ่มแอตทริบิวต์อีกสองสามรายการ แล้วคุณจะต้องจัดรูปแบบข้อมูลตลอดเวลา นอกจากนี้ ข้อมูลที่เข้ามายังสามารถอยู่ในรูปแบบที่แตกต่างกันและประเภทต่างๆ ETL ทำให้ชีวิตของคุณง่ายขึ้นมาก
3. ETL ช่วยลดความเสี่ยงที่เกี่ยวข้องกับปัจจัยมนุษย์
ไม่ว่าคุณจะระมัดระวังกับข้อมูลของคุณแค่ไหน คุณก็จะไม่มีภูมิคุ้มกันต่อข้อผิดพลาด ตัวอย่างเช่น ข้อมูลอาจถูกทำซ้ำโดยไม่ได้ตั้งใจในระบบเป้าหมาย หรือการป้อนข้อมูลด้วยตนเองอาจมีข้อผิดพลาด เครื่องมือ ETL ช่วยให้คุณหลีกเลี่ยงปัญหาดังกล่าวได้ด้วยการกำจัดอิทธิพลของมนุษย์
4. ETL ช่วยปรับปรุงการตัดสินใจ
ด้วยการทำงานอัตโนมัติของเวิร์กโฟลว์ข้อมูลที่สำคัญและลดโอกาสของข้อผิดพลาด ETL ช่วยให้มั่นใจได้ว่าข้อมูลที่คุณได้รับสำหรับการวิเคราะห์มีคุณภาพสูงและเชื่อถือได้ และข้อมูลที่มีคุณภาพเป็นพื้นฐานในการตัดสินใจขององค์กรที่ดีขึ้น
5. ETL เพิ่ม ROI
เนื่องจากช่วยประหยัดเวลา แรงกาย และทรัพยากร กระบวนการ ETL จึงช่วยปรับปรุง ROI ของคุณได้ในท้ายที่สุด นอกจากนี้ ด้วยการปรับปรุงการวิเคราะห์ธุรกิจ คุณจะเพิ่มผลกำไรของคุณ เนื่องจากบริษัทต่างๆ อาศัยกระบวนการ ETL ในการรับข้อมูลที่รวมเข้าด้วยกันและตัดสินใจทางธุรกิจได้ดีขึ้น
ความท้าทายของ ETL
เมื่อเลือกเครื่องมือ ETL คุณควรพึ่งพาข้อกำหนดของธุรกิจ ปริมาณข้อมูลที่รวบรวม และวิธีที่คุณใช้งานนั้นคุ้มค่า คุณจะพบความท้าทายอะไรบ้างเมื่อตั้งค่ากระบวนการ ETL
1. การประมวลผลข้อมูลจากแหล่งต่างๆ
บริษัทหนึ่งสามารถทำงานกับแหล่งข้อมูลหลายร้อยแห่งด้วยรูปแบบข้อมูลที่แตกต่างกัน ข้อมูลเหล่านี้อาจรวมถึงข้อมูลที่มีโครงสร้างและบางส่วน ข้อมูลการสตรีมแบบเรียลไทม์ ไฟล์แบบแฟลต ไฟล์ CSV ตะกร้า S3 แหล่งที่มาของการสตรีม และอื่นๆ ข้อมูลบางส่วนนี้แปลงเป็นแพ็กเก็ตได้ดีที่สุด ในขณะที่สำหรับการแปลงข้อมูลสตรีมมิงอื่นๆ ทำงานได้ดีกว่า การประมวลผลข้อมูลแต่ละประเภทอย่างมีประสิทธิภาพและใช้งานได้จริงอาจเป็นความท้าทายครั้งใหญ่
2. คุณภาพของข้อมูลเป็นสิ่งสำคัญยิ่ง
เพื่อให้การวิเคราะห์ทำงานอย่างมีประสิทธิภาพ คุณต้องแน่ใจว่าการแปลงข้อมูลถูกต้องและสมบูรณ์ การประมวลผลด้วยตนเอง การตรวจหาข้อผิดพลาดเป็นประจำ และการเขียนข้อความค้นหา SQL ใหม่ อาจส่งผลให้เกิดข้อผิดพลาด ทำซ้ำ หรือข้อมูลสูญหาย เครื่องมือ ETL ช่วยนักวิเคราะห์จากงานประจำและช่วยลดข้อผิดพลาด การตรวจสอบคุณภาพข้อมูลจะระบุความไม่สอดคล้องกันและการทำซ้ำ และฟังก์ชันการตรวจสอบจะเตือนว่าคุณกำลังจัดการกับประเภทข้อมูลที่เข้ากันไม่ได้และปัญหาอื่นๆ
3. ระบบวิเคราะห์ของคุณจะต้องปรับขนาดได้
จำนวนข้อมูลที่บริษัทรวบรวมจะเพิ่มขึ้นเรื่อยๆ ในช่วงหลายปีที่ผ่านมา สำหรับตอนนี้ คุณสามารถพอใจกับฐานข้อมูลในเครื่องและการดาวน์โหลดแบบกลุ่ม แต่จะเพียงพอสำหรับธุรกิจของคุณเสมอหรือไม่ เป็นการดีที่มีความเป็นไปได้ที่จะปรับขนาดกระบวนการ ETL และความจุเป็นอนันต์! เมื่อพูดถึงการตัดสินใจโดยใช้ข้อมูล ให้คิดให้ใหญ่และรวดเร็ว: ใช้ประโยชน์จากที่เก็บข้อมูลบนคลาวด์ (เช่น Google BigQuery) ที่ให้คุณประมวลผลข้อมูลจำนวนมากได้อย่างรวดเร็วและราคาถูก
ETL กับ ELT — อะไรคือความแตกต่าง?
ELT (แยก, โหลด, แปลง) เป็นรูปลักษณ์ที่ทันสมัยของกระบวนการ ETL ที่คุ้นเคย ซึ่งข้อมูลจะถูกแปลง หลังจาก โหลดไปยังที่จัดเก็บ
เครื่องมือ ETL แบบดั้งเดิมจะดึงและแปลงข้อมูลจากแหล่งต่างๆ ก่อนโหลดลงในที่จัดเก็บข้อมูล ด้วยการถือกำเนิดของที่เก็บข้อมูลบนคลาวด์ ไม่จำเป็นต้องล้างข้อมูลในขั้นตอนกลางระหว่างตำแหน่งที่เก็บข้อมูลต้นทางและปลายทาง
ELT มีความเกี่ยวข้องเป็นพิเศษกับการวิเคราะห์ขั้นสูง ตัวอย่างเช่น คุณสามารถอัปโหลดข้อมูลดิบลงใน Data Lake แล้วรวมเข้ากับข้อมูลจากแหล่งอื่นหรือใช้เพื่อฝึกโมเดลการคาดการณ์ การรักษาข้อมูลดิบช่วยให้นักวิเคราะห์ขยายขีดความสามารถได้ แนวทางนี้รวดเร็วเพราะใช้ประโยชน์จากกลไกการประมวลผลข้อมูลที่ทันสมัย และลดการย้ายข้อมูลที่ไม่จำเป็น
คุณควรเลือกแบบไหน? ETL หรือ ELT? หากคุณทำงานในพื้นที่และข้อมูลของคุณสามารถคาดเดาได้และมาจากแหล่งที่มาเพียงไม่กี่แห่ง ETL แบบเดิมก็เพียงพอแล้ว อย่างไรก็ตาม มีความเกี่ยวข้องน้อยลงเรื่อยๆ เนื่องจากมีบริษัทจำนวนมากขึ้นที่ย้ายไปยังสถาปัตยกรรมข้อมูลบนคลาวด์หรือไฮบริด
เคล็ดลับ 5 ข้อเพื่อความสำเร็จในการใช้งาน ETL
หากคุณต้องการใช้กระบวนการ ETL ที่ประสบความสำเร็จ ให้ทำตามขั้นตอนเหล่านี้:
ขั้นตอนที่ 1 ระบุแหล่งที่มาของข้อมูลที่คุณต้องการรวบรวมและจัดเก็บให้ชัดเจน แหล่งที่มาเหล่านี้อาจเป็นฐานข้อมูลเชิงสัมพันธ์ของ SQL, ฐานข้อมูลที่ไม่ใช่เชิงสัมพันธ์ NoSQL, แพลตฟอร์มซอฟต์แวร์เป็นบริการ (SaaS) หรือแอปพลิเคชันอื่นๆ เมื่อเชื่อมต่อแหล่งข้อมูลแล้ว ให้กำหนดเขตข้อมูลเฉพาะที่คุณต้องการแยก จากนั้นยอมรับหรือป้อนข้อมูลนี้จากแหล่งต่างๆ ในรูปแบบดิบ
ขั้นตอนที่ 2 รวมข้อมูลนี้โดยใช้ชุดกฎเกณฑ์ทางธุรกิจ (เช่น การรวม เอกสารแนบ การเรียงลำดับ ฟังก์ชันผสาน และอื่นๆ)
ขั้นตอนที่ 3 หลังจากการแปลงแล้ว ข้อมูลจะต้องโหลดลงสตอเรจ ในขั้นตอนนี้ คุณต้องตัดสินใจเกี่ยวกับความถี่ของการอัปโหลดข้อมูล ระบุว่าคุณต้องการบันทึกข้อมูลใหม่หรืออัปเดตข้อมูลที่มีอยู่
ขั้นตอนที่ 4 สิ่งสำคัญคือต้องตรวจสอบจำนวนเร็กคอร์ดก่อนและหลังการถ่ายโอนข้อมูลไปยังที่เก็บ ควรทำเพื่อแยกข้อมูลที่ไม่ถูกต้องและซ้ำซ้อน
ขั้นตอนที่ 5 ขั้นตอน สุดท้ายคือการทำให้กระบวนการ ETL เป็นแบบอัตโนมัติโดยใช้เครื่องมือพิเศษ ซึ่งจะช่วยให้คุณประหยัดเวลา ปรับปรุงความถูกต้อง และลดความพยายามในการรีสตาร์ทกระบวนการ ETL ด้วยตนเอง ด้วยเครื่องมืออัตโนมัติของ ETL คุณสามารถออกแบบและควบคุมเวิร์กโฟลว์ผ่านอินเทอร์เฟซที่เรียบง่าย นอกจากนี้ เครื่องมือเหล่านี้มีความสามารถ เช่น การทำโปรไฟล์และการล้างข้อมูล
วิธีการเลือกเครื่องมือ ETL
เริ่มต้นด้วย มาดูกันว่ามีเครื่องมือ ETL ใดบ้าง ปัจจุบันมีสี่ประเภทที่มีอยู่ บางส่วนได้รับการออกแบบมาให้ทำงานในสภาพแวดล้อมภายใน บางส่วนทำงานในระบบคลาวด์ และบางส่วนทำงานได้ทั้งสองสภาพแวดล้อม วิธีเลือกขึ้นอยู่กับว่าข้อมูลของคุณตั้งอยู่ที่ไหนและธุรกิจของคุณต้องการอะไร:
- เครื่องมือ ETL สำหรับการประมวลผลแบบกลุ่มของข้อมูลในที่จัดเก็บในตัวเครื่อง
- เครื่องมือ Cloud ETL ที่สามารถดึงและโหลดข้อมูลจากแหล่งที่มาโดยตรงไปยังที่เก็บข้อมูลบนคลาวด์ จากนั้นพวกเขาสามารถแปลงข้อมูลโดยใช้พลังและขนาดของคลาวด์ ตัวอย่าง: OWOX BI.
- เครื่องมือโอเพ่นซอร์ส ETL เช่น Apache Airflow, Apache Kafka และ Apache NiFi เป็นทางเลือกด้านงบประมาณสำหรับบริการแบบชำระเงิน บางส่วนไม่รองรับการเปลี่ยนแปลงที่ซับซ้อนและอาจมีปัญหาในการสนับสนุนลูกค้า
- เครื่องมือ ETL แบบเรียลไทม์ ข้อมูลได้รับการประมวลผลแบบเรียลไทม์โดยใช้โมเดลแบบกระจายและความสามารถในการสตรีมข้อมูล
สิ่งที่ต้องมองหาเมื่อเลือกเครื่องมือ ETL:
- ใช้งานง่ายและบำรุงรักษา
- ความเร็วในการทำงาน
- ระดับความปลอดภัย
- จำนวนและความหลากหลายของตัวเชื่อมต่อที่ต้องการ
- ความสามารถในการทำงานร่วมกับส่วนประกอบอื่นๆ ของแพลตฟอร์มข้อมูลของคุณได้อย่างราบรื่น รวมถึงการจัดเก็บข้อมูลและ data lakes
ETL/ELT และ OWOX BI
ด้วย OWOX BI คุณสามารถรวบรวมข้อมูลการตลาดสำหรับรายงานความซับซ้อนใดๆ ในที่เก็บข้อมูลบนคลาวด์ Google BigQuery ที่ปลอดภัย โดยไม่ต้องอาศัยความช่วยเหลือจากนักวิเคราะห์และนักพัฒนา
สิ่งที่คุณได้รับจาก OWOX BI:
- เก็บรวบรวมข้อมูลจากแหล่งต่างๆ โดยอัตโนมัติ
- นำเข้าข้อมูลดิบไปยัง Google BigQuery โดยอัตโนมัติ
- ทำความสะอาด ขจัดข้อมูลซ้ำซ้อน ตรวจสอบคุณภาพ และอัปเดตข้อมูล
- จัดเตรียมและสร้างแบบจำลองข้อมูลที่พร้อมสำหรับธุรกิจ
- สร้างรายงานโดยไม่ได้รับความช่วยเหลือจากนักวิเคราะห์หรือความรู้เกี่ยวกับ SQL
OWOX BI ช่วยเพิ่มเวลาอันมีค่าของคุณ ดังนั้นคุณจึงสามารถให้ความสำคัญกับการเพิ่มประสิทธิภาพแคมเปญโฆษณาและโซนการเติบโตได้
คุณไม่จำเป็นต้องรอรายงานจากนักวิเคราะห์อีกต่อไป รับแดชบอร์ดสำเร็จรูปหรือรายงานส่วนบุคคลที่อิงตามข้อมูลจำลองและเหมาะสำหรับธุรกิจของคุณ
ด้วยวิธีการเฉพาะของ OWOX BI คุณสามารถแก้ไขแหล่งข้อมูลและโครงสร้างข้อมูลโดยไม่ต้องเขียนทับการสืบค้น SQL หรือจัดลำดับรายงานใหม่ สิ่งนี้มีความเกี่ยวข้องอย่างยิ่งกับการเปิดตัว Google Analytics 4 ใหม่
ประเด็นที่สำคัญ
ปริมาณข้อมูลที่รวบรวมโดยบริษัทต่างๆ เพิ่มมากขึ้นทุกวันและจะเพิ่มขึ้นเรื่อยๆ ในตอนนี้ก็เพียงพอแล้วที่จะทำงานกับฐานข้อมูลในเครื่องและการดาวน์โหลดแบบกลุ่ม อย่างไรก็ตาม ในไม่ช้าก็จะไม่ตอบสนองความต้องการทางธุรกิจ ดังนั้น ความเป็นไปได้ในการปรับขนาดกระบวนการ ETL จึงมีประโยชน์และมีความเกี่ยวข้องอย่างยิ่งกับการวิเคราะห์ขั้นสูง
ข้อได้เปรียบหลักของเครื่องมือ ETL คือ:
- ประหยัดเวลาของคุณ
- หลีกเลี่ยงการประมวลผลข้อมูลด้วยตนเอง
- ทำให้ง่ายต่อการทำงานกับข้อมูลที่ซับซ้อน
- ลดความเสี่ยงที่เกี่ยวข้องกับปัจจัยมนุษย์
- ช่วยปรับปรุงการตัดสินใจ
- ROI ที่เพิ่มขึ้น
เมื่อต้องเลือกเครื่องมือ ETL ให้นึกถึงความต้องการเฉพาะของธุรกิจของคุณ หากคุณทำงานในพื้นที่และข้อมูลของคุณสามารถคาดเดาได้และมาจากแหล่งที่มาเพียงไม่กี่แห่ง ETL แบบเดิมก็เพียงพอแล้ว แต่อย่าลืมว่ามีบริษัทจำนวนมากขึ้นเรื่อยๆ ที่เปลี่ยนไปใช้สถาปัตยกรรมคลาวด์หรือไฮบริด และคุณต้องคำนึงถึงเรื่องนี้ด้วย