
Was ist ETL: der ultimative Leitfaden 101
Veröffentlicht: 2022-05-25Je mehr Daten aus verschiedenen Quellen ein Unternehmen sammelt, desto größer sind seine Fähigkeiten in den Bereichen Analytik, Data Science und maschinelles Lernen. Doch neben Chancen wachsen auch Sorgen im Zusammenhang mit der Datenverarbeitung. Schließlich müssen all diese rohen und unterschiedlichen Daten verarbeitet werden, bevor Sie mit der Erstellung von Berichten und der Suche nach Erkenntnissen beginnen: bereinigt, überprüft, in ein einziges Format konvertiert und zusammengeführt. Für diese Aufgaben werden Prozesse und Tools zum Extrahieren , Transformieren und Laden (oder ETL) verwendet. In diesem Artikel analysieren wir im Detail, was ETL ist und warum ETL-Tools von Analysten und Vermarktern benötigt werden.
Inhaltsverzeichnis
- Was ist ETL und warum ist es wichtig?
- Eine kurze Geschichte, wie ETL entstanden ist
- Wie der ETL-Prozess funktioniert
- Schritt 1. Daten extrahieren
- Schritt 2. Daten transformieren
- Schritt 3. Daten laden
- Vorteile von ETL
- Herausforderungen von ETL
- ETL vs. ELT – Was ist der Unterschied?
- 5 Tipps für eine erfolgreiche ETL-Implementierung
- So wählen Sie ein ETL-Tool aus
- ETL/ELT und OWOX BI
- Die zentralen Thesen
Was ist ETL und warum ist es wichtig?
Extract, Transform, Load ist ein Datenintegrationsprozess, der der datengesteuerten Analyse zugrunde liegt und aus drei Phasen besteht:
- Daten werden aus der ursprünglichen Quelle extrahiert
- Die Daten werden in ein für die Analyse geeignetes Format konvertiert
- Daten werden in einen Speicher, einen Data Lake oder ein Business-Intelligence-System geladen
ETL-Tools ermöglichen es Unternehmen, Daten verschiedener Art aus mehreren Quellen zu sammeln und diese Daten zusammenzuführen, um sie an einem zentralen Speicherort wie Google BigQuery, Snowflake oder Azure zu bearbeiten.
Extraktions-, Transformations- und Ladeprozesse bilden die Grundlage für eine erfolgreiche Datenanalyse und schaffen eine einzige Quelle zuverlässiger Daten, die die Konsistenz und Relevanz aller Daten Ihres Unternehmens gewährleisten.
Um für Entscheidungsträger so nützlich wie möglich zu sein, muss sich das Analysesystem eines Unternehmens ändern, wenn sich das Unternehmen ändert. ETL ist ein regelmäßiger Prozess, und Ihr Analysesystem muss flexibel, automatisiert und gut dokumentiert sein.
Eine kurze Geschichte, wie ETL entstanden ist
ETL wurde in den 1970er Jahren populär, als Unternehmen begannen, mit mehreren Repositories oder Datenbanken zu arbeiten. Infolgedessen wurde es notwendig, all diese Daten effektiv zu integrieren.
In den späten 1980er Jahren erschienen Datenspeichertechnologien, die einen integrierten Zugriff auf Daten aus mehreren heterogenen Systemen boten. Das Problem war jedoch, dass viele Datenbanken herstellerspezifische ETL-Tools erforderten. Daher haben sich verschiedene Abteilungen oft für unterschiedliche ETL-Tools zur Verwendung mit unterschiedlichen Datenspeicherlösungen entschieden. Dies führte dazu, dass ständig Skripte für unterschiedliche Datenquellen geschrieben und angepasst werden mussten. Die Zunahme des Datenvolumens und der Komplexität führte zu einem automatisierten ETL-Prozess, der manuelles Codieren vermeidet.
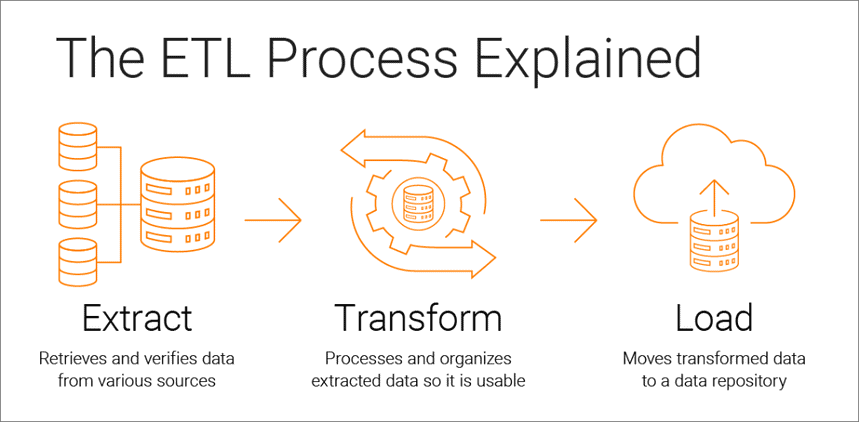
Wie der ETL-Prozess funktioniert
Der ETL-Prozess besteht aus drei Schritten: Extrahieren, Transformieren und Laden. Werfen wir einen genauen Blick auf jeden von ihnen.
Schritt 1. Daten extrahieren
In diesem Schritt werden rohe (strukturierte und teilweise strukturierte) Daten aus verschiedenen Quellen extrahiert und zur anschließenden Verarbeitung in einem Zwischenbereich (einer temporären Datenbank oder einem temporären Server) abgelegt.
Quellen solcher Daten können sein:
- Webseiten
- Mobile Geräte und Anwendungen
- CRM/ERP-Systeme
- API-Schnittstellen
- Marketing-Dienstleistungen
- Analyse-Tools
- Datenbanken
- Cloud-, Hybrid- und lokale Umgebungen
- Flache Dateien
- Tabellenkalkulationen
- SQL- oder NoSQL-Server
- Datenübertragungstools für das Internet der Dinge (IoT) wie Verkaufsautomaten, Geldautomaten und Warensensoren
Aus verschiedenen Quellen gesammelte Daten sind normalerweise heterogen und werden in verschiedenen Formaten präsentiert: XML, JSON, CSV und andere. Daher müssen Sie vor dem Extrahieren eine logische Datenzuordnung erstellen, die die Beziehung zwischen Datenquellen und den Zieldaten beschreibt.
In diesem Schritt muss überprüft werden, ob:
- Extrahierte Datensätze stimmen mit den Quelldaten überein
- Spam/unerwünschte Daten gelangen in den Download
- Die Daten erfüllen die Speicheranforderungen des Ziels
- Es gibt Duplikate und fragmentierte Daten
- Alle Schlüssel sind vorhanden
Daten können auf drei Arten extrahiert werden:
- Teilextraktion – Die Quelle benachrichtigt Sie über die neuesten Datenänderungen.
- Teilextraktion ohne Benachrichtigung – Nicht alle Datenquellen bieten eine Aktualisierungsbenachrichtigung; Sie können jedoch auf Datensätze verweisen, die sich geändert haben, und einen Auszug aus solchen Datensätzen bereitstellen.
- Vollständige Extraktion – Einige Systeme können überhaupt nicht feststellen, welche Daten geändert wurden; in diesem Fall ist nur eine vollständige Extraktion möglich. Dazu benötigen Sie eine Kopie des letzten Uploads im gleichen Format, damit Sie Änderungen finden und vornehmen können.
Dieser Schritt kann entweder manuell von Analysten oder automatisch durchgeführt werden. Das manuelle Extrahieren von Daten ist jedoch zeitaufwändig und kann zu Fehlern führen. Daher empfehlen wir die Verwendung von Tools wie OWOX BI, die den ETL-Prozess automatisieren und Ihnen qualitativ hochwertige Daten liefern.
Schritt 2. Daten transformieren
In diesem Schritt werden die in einem Zwischenbereich (Zwischenspeicher) gesammelten Rohdaten in ein einheitliches Format umgewandelt, das den Bedürfnissen des Unternehmens und den Anforderungen der Zieldatenspeicherung entspricht. Dieser Ansatz – die Verwendung eines Zwischenspeicherorts anstelle des direkten Hochladens von Daten zum endgültigen Ziel – ermöglicht es Ihnen, Daten schnell zurückzusetzen, wenn plötzlich etwas schief geht.
Die Datentransformation kann die folgenden Vorgänge umfassen:
- Bereinigung — Beseitigen Sie Dateninkonsistenzen und -ungenauigkeiten.
- Standardisierung – Wandeln Sie alle Datentypen in dasselbe Format um: Datumsangaben, Währungen usw.
- Deduplizierung – Schließen Sie redundante Daten aus oder verwerfen Sie sie.
- Validierung – Löschen Sie ungenutzte Daten und markieren Sie Anomalien.
- Zeilen oder Spalten von Daten neu sortieren
- Mapping – Führen Sie Daten von zwei Werten zu einem zusammen oder teilen Sie umgekehrt Daten von einem Wert in zwei auf.
- Ergänzen – Extrahieren Sie Daten aus anderen Quellen.
- Formatieren von Daten in Tabellen gemäß dem Schema des Zieldatenspeichers
- Prüfung der Datenqualität und Überprüfung der Compliance
- Andere Aufgaben — Wenden Sie alle zusätzlichen/optionalen Regeln an, um die Datenqualität zu verbessern; Wenn sich beispielsweise der Vor- und Nachname in der Tabelle in verschiedenen Spalten befinden, können Sie sie zusammenführen.
Transformation ist vielleicht der wichtigste Teil des ETL-Prozesses. Es hilft Ihnen, die Datenqualität zu verbessern und stellt sicher, dass verarbeitete Daten vollständig kompatibel und bereit für die Verwendung in Berichten und anderen Geschäftsaufgaben an den Speicher geliefert werden.
Unserer Erfahrung nach bereiten einige Unternehmen immer noch keine betriebsbereiten Daten vor und erstellen Berichte nicht auf Basis von Rohdaten. Das Hauptproblem bei diesem Ansatz ist das endlose Debuggen und Umschreiben von SQL-Abfragen. Daher empfehlen wir dringend, diese Phase nicht zu ignorieren.
OWOX BI sammelt automatisch Rohdaten aus verschiedenen Quellen und konvertiert sie in ein berichtsfreundliches Format. Sie erhalten vorgefertigte Datensätze, die automatisch in die gewünschte Struktur transformiert werden, unter Berücksichtigung der für Marketer wichtigen Nuancen. Sie müssen keine Zeit damit verbringen, komplexe Transformationen zu entwickeln und zu unterstützen, sich in die Datenstruktur einzuarbeiten und stundenlang nach den Ursachen von Abweichungen zu suchen.
Schritt 3. Daten laden
An diesem Punkt werden verarbeitete Daten aus dem Staging-Bereich entweder lokal oder in der Cloud in die Zieldatenbank, den Speicher oder den Data Lake hochgeladen.
Dies bietet verschiedenen Teams innerhalb des Unternehmens bequemen Zugriff auf betriebsbereite Daten.
Es gibt mehrere Upload-Optionen:
- Anfängliches Laden — Erstmaliges Füllen aller Tabellen im Datenspeicher.
- Inkrementelles Laden – Schreiben Sie regelmäßig nach Bedarf neue Daten. In diesem Fall vergleicht das System eingehende Daten mit bereits vorhandenen und erstellt zusätzliche Datensätze nur, wenn es neue Daten erkennt. Dieser Ansatz reduziert die Kosten der Datenverarbeitung durch Verringerung des Volumens.
- Vollständiges Update — Löschen Sie Tabelleninhalte und laden Sie die Tabelle mit den neuesten Daten neu.
Sie können jeden dieser Schritte mit ETL-Tools oder manuell mit benutzerdefiniertem Code und SQL-Abfragen ausführen.
Vorteile von ETL
1. ETL spart Ihnen Zeit und hilft Ihnen, manuelle Datenverarbeitung zu vermeiden.
Der größte Vorteil des ETL-Prozesses besteht darin, dass er Ihnen hilft, Daten automatisch zu sammeln, zu konvertieren und zu konsolidieren. Sie können Zeit und Mühe sparen und den manuellen Import einer großen Anzahl von Zeilen überflüssig machen.

2. ETL erleichtert die Arbeit mit komplexen Daten.
Im Laufe der Zeit muss Ihr Unternehmen mit einer großen Menge komplexer und vielfältiger Daten umgehen: Zeitzonen, Kundennamen, Geräte-IDs, Standorte usw. Fügen Sie ein paar weitere Attribute hinzu, und Sie müssen Daten rund um die Uhr formatieren. Außerdem können eingehende Daten in unterschiedlichen Formaten und unterschiedlichen Typen vorliegen. ETL macht Ihr Leben viel einfacher.
3. ETL reduziert die mit dem menschlichen Faktor verbundenen Risiken.
Egal wie sorgfältig Sie mit Ihren Daten umgehen, Sie sind nicht vor Fehlern gefeit. Beispielsweise können Daten versehentlich im Zielsystem dupliziert werden oder eine manuelle Eingabe fehlerhaft sein. Durch die Eliminierung menschlicher Einflüsse hilft Ihnen ein ETL-Tool, solche Probleme zu vermeiden.
4. ETL hilft, die Entscheidungsfindung zu verbessern.
Durch die Automatisierung kritischer Datenworkflows und die Verringerung der Fehlerwahrscheinlichkeit stellt ETL sicher, dass die Daten, die Sie zur Analyse erhalten, von hoher Qualität sind und vertrauenswürdig sind. Und qualitativ hochwertige Daten sind von grundlegender Bedeutung, um bessere Unternehmensentscheidungen zu treffen.
5. ETL erhöht den ROI.
Da es Ihnen Zeit, Mühe und Ressourcen spart, hilft Ihnen der ETL-Prozess letztendlich, Ihren ROI zu verbessern. Darüber hinaus steigern Sie durch die Verbesserung der Geschäftsanalysen Ihre Gewinne. Denn Unternehmen verlassen sich auf den ETL-Prozess, um konsolidierte Daten zu erhalten und bessere Geschäftsentscheidungen zu treffen.
Herausforderungen von ETL
Bei der Auswahl eines ETL-Tools lohnt es sich, sich auf Ihre Geschäftsanforderungen, die Menge der gesammelten Daten und die Art und Weise, wie Sie es verwenden, zu verlassen. Auf welche Herausforderungen können Sie bei der Einrichtung des ETL-Prozesses stoßen?
1. Verarbeitung von Daten aus einer Vielzahl von Quellen.
Ein Unternehmen kann mit Hunderten von Quellen mit unterschiedlichen Datenformaten arbeiten. Dazu können strukturierte und teilweise strukturierte Daten, Echtzeit-Streaming-Daten, Flatfiles, CSV-Dateien, S3-Baskets, Streaming-Quellen und mehr gehören. Einige dieser Daten werden am besten in Paketen konvertiert, während für andere die Streaming-Datenkonvertierung besser funktioniert. Jede Art von Daten auf die effizienteste und praktischste Weise zu verarbeiten, kann eine große Herausforderung sein.
2. Datenqualität ist von größter Bedeutung.
Damit Analytics effizient funktioniert, müssen Sie eine genaue und vollständige Datentransformation sicherstellen. Manuelle Verarbeitung, regelmäßige Fehlererkennung und Neuschreiben von SQL-Abfragen können zu Fehlern, Duplizierung oder Datenverlust führen. ETL-Tools ersparen Analysten die Routine und helfen, Fehler zu reduzieren. Ein Datenqualitätsaudit identifiziert Inkonsistenzen und Duplikate, und Überwachungsfunktionen warnen, wenn Sie es mit inkompatiblen Datentypen und anderen Problemen zu tun haben.
3. Ihr Analysesystem muss skalierbar sein.
Die Menge an Daten, die Unternehmen sammeln, wird im Laufe der Jahre nur noch wachsen. Im Moment können Sie mit einer lokalen Datenbank und Batch-Downloads zufrieden sein, aber wird das für Ihr Unternehmen immer ausreichen? Es ist großartig, die Möglichkeit zu haben, ETL-Prozesse und -Kapazitäten ins Unendliche zu skalieren! Wenn es um datengesteuerte Entscheidungen geht, denken Sie groß und schnell: Nutzen Sie Cloud-Speicher (wie Google BigQuery), mit dem Sie große Datenmengen schnell und kostengünstig verarbeiten können.
ETL vs. ELT – Was ist der Unterschied?
ELT (Extract, Load, Transform) ist im Wesentlichen ein moderner Blick auf den bekannten ETL-Prozess, bei dem Daten konvertiert werden, nachdem sie in den Speicher geladen wurden.
Herkömmliche ETL-Tools extrahieren und konvertieren Daten aus verschiedenen Quellen, bevor sie in den Speicher geladen werden. Mit dem Aufkommen von Cloud-Speicher müssen Daten nicht mehr in der Zwischenphase zwischen Quell- und Zieldatenspeicherort bereinigt werden.
ELT ist besonders relevant für Advanced Analytics. Sie können beispielsweise Rohdaten in einen Data Lake hochladen und diese dann mit Daten aus anderen Quellen zusammenführen oder zum Trainieren von Vorhersagemodellen verwenden. Durch die Rohdatenhaltung können Analysten ihre Fähigkeiten erweitern. Dieser Ansatz ist schnell, da er die Leistungsfähigkeit moderner Datenverarbeitungsmechanismen nutzt und unnötige Datenbewegungen reduziert.
Welche sollten Sie wählen? ETL oder ELT? Wenn Sie lokal arbeiten und Ihre Daten vorhersehbar sind und nur aus wenigen Quellen stammen, reicht herkömmliches ETL aus. Es wird jedoch immer weniger relevant, da immer mehr Unternehmen auf Cloud- oder hybride Datenarchitekturen umsteigen.
5 Tipps für eine erfolgreiche ETL-Implementierung
Wenn Sie einen erfolgreichen ETL-Prozess implementieren möchten, gehen Sie folgendermaßen vor:
Schritt 1. Identifizieren Sie eindeutig die Quellen der Daten, die Sie sammeln und speichern möchten. Diese Quellen können relationale SQL-Datenbanken, nicht relationale NoSQL-Datenbanken, SaaS-Plattformen (Software as a Service) oder andere Anwendungen sein. Sobald die Datenquellen verbunden sind, definieren Sie die spezifischen Datenfelder, die Sie extrahieren möchten. Übernehmen oder geben Sie dann diese Daten aus verschiedenen Quellen in Rohform ein.
Schritt 2. Vereinheitlichen Sie diese Daten mithilfe einer Reihe von Geschäftsregeln (z. B. Aggregation, Anhang, Sortierung, Zusammenführungsfunktionen usw.).
Schritt 3. Nach der Transformation müssen die Daten in den Speicher geladen werden. In diesem Schritt müssen Sie die Häufigkeit des Hochladens von Daten festlegen. Geben Sie an, ob Sie neue Daten erfassen oder vorhandene Daten aktualisieren möchten.
Schritt 4. Es ist wichtig, die Anzahl der Datensätze vor und nach der Übertragung von Daten in das Repository zu überprüfen. Dies sollte erfolgen, um ungültige und redundante Daten auszuschließen.
Schritt 5. Der letzte Schritt besteht darin, den ETL-Prozess mit speziellen Tools zu automatisieren. Dies hilft Ihnen, Zeit zu sparen, die Genauigkeit zu verbessern und den Aufwand für den manuellen Neustart des ETL-Prozesses zu reduzieren. Mit ETL-Automatisierungstools können Sie einen Workflow über eine einfache Schnittstelle entwerfen und steuern. Darüber hinaus verfügen diese Tools über Funktionen wie Profilerstellung und Datenbereinigung.
So wählen Sie ein ETL-Tool aus
Lassen Sie uns zunächst herausfinden, welche ETL-Tools es gibt. Derzeit sind vier Typen verfügbar. Einige sind so konzipiert, dass sie in einer lokalen Umgebung funktionieren, andere in der Cloud und wieder andere in beiden Umgebungen. Welche Sie wählen sollten, hängt davon ab, wo sich Ihre Daten befinden und welche Anforderungen Ihr Unternehmen hat:
- ETL-Tools für die Stapelverarbeitung von Daten im lokalen Speicher.
- Cloud-ETL-Tools, die Daten aus Quellen extrahieren und direkt in den Cloud-Speicher laden können. Anschließend können sie die Daten mithilfe der Leistungsfähigkeit und Skalierbarkeit der Cloud umwandeln. Beispiel: OWOX BI.
- ETL-Open-Source-Tools wie Apache Airflow, Apache Kafka und Apache NiFi sind eine kostengünstige Alternative zu kostenpflichtigen Diensten. Einige unterstützen keine komplexen Transformationen und haben möglicherweise Probleme mit dem Kundensupport.
- Echtzeit-ETL-Tools. Die Daten werden mithilfe eines verteilten Modells und Datenstreaming-Funktionen in Echtzeit verarbeitet.
Worauf Sie bei der Auswahl eines ETL-Tools achten sollten:
- Benutzerfreundlichkeit und Wartung
- Geschwindigkeit der Arbeit
- Sicherheitsstufe
- Anzahl und Vielfalt der benötigten Anschlüsse
- Fähigkeit zur nahtlosen Zusammenarbeit mit anderen Komponenten Ihrer Datenplattform, einschließlich Datenspeicherung und Data Lakes
ETL/ELT und OWOX BI
Mit OWOX BI können Sie ohne die Hilfe von Analysten und Entwicklern Marketingdaten für beliebig komplexe Berichte im sicheren Google BigQuery-Cloudspeicher sammeln.
Was Sie mit OWOX BI bekommen:
- Sammeln Sie automatisch Daten aus verschiedenen Quellen
- Rohdaten automatisch in Google BigQuery importieren
- Bereinigen, deduplizieren, überwachen Sie die Qualität und aktualisieren Sie Daten
- Bereiten Sie betriebsbereite Daten vor und modellieren Sie sie
- Erstellen Sie Berichte ohne die Hilfe von Analysten oder SQL-Kenntnissen
OWOX BI setzt Ihre kostbare Zeit frei, damit Sie sich mehr auf die Optimierung von Werbekampagnen und Wachstumszonen konzentrieren können.
Sie müssen nicht mehr auf Berichte eines Analysten warten. Erhalten Sie vorgefertigte Dashboards oder einen individuellen Bericht, der auf simulierten Daten basiert und für Ihr Unternehmen geeignet ist.
Mit dem einzigartigen Ansatz von OWOX BI können Sie Datenquellen und Datenstrukturen ändern, ohne SQL-Abfragen zu überschreiben oder Berichte neu zu ordnen. Dies ist besonders relevant mit der Veröffentlichung des neuen Google Analytics 4.
Die zentralen Thesen
Die von Unternehmen gesammelten Datenmengen werden täglich größer und werden weiter wachsen. Es reicht vorerst aus, mit lokalen Datenbanken und Batch-Downloads zu arbeiten, aber sehr bald wird es die geschäftlichen Anforderungen nicht mehr erfüllen. Die Möglichkeit, ETL-Prozesse zu skalieren, ist also praktisch und besonders relevant für Advanced Analytics.
Die Hauptvorteile von ETL-Tools sind:
- Sparen Sie Ihre Zeit.
- Vermeidung manueller Datenverarbeitung.
- erleichtert die Arbeit mit komplexen Daten.
- Verringerung der mit dem menschlichen Faktor verbundenen Risiken.
- helfen, die Entscheidungsfindung zu verbessern.
- Steigerung des ROI.
Denken Sie bei der Auswahl eines ETL-Tools an die besonderen Anforderungen Ihres Unternehmens. Wenn Sie lokal arbeiten und Ihre Daten vorhersehbar sind und nur aus wenigen Quellen stammen, reicht herkömmliches ETL aus. Aber vergessen Sie nicht, dass immer mehr Unternehmen auf Cloud- oder hybride Architekturen umsteigen und Sie dies berücksichtigen müssen.