
ETLとは:究極のガイド101
公開: 2022-05-25企業が収集するさまざまなソースからのデータが多いほど、分析、データサイエンス、機械学習の機能が向上します。 しかし、機会とともに、データ処理に関連する懸念が高まっています。 結局のところ、レポートの作成と洞察の検索を開始する前に、この生の異種データをすべて処理する必要があります。つまり、クリーンアップ、チェック、単一フォーマットへの変換、およびマージです。 これらのタスクには、抽出、変換、および読み込み(またはETL)プロセスとツールが使用されます。 この記事では、ETLとは何か、アナリストやマーケターがETLツールを必要とする理由を詳しく分析します。
目次
- ETLとは何ですか?なぜそれが重要なのですか?
- ETLがどのようにして生まれたかの簡単な歴史
- ETLプロセスの仕組み
- ステップ1.データを抽出する
- ステップ2.データを変換する
- ステップ3.データをロードする
- ETLの利点
- ETLの課題
- ETLとELT—違いは何ですか?
- ETLの実装を成功させるための5つのヒント
- ETLツールの選択方法
- ETL/ELTおよびOWOXBI
- 重要なポイント
ETLとは何ですか?なぜそれが重要なのですか?
抽出、変換、読み込みは、データ駆動型分析の基礎となるデータ統合プロセスであり、次の3つの段階で構成されます。
- データは元のソースから抽出されます
- データは分析に適した形式に変換されます
- データは、ストレージ、データレイク、またはビジネスインテリジェンスシステムに読み込まれます
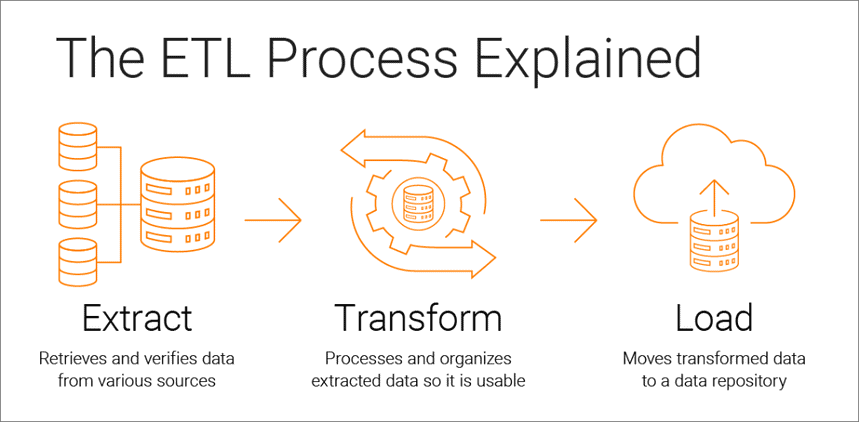
ETLツールを使用すると、企業は複数のソースからさまざまな種類のデータを収集し、そのデータをマージして、Google BigQuery、Snowflake、Azureなどの集中ストレージの場所で使用できます。
抽出、変換、および読み込みのプロセスは、データ分析を成功させるための基盤を提供し、信頼できるデータの単一のソースを作成して、会社のすべてのデータの一貫性と関連性を確保します。
意思決定者にとって可能な限り有用であるためには、ビジネスの分析システムは、ビジネスの変化に応じて変化する必要があります。 ETLは通常のプロセスであり、分析システムは柔軟性があり、自動化されており、十分に文書化されている必要があります。
ETLがどのようにして生まれたかの簡単な歴史
ETLは、企業が複数のリポジトリまたはデータベースを使用し始めた1970年代に普及しました。 その結果、このすべてのデータを効果的に統合することが必要になりました。
1980年代後半に、いくつかの異種システムからのデータへの統合アクセスを提供するデータストレージテクノロジーが登場しました。 しかし、問題は、多くのデータベースがベンダー固有のETLツールを必要とすることでした。 したがって、さまざまな部門が、さまざまなデータストレージソリューションで使用するためにさまざまなETLツールを選択することがよくあります。 そのため、さまざまなデータソースのスクリプトを絶えず作成して調整する必要がありました。 データ量と複雑さの増加により、手動コーディングを回避する自動ETLプロセスが実現しました。
ETLプロセスの仕組み
ETLプロセスは、抽出、変換、および読み込みの3つのステップで構成されます。 それぞれを詳しく見ていきましょう。
ステップ1.データを抽出する
このステップでは、さまざまなソースからの生の(構造化および部分的に構造化された)データが抽出され、後続の処理のために中間領域(一時データベースまたはサーバー)に配置されます。
このようなデータのソースは次のとおりです。
- ウェブサイト
- モバイルデバイスとアプリケーション
- CRM/ERPシステム
- APIインターフェース
- マーケティングサービス
- 分析ツール
- データベース
- クラウド、ハイブリッド、およびオンプレミス環境
- フラットファイル
- スプレッドシート
- SQLまたはNoSQLサーバー
- Eメール
- 自動販売機、ATM、商品センサーなどのモノのインターネット(IoT)データ転送ツール
さまざまなソースから収集されたデータは通常、異種であり、XML、JSON、CSVなどのさまざまな形式で表示されます。 したがって、それを抽出する前に、データソースとターゲットデータ間の関係を説明する論理データマップを作成する必要があります。
このステップでは、次のことを確認する必要があります。
- 抽出されたレコードはソースデータと一致します
- スパム/不要なデータがダウンロードに含まれます
- データは宛先ストレージの要件を満たしています
- 重複したデータと断片化されたデータがあります
- すべてのキーが配置されています
データは次の3つの方法で抽出できます。
- 部分抽出—ソースは最新のデータ変更を通知します。
- 通知なしの部分抽出—すべてのデータソースが更新通知を提供するわけではありません。 ただし、変更されたレコードを指し示し、そのようなレコードからの抜粋を提供することはできます。
- 完全抽出—一部のシステムは、変更されたデータをまったく判別できません。 この場合、完全な抽出のみが可能です。 そのためには、同じ形式の最新のアップロードのコピーが必要です。これにより、検索して変更を加えることができます。
この手順は、アナリストが手動で実行することも、自動で実行することもできます。 ただし、手動でデータを抽出するには時間がかかり、エラーが発生する可能性があります。 したがって、ETLプロセスを自動化し、高品質のデータを提供するOWOXBIなどのツールを使用することをお勧めします。
ステップ2.データを変換する
このステップでは、中間領域(一時ストレージ)で収集された生データが、ビジネスのニーズとターゲットデータストレージの要件を満たす統一された形式に変換されます。 このアプローチ(最終的な宛先にデータを直接アップロードする代わりに中間ストレージの場所を使用)を使用すると、何かが突然問題になった場合にデータをすばやくロールバックできます。
データ変換には、次の操作を含めることができます。
- クリーニング—データの不整合や不正確さを排除します。
- 標準化—すべてのデータ型を同じ形式(日付、通貨など)に変換します。
- 重複排除—冗長データを除外または破棄します。
- 検証—未使用のデータを削除し、異常にフラグを立てます。
- データの行または列の並べ替え
- マッピング— 2つの値のデータを1つにマージするか、逆に、1つの値のデータを2つに分割します。
- 補足—他のソースからデータを抽出します。
- ターゲットデータストレージのスキーマに従ってデータをテーブルにフォーマットする
- データ品質の監査とコンプライアンスのレビュー
- その他のタスク—追加/オプションのルールを適用してデータ品質を向上させます。 たとえば、テーブルの名前と名前が異なる列にある場合は、それらをマージできます。
変換は、おそらくETLプロセスの最も重要な部分です。 これにより、データ品質が向上し、処理されたデータが完全に互換性のあるストレージに配信され、レポートやその他のビジネスタスクですぐに使用できるようになります。
私たちの経験では、一部の企業はまだビジネス対応データを準備しておらず、生データに関するレポートを作成していません。 このアプローチの主な問題は、SQLクエリの無限のデバッグと書き換えです。 したがって、この段階を無視しないことを強くお勧めします。
OWOX BIは、さまざまなソースから生データを自動的に収集し、レポートに適した形式に変換します。 マーケターにとって重要なニュアンスを考慮して、目的の構造に自動的に変換される既製のデータセットを受け取ります。 複雑な変換の開発とサポートに時間を費やしたり、データ構造を詳しく調べたり、不一致の原因を探すために何時間も費やしたりする必要はありません。
ステップ3.データをロードする
この時点で、ステージング領域からの処理済みデータは、ローカルまたはクラウドのいずれかで、ターゲットデータベース、ストレージ、またはデータレイクにアップロードされます。
これにより、社内のさまざまなチームがすぐに使えるデータに簡単にアクセスできます。
いくつかのアップロードオプションがあります。
- 初期ロード—データストレージ内のすべてのテーブルを初めて入力します。
- 増分負荷—必要に応じて定期的に新しいデータを書き込みます。 この場合、システムは受信データをすでに利用可能なデータと比較し、新しいデータを検出した場合にのみ追加のレコードを作成します。 このアプローチは、データの量を減らすことにより、データ処理のコストを削減します。
- 完全更新—テーブルの内容を削除し、最新のデータをテーブルに再ロードします。
これらの各手順は、ETLツールを使用するか、カスタムコードとSQLクエリを使用して手動で実行できます。
ETLの利点
1. ETLは時間を節約し、手動のデータ処理を回避するのに役立ちます。

ETLプロセスの最大の利点は、データを自動的に収集、変換、および統合できることです。 時間と労力を節約し、膨大な数の行を手動でインポートする必要をなくすことができます。
2. ETLを使用すると、複雑なデータを簡単に操作できます。
時間の経過とともに、ビジネスでは、タイムゾーン、顧客名、デバイスID、場所など、複雑で多様な大量のデータを処理する必要があります。さらにいくつかの属性を追加すると、24時間体制でデータをフォーマットする必要があります。 さらに、受信データはさまざまな形式およびさまざまなタイプにすることができます。 ETLはあなたの生活をはるかに楽にします。
3. ETLは、人的要因に関連するリスクを軽減します。
データにどれほど注意を払っていても、間違いの影響を受けません。 たとえば、ターゲットシステムでデータが誤って複製されたり、手動入力にエラーが含まれたりする場合があります。 ETLツールは、人間の影響を排除することで、このような問題を回避するのに役立ちます。
4. ETLは、意思決定の改善に役立ちます。
重要なデータワークフローを自動化し、エラーの可能性を減らすことで、ETLは、分析のために受け取るデータが高品質で信頼できることを保証します。 そして、質の高いデータは、より良い企業の意思決定を行うための基本です。
5.ETLはROIを向上させます。
時間、労力、およびリソースを節約できるため、ETLプロセスは最終的にROIの向上に役立ちます。 さらに、ビジネス分析を改善することにより、利益を増やすことができます。 これは、企業が統合データを取得してより適切なビジネス上の意思決定を行うためにETLプロセスに依存しているためです。
ETLの課題
ETLツールを選択するときは、ビジネス要件、収集されるデータの量、およびその使用方法に依存する価値があります。 ETLプロセスを設定するときに、どのような課題に直面する可能性がありますか?
1.さまざまなソースからのデータを処理します。
1つの会社が、さまざまなデータ形式の何百ものソースを処理できます。 これらには、構造化および部分的に構造化されたデータ、リアルタイムストリーミングデータ、フラットファイル、CSVファイル、S3バスケット、ストリーミングソースなどが含まれます。 このデータの一部はパケットに変換するのが最適ですが、他のデータの場合はストリーミングデータ変換の方が効果的です。 各タイプのデータを最も効率的かつ実用的な方法で処理することは、大きな課題となる可能性があります。
2.データ品質が最も重要です。
分析を効率的に機能させるには、正確で完全なデータ変換を保証する必要があります。 手動処理、定期的なエラー検出、およびSQLクエリの書き換えにより、エラー、重複、またはデータ損失が発生する可能性があります。 ETLツールは、アナリストをルーチンから救い、エラーを減らすのに役立ちます。 データ品質監査は、不整合と重複を識別し、監視機能は、互換性のないデータ型やその他の問題を処理している場合に警告します。
3.分析システムはスケーラブルである必要があります。
企業が収集するデータの量は、ここ数年で増加するだけです。 今のところ、ローカルデータベースとバッチダウンロードに満足できますが、それはあなたのビジネスにとって常に十分でしょうか? ETLプロセスと容量を無限に拡張できる可能性があるのは素晴らしいことです。 データ主導の意思決定に関しては、大きくて迅速に考えてください。大量のデータを迅速かつ安価に処理できるクラウドストレージ(Google BigQueryなど)を利用してください。
ETLとELT—違いは何ですか?
ELT(Extract、Load、Transform)は、基本的に、データがストレージにロードされた後に変換される、おなじみのETLプロセスの最新の外観です。
従来のETLツールは、データをストレージにロードする前に、さまざまなソースからデータを抽出して変換します。 クラウドストレージの出現により、ソースとターゲットのデータストレージの場所の間の中間段階でデータをクリーンアップする必要がなくなりました。
ELTは、特に高度な分析に関連しています。 たとえば、生データをデータレイクにアップロードしてから、他のソースからのデータとマージしたり、予測モデルのトレーニングに使用したりできます。 データを生のままにしておくことで、アナリストは機能を拡張できます。 このアプローチは、最新のデータ処理メカニズムの能力を活用し、不要なデータ移動を減らすため、高速です。
どちらを選ぶべきですか? ETLまたはELT? ローカルで作業していて、データが予測可能で、少数のソースからのみ取得されている場合は、従来のETLで十分です。 ただし、クラウドまたはハイブリッドデータアーキテクチャに移行する企業が増えるにつれ、関連性はますます低くなっています。
ETLの実装を成功させるための5つのヒント
正常なETLプロセスを実装する場合は、次の手順に従います。
手順1.収集して保存するデータのソースを明確に特定します。 これらのソースには、SQLリレーショナルデータベース、NoSQL非リレーショナルデータベース、サービスとしてのソフトウェア(SaaS)プラットフォーム、またはその他のアプリケーションがあります。 データソースが接続されたら、抽出する特定のデータフィールドを定義します。 次に、さまざまなソースからのこのデータを生の形式で受け入れるか入力します。
手順2.一連のビジネスルール(集計、添付、並べ替え、マージ関数など)を使用して、このデータを統合します。
ステップ3.変換後、データをストレージにロードする必要があります。 このステップでは、データのアップロードの頻度を決定する必要があります。 新しいデータを記録するか、既存のデータを更新するかを指定します。
ステップ4.データをリポジトリに転送する前後のレコード数を確認することが重要です。 これは、無効で冗長なデータを除外するために行う必要があります。
ステップ5.最後のステップは、特別なツールを使用してETLプロセスを自動化することです。 これにより、時間を節約し、精度を向上させ、ETLプロセスを手動で再起動する手間を減らすことができます。 ETL自動化ツールを使用すると、シンプルなインターフェイスを介してワークフローを設計および制御できます。 さらに、これらのツールには、プロファイリングやデータクリーニングなどの機能があります。
ETLツールの選択方法
まず、どのETLツールが存在するかを理解しましょう。 現在、4種類あります。 ローカル環境で動作するように設計されているもの、クラウドで動作するもの、両方の環境で動作するものがあります。 どちらを選択するかは、データの場所とビジネスに必要なものによって異なります。
- ローカルストレージ内のデータをバッチ処理するためのETLツール。
- ソースからクラウドストレージに直接データを抽出して読み込むことができるクラウドETLツール。 次に、クラウドの能力と規模を使用してデータを変換できます。 例:OWOXBI。
- Apache Airflow、Apache Kafka、Apache NiFiなどのETLオープンソースツールは、有料サービスに代わる予算の選択肢です。 複雑な変換をサポートしていないものもあり、カスタマーサポートの問題がある場合があります。
- リアルタイムETLツール。 データは、分散モデルとデータストリーミング機能を使用してリアルタイムで処理されます。
ETLツールを選択するときに探すべきこと:
- 使いやすさとメンテナンスのしやすさ
- 仕事のスピード
- セキュリティのレベル
- 必要なコネクタの数と種類
- データストレージやデータレイクなど、データプラットフォームの他のコンポーネントとシームレスに連携する機能
ETL/ELTおよびOWOXBI
OWOX BIを使用すると、アナリストや開発者の助けを借りずに、安全なGoogleBigQueryクラウドストレージの複雑さのレポートのマーケティングデータを収集できます。
OWOX BIで得られるもの:
- さまざまなソースからデータを自動的に収集します
- 生データをGoogleBigQueryに自動的にインポートする
- データのクリーンアップ、重複排除、品質の監視、更新
- ビジネス対応データの準備とモデル化
- アナリストやSQLの知識がなくてもレポートを作成できます
OWOX BIは貴重な時間を解放するので、広告キャンペーンと成長ゾーンの最適化により多くの注意を払うことができます。
アナリストからの報告を待つ必要がなくなりました。 シミュレートされたデータに基づいており、ビジネスに適した既製のダッシュボードまたは個別のレポートを入手してください。
OWOX BIの独自のアプローチにより、SQLクエリを上書きしたり、レポートを並べ替えたりすることなく、データソースとデータ構造を変更できます。 これは、新しいGoogleAnalytics4のリリースに特に関係があります。
重要なポイント
企業が収集するデータの量は日々増加しており、今後も増え続けるでしょう。 今のところ、ローカルデータベースとバッチダウンロードを使用するだけで十分ですが、すぐにビジネスニーズを満たせなくなります。 したがって、ETLプロセスをスケーリングする可能性は便利であり、特に高度な分析に関連しています。
ETLツールの主な利点は次のとおりです。
- あなたの時間を節約します。
- 手動のデータ処理を回避します。
- 複雑なデータを簡単に操作できるようにします。
- 人的要因に関連するリスクを軽減します。
- 意思決定の改善を支援します。
- ROIの向上。
ETLツールの選択に関しては、ビジネスの特定のニーズについて考えてください。 ローカルで作業していて、データが予測可能で、少数のソースからのみ取得されている場合は、従来のETLで十分です。 ただし、ますます多くの企業がクラウドまたはハイブリッドアーキテクチャに移行していることを忘れないでください。これを考慮に入れる必要があります。