
Co to jest ETL: najlepszy przewodnik 101
Opublikowany: 2022-05-25Im więcej danych z różnych źródeł gromadzi firma, tym większe są jej możliwości w zakresie analityki, nauki o danych i uczenia maszynowego. Jednak wraz z możliwościami rosną obawy związane z przetwarzaniem danych. W końcu przed przystąpieniem do tworzenia raportów i wyszukiwania spostrzeżeń wszystkie te nieprzetworzone i rozbieżne dane muszą zostać przetworzone: wyczyszczone, sprawdzone, przekonwertowane do jednego formatu i scalone. Do tych zadań są używane procesy i narzędzia Extract , Transform i Load (lub ETL). W tym artykule szczegółowo przeanalizujemy, czym jest ETL i dlaczego narzędzia ETL są potrzebne analitykom i marketerom.
Spis treści
- Czym jest ETL i dlaczego jest ważny?
- Krótka historia powstania ETL
- Jak działa proces ETL
- Krok 1. Wyodrębnij dane
- Krok 2. Przekształć dane
- Krok 3. Załaduj dane
- Zalety ETL
- Wyzwania ETL
- ETL vs ELT — jaka jest różnica?
- 5 wskazówek, jak pomyślnie wdrożyć ETL
- Jak wybrać narzędzie ETL
- ETL/ELT i OWOX BI
- Kluczowe dania na wynos
Czym jest ETL i dlaczego jest ważny?
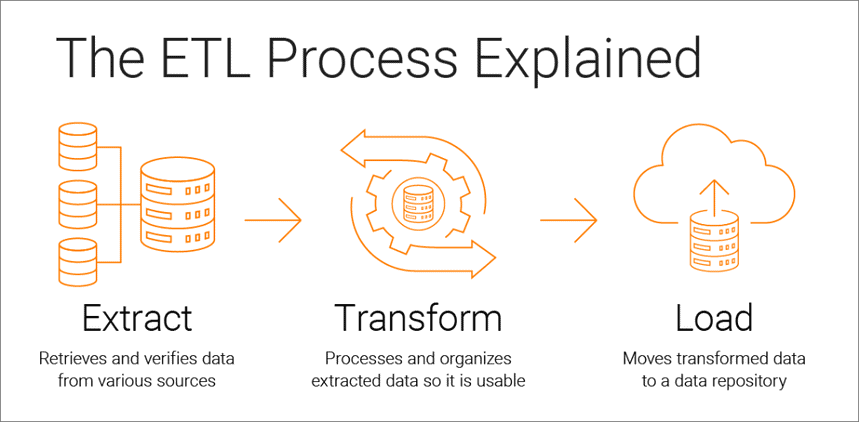
Wyodrębnij, przekształć, załaduj to proces integracji danych, który stanowi podstawę analizy opartej na danych i składa się z trzech etapów:
- Dane są pobierane z oryginalnego źródła
- Dane są konwertowane do formatu odpowiedniego do analizy
- Dane są ładowane do pamięci masowej, jeziora danych lub systemu analizy biznesowej
Narzędzia ETL pozwalają firmom zbierać dane różnego typu z wielu źródeł i łączyć je w celu pracy z nimi w scentralizowanej lokalizacji pamięci masowej, takiej jak Google BigQuery, Snowflake czy Azure.
Procesy wyodrębniania, przekształcania i ładowania stanowią podstawę skutecznej analizy danych i tworzą jedno źródło wiarygodnych danych, zapewniając spójność i trafność wszystkich danych firmy.
Aby być jak najbardziej użytecznym dla decydentów, system analityczny firmy musi zmieniać się wraz ze zmianą firmy. ETL to regularny proces, a Twój system analityczny musi być elastyczny, zautomatyzowany i dobrze udokumentowany.
Krótka historia powstania ETL
ETL stał się popularny w latach 70., kiedy firmy zaczęły pracować z wieloma repozytoriami lub bazami danych. W rezultacie konieczne stało się skuteczne zintegrowanie wszystkich tych danych.
Pod koniec lat 80. pojawiły się technologie przechowywania danych, które oferowały zintegrowany dostęp do danych z kilku heterogenicznych systemów. Problem polegał jednak na tym, że wiele baz danych wymagało narzędzi ETL specyficznych dla dostawcy. Dlatego różne działy często wybierają różne narzędzia ETL do użytku z różnymi rozwiązaniami do przechowywania danych. Doprowadziło to do konieczności ciągłego pisania i dostosowywania skryptów do różnych źródeł danych. Wzrost ilości i złożoności danych doprowadził do zautomatyzowanego procesu ETL, który pozwala uniknąć ręcznego kodowania.
Jak działa proces ETL
Proces ETL składa się z trzech etapów: wyodrębniania, przekształcania i ładowania. Przyjrzyjmy się każdemu z nich.
Krok 1. Wyodrębnij dane
Na tym etapie surowe (ustrukturyzowane i częściowo ustrukturyzowane) dane z różnych źródeł są wyodrębniane i umieszczane w obszarze pośrednim (tymczasowej bazie danych lub serwerze) w celu dalszego przetwarzania.
Źródłem takich danych mogą być:
- Strony internetowe
- Urządzenia mobilne i aplikacje
- Systemy CRM/ERP
- Interfejsy API
- Usługi marketingowe
- Narzędzia analityczne
- Bazy danych
- Środowiska chmurowe, hybrydowe i lokalne
- Pliki płaskie
- Arkusze kalkulacyjne
- Serwery SQL lub NoSQL
- Narzędzia do przesyłania danych Internetu rzeczy (IoT), takie jak automaty sprzedające, bankomaty i czujniki towarów
Dane zebrane z różnych źródeł są zwykle niejednorodne i prezentowane w różnych formatach: XML, JSON, CSV i innych. Dlatego przed ich wyodrębnieniem należy utworzyć logiczną mapę danych, która opisuje relacje między źródłami danych a danymi docelowymi.
Na tym etapie należy sprawdzić, czy:
- Wyodrębnione rekordy pasują do danych źródłowych
- Spam/niechciane dane dostaną się do pobrania
- Dane spełniają wymagania dotyczące przechowywania docelowego
- Istnieją duplikaty i fragmentaryczne dane
- Wszystkie klucze są na swoim miejscu
Dane można wyodrębnić na trzy sposoby:
- Częściowe wyodrębnianie — źródło powiadamia o najnowszych zmianach danych.
- Częściowa ekstrakcja bez powiadomienia — nie wszystkie źródła danych zapewniają powiadomienie o aktualizacji; mogą jednak wskazać rekordy, które uległy zmianie i dostarczyć fragment takich rekordów.
- Pełna ekstrakcja — niektóre systemy nie mogą w ogóle określić, które dane zostały zmienione; w tym przypadku możliwa jest tylko pełna ekstrakcja. Aby to zrobić, potrzebujesz kopii najnowszego pliku przesłanego w tym samym formacie, aby móc wyszukiwać i wprowadzać zmiany.
Ten krok może być wykonany ręcznie przez analityków lub automatycznie. Jednak ręczne wyodrębnianie danych jest czasochłonne i może prowadzić do błędów. Dlatego zalecamy korzystanie z narzędzi takich jak OWOX BI, które automatyzują proces ETL i dostarczają wysokiej jakości danych.
Krok 2. Przekształć dane
Na tym etapie surowe dane zebrane w obszarze pośrednim (magazynie tymczasowe) są konwertowane do jednolitego formatu, który spełnia potrzeby biznesowe i wymagania docelowego miejsca przechowywania danych. Takie podejście — korzystanie z pośredniej lokalizacji pamięci masowej zamiast bezpośredniego przesyłania danych do miejsca docelowego — umożliwia szybkie wycofanie danych, jeśli nagle coś pójdzie nie tak.
Transformacja danych może obejmować następujące operacje:
- Czyszczenie — Wyeliminuj niespójności i niedokładności danych.
- Standaryzacja — Konwertuj wszystkie typy danych do tego samego formatu: daty, waluty itp.
- Deduplikacja — Wyklucz lub odrzuć nadmiarowe dane.
- Walidacja — Usuń nieużywane dane i anomalie flag.
- Ponowne sortowanie wierszy lub kolumn danych
- Mapowanie — Scal dane z dwóch wartości w jedną lub odwrotnie, podziel dane z jednej wartości na dwie.
- Uzupełnianie — Wyodrębnij dane z innych źródeł.
- Formatowanie danych do tabel zgodnie ze schematem docelowego przechowywania danych
- Audyt jakości danych i przegląd zgodności
- Inne zadania — Zastosuj wszelkie dodatkowe/opcjonalne reguły w celu poprawy jakości danych; na przykład, jeśli imię i nazwisko w tabeli znajdują się w różnych kolumnach, możesz je scalić.
Transformacja jest prawdopodobnie najważniejszą częścią procesu ETL. Pomaga poprawić jakość danych i zapewnia, że przetworzone dane są dostarczane do pamięci masowej w pełni kompatybilne i gotowe do użycia w raportowaniu i innych zadaniach biznesowych.
Z naszego doświadczenia wynika, że niektóre firmy nadal nie przygotowują gotowych danych biznesowych i nie budują raportów na danych surowych. Głównym problemem tego podejścia jest niekończące się debugowanie i przepisywanie zapytań SQL. Dlatego zdecydowanie odradzamy ignorowanie tego etapu.
OWOX BI automatycznie zbiera surowe dane z różnych źródeł i konwertuje je do formatu przyjaznego dla raportów. Otrzymujesz gotowe zestawy danych, które są automatycznie przekształcane do pożądanej struktury, uwzględniającej ważne dla marketerów niuanse. Nie będziesz musiał spędzać czasu na opracowywaniu i wspieraniu złożonych transformacji, zagłębiać się w strukturę danych i godzinami szukać przyczyn rozbieżności.
Krok 3. Załaduj dane
W tym momencie przetworzone dane z obszaru tymczasowego są przesyłane do docelowej bazy danych, magazynu lub jeziora danych, lokalnie lub w chmurze.
Zapewnia to wygodny dostęp do gotowych danych biznesowych różnym zespołom w firmie.
Istnieje kilka opcji przesyłania:
- Ładowanie początkowe — po raz pierwszy wypełnij wszystkie tabele w pamięci danych.
- Obciążenie przyrostowe — Zapisuj nowe dane okresowo w razie potrzeby. W takim przypadku system porównuje przychodzące dane z już dostępnymi i tworzy dodatkowe rekordy tylko wtedy, gdy wykryje nowe dane. Takie podejście obniża koszty przetwarzania danych poprzez zmniejszenie ich objętości.
- Pełna aktualizacja — Usuń zawartość tabeli i ponownie załaduj tabelę najnowszymi danymi.
Każdy z tych kroków można wykonać za pomocą narzędzi ETL lub ręcznie, używając niestandardowego kodu i zapytań SQL.
Zalety ETL
1. ETL oszczędza Twój czas i pomaga uniknąć ręcznego przetwarzania danych.
Największą zaletą procesu ETL jest to, że pomaga on automatycznie gromadzić, konwertować i konsolidować dane. Możesz zaoszczędzić czas i wysiłek oraz wyeliminować potrzebę ręcznego importowania ogromnej liczby wierszy.

2. ETL ułatwia pracę ze złożonymi danymi.
Z biegiem czasu Twoja firma musi radzić sobie z dużą ilością złożonych i różnorodnych danych: stref czasowych, nazw klientów, identyfikatorów urządzeń, lokalizacji itp. Dodaj jeszcze kilka atrybutów, a będziesz musiał formatować dane przez całą dobę. Ponadto przychodzące dane mogą mieć różne formaty i typy. ETL znacznie ułatwia życie.
3. ETL zmniejsza ryzyko związane z czynnikiem ludzkim.
Bez względu na to, jak ostrożnie podchodzisz do swoich danych, nie jesteś odporny na błędy. Na przykład dane mogą zostać przypadkowo zduplikowane w systemie docelowym lub wprowadzone ręcznie dane mogą zawierać błąd. Eliminując wpływ człowieka, narzędzie ETL pomaga uniknąć takich problemów.
4. ETL pomaga usprawnić podejmowanie decyzji.
Automatyzując krytyczne przepływy danych i zmniejszając ryzyko błędów, ETL zapewnia, że dane, które otrzymujesz do analizy, są wysokiej jakości i można im ufać. Jakość danych ma kluczowe znaczenie dla podejmowania lepszych decyzji korporacyjnych.
5. ETL zwiększa ROI.
Ponieważ proces ETL pozwala zaoszczędzić czas, wysiłek i zasoby, ostatecznie pomaga poprawić zwrot z inwestycji. Dodatkowo poprawiając analitykę biznesową zwiększasz swoje zyski. Dzieje się tak, ponieważ firmy polegają na procesie ETL w celu uzyskania skonsolidowanych danych i podejmowania lepszych decyzji biznesowych.
Wyzwania ETL
Wybierając narzędzie ETL, warto polegać na wymaganiach biznesowych, ilości gromadzonych danych i sposobie ich wykorzystania. Jakie wyzwania możesz napotkać podczas konfigurowania procesu ETL?
1. Przetwarzanie danych z różnych źródeł.
Jedna firma może pracować z setkami źródeł o różnych formatach danych. Mogą to być dane ustrukturyzowane i częściowo ustrukturyzowane, dane strumieniowe w czasie rzeczywistym, pliki płaskie, pliki CSV, koszyki S3, źródła strumieniowe i wiele innych. Niektóre z tych danych najlepiej konwertować w pakietach, podczas gdy w przypadku innych konwersja danych strumieniowych działa lepiej. Przetwarzanie każdego rodzaju danych w najbardziej wydajny i praktyczny sposób może być ogromnym wyzwaniem.
2. Jakość danych jest najważniejsza.
Aby analityka działała wydajnie, musisz zapewnić dokładną i pełną transformację danych. Ręczne przetwarzanie, regularne wykrywanie błędów i przepisywanie zapytań SQL może spowodować błędy, duplikację lub utratę danych. Narzędzia ETL chronią analityków przed rutyną i pomagają zredukować błędy. Audyt jakości danych identyfikuje niespójności i duplikaty, a funkcje monitorowania ostrzegają, jeśli masz do czynienia z niekompatybilnymi typami danych i innymi problemami.
3. Twój system analityczny musi być skalowalny.
Ilość danych gromadzonych przez firmy będzie rosła tylko z biegiem lat. Na razie możesz być zadowolony z lokalnej bazy danych i pobierania wsadowego, ale czy zawsze będzie to wystarczające dla Twojej firmy? Wspaniale jest mieć możliwość skalowania procesów ETL i zdolności do nieskończoności! Jeśli chodzi o podejmowanie decyzji na podstawie danych, myśl na dużą skalę i szybko: korzystaj z pamięci masowej w chmurze (takiej jak Google BigQuery), która pozwala szybko i tanio przetwarzać duże ilości danych.
ETL vs ELT — jaka jest różnica?
ELT (Extract, Load, Transform) to zasadniczo nowoczesne spojrzenie na znany proces ETL, w którym dane są konwertowane po załadowaniu do pamięci.
Tradycyjne narzędzia ETL wyodrębniają i konwertują dane z różnych źródeł przed załadowaniem ich do pamięci masowej. Wraz z pojawieniem się pamięci masowej w chmurze nie ma potrzeby czyszczenia danych na etapie pośrednim między źródłowym a docelowym miejscem przechowywania danych.
ELT ma szczególne znaczenie w przypadku zaawansowanej analityki. Na przykład możesz przesłać nieprzetworzone dane do jeziora danych, a następnie scalić je z danymi z innych źródeł lub użyć ich do trenowania modeli predykcyjnych. Przechowywanie surowych danych pozwala analitykom na rozszerzenie ich możliwości. Takie podejście jest szybkie, ponieważ wykorzystuje moc nowoczesnych mechanizmów przetwarzania danych i ogranicza niepotrzebny ruch danych.
Który wybrać? ETL czy ELT? Jeśli pracujesz lokalnie, a Twoje dane są przewidywalne i pochodzą tylko z kilku źródeł, wystarczy tradycyjny ETL. Jednak staje się ona coraz mniej istotna, ponieważ coraz więcej firm przechodzi na architektury danych w chmurze lub hybrydowe.
5 wskazówek, jak pomyślnie wdrożyć ETL
Jeśli chcesz zaimplementować pomyślny proces ETL, wykonaj następujące kroki:
Krok 1. Jasno określ źródła danych, które chcesz gromadzić i przechowywać. Tymi źródłami mogą być relacyjne bazy danych SQL, nierelacyjne bazy danych NoSQL, platformy oprogramowania jako usługi (SaaS) lub inne aplikacje. Po połączeniu źródeł danych zdefiniuj określone pola danych, które chcesz wyodrębnić. Następnie zaakceptuj lub wprowadź te dane z różnych źródeł w postaci surowej.
Krok 2. Ujednolicenie tych danych przy użyciu zestawu reguł biznesowych (takich jak agregacja, dołączanie, sortowanie, funkcje scalania itd.).
Krok 3. Po przekształceniu dane muszą zostać załadowane do pamięci. Na tym etapie musisz zdecydować o częstotliwości przesyłania danych. Określ, czy chcesz rejestrować nowe dane, czy aktualizować istniejące.
Krok 4. Ważne jest, aby sprawdzić liczbę rekordów przed i po przesłaniu danych do repozytorium. Należy to zrobić, aby wykluczyć nieprawidłowe i nadmiarowe dane.
Krok 5. Ostatnim krokiem jest automatyzacja procesu ETL za pomocą specjalnych narzędzi. Pomoże to zaoszczędzić czas, poprawić dokładność i zmniejszyć wysiłek związany z ręcznym restartowaniem procesu ETL. Dzięki narzędziom do automatyzacji ETL możesz projektować i kontrolować przepływ pracy za pomocą prostego interfejsu. Ponadto narzędzia te mają możliwości, takie jak profilowanie i czyszczenie danych.
Jak wybrać narzędzie ETL
Na początek zastanówmy się, jakie istnieją narzędzia ETL. Obecnie dostępne są cztery typy. Niektóre są przeznaczone do pracy w środowisku lokalnym, niektóre działają w chmurze, a niektóre działają w obu środowiskach. Wybór zależy od tego, gdzie znajdują się Twoje dane i jakie potrzeby ma Twoja firma:
- Narzędzia ETL do przetwarzania wsadowego danych w pamięci lokalnej.
- Narzędzia ETL w chmurze, które mogą wyodrębniać i ładować dane ze źródeł bezpośrednio do pamięci w chmurze. Następnie mogą przekształcać dane, korzystając z mocy i skali chmury. Przykład: OWOX BI.
- Narzędzia open source ETL, takie jak Apache Airflow, Apache Kafka i Apache NiFi, stanowią budżetową alternatywę dla usług płatnych. Niektóre nie obsługują złożonych przekształceń i mogą mieć problemy z obsługą klienta.
- Narzędzia ETL w czasie rzeczywistym. Dane są przetwarzane w czasie rzeczywistym przy użyciu modelu rozproszonego i możliwości przesyłania strumieniowego danych.
Na co zwrócić uwagę przy wyborze narzędzia ETL:
- Łatwość użytkowania i konserwacji
- Szybkość pracy
- Poziom bezpieczeństwa
- Liczba i różnorodność potrzebnych złączy
- Możliwość bezproblemowej współpracy z innymi komponentami platformy danych, w tym przechowywaniem danych i jeziorami danych
ETL/ELT i OWOX BI
Dzięki OWOX BI możesz zbierać dane marketingowe do raportów o dowolnej złożoności w bezpiecznym magazynie w chmurze Google BigQuery bez pomocy analityków i programistów.
Co zyskujesz dzięki OWOX BI:
- Automatycznie zbieraj dane z różnych źródeł
- Automatycznie importuj nieprzetworzone dane do Google BigQuery
- Wyczyść, deduplikuj, monitoruj jakość i aktualizuj dane
- Przygotuj i zamodeluj dane biznesowe
- Twórz raporty bez pomocy analityków czy znajomości SQL
OWOX BI uwalnia Twój cenny czas, dzięki czemu możesz poświęcić więcej uwagi optymalizacji kampanii reklamowych i stref wzrostu.
Nie musisz już czekać na raporty od analityka. Uzyskaj gotowe dashboardy lub indywidualny raport, który jest oparty na symulowanych danych i jest odpowiedni dla Twojej firmy.
Dzięki unikalnemu podejściu OWOX BI możesz modyfikować źródła danych i struktury danych bez nadpisywania zapytań SQL lub zmiany kolejności raportów. Jest to szczególnie istotne w przypadku wydania nowej wersji Google Analytics 4.
Kluczowe dania na wynos
Ilość danych gromadzonych przez firmy z każdym dniem jest coraz większa i będzie rosła. Na razie wystarczy praca z lokalnymi bazami danych i pobieranie wsadowe, jednak już niedługo nie zaspokoi to potrzeb biznesowych. Tak więc możliwość skalowania procesów ETL jest przydatna i jest szczególnie istotna w przypadku zaawansowanej analityki.
Główne zalety narzędzi ETL to:
- oszczędzając Twój czas.
- unikanie ręcznego przetwarzania danych.
- ułatwiając pracę ze złożonymi danymi.
- zmniejszenie zagrożeń związanych z czynnikiem ludzkim.
- pomoc w usprawnieniu procesu decyzyjnego.
- zwiększenie zwrotu z inwestycji.
Wybierając narzędzie ETL, zastanów się nad konkretnymi potrzebami Twojej firmy. Jeśli pracujesz lokalnie, a Twoje dane są przewidywalne i pochodzą tylko z kilku źródeł, wystarczy tradycyjny ETL. Nie zapominaj jednak, że coraz więcej firm przechodzi na architektury chmurowe lub hybrydowe i musisz wziąć to pod uwagę.