
คู่มือแนะนำ MapReduce ใน Big Data
เผยแพร่แล้ว: 2022-09-21MapReduce นำเสนอวิธีการสร้างแอปพลิเคชันที่มีประสิทธิภาพ เร็วขึ้น และคุ้มค่า
โมเดลนี้ใช้แนวคิดขั้นสูง เช่น การประมวลผลแบบขนาน ตำแหน่งข้อมูล เป็นต้น เพื่อให้เกิดประโยชน์มากมายแก่โปรแกรมเมอร์และองค์กร
แต่มีโมเดลการเขียนโปรแกรมและเฟรมเวิร์กมากมายในตลาดที่มีอยู่จนยากที่จะเลือก
และเมื่อพูดถึง Big Data คุณไม่สามารถเลือกอะไรก็ได้ คุณต้องเลือกเทคโนโลยีดังกล่าวที่สามารถจัดการกับข้อมูลจำนวนมากได้
MapReduce เป็นวิธีแก้ปัญหาที่ยอดเยี่ยม
ในบทความนี้ ฉันจะพูดถึงว่าจริงๆ แล้ว MapReduce คืออะไรและมีประโยชน์อย่างไร
เริ่มกันเลย!
MapReduce คืออะไร?
MapReduce เป็นโมเดลการเขียนโปรแกรมหรือเฟรมเวิร์กซอฟต์แวร์ภายในเฟรมเวิร์ก Apache Hadoop ใช้สำหรับสร้างแอปพลิเคชันที่สามารถประมวลผลข้อมูลขนาดใหญ่แบบขนานบนโหนดหลายพันโหนด (เรียกว่าคลัสเตอร์หรือกริด) ที่มีความทนทานต่อข้อผิดพลาดและความน่าเชื่อถือ
การประมวลผลข้อมูลนี้เกิดขึ้นในฐานข้อมูลหรือระบบไฟล์ที่จัดเก็บข้อมูล MapReduce สามารถทำงานร่วมกับ Hadoop File System (HDFS) เพื่อเข้าถึงและจัดการปริมาณข้อมูลขนาดใหญ่
กรอบงานนี้เปิดตัวในปี 2547 โดย Google และเป็นที่นิยมโดย Apache Hadoop เป็นเลเยอร์หรือเอ็นจิ้นการประมวลผลใน Hadoop ที่รันโปรแกรม MapReduce ที่พัฒนาในภาษาต่างๆ รวมถึง Java, C++, Python และ Ruby
โปรแกรม MapReduce ในระบบคลาวด์คอมพิวติ้งทำงานแบบคู่ขนาน ดังนั้นจึงเหมาะสำหรับการวิเคราะห์ข้อมูลในขนาดใหญ่

MapReduce มุ่งเป้าที่จะแบ่งงานออกเป็นงานย่อยๆ หลายงานโดยใช้ฟังก์ชัน "แผนที่" และ "ลด" มันจะแมปแต่ละงานแล้วลดเป็นงานที่เทียบเท่ากันหลายงาน ซึ่งส่งผลให้พลังการประมวลผลและโอเวอร์เฮดในเครือข่ายคลัสเตอร์ลดลง
ตัวอย่าง: สมมติว่าคุณกำลังเตรียมอาหารสำหรับบ้านที่เต็มไปด้วยแขก ดังนั้น หากคุณพยายามเตรียมอาหารทั้งหมดและทำตามขั้นตอนทั้งหมดด้วยตัวเอง จะกลายเป็นเรื่องวุ่นวายและใช้เวลานาน
แต่สมมติว่าคุณให้เพื่อนหรือเพื่อนร่วมงานบางคน (ไม่ใช่แขก) ช่วยคุณเตรียมอาหารโดยแจกจ่ายกระบวนการต่างๆ ให้กับบุคคลอื่นที่สามารถทำงานพร้อมกันได้ ในกรณีนี้ คุณจะเตรียมอาหารได้เร็วและง่ายขึ้นในขณะที่แขกของคุณยังคงอยู่ในบ้าน
MapReduce ทำงานในลักษณะเดียวกันกับงานแบบกระจายและการประมวลผลแบบคู่ขนานเพื่อให้งานที่กำหนดได้เร็วและง่ายขึ้น
Apache Hadoop ช่วยให้โปรแกรมเมอร์ใช้ MapReduce เพื่อรันโมเดลบนชุดข้อมูลแบบกระจายขนาดใหญ่ และใช้แมชชีนเลิร์นนิงขั้นสูงและเทคนิคทางสถิติเพื่อค้นหารูปแบบ คาดการณ์ ระบุความสัมพันธ์ และอื่นๆ
คุณสมบัติของ MapReduce
คุณสมบัติหลักบางประการของ MapReduce คือ:
- ส่วนต่อประสานผู้ใช้: คุณจะได้รับส่วนต่อประสานผู้ใช้ที่ใช้งานง่ายซึ่งให้รายละเอียดที่เหมาะสมในแต่ละแง่มุมของกรอบงาน มันจะช่วยให้คุณกำหนดค่า นำไปใช้ และปรับแต่งงานของคุณได้อย่างราบรื่น

- น้ำหนักบรรทุก: แอปพลิเคชันใช้อินเทอร์เฟซ Mapper และ Reducer เพื่อเปิดใช้งานแผนที่และลดฟังก์ชัน Mapper จับคู่คู่คีย์-ค่าอินพุตกับคู่คีย์-ค่าระดับกลาง Reducer ใช้เพื่อลดคู่คีย์-ค่าระดับกลางที่แชร์คีย์กับค่าอื่นๆ ที่มีขนาดเล็กกว่า มันทำหน้าที่สามอย่าง - เรียงลำดับ สับเปลี่ยน และลดขนาด
- ตัว แบ่งพาร์ติชั่น: ควบคุมการแบ่งส่วนของคีย์แมป-เอาท์พุตระดับกลาง
- นักข่าว: เป็นฟังก์ชันในการรายงานความคืบหน้า อัปเดตตัวนับ และตั้งค่าข้อความสถานะ
- ตัว นับ: แสดงถึงตัวนับทั่วโลกที่แอปพลิเคชัน MapReduce กำหนด
- OutputCollector: ฟังก์ชันนี้รวบรวมข้อมูลเอาต์พุตจาก Mapper หรือ Reducer แทนเอาต์พุตระดับกลาง
- RecordWriter: เขียนเอาต์พุตข้อมูลหรือคู่คีย์-ค่าลงในไฟล์เอาต์พุต
- DistributedCache: กระจายไฟล์ขนาดใหญ่กว่าแบบอ่านอย่างเดียวที่มีเฉพาะแอปพลิเคชันอย่างมีประสิทธิภาพ
- การบีบอัดข้อมูล: ตัวเขียนแอปพลิเคชันสามารถบีบอัดทั้งเอาต์พุตงานและเอาต์พุตแผนที่ระดับกลาง
- การข้ามบันทึกที่ไม่ถูกต้อง: คุณสามารถข้ามบันทึกที่ไม่ถูกต้องหลายรายการขณะประมวลผลอินพุตแผนที่ของคุณ คุณลักษณะนี้สามารถควบคุมได้ผ่านคลาส – SkipBadRecords
- การดีบัก: คุณจะได้รับตัวเลือกในการเรียกใช้สคริปต์ที่ผู้ใช้กำหนดและเปิดใช้งานการดีบัก หากงานใน MapReduce ล้มเหลว คุณสามารถเรียกใช้สคริปต์แก้ไขข้อบกพร่องและค้นหาปัญหาได้
สถาปัตยกรรม MapReduce
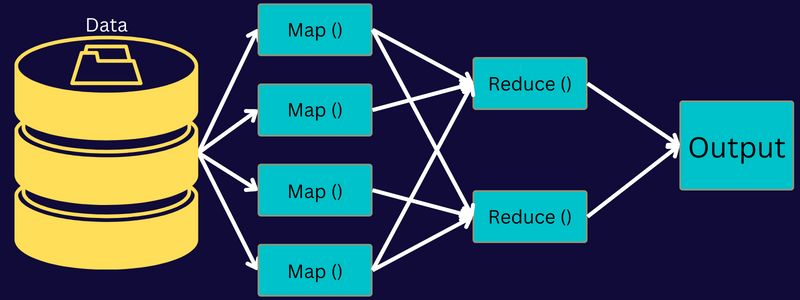
มาทำความเข้าใจสถาปัตยกรรมของ MapReduce โดยเจาะลึกลงไปในส่วนประกอบต่างๆ กัน:
- งาน: งานใน MapReduce เป็นงานจริงที่ลูกค้า MapReduce ต้องการดำเนินการ ประกอบด้วยงานเล็ก ๆ หลายงานที่รวมกันเป็นงานสุดท้าย
- เซิร์ฟเวอร์ประวัติงาน: เป็นกระบวนการของภูตในการจัดเก็บและบันทึกข้อมูลประวัติทั้งหมดเกี่ยวกับแอปพลิเคชันหรืองาน เช่น บันทึกที่สร้างขึ้นหลังจากหรือก่อนดำเนินการงาน
- ลูกค้า: ลูกค้า (โปรแกรมหรือ API) นำงานมาที่ MapReduce เพื่อดำเนินการหรือประมวลผล ใน MapReduce ลูกค้าหนึ่งรายหรือหลายรายสามารถส่งงานไปยัง MapReduce Manager เพื่อดำเนินการได้อย่างต่อเนื่อง
- MapReduce Master: MapReduce Master แบ่งงานออกเป็นส่วนย่อยๆ หลายส่วน เพื่อให้แน่ใจว่างานต่างๆ ดำเนินไปพร้อม ๆ กัน
- ส่วนของงาน: งานย่อยหรือส่วนของงานได้มาจากการแบ่งงานหลัก พวกเขาทำงานและรวมกันในที่สุดเพื่อสร้างงานสุดท้าย
- ป้อนข้อมูล: เป็นชุดข้อมูลที่ป้อนให้กับ MapReduce สำหรับการประมวลผลงาน
- ข้อมูลผลลัพธ์: เป็นผลลัพธ์สุดท้ายที่ได้รับเมื่อประมวลผลงานแล้ว
ดังนั้น สิ่งที่เกิดขึ้นจริงในสถาปัตยกรรมนี้คือลูกค้าส่งงานไปยัง MapReduce Master ซึ่งแบ่งงานออกเป็นส่วนๆ ที่เล็กกว่าและเท่าๆ กัน ซึ่งช่วยให้สามารถประมวลผลงานได้เร็วขึ้น เนื่องจากงานขนาดเล็กใช้เวลาดำเนินการน้อยกว่างานที่มีขนาดใหญ่กว่า
อย่างไรก็ตาม ตรวจสอบให้แน่ใจว่างานไม่ได้แบ่งออกเป็นงานเล็กๆ เกินไป เพราะหากคุณทำเช่นนั้น คุณอาจต้องเผชิญกับค่าใช้จ่ายที่มากขึ้นในการจัดการการแยกส่วนและเสียเวลาอย่างมากกับงานนั้น
ถัดไป ส่วนของงานจะพร้อมใช้งานเพื่อดำเนินการกับแผนที่และงานลด นอกจากนี้ งานแผนที่และงานลดยังมีโปรแกรมที่เหมาะสมตามกรณีการใช้งานที่ทีมกำลังดำเนินการอยู่ โปรแกรมเมอร์พัฒนาโค้ดตามตรรกะเพื่อตอบสนองความต้องการ
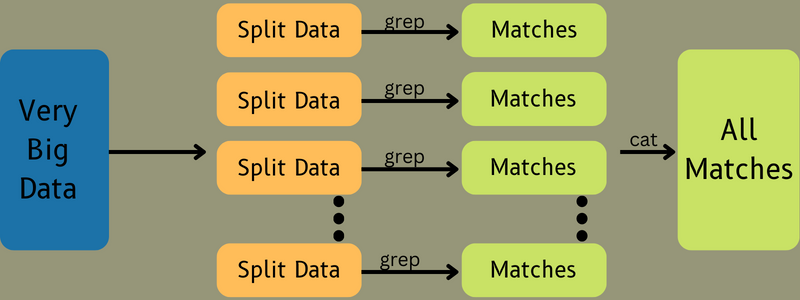
หลังจากนี้ ข้อมูลอินพุตจะถูกป้อนไปยังงานแผนที่ เพื่อให้ Map สามารถสร้างเอาต์พุตเป็นคู่คีย์-ค่าได้อย่างรวดเร็ว แทนที่จะจัดเก็บข้อมูลนี้บน HDFS จะใช้ดิสก์ในเครื่องเพื่อจัดเก็บข้อมูลเพื่อลดโอกาสในการจำลองแบบ
เมื่องานเสร็จสมบูรณ์ คุณสามารถทิ้งผลลัพธ์ได้ ดังนั้นการจำลองแบบจะกลายเป็น overkill เมื่อคุณจัดเก็บเอาต์พุตบน HDFS เอาต์พุตของงานแผนที่แต่ละงานจะถูกป้อนไปยังงานลด และเอาต์พุตแผนที่จะถูกส่งไปยังเครื่องที่รันงานลด
ถัดไป เอาต์พุตจะถูกรวมและส่งไปยังฟังก์ชันลดที่กำหนดโดยผู้ใช้ สุดท้าย เอาต์พุตที่ลดลงจะถูกเก็บไว้ใน HDFS
นอกจากนี้ กระบวนการสามารถมีแผนที่และงานลดได้หลายงานสำหรับการประมวลผลข้อมูล ขึ้นอยู่กับเป้าหมายสุดท้าย อัลกอริธึม Map and Reduce ได้รับการปรับให้เหมาะสมเพื่อให้เวลาหรือพื้นที่ซับซ้อนน้อยที่สุด
เนื่องจาก MapReduce เกี่ยวข้องกับงานแผนที่และการลดเป็นหลัก จึงจำเป็นต้องทำความเข้าใจเพิ่มเติมเกี่ยวกับงานเหล่านี้ ดังนั้น เรามาพูดถึงขั้นตอนต่างๆ ของ MapReduce เพื่อทำความเข้าใจหัวข้อเหล่านี้ให้ชัดเจน
เฟสของ MapReduce
แผนที่
ข้อมูลอินพุตถูกแมปเข้ากับเอาต์พุตหรือคู่คีย์-ค่าในเฟสนี้ ที่นี่ คีย์สามารถอ้างถึง id ของที่อยู่ในขณะที่ค่าสามารถเป็นค่าที่แท้จริงของที่อยู่นั้นได้
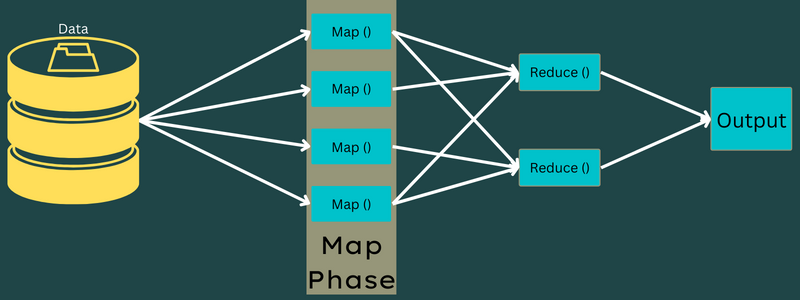
มีเพียงงานเดียวแต่สองงานในเฟสนี้ – การแยกและการทำแผนที่ Splits หมายถึง ส่วนย่อยหรือส่วนของงานที่แยกจากงานหลัก สิ่งเหล่านี้เรียกว่าการแยกอินพุต ดังนั้นการแยกอินพุตสามารถเรียกได้ว่าเป็นส่วนอินพุตที่ใช้โดยแผนที่

ถัดไป งานการทำแผนที่จะเกิดขึ้น ถือเป็นช่วงแรกในขณะที่รันโปรแกรมลดแผนที่ ที่นี่ ข้อมูลที่มีอยู่ในทุก ๆ แยกจะถูกส่งต่อไปยังฟังก์ชันแผนที่เพื่อประมวลผลและสร้างผลลัพธ์
ฟังก์ชัน – Map() ดำเนินการในที่เก็บหน่วยความจำบนคู่คีย์-ค่าอินพุต สร้างคู่คีย์-ค่าระดับกลาง คู่คีย์-ค่าใหม่นี้จะทำงานเป็นอินพุตที่จะป้อนไปยังฟังก์ชัน Reduce() หรือ Reducer
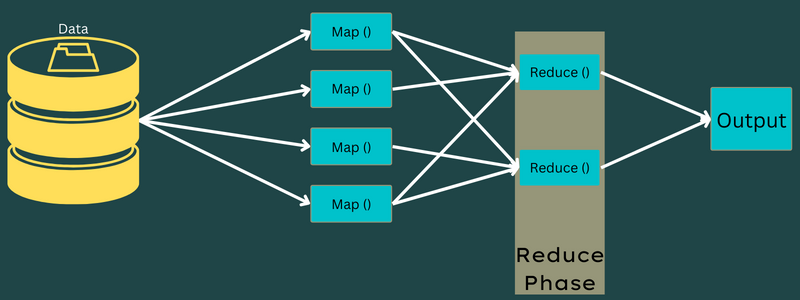
ลด
คู่คีย์-ค่ากลางที่ได้รับในขั้นตอนการทำแผนที่ทำงานเป็นอินพุตสำหรับฟังก์ชันลดหรือตัวลด คล้ายกับขั้นตอนการทำแผนที่ มีสองงานที่เกี่ยวข้อง – สับเปลี่ยนและย่อ
ดังนั้น คู่คีย์-ค่าที่ได้รับจะถูกจัดเรียงและสับเปลี่ยนเพื่อป้อนไปยังตัวลด ถัดไป ตัวลดจะจัดกลุ่มหรือรวบรวมข้อมูลตามคู่ของคีย์-ค่าตามอัลกอริทึมตัวลดที่นักพัฒนาเขียนไว้
ในที่นี้ ค่าจากเฟสการสับเปลี่ยนจะรวมกันเพื่อส่งกลับค่าเอาต์พุต เฟสนี้จะสรุปชุดข้อมูลทั้งหมด
ตอนนี้ กระบวนการที่สมบูรณ์ของการดำเนินการแผนที่และลดงานถูกควบคุมโดยบางหน่วยงาน เหล่านี้คือ:
- ตัวติดตามงาน: พูดง่ายๆ ว่าเครื่องมือติดตามงานทำหน้าที่เป็นผู้เชี่ยวชาญที่รับผิดชอบการทำงานที่ส่งเข้ามาอย่างสมบูรณ์ ตัวติดตามงานจัดการงานและทรัพยากรทั้งหมดทั่วทั้งคลัสเตอร์ นอกจากนี้ ตัวติดตามงานจะกำหนดเวลาทุกแผนที่ที่เพิ่มลงในตัวติดตามงานซึ่งทำงานบนโหนดข้อมูลเฉพาะ
- ตัวติดตามงานหลายตัว: พูดง่ายๆ ว่าตัวติดตามงานหลายตัวทำงานเป็นทาสที่ทำงานตามคำแนะนำของตัวติดตามงาน ตัวติดตามงานถูกปรับใช้บนทุกโหนดแยกกันในคลัสเตอร์ที่ดำเนินการแผนที่และลดงาน
ใช้งานได้เพราะงานจะถูกแบ่งออกเป็นหลายงานที่จะทำงานบนโหนดข้อมูลที่แตกต่างจากคลัสเตอร์ Job Tracker มีหน้าที่รับผิดชอบในการประสานงานงานโดยจัดกำหนดการงานและเรียกใช้งานบนโหนดข้อมูลหลายโหนด ถัดไป Task Tracker ที่อยู่บนโหนดข้อมูลแต่ละโหนดจะดำเนินการบางส่วนของงานและดูแลแต่ละงาน
นอกจากนี้ Task Trackers จะส่งรายงานความคืบหน้าไปยังตัวติดตามงาน นอกจากนี้ Task Tracker จะส่งสัญญาณ "การเต้นของหัวใจ" ไปยัง Job Tracker เป็นระยะและแจ้งสถานะของระบบ ในกรณีที่เกิดความล้มเหลว ตัวติดตามงานสามารถจัดกำหนดการงานใหม่บนตัวติดตามงานอื่นได้
เฟสเอาต์พุต: เมื่อคุณมาถึงเฟสนี้ คุณจะมีคู่คีย์-ค่าสุดท้ายที่สร้างจากตัวลดขนาด คุณสามารถใช้ตัวจัดรูปแบบเอาต์พุตเพื่อแปลคู่คีย์-ค่าและเขียนลงในไฟล์โดยใช้ตัวเขียนบันทึก
ทำไมต้องใช้ MapReduce?
นี่คือประโยชน์บางประการของ MapReduce ซึ่งอธิบายเหตุผลว่าทำไมคุณต้องใช้ในแอปพลิเคชัน Big Data:
การประมวลผลแบบขนาน
คุณสามารถแบ่งงานออกเป็นโหนดต่างๆ โดยที่ทุกโหนดจะจัดการส่วนหนึ่งของงานนี้ใน MapReduce พร้อมกันได้ ดังนั้น การแบ่งงานที่ใหญ่กว่าออกเป็นงานที่เล็กกว่าจะลดความซับซ้อนลง นอกจากนี้ เนื่องจากงานต่างๆ ทำงานพร้อมกันในเครื่องต่างๆ แทนที่จะเป็นเครื่องเดียว การประมวลผลข้อมูลจึงใช้เวลาน้อยลงอย่างมาก
พื้นที่ข้อมูล
ใน MapReduce คุณสามารถย้ายหน่วยประมวลผลไปยังข้อมูลได้ ไม่ใช่ในทางกลับกัน
ในวิธีดั้งเดิม ข้อมูลถูกนำไปยังหน่วยประมวลผลเพื่อทำการประมวลผล อย่างไรก็ตาม ด้วยการเติบโตอย่างรวดเร็วของข้อมูล กระบวนการนี้จึงทำให้เกิดความท้าทายมากมาย บางส่วนมีค่าใช้จ่ายสูงขึ้น ใช้เวลานานขึ้น เป็นภาระของมาสเตอร์โหนด เกิดความล้มเหลวบ่อยครั้ง และประสิทธิภาพของเครือข่ายลดลง
แต่ MapReduce ช่วยแก้ปัญหาเหล่านี้โดยปฏิบัติตามแนวทางย้อนกลับ – นำหน่วยประมวลผลไปยังข้อมูล ด้วยวิธีนี้ ข้อมูลจะถูกกระจายไปตามโหนดต่างๆ โดยที่ทุกโหนดสามารถประมวลผลส่วนหนึ่งของข้อมูลที่เก็บไว้ได้
เป็นผลให้มีความคุ้มค่าและลดเวลาในการประมวลผลเนื่องจากแต่ละโหนดทำงานควบคู่ไปกับส่วนข้อมูลที่เกี่ยวข้อง นอกจากนี้ เนื่องจากทุกโหนดประมวลผลส่วนหนึ่งของข้อมูลนี้ จึงไม่มีโหนดใดทำงานหนักเกินไป
ความปลอดภัย

โมเดล MapReduce ให้ความปลอดภัยที่สูงขึ้น ช่วยปกป้องแอปพลิเคชันของคุณจากข้อมูลที่ไม่ได้รับอนุญาตในขณะที่เพิ่มความปลอดภัยของคลัสเตอร์
ความสามารถในการปรับขนาดและความยืดหยุ่น
MapReduce เป็นเฟรมเวิร์กที่ปรับขนาดได้สูง ช่วยให้คุณสามารถเรียกใช้แอปพลิเคชันจากหลายเครื่องโดยใช้ข้อมูลที่มีเทราไบต์นับพัน นอกจากนี้ยังให้ความยืดหยุ่นในการประมวลผลข้อมูลที่สามารถจัดโครงสร้าง กึ่งโครงสร้าง หรือไม่มีโครงสร้าง และรูปแบบหรือขนาดใดก็ได้
ความเรียบง่าย
คุณสามารถเขียนโปรแกรม MapReduce ในภาษาการเขียนโปรแกรมใดๆ เช่น Java, R, Perl, Python และอื่นๆ ดังนั้นจึงเป็นเรื่องง่ายสำหรับทุกคนในการเรียนรู้และเขียนโปรแกรม ในขณะเดียวกันก็มั่นใจได้ว่าจะเป็นไปตามข้อกำหนดในการประมวลผลข้อมูล
กรณีการใช้งานของ MapReduce
- การทำดัชนีข้อความแบบเต็ม: MapReduce ใช้เพื่อดำเนินการสร้างดัชนีข้อความแบบเต็ม Mapper สามารถจับคู่แต่ละคำหรือวลีในเอกสารเดียว และตัวลดจะใช้ในการเขียนองค์ประกอบที่แมปทั้งหมดไปยังดัชนี
- การคำนวณเพจแรงก์: Google ใช้ MapReduce ในการคำนวณเพจแรงก์
- การวิเคราะห์บันทึก: MapReduce สามารถวิเคราะห์ไฟล์บันทึกได้ มันสามารถแบ่งไฟล์บันทึกขนาดใหญ่ออกเป็นส่วนต่าง ๆ หรือแยกในขณะที่ผู้ทำแผนที่ค้นหาหน้าเว็บที่เข้าถึงได้
คู่คีย์-ค่าจะถูกป้อนไปยังตัวลดหากมีการพบหน้าเว็บในบันทึก ที่นี่ หน้าเว็บจะเป็นคีย์ และดัชนี “1” คือค่า หลังจากแจกคู่คีย์-ค่าให้กับ Reducer แล้ว หน้าเว็บต่างๆ จะถูกรวมเข้าด้วยกัน ผลลัพธ์สุดท้ายคือจำนวน Hit โดยรวมของแต่ละหน้าเว็บ

- Reverse Web-Link Graph: กรอบงานยังพบการใช้งานใน Reverse Web-Link Graph ที่นี่ Map() ให้ผลเป้าหมาย URL และแหล่งที่มาและรับอินพุตจากแหล่งที่มาหรือหน้าเว็บ
ถัดไป Reduce() จะรวมรายการของ URL แหล่งที่มาแต่ละรายการที่เชื่อมโยงกับ URL เป้าหมาย ในที่สุดก็ส่งออกแหล่งที่มาและเป้าหมาย
- การ นับจำนวนคำ: MapReduce ใช้เพื่อนับจำนวนครั้งที่คำปรากฏในเอกสารที่กำหนด
- ภาวะโลกร้อน: องค์กร รัฐบาล และบริษัทต่างๆ สามารถใช้ MapReduce เพื่อแก้ปัญหาภาวะโลกร้อนได้
ตัวอย่างเช่น คุณอาจต้องการทราบเกี่ยวกับระดับอุณหภูมิที่เพิ่มขึ้นของมหาสมุทรอันเนื่องมาจากภาวะโลกร้อน สำหรับสิ่งนี้ คุณสามารถรวบรวมข้อมูลนับพันทั่วโลก ข้อมูลอาจเป็นอุณหภูมิสูง อุณหภูมิต่ำ ละติจูด ลองจิจูด วันที่ เวลา ฯลฯ ซึ่งจะใช้เวลาหลายแผนที่และลดงานในการคำนวณผลลัพธ์โดยใช้ MapReduce
- การทดลองยา: ตามเนื้อผ้านักวิทยาศาสตร์ข้อมูลและนักคณิตศาสตร์ทำงานร่วมกันเพื่อกำหนดยาใหม่ที่สามารถต่อสู้กับความเจ็บป่วย ด้วยการเผยแพร่อัลกอริธึมและ MapReduce แผนกไอทีในองค์กรสามารถจัดการกับปัญหาที่จัดการโดย Supercomputers, Ph.D. นักวิทยาศาสตร์ ฯลฯ ตอนนี้คุณสามารถตรวจสอบประสิทธิภาพของยาสำหรับกลุ่มผู้ป่วยได้
- แอปพลิเคชันอื่นๆ: MapReduce สามารถประมวลผลข้อมูลขนาดใหญ่ที่ไม่พอดีกับฐานข้อมูลเชิงสัมพันธ์ นอกจากนี้ยังใช้เครื่องมือวิทยาศาสตร์ข้อมูลและอนุญาตให้เรียกใช้ผ่านชุดข้อมูลแบบกระจายที่แตกต่างกัน ซึ่งก่อนหน้านี้ทำได้บนคอมพิวเตอร์เครื่องเดียวเท่านั้น
อันเป็นผลมาจากความแข็งแกร่งและความเรียบง่ายของ MapReduce ทำให้พบการใช้งานในด้านการทหาร ธุรกิจ วิทยาศาสตร์ ฯลฯ
บทสรุป
MapReduce สามารถพิสูจน์ได้ว่าเป็นความก้าวหน้าทางเทคโนโลยี ไม่เพียงแต่เป็นกระบวนการที่เร็วและง่ายกว่าเท่านั้น แต่ยังประหยัดต้นทุนและใช้เวลาน้อยลงอีกด้วย เมื่อพิจารณาถึงข้อดีและการใช้งานที่เพิ่มขึ้น มีแนวโน้มว่าจะมีการนำไปใช้ในอุตสาหกรรมและองค์กรต่างๆ มากขึ้น
คุณอาจสำรวจแหล่งข้อมูลที่ดีที่สุดเพื่อเรียนรู้ Big Data และ Hadoop