
Panduan Pengenalan MapReduce di Big Data
Diterbitkan: 2022-09-21MapReduce menawarkan cara yang efektif, lebih cepat, dan hemat biaya untuk membuat aplikasi.
Model ini menggunakan konsep lanjutan seperti pemrosesan paralel, lokalitas data, dll., untuk memberikan banyak manfaat bagi pemrogram dan organisasi.
Tetapi ada begitu banyak model dan kerangka kerja pemrograman di pasaran yang tersedia sehingga menjadi sulit untuk dipilih.
Dan ketika datang ke Big Data, Anda tidak bisa begitu saja memilih apa pun. Anda harus memilih teknologi yang dapat menangani sejumlah besar data.
MapReduce adalah solusi yang bagus untuk itu.
Pada artikel ini, saya akan membahas apa sebenarnya MapReduce dan bagaimana hal itu dapat bermanfaat.
Ayo mulai!
Apa Itu MapReduce?
MapReduce adalah model pemrograman atau kerangka kerja perangkat lunak dalam kerangka Apache Hadoop. Ini digunakan untuk membuat aplikasi yang mampu memproses data besar secara paralel pada ribuan node (disebut cluster atau grid) dengan toleransi kesalahan dan keandalan.
Pemrosesan data ini terjadi pada database atau sistem file tempat data disimpan. MapReduce dapat bekerja dengan Hadoop File System (HDFS) untuk mengakses dan mengelola volume data yang besar.
Framework ini diperkenalkan pada tahun 2004 oleh Google dan dipopulerkan oleh Apache Hadoop. Ini adalah lapisan pemrosesan atau mesin di Hadoop yang menjalankan program MapReduce yang dikembangkan dalam berbagai bahasa, termasuk Java, C++, Python, dan Ruby.
Program MapReduce dalam komputasi awan berjalan secara paralel, sehingga cocok untuk melakukan analisis data dalam skala besar.

MapReduce bertujuan untuk membagi tugas menjadi lebih kecil, beberapa tugas menggunakan fungsi "peta" dan "pengurangan". Ini akan memetakan setiap tugas dan kemudian menguranginya menjadi beberapa tugas yang setara, yang menghasilkan daya pemrosesan dan overhead yang lebih rendah pada jaringan cluster.
Contoh: Misalkan Anda sedang menyiapkan makanan untuk sebuah rumah yang penuh dengan tamu. Jadi, jika Anda mencoba menyiapkan semua hidangan dan melakukan semua prosesnya sendiri, itu akan menjadi sibuk dan memakan waktu.
Tetapi misalkan Anda melibatkan beberapa teman atau kolega Anda (bukan tamu) untuk membantu Anda menyiapkan makanan dengan membagikan proses yang berbeda kepada orang lain yang dapat melakukan tugas secara bersamaan. Dalam hal ini, Anda akan menyiapkan makanan lebih cepat dan lebih mudah saat tamu Anda masih di rumah.
MapReduce bekerja dengan cara yang sama dengan tugas terdistribusi dan pemrosesan paralel untuk memungkinkan cara yang lebih cepat dan lebih mudah untuk menyelesaikan tugas yang diberikan.
Apache Hadoop memungkinkan pemrogram untuk memanfaatkan MapReduce untuk mengeksekusi model pada kumpulan data terdistribusi besar dan menggunakan pembelajaran mesin dan teknik statistik tingkat lanjut untuk menemukan pola, membuat prediksi, korelasi titik, dan banyak lagi.
Fitur MapReduce
Beberapa fitur utama MapReduce adalah:
- Antarmuka pengguna: Anda akan mendapatkan antarmuka pengguna intuitif yang memberikan detail yang masuk akal pada setiap aspek kerangka kerja. Ini akan membantu Anda mengonfigurasi, menerapkan, dan menyetel tugas Anda dengan mulus.

- Payload: Aplikasi menggunakan antarmuka Mapper dan Reducer untuk mengaktifkan peta dan mengurangi fungsi. Mapper memetakan pasangan nilai kunci masukan ke pasangan nilai kunci perantara. Reducer digunakan untuk mengurangi pasangan kunci-nilai menengah yang berbagi kunci ke nilai lain yang lebih kecil. Ini melakukan tiga fungsi - mengurutkan, mengacak, dan mengurangi.
- Partitioner: Ini mengontrol pembagian kunci peta-output perantara.
- Reporter: Ini adalah fungsi untuk melaporkan kemajuan, memperbarui Counter, dan mengatur pesan status.
- Penghitung: Ini mewakili penghitung global yang didefinisikan oleh aplikasi MapReduce.
- OutputCollector: Fungsi ini mengumpulkan data output dari Mapper atau Reducer, bukan output perantara.
- RecordWriter: Ini menulis output data atau pasangan nilai kunci ke file output.
- DistributedCache: Ini secara efisien mendistribusikan file read-only yang lebih besar yang spesifik untuk aplikasi.
- Kompresi data: Penulis aplikasi dapat mengompresi output pekerjaan dan output peta perantara.
- Lompatan catatan buruk: Anda dapat melewati beberapa catatan buruk saat memproses input peta Anda. Fitur ini dapat dikontrol melalui kelas – SkipBadRecords.
- Debugging: Anda akan mendapatkan opsi untuk menjalankan skrip yang ditentukan pengguna dan mengaktifkan debugging. Jika tugas di MapReduce gagal, Anda dapat menjalankan skrip debug dan menemukan masalahnya.
Arsitektur Pengurangan Peta
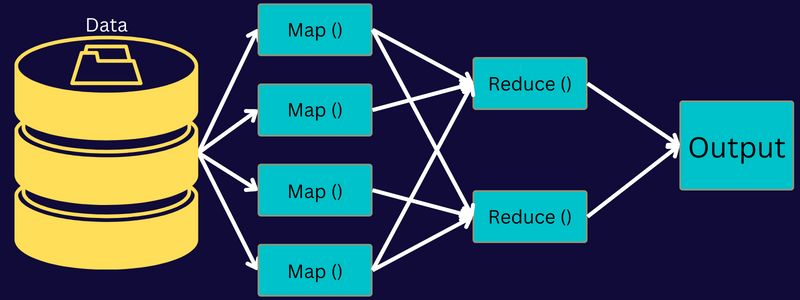
Mari kita pahami arsitektur MapReduce dengan masuk lebih dalam ke komponennya:
- Pekerjaan: Pekerjaan di MapReduce adalah tugas sebenarnya yang ingin dilakukan klien MapReduce. Ini terdiri dari beberapa tugas yang lebih kecil yang digabungkan untuk membentuk tugas akhir.
- Server Riwayat Pekerjaan: Ini adalah proses daemon untuk menyimpan dan menyimpan semua data historis tentang aplikasi atau tugas, seperti log yang dibuat setelah atau sebelum menjalankan pekerjaan.
- Klien: Klien (program atau API) membawa pekerjaan ke MapReduce untuk dieksekusi atau diproses. Di MapReduce, satu atau beberapa klien dapat terus mengirim pekerjaan ke Manajer MapReduce untuk diproses.
- MapReduce Master: Master MapReduce membagi pekerjaan menjadi beberapa bagian yang lebih kecil, memastikan tugas berjalan secara bersamaan.
- Bagian Pekerjaan: Sub pekerjaan atau bagian pekerjaan diperoleh dengan membagi pekerjaan utama. Mereka dikerjakan dan digabungkan pada akhirnya untuk membuat tugas akhir.
- Data input: Ini adalah kumpulan data yang diumpankan ke MapReduce untuk pemrosesan tugas.
- Data keluaran: Ini adalah hasil akhir yang diperoleh setelah tugas diproses.
Jadi, apa yang sebenarnya terjadi dalam arsitektur ini adalah klien mengirimkan pekerjaan ke Master MapReduce, yang membaginya menjadi bagian-bagian yang lebih kecil dan sama. Ini memungkinkan pekerjaan diproses lebih cepat karena tugas yang lebih kecil membutuhkan lebih sedikit waktu untuk diproses daripada tugas yang lebih besar.
Namun, pastikan tugas tidak dibagi menjadi tugas yang terlalu kecil karena jika Anda melakukannya, Anda mungkin harus menghadapi overhead yang lebih besar untuk mengelola pemisahan dan membuang waktu yang signifikan untuk itu.
Selanjutnya, bagian pekerjaan tersedia untuk melanjutkan tugas Peta dan Kurangi. Selanjutnya, tugas Map and Reduce memiliki program yang sesuai berdasarkan use case yang sedang dikerjakan tim. Pemrogram mengembangkan kode berbasis logika untuk memenuhi persyaratan.
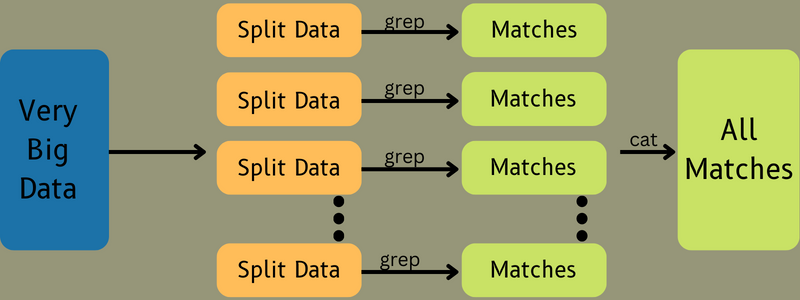
Setelah ini, data input diumpankan ke Tugas Peta sehingga Peta dapat dengan cepat menghasilkan output sebagai pasangan nilai kunci. Alih-alih menyimpan data ini di HDFS, disk lokal digunakan untuk menyimpan data untuk menghilangkan kemungkinan replikasi.
Setelah tugas selesai, Anda dapat membuang hasilnya. Oleh karena itu, replikasi akan menjadi berlebihan saat Anda menyimpan output pada HDFS. Output dari setiap tugas peta akan diumpankan ke tugas pengurangan, dan output peta akan diberikan ke mesin yang menjalankan tugas pengurangan.
Selanjutnya, output akan digabungkan dan diteruskan ke fungsi pengurangan yang ditentukan oleh pengguna. Akhirnya, output yang dikurangi akan disimpan pada HDFS.
Selain itu, proses dapat memiliki beberapa tugas Peta dan Kurangi untuk pemrosesan data tergantung pada tujuan akhir. Algoritma Map and Reduce dioptimalkan untuk menjaga kompleksitas waktu atau ruang tetap minimum.
Karena MapReduce terutama melibatkan tugas Map dan Reduce, penting untuk memahami lebih banyak tentang mereka. Jadi, mari kita bahas fase-fase MapReduce untuk mendapatkan gambaran yang jelas tentang topik-topik ini.
Fase dari MapReduce
Peta
Data input dipetakan ke dalam pasangan output atau key-value dalam fase ini. Di sini, kunci dapat merujuk ke id alamat sedangkan nilainya bisa menjadi nilai sebenarnya dari alamat itu.
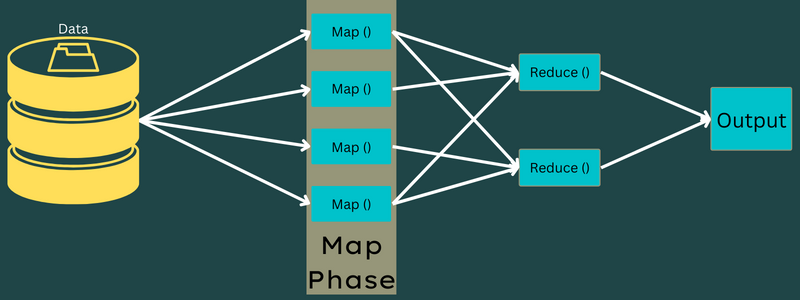
Hanya ada satu tetapi dua tugas dalam fase ini – pemisahan, dan pemetaan. Pemisahan berarti sub-bagian atau bagian pekerjaan yang dipisahkan dari pekerjaan utama. Ini juga disebut input split. Jadi, input split bisa disebut potongan input yang dikonsumsi oleh peta.

Selanjutnya, tugas pemetaan berlangsung. Ini dianggap sebagai fase pertama saat menjalankan program pengurangan peta. Di sini, data yang terkandung dalam setiap pemisahan akan diteruskan ke fungsi peta untuk diproses dan menghasilkan output.
Fungsi – Map() dijalankan dalam repositori memori pada pasangan nilai kunci input, menghasilkan pasangan nilai kunci perantara. Pasangan nilai kunci baru ini akan berfungsi sebagai input untuk diumpankan ke fungsi Reduce() atau Reducer.
Mengurangi
Pasangan nilai kunci perantara yang diperoleh dalam fase pemetaan berfungsi sebagai input untuk fungsi Reduce atau Reducer. Mirip dengan fase pemetaan, ada dua tugas yang terlibat – mengacak dan mengurangi.
Jadi, pasangan nilai kunci yang diperoleh diurutkan dan diacak untuk diumpankan ke Reducer. Selanjutnya, Reducer mengelompokkan atau mengagregasi data sesuai dengan pasangan nilai kuncinya berdasarkan algoritme peredam yang telah ditulis oleh pengembang.
Di sini, nilai-nilai dari fase pengocokan digabungkan untuk mengembalikan nilai keluaran. Fase ini merangkum seluruh dataset.
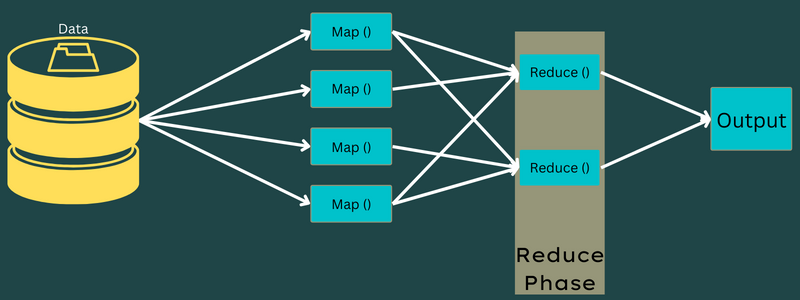
Sekarang, proses lengkap menjalankan tugas Map and Reduce dikendalikan oleh beberapa entitas. Ini adalah:
- Pelacak Pekerjaan: Dengan kata sederhana, pelacak pekerjaan bertindak sebagai master yang bertanggung jawab untuk melaksanakan pekerjaan yang dikirimkan sepenuhnya. Pelacak pekerjaan mengelola semua pekerjaan dan sumber daya di seluruh cluster. Selain itu, pelacak pekerjaan menjadwalkan setiap peta yang ditambahkan pada Pelacak Tugas yang berjalan pada simpul data tertentu.
- Beberapa pelacak tugas: Dengan kata sederhana, beberapa pelacak tugas berfungsi sebagai budak yang melakukan tugas dengan mengikuti instruksi dari Pelacak Pekerjaan. Pelacak tugas dikerahkan pada setiap node secara terpisah di kluster yang menjalankan tugas Peta dan Kurangi.
Ini bekerja karena pekerjaan akan dibagi menjadi beberapa tugas yang akan berjalan pada node data yang berbeda dari sebuah cluster. Job Tracker bertanggung jawab untuk mengoordinasikan tugas dengan menjadwalkan tugas dan menjalankannya di beberapa node data. Selanjutnya, Pelacak Tugas yang ada di setiap simpul data mengeksekusi bagian-bagian pekerjaan dan menjaga setiap tugas.
Selanjutnya, Pelacak Tugas mengirimkan laporan kemajuan ke pelacak pekerjaan. Selain itu, Pelacak Tugas secara berkala mengirimkan sinyal "detak jantung" ke Pelacak Pekerjaan dan memberi tahu mereka tentang status sistem. Jika terjadi kegagalan, pelacak pekerjaan mampu menjadwal ulang pekerjaan di pelacak tugas lain.
Fase keluaran: Saat Anda mencapai fase ini, Anda akan memiliki pasangan nilai kunci terakhir yang dihasilkan dari Peredam. Anda dapat menggunakan formatter keluaran untuk menerjemahkan pasangan nilai kunci dan menulisnya ke file dengan bantuan penulis rekaman.
Mengapa Menggunakan MapReduce?
Berikut adalah beberapa manfaat dari MapReduce, menjelaskan alasan mengapa Anda harus menggunakannya dalam aplikasi big data Anda:
Proses paralel
Anda dapat membagi pekerjaan menjadi node yang berbeda di mana setiap node secara bersamaan menangani bagian dari pekerjaan ini di MapReduce. Jadi, membagi tugas yang lebih besar menjadi tugas yang lebih kecil akan mengurangi kerumitannya. Selain itu, karena tugas yang berbeda dijalankan secara paralel di mesin yang berbeda, bukan di satu mesin, waktu yang dibutuhkan untuk memproses data secara signifikan lebih sedikit.
Lokalitas Data
Di MapReduce, Anda dapat memindahkan unit pemrosesan ke data, bukan sebaliknya.
Dengan cara tradisional, data dibawa ke unit pemrosesan untuk diproses. Namun, dengan pertumbuhan data yang cepat, proses ini mulai menimbulkan banyak tantangan. Beberapa di antaranya adalah biaya yang lebih tinggi, lebih memakan waktu, membebani master node, sering gagal, dan mengurangi kinerja jaringan.
Tetapi MapReduce membantu mengatasi masalah ini dengan mengikuti pendekatan terbalik – membawa unit pemrosesan ke data. Dengan cara ini, data didistribusikan di antara node yang berbeda di mana setiap node dapat memproses sebagian dari data yang disimpan.
Akibatnya, ia menawarkan efektivitas biaya dan mengurangi waktu pemrosesan karena setiap node bekerja secara paralel dengan bagian data yang sesuai. Selain itu, karena setiap node memproses sebagian dari data ini, tidak ada node yang terbebani.
Keamanan

Model MapReduce menawarkan keamanan yang lebih tinggi. Ini membantu melindungi aplikasi Anda dari data yang tidak sah sekaligus meningkatkan keamanan cluster.
Skalabilitas dan Fleksibilitas
MapReduce adalah kerangka kerja yang sangat skalabel. Ini memungkinkan Anda untuk menjalankan aplikasi dari beberapa mesin, menggunakan data dengan ribuan terabyte. Ini juga menawarkan fleksibilitas pemrosesan data yang dapat terstruktur, semi-terstruktur, atau tidak terstruktur dan dalam format atau ukuran apa pun.
Kesederhanaan
Anda dapat menulis program MapReduce dalam bahasa pemrograman apa pun seperti Java, R, Perl, Python, dan lainnya. Oleh karena itu, mudah bagi siapa saja untuk mempelajari dan menulis program sambil memastikan persyaratan pemrosesan data mereka terpenuhi.
Gunakan Kasus MapReduce
- Pengindeksan teks lengkap: MapReduce digunakan untuk melakukan pengindeksan teks lengkap. Mapper-nya dapat memetakan setiap kata atau frasa dalam satu dokumen. Dan Reducer digunakan untuk menulis semua elemen yang dipetakan ke indeks.
- Menghitung Pagerank: Google menggunakan MapReduce untuk menghitung Pagerank.
- Analisis log: MapReduce dapat menganalisis file log. Itu dapat memecah file log besar menjadi berbagai bagian atau split sementara mapper mencari halaman web yang diakses.
Pasangan nilai kunci akan diumpankan ke peredam jika halaman web terlihat di log. Di sini, halaman web akan menjadi kuncinya, dan indeks "1" adalah nilainya. Setelah memberikan pasangan nilai kunci ke Reducer, berbagai halaman web akan digabungkan. Hasil akhir adalah jumlah keseluruhan klik untuk setiap halaman web.

- Grafik Tautan Web Terbalik: Kerangka kerja ini juga menemukan penggunaan dalam Grafik Tautan Web Terbalik. Di sini, Map() menghasilkan target URL dan sumber dan mengambil input dari sumber atau halaman web.
Selanjutnya, Reduce() menggabungkan daftar setiap URL sumber yang terkait dengan URL target. Akhirnya, itu menampilkan sumber dan target.
- Penghitungan kata: MapReduce digunakan untuk menghitung berapa kali sebuah kata muncul dalam dokumen tertentu.
- Pemanasan global: Organisasi, pemerintah, dan perusahaan dapat menggunakan MapReduce untuk memecahkan masalah pemanasan global.
Misalnya , Anda mungkin ingin tahu tentang peningkatan suhu laut akibat pemanasan global. Untuk ini, Anda dapat mengumpulkan ribuan data di seluruh dunia. Data dapat berupa suhu tinggi, suhu rendah, garis lintang, garis bujur, tanggal, waktu, dll. Ini akan mengambil beberapa peta dan mengurangi tugas untuk menghitung output menggunakan MapReduce.
- Uji coba obat: Secara tradisional, ilmuwan data dan ahli matematika bekerja sama untuk merumuskan obat baru yang dapat melawan penyakit. Dengan penyebaran algoritma dan MapReduce, departemen TI dalam organisasi dapat dengan mudah mengatasi masalah yang hanya ditangani oleh Supercomputers, Ph.D. ilmuwan, dll. Sekarang, Anda dapat memeriksa efektivitas obat untuk sekelompok pasien.
- Aplikasi lain: MapReduce bahkan dapat memproses data skala besar yang tidak akan muat dalam database relasional. Ini juga menggunakan alat ilmu data dan memungkinkan menjalankannya pada kumpulan data terdistribusi yang berbeda, yang sebelumnya hanya mungkin dilakukan pada satu komputer.
Sebagai hasil dari ketangguhan dan kesederhanaan MapReduce, ia menemukan aplikasi di militer, bisnis, sains, dll.
Kesimpulan
MapReduce terbukti menjadi terobosan dalam teknologi. Ini bukan hanya proses yang lebih cepat dan sederhana tetapi juga hemat biaya dan tidak memakan waktu lama. Mengingat keunggulannya dan peningkatan penggunaannya, kemungkinan akan menyaksikan adopsi yang lebih tinggi di seluruh industri dan organisasi.
Anda juga dapat menjelajahi beberapa sumber daya terbaik untuk mempelajari Big Data dan Hadoop.