
Вводное руководство по MapReduce в больших данных
Опубликовано: 2022-09-21MapReduce предлагает эффективный, быстрый и экономичный способ создания приложений.
В этой модели используются передовые концепции, такие как параллельная обработка, локальность данных и т. д., что обеспечивает множество преимуществ для программистов и организаций.
Но на рынке так много моделей программирования и фреймворков, что выбрать становится сложно.
А когда дело доходит до больших данных, нельзя просто так что-то выбрать. Вы должны выбирать такие технологии, которые могут обрабатывать большие блоки данных.
MapReduce — отличное решение для этого.
В этой статье я расскажу, что такое MapReduce и чем он может быть полезен.
Давайте начнем!
Что такое MapReduce?
MapReduce — это модель программирования или программная среда в среде Apache Hadoop. Он используется для создания приложений, способных обрабатывать большие объемы данных параллельно на тысячах узлов (называемых кластерами или сетками) с отказоустойчивостью и надежностью.
Эта обработка данных происходит в базе данных или файловой системе, где хранятся данные. MapReduce может работать с файловой системой Hadoop (HDFS) для доступа к большим объемам данных и управления ими.
Эта структура была представлена в 2004 году компанией Google и популяризирована Apache Hadoop. Это уровень обработки или механизм в Hadoop, на котором выполняются программы MapReduce, разработанные на разных языках, включая Java, C++, Python и Ruby.
Программы MapReduce в облачных вычислениях работают параллельно, поэтому подходят для анализа данных в больших масштабах.

MapReduce направлен на разделение задачи на более мелкие, несколько задач с использованием функций «карты» и «уменьшения». Он сопоставит каждую задачу, а затем сократит ее до нескольких эквивалентных задач, что приведет к меньшей вычислительной мощности и накладным расходам в сети кластера.
Пример: Предположим, вы готовите еду для дома, полного гостей. Так что, если вы попытаетесь приготовить все блюда и сделать все процессы самостоятельно, это станет суете и займет много времени.
Но предположим, что вы привлекаете некоторых из своих друзей или коллег (не гостей), чтобы помочь вам приготовить еду, распределяя различные процессы на другого человека, который может выполнять задачи одновременно. В этом случае вы приготовите еду намного быстрее и проще, пока ваши гости еще в доме.
MapReduce работает аналогичным образом с распределенными задачами и параллельной обработкой, чтобы обеспечить более быстрый и простой способ выполнения данной задачи.
Apache Hadoop позволяет программистам использовать MapReduce для выполнения моделей на больших распределенных наборах данных и использовать передовые методы машинного обучения и статистические методы для поиска закономерностей, прогнозирования, выявления корреляций и многого другого.
Возможности MapReduce
Некоторые из основных особенностей MapReduce:
- Пользовательский интерфейс: вы получите интуитивно понятный пользовательский интерфейс, который предоставляет разумную информацию о каждом аспекте фреймворка. Это поможет вам легко настраивать, применять и настраивать задачи.

- Полезная нагрузка: приложения используют интерфейсы Mapper и Reducer для включения функций карты и сокращения. Mapper сопоставляет входные пары ключ-значение с промежуточными парами ключ-значение. Редуктор используется для сокращения промежуточных пар ключ-значение, разделяющих ключ, до других меньших значений. Он выполняет три функции — сортирует, перемешивает и сокращает.
- Разделитель: управляет разделением промежуточных ключей вывода карты.
- Reporter: это функция, позволяющая сообщать о ходе выполнения, обновлять счетчики и устанавливать сообщения о состоянии.
- Счетчики: представляет собой глобальные счетчики, определяемые приложением MapReduce.
- OutputCollector: эта функция собирает выходные данные из Mapper или Reducer вместо промежуточных выходных данных.
- RecordWriter: записывает выходные данные или пары ключ-значение в выходной файл.
- DistributedCache: эффективно распределяет большие файлы только для чтения, относящиеся к конкретному приложению.
- Сжатие данных: автор приложения может сжимать как выходные данные задания, так и промежуточные выходные данные карты.
- Пропуск плохих записей : вы можете пропустить несколько плохих записей при обработке входных данных карты. Этой функцией можно управлять через класс SkipBadRecords.
- Отладка: вы получите возможность запускать пользовательские сценарии и включать отладку. Если задача в MapReduce не удалась, вы можете запустить сценарий отладки и найти проблемы.
Архитектура MapReduce
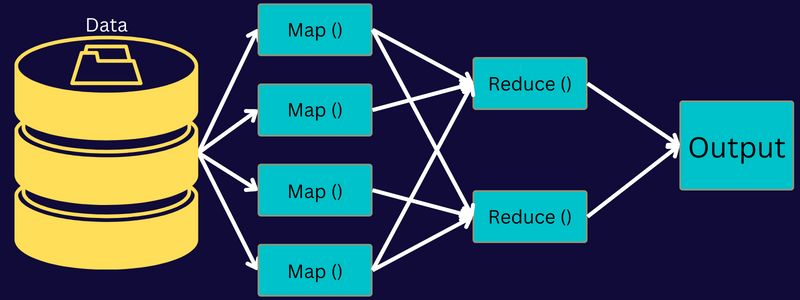
Давайте разберемся с архитектурой MapReduce, углубившись в ее компоненты:
- Задание: Задание в MapReduce — это реальная задача, которую хочет выполнить клиент MapReduce. Он состоит из нескольких более мелких задач, которые в совокупности образуют окончательную задачу.
- Сервер истории заданий: это процесс-демон для хранения и сохранения всех исторических данных о приложении или задаче, таких как журналы, созданные после или до выполнения задания.
- Клиент: клиент (программа или API) передает задание в MapReduce для выполнения или обработки. В MapReduce один или несколько клиентов могут непрерывно отправлять задания MapReduce Manager для обработки.
- Мастер MapReduce: мастер MapReduce делит задание на несколько более мелких частей, обеспечивая одновременное выполнение задач.
- Части работы: дополнительные работы или части работы получаются путем разделения основной работы. Они обрабатываются и, наконец, объединяются, чтобы создать окончательную задачу.
- Входные данные: это набор данных, переданный в MapReduce для обработки задачи.
- Выходные данные: это окончательный результат, полученный после обработки задачи.
Итак, что на самом деле происходит в этой архитектуре, так это то, что клиент отправляет задание мастеру MapReduce, который делит его на более мелкие равные части. Это позволяет выполнять задание быстрее, поскольку для обработки небольших задач требуется меньше времени, чем для более крупных задач.
Тем не менее, убедитесь, что задачи не разделены на слишком маленькие задачи, потому что, если вы это сделаете, вам, возможно, придется столкнуться с большими накладными расходами на управление разделением и тратить на это значительное время.
Затем части задания становятся доступными для выполнения задач Map и Reduce. Кроме того, задачи Map и Reduce имеют подходящую программу, основанную на сценарии использования, над которым работает команда. Программист разрабатывает логический код для выполнения требований.
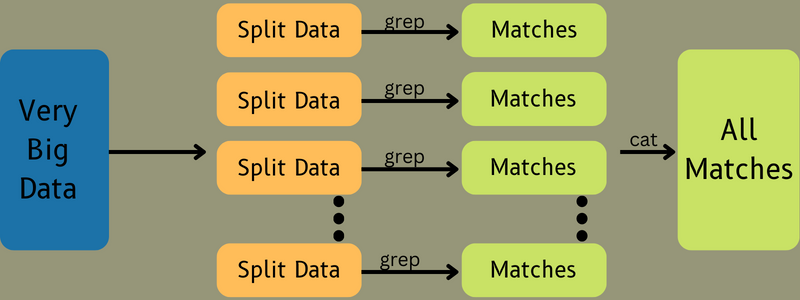
После этого входные данные передаются в задачу карты, чтобы карта могла быстро сгенерировать выходные данные в виде пары ключ-значение. Вместо хранения этих данных в HDFS для хранения данных используется локальный диск, чтобы исключить вероятность репликации.
Как только задача будет выполнена, вы можете выбросить результат. Следовательно, репликация станет излишним, если вы сохраните выходные данные в HDFS. Выходные данные каждой задачи карты будут переданы задаче сокращения, а выходные данные карты будут предоставлены машине, выполняющей задачу сокращения.
Затем выходные данные будут объединены и переданы функции сокращения, определенной пользователем. Наконец, сокращенный вывод будет храниться в HDFS.
Более того, процесс может иметь несколько задач Map и Reduce для обработки данных в зависимости от конечной цели. Алгоритмы Map и Reduce оптимизированы для минимизации временной или пространственной сложности.
Поскольку MapReduce в основном включает задачи Map и Reduce, уместно узнать о них больше. Итак, давайте обсудим этапы MapReduce, чтобы получить четкое представление об этих темах.
Этапы MapReduce
карта
На этом этапе входные данные сопоставляются с выходными или парами ключ-значение. Здесь ключ может относиться к идентификатору адреса, а значение может быть фактическим значением этого адреса.
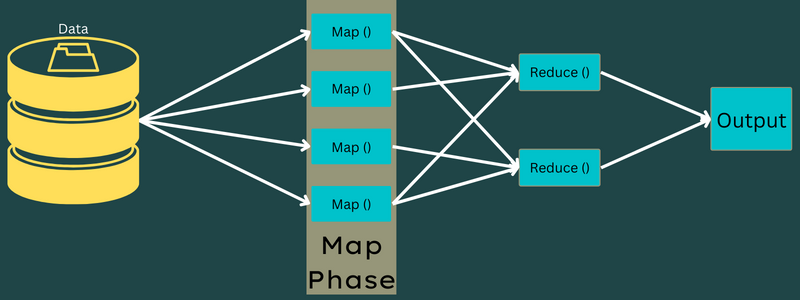
На этом этапе есть только одна, но две задачи — сплиты и картографирование. Разделения означают подчасти или части задания, отделенные от основного задания. Их также называют входными разбиениями. Таким образом, входное разделение можно назвать входным фрагментом, потребляемым картой.

Далее выполняется задача сопоставления. Это считается первой фазой при выполнении программы уменьшения карты. Здесь данные, содержащиеся в каждом разбиении, будут переданы функции отображения для обработки и создания выходных данных.
Функция – Map() выполняется в репозитории памяти для входных пар ключ-значение, создавая промежуточную пару ключ-значение. Эта новая пара ключ-значение будет служить входными данными для функции Reduce() или Reducer.
Уменьшать
Промежуточные пары ключ-значение, полученные на этапе сопоставления, работают как входные данные для функции Reduce или Reducer. Как и на этапе сопоставления, здесь задействованы две задачи — перемешивание и уменьшение.
Таким образом, полученные пары ключ-значение сортируются и перемешиваются для передачи в Редьюсер. Затем редюсер группирует или агрегирует данные в соответствии с парой ключ-значение на основе алгоритма редуктора, написанного разработчиком.
Здесь значения из фазы перетасовки объединяются для возврата выходного значения. На этом этапе подводится итог всему набору данных.
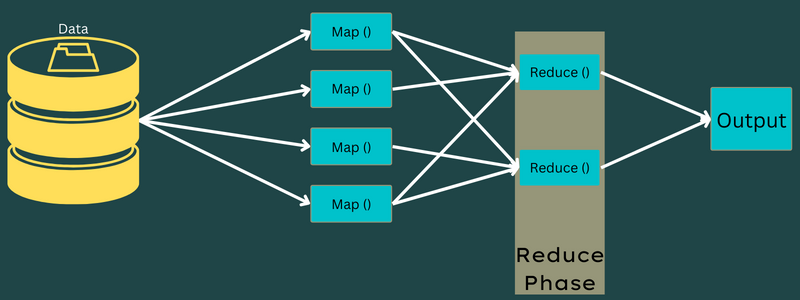
Теперь весь процесс выполнения задач Map и Reduce контролируется некоторыми сущностями. Это:
- Трекер вакансий: Проще говоря, трекер вакансий действует как мастер, который отвечает за полное выполнение отправленного задания. Средство отслеживания заданий управляет всеми заданиями и ресурсами в кластере. Кроме того, средство отслеживания заданий планирует каждую карту, добавленную в средство отслеживания задач, которое работает на определенном узле данных.
- Несколько трекеров задач: Проще говоря, несколько трекеров задач работают как ведомые, выполняя задачу в соответствии с инструкциями трекера заданий. Трекер задач развернут на каждом узле отдельно в кластере, выполняющем задачи Map и Reduce.
Это работает, потому что задание будет разделено на несколько задач, которые будут выполняться на разных узлах данных из кластера. Job Tracker отвечает за координацию задачи, планируя задачи и запуская их на нескольких узлах данных. Затем Task Tracker, сидящий на каждом узле данных, выполняет части задания и следит за каждой задачей.
Кроме того, средства отслеживания задач отправляют отчеты о ходе выполнения в средство отслеживания заданий. Кроме того, Task Tracker периодически отправляет сигнал «пульса» на Job Tracker и уведомляет их о состоянии системы. В случае любого сбоя средство отслеживания заданий может перенести задание на другое средство отслеживания задач.
Фаза вывода: когда вы достигнете этой фазы, у вас будут окончательные пары ключ-значение, сгенерированные из Reducer. Вы можете использовать средство форматирования вывода для преобразования пар ключ-значение и записи их в файл с помощью средства записи.
Зачем использовать MapReduce?
Вот некоторые из преимуществ MapReduce, объясняющие причины, по которым вы должны использовать его в своих приложениях для работы с большими данными:
Параллельная обработка
Вы можете разделить задание на разные узлы, где каждый узел одновременно обрабатывает часть этого задания в MapReduce. Таким образом, разделение больших задач на более мелкие снижает сложность. Кроме того, поскольку разные задачи выполняются параллельно на разных машинах, а не на одной, обработка данных занимает значительно меньше времени.
Местоположение данных
В MapReduce вы можете перемещать блок обработки данных, а не наоборот.
Традиционными способами данные доводились до блока обработки для обработки. Однако с быстрым ростом данных этот процесс стал создавать множество проблем. Некоторые из них были более дорогостоящими, требующими больше времени, нагрузкой на главный узел, частыми сбоями и снижением производительности сети.
Но MapReduce помогает решить эти проблемы, следуя обратному подходу — переносу процессора в данные. Таким образом, данные распределяются между разными узлами, где каждый узел может обрабатывать часть хранимых данных.
В результате это обеспечивает экономическую эффективность и сокращает время обработки, поскольку каждый узел работает параллельно с соответствующей частью данных. Кроме того, поскольку каждый узел обрабатывает часть этих данных, ни один узел не будет перегружен.
Безопасность

Модель MapReduce обеспечивает более высокий уровень безопасности. Это помогает защитить ваше приложение от несанкционированных данных, одновременно повышая безопасность кластера.
Масштабируемость и гибкость
MapReduce — это хорошо масштабируемый фреймворк. Он позволяет запускать приложения с нескольких машин, используя данные объемом в тысячи терабайт. Он также предлагает гибкость обработки данных, которые могут быть структурированными, полуструктурированными или неструктурированными, а также любого формата и размера.
Простота
Вы можете писать программы MapReduce на любом языке программирования, таком как Java, R, Perl, Python и других. Таким образом, любой может легко изучать и писать программы, обеспечивая при этом выполнение своих требований к обработке данных.
Варианты использования MapReduce
- Полнотекстовое индексирование: MapReduce используется для выполнения полнотекстового индексирования. Его Mapper может отображать каждое слово или фразу в одном документе. А Редюсер используется для записи всех сопоставленных элементов в индекс.
- Расчет PageRank: Google использует MapReduce для расчета PageRank.
- Анализ журнала: MapReduce может анализировать файлы журналов. Он может разбивать большой файл журнала на различные части или разделять, пока картограф ищет доступные веб-страницы.
Пара ключ-значение будет передана редюсеру, если веб-страница будет обнаружена в журнале. Здесь веб-страница будет ключом, а индекс «1» — значением. После выдачи пары ключ-значение редуктору различные веб-страницы будут агрегированы. Конечным результатом является общее количество посещений каждой веб-страницы.

- Обратный граф веб-ссылок: эта структура также находит применение в обратном графе веб-ссылок. Здесь Map() возвращает целевой URL-адрес и источник и получает данные из источника или веб-страницы.
Затем Reduce() объединяет список всех исходных URL-адресов, связанных с целевыми URL-адресами. Наконец, он выводит источники и цель.
- Подсчет слов: MapReduce используется для подсчета того, сколько раз слово встречается в данном документе.
- Глобальное потепление: организации, правительства и компании могут использовать MapReduce для решения проблем глобального потепления.
Например , вы можете захотеть узнать о повышении уровня температуры океана из-за глобального потепления. Для этого вы можете собрать тысячи данных по всему миру. Данные могут быть высокой температурой, низкой температурой, широтой, долготой, датой, временем и т. д. для этого потребуется несколько карт и уменьшится количество задач для расчета вывода с помощью MapReduce.
- Испытания лекарств. Традиционно ученые и математики работали вместе, чтобы сформулировать новое лекарство, которое может бороться с болезнью. С распространением алгоритмов и MapReduce ИТ-отделы в организациях могут легко решать проблемы, с которыми справились только суперкомпьютеры, доктор философии. ученые и т. д. Теперь вы можете проверить эффективность препарата для группы пациентов.
- Другие приложения: MapReduce может обрабатывать даже крупномасштабные данные, которые в противном случае не помещались бы в реляционную базу данных. Он также использует инструменты науки о данных и позволяет запускать их на разных распределенных наборах данных, что ранее было возможно только на одном компьютере.
Благодаря надежности и простоте MapReduce находит применение в вооруженных силах, бизнесе, науке и т. д.
Вывод
MapReduce может оказаться прорывом в технологии. Это не только более быстрый и простой процесс, но также экономичный и менее трудоемкий. Учитывая его преимущества и растущее использование, он, вероятно, станет свидетелем более широкого внедрения в различных отраслях и организациях.
Вы также можете изучить некоторые лучшие ресурсы для изучения больших данных и Hadoop.