
ビッグデータにおける MapReduce の導入ガイド
公開: 2022-09-21MapReduce は、アプリケーションを作成するための効果的、高速、かつ費用対効果の高い方法を提供します。
このモデルは、並列処理、データの局所性などの高度な概念を利用して、プログラマーや組織に多くのメリットをもたらします。
しかし、市場には非常に多くのプログラミング モデルとフレームワークがあり、選択が難しくなっています。
そして、ビッグデータに関しては、何も選択することはできません。 大量のデータを処理できるテクノロジーを選択する必要があります。
MapReduce は、それに対する優れたソリューションです。
この記事では、MapReduce とは何か、そして MapReduce がどのように役立つかについて説明します。
はじめましょう!
MapReduce とは?
MapReduce は、Apache Hadoop フレームワーク内のプログラミング モデルまたはソフトウェア フレームワークです。 耐障害性と信頼性を備えた数千のノード (クラスターまたはグリッドと呼ばれる) で大量のデータを並行して処理できるアプリケーションを作成するために使用されます。
このデータ処理は、データが保存されているデータベースまたはファイル システムで行われます。 MapReduce は、Hadoop ファイル システム (HDFS) と連携して、大量のデータにアクセスして管理できます。
このフレームワークは 2004 年に Google によって導入され、Apache Hadoop によって普及しました。 これは、Java、C++、Python、Ruby などのさまざまな言語で開発された MapReduce プログラムを実行する Hadoop の処理レイヤーまたはエンジンです。
クラウド コンピューティングの MapReduce プログラムは並列で実行されるため、大規模なデータ分析を実行するのに適しています。

MapReduce は、「map」および「reduce」関数を使用して、タスクをより小さな複数のタスクに分割することを目的としています。 各タスクをマップし、それをいくつかの同等のタスクに減らします。これにより、クラスター ネットワークの処理能力とオーバーヘッドが削減されます。
例:客でいっぱいの家のために食事を準備しているとします。 そのため、すべての料理を自分で準備し、すべてのプロセスを自分で行おうとすると、多忙で時間がかかります。
しかし、友人や同僚 (ゲストではない) を巻き込んで、タスクを同時に実行できる別の人にさまざまなプロセスを分散させることで、食事の準備を手伝ってもらうとします。 その場合、ゲストがまだ家にいる間に、食事をより速く簡単に準備できます。
MapReduce は、分散タスクと並列処理で同様の方法で機能し、特定のタスクをより迅速かつ簡単に完了できるようにします。
Apache Hadoop を使用すると、プログラマーは MapReduce を利用して大規模な分散データ セットでモデルを実行し、高度な機械学習と統計手法を使用してパターンの検出、予測、相関の特定などを行うことができます。
MapReduceの特徴
MapReduce の主な機能の一部は次のとおりです。
- ユーザー インターフェイス:フレームワークの各側面に関する適切な詳細を提供する直感的なユーザー インターフェイスが得られます。 タスクをシームレスに構成、適用、調整するのに役立ちます。

- ペイロード:アプリケーションは Mapper および Reducer インターフェースを利用して、map および reduce 機能を有効にします。 Mapper は、入力キーと値のペアを中間のキーと値のペアにマップします。 Reducer は、キーを共有する中間のキーと値のペアを他の小さな値に削減するために使用されます。 ソート、シャッフル、リデュースの 3 つの機能を実行します。
- パーティショナー:中間マップ出力キーの分割を制御します。
- レポーター:進行状況の報告、カウンターの更新、ステータスメッセージの設定を行う機能です。
- カウンター: MapReduce アプリケーションが定義するグローバル カウンターを表します。
- OutputCollector:この関数は、中間出力ではなく Mapper または Reducer から出力データを収集します。
- RecordWriter:データ出力またはキーと値のペアを出力ファイルに書き込みます。
- DistributedCache:アプリケーション固有のより大きな読み取り専用ファイルを効率的に分散します。
- データ圧縮:アプリケーション作成者は、ジョブ出力と中間マップ出力の両方を圧縮できます。
- 不良レコードのスキップ:マップ入力の処理中に、いくつかの不良レコードをスキップできます。 この機能は、SkipBadRecords クラスを通じて制御できます。
- デバッグ:ユーザー定義のスクリプトを実行し、デバッグを有効にするオプションが表示されます。 MapReduce のタスクが失敗した場合は、デバッグ スクリプトを実行して問題を見つけることができます。
MapReduce アーキテクチャ
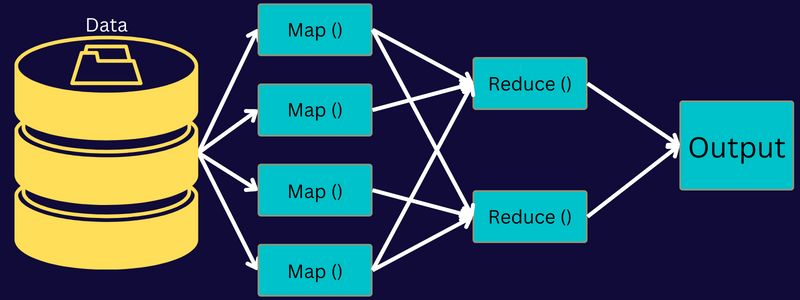
コンポーネントを深く掘り下げて、MapReduce のアーキテクチャを理解しましょう。
- ジョブ: MapReduce のジョブは、MapReduce クライアントが実行したい実際のタスクです。 これは、最終的なタスクを形成するために組み合わされたいくつかの小さなタスクで構成されています。
- ジョブ履歴サーバー: ジョブの実行後または実行前に生成されたログなど、アプリケーションまたはタスクに関するすべての履歴データを保存および保存するデーモン プロセスです。
- クライアント:クライアント (プログラムまたは API) は、実行または処理のためにジョブを MapReduce に持ち込みます。 MapReduce では、1 つまたは複数のクライアントが継続的にジョブを MapReduce Manager に送信して処理することができます。
- MapReduce マスター: MapReduce マスターは、ジョブをいくつかの小さな部分に分割し、タスクが同時に進行するようにします。
- ジョブ パーツ:サブ ジョブまたはジョブ パーツは、プライマリ ジョブを分割することによって得られます。 それらは最終的に作業され、最終的に組み合わされて最終的なタスクが作成されます。
- 入力データ:タスク処理のために MapReduce に供給されるデータセットです。
- 出力データ:タスクが処理された後に得られる最終結果です。
したがって、このアーキテクチャで実際に行われるのは、クライアントがジョブを MapReduce マスターに送信し、マスターがジョブをより小さく等しい部分に分割することです。 これにより、大きなタスクの代わりに小さなタスクの処理にかかる時間が短縮されるため、ジョブをより速く処理できます。
ただし、タスクが小さすぎるタスクに分割されないようにしてください。そうすると、分割を管理するオーバーヘッドが大きくなり、かなりの時間を無駄にする可能性があるためです。
次に、Map および Reduce タスクを続行するために、ジョブ パーツが使用可能になります。 さらに、Map および Reduce タスクには、チームが取り組んでいるユース ケースに基づいた適切なプログラムがあります。 プログラマーは、要件を満たすロジック ベースのコードを開発します。
この後、入力データが Map タスクに渡され、Map がキーと値のペアとして出力をすばやく生成できるようになります。 このデータを HDFS に格納する代わりに、ローカル ディスクを使用してデータを格納し、レプリケーションの可能性を排除します。
タスクが完了したら、出力を破棄できます。 したがって、出力を HDFS に保存すると、レプリケーションはやり過ぎになります。 各 map タスクの出力は reduce タスクに供給され、map 出力は reduce タスクを実行しているマシンに提供されます。
次に、出力がマージされ、ユーザーが定義した reduce 関数に渡されます。 最後に、削減された出力が HDFS に保存されます。
さらに、プロセスには、最終目標に応じて、データ処理用の複数の Map および Reduce タスクを含めることができます。 Map および Reduce アルゴリズムは、時間または空間の複雑さを最小限に抑えるように最適化されています。
MapReduce には主に Map タスクと Reduce タスクが含まれるため、それらについてさらに理解することが重要です。 それでは、MapReduce のフェーズについて説明して、これらのトピックを明確に理解してください。
MapReduce のフェーズ
地図
入力データは、このフェーズで出力またはキーと値のペアにマップされます。 ここで、キーはアドレスの ID を参照でき、値はそのアドレスの実際の値にすることができます。
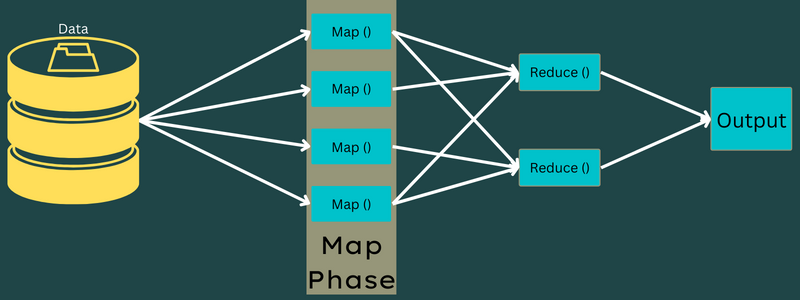
このフェーズには、分割とマッピングの 2 つのタスクしかありません。 分割とは、メイン ジョブから分割されたサブ パーツまたはジョブ パーツを意味します。 これらは入力分割とも呼ばれます。 したがって、入力分割は、マップによって消費される入力チャンクと呼ぶことができます。

次に、マッピング タスクが実行されます。 これは、map-reduce プログラムを実行する際の最初のフェーズと見なされます。 ここでは、すべての分割に含まれるデータが map 関数に渡され、出力が処理および生成されます。
関数 – Map() は、入力キーと値のペアに対してメモリ リポジトリで実行され、中間のキーと値のペアを生成します。 この新しいキーと値のペアは、Reduce() または Reducer 関数に渡される入力として機能します。
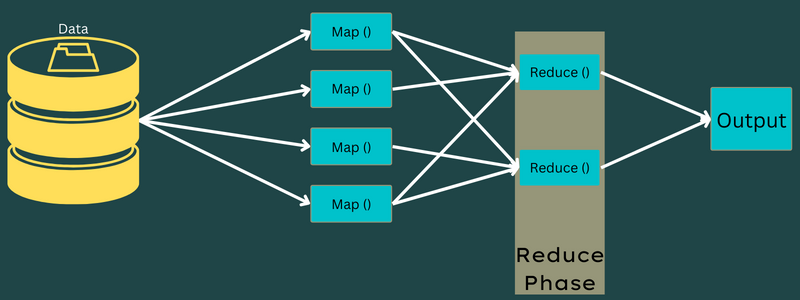
減らす
マッピング フェーズで取得された中間のキーと値のペアは、Reduce 関数または Reducer の入力として機能します。 マッピング フェーズと同様に、shuffle と reduce という 2 つのタスクが関係します。
そのため、取得されたキーと値のペアは並べ替えられてシャッフルされ、Reducer に渡されます。 次に、Reducer は、開発者が作成した Reducer アルゴリズムに基づいて、キーと値のペアに従ってデータをグループ化または集約します。
ここでは、シャッフル フェーズの値を組み合わせて出力値を返します。 このフェーズでは、データセット全体を合計します。
現在、Map および Reduce タスクを実行する完全なプロセスは、いくつかのエンティティによって制御されています。 これらは:
- ジョブ トラッカー:簡単に言えば、ジョブ トラッカーは、送信されたジョブを完全に実行する責任を負うマスターとして機能します。 ジョブ トラッカーは、クラスター全体のすべてのジョブとリソースを管理します。 さらに、ジョブ トラッカーは、特定のデータ ノードで実行されるタスク トラッカーに追加されたすべてのマップをスケジュールします。
- 複数のタスク トラッカー:簡単に言えば、複数のタスク トラッカーがスレーブとして機能し、ジョブ トラッカーの指示に従ってタスクを実行します。 タスク トラッカーは、Map および Reduce タスクを実行するクラスター内のすべてのノードに個別にデプロイされます。
これが機能するのは、ジョブがクラスターの異なるデータ ノードで実行される複数のタスクに分割されるためです。 ジョブ トラッカーは、タスクをスケジュールして複数のデータ ノードで実行することにより、タスクを調整します。 次に、各データ ノードにあるタスク トラッカーがジョブの一部を実行し、各タスクを監視します。
さらに、タスク トラッカーは進行状況レポートをジョブ トラッカーに送信します。 また、タスク トラッカーは定期的に「ハートビート」信号をジョブ トラッカーに送信し、システム ステータスを通知します。 障害が発生した場合、ジョブ トラッカーは別のタスク トラッカーでジョブを再スケジュールできます。
出力フェーズ: このフェーズに到達すると、Reducer から最終的なキーと値のペアが生成されます。 出力フォーマッターを使用してキーと値のペアを変換し、レコード ライターを使用してそれらをファイルに書き込むことができます。
MapReduce を使用する理由
MapReduce の利点のいくつかを次に示し、ビッグ データ アプリケーションで MapReduce を使用する必要がある理由を説明します。
並列処理
ジョブを異なるノードに分割し、すべてのノードが MapReduce でこのジョブの一部を同時に処理することができます。 したがって、大きなタスクを小さなタスクに分割すると、複雑さが軽減されます。 また、単一のマシンではなく、異なるマシンで異なるタスクが並行して実行されるため、データの処理にかかる時間が大幅に短縮されます。
データの局所性
MapReduce では、処理単位をデータに移動できますが、その逆はできません。
従来の方法では、データは処理のために処理ユニットに送られました。 しかし、データが急速に増加するにつれて、このプロセスは多くの課題を引き起こし始めました。 それらのいくつかは、コストが高く、時間がかかり、マスター ノードに負担がかかり、頻繁に障害が発生し、ネットワーク パフォーマンスが低下しました。
しかし、MapReduce は逆のアプローチ (処理単位をデータにもたらす) に従うことで、これらの問題を克服するのに役立ちます。 このようにして、データはさまざまなノードに分散され、すべてのノードが保存されたデータの一部を処理できます。
その結果、各ノードが対応するデータ部分と並行して動作するため、費用対効果が高くなり、処理時間が短縮されます。 さらに、すべてのノードがこのデータの一部を処理するため、ノードに過負荷がかかることはありません。
安全

MapReduce モデルは、より高いセキュリティを提供します。 クラスターのセキュリティを強化しながら、不正なデータからアプリケーションを保護するのに役立ちます。
スケーラビリティと柔軟性
MapReduce は非常にスケーラブルなフレームワークです。 数千テラバイトのデータを使用して、複数のマシンからアプリケーションを実行できます。 また、構造化、半構造化、または構造化されていない、任意の形式またはサイズのデータを柔軟に処理できます。
シンプルさ
Java、R、Perl、Python などの任意のプログラミング言語で MapReduce プログラムを作成できます。 したがって、データ処理要件を満たしながら、誰でも簡単にプログラムを学習および作成できます。
MapReduce のユースケース
- フルテキスト インデックス作成: MapReduce を使用してフルテキスト インデックス作成を実行します。 そのマッパーは、単一のドキュメント内の各単語またはフレーズをマップできます。 そして、Reducer を使用して、マップされたすべての要素をインデックスに書き込みます。
- ページランクの計算: Google は、ページランクの計算に MapReduce を使用します。
- ログ分析: MapReduce はログ ファイルを分析できます。 マッパーがアクセスされた Web ページを検索している間に、大きなログ ファイルをさまざまな部分または分割に分割できます。
ログに Web ページが見つかった場合、キーと値のペアがレデューサーに供給されます。 ここでは、Web ページがキーになり、インデックス「1」が値になります。 キーと値のペアを Reducer に渡すと、さまざまな Web ページが集約されます。 最終的な出力は、各 Web ページの総ヒット数です。

- リバース Web リンク グラフ:フレームワークは、リバース Web リンク グラフでも使用されます。 ここで、Map() は URL ターゲットとソースを生成し、ソースまたは Web ページから入力を受け取ります。
次に、Reduce() は、ターゲット URL に関連付けられた各ソース URL のリストを集約します。 最後に、ソースとターゲットを出力します。
- 単語カウント: MapReduce は、特定のドキュメントに単語が出現する回数をカウントするために使用されます。
- 地球温暖化:組織、政府、および企業は、MapReduce を使用して地球温暖化の問題を解決できます。
たとえば、地球温暖化による海洋温度の上昇について知りたい場合があります。 このために、世界中の何千ものデータを収集できます。 データは、高温、低温、緯度、経度、日付、時刻などです。これには複数のマップが必要であり、MapReduce を使用して出力を計算するタスクが削減されます。
- 薬物試験:従来、データ サイエンティストと数学者は協力して、病気と闘うことができる新薬を開発していました。 アルゴリズムと MapReduce の普及により、組織の IT 部門は、スーパーコンピューターのみが処理していた問題に簡単に取り組むことができます。 これで、患者グループに対する薬の有効性を調べることができます。
- その他のアプリケーション: MapReduce は、他の方法ではリレーショナル データベースに収まらない大規模なデータも処理できます。 また、データ サイエンス ツールを使用し、以前は 1 台のコンピューターでしか実行できなかった、さまざまな分散データセットでそれらを実行できます。
MapReduce の堅牢性とシンプルさの結果として、軍事、ビジネス、科学などに応用されています。
結論
MapReduce は、テクノロジーのブレークスルーになる可能性があります。 これは、プロセスが高速で単純であるだけでなく、コスト効率が高く、時間もかかりません。 その利点と使用の増加を考えると、業界や組織全体でより多くの採用が見られる可能性があります。
また、ビッグ データと Hadoop を学習するための最良のリソースを探索することもできます。