
دليل مقدمة إلى MapReduce في البيانات الضخمة
نشرت: 2022-09-21يوفر MapReduce طريقة فعالة وسريعة وفعالة من حيث التكلفة لإنشاء التطبيقات.
يستخدم هذا النموذج مفاهيم متقدمة مثل المعالجة المتوازية ، ومكان البيانات ، وما إلى ذلك ، لتوفير الكثير من الفوائد للمبرمجين والمؤسسات.
ولكن هناك الكثير من نماذج وأطر البرمجة المتاحة في السوق بحيث يصبح من الصعب الاختيار.
وعندما يتعلق الأمر بالبيانات الضخمة ، لا يمكنك اختيار أي شيء. يجب عليك اختيار مثل هذه التقنيات التي يمكنها التعامل مع أجزاء كبيرة من البيانات.
MapReduce هو حل رائع لذلك.
في هذه المقالة ، سأناقش ماهية MapReduce حقًا وكيف يمكن أن يكون مفيدًا.
لنبدأ!
ما هو MapReduce؟
MapReduce هو نموذج برمجة أو إطار عمل برمجي ضمن إطار عمل Apache Hadoop. يتم استخدامه لإنشاء تطبيقات قادرة على معالجة البيانات الضخمة بالتوازي على آلاف العقد (تسمى المجموعات أو الشبكات) مع تحمل الخطأ والموثوقية.
تحدث معالجة البيانات هذه على قاعدة بيانات أو نظام ملفات حيث يتم تخزين البيانات. يمكن أن يعمل MapReduce مع نظام ملفات Hadoop (HDFS) للوصول إلى كميات كبيرة من البيانات وإدارتها.
تم تقديم إطار العمل هذا في عام 2004 بواسطة Google وتم تعميمه بواسطة Apache Hadoop. إنها طبقة معالجة أو محرك في Hadoop يقوم بتشغيل برامج MapReduce المطورة بلغات مختلفة ، بما في ذلك Java و C ++ و Python و Ruby.
تعمل برامج MapReduce في الحوسبة السحابية بالتوازي ، وبالتالي فهي مناسبة لإجراء تحليل البيانات على نطاقات كبيرة.

يهدف MapReduce إلى تقسيم المهمة إلى مهام أصغر ومتعددة باستخدام وظائف "الخريطة" و "تقليل". سيقوم بتعيين كل مهمة ثم تقليصها إلى عدة مهام مكافئة ، مما يؤدي إلى تقليل قوة المعالجة والنفقات العامة على شبكة الكتلة.
مثال: لنفترض أنك تحضر وجبة لمنزل مليء بالضيوف. لذلك ، إذا حاولت تحضير جميع الأطباق والقيام بجميع العمليات بنفسك ، فستصبح محمومة وتستغرق وقتًا طويلاً.
لكن افترض أنك أشركت بعضًا من أصدقائك أو زملائك (وليس الضيوف) لمساعدتك في تحضير الوجبة من خلال توزيع عمليات مختلفة على شخص آخر يمكنه أداء المهام في وقت واحد. في هذه الحالة ، ستقوم بإعداد الوجبة بطريقة أسرع وأسهل بينما لا يزال ضيوفك في المنزل.
يعمل MapReduce بطريقة مماثلة مع المهام الموزعة والمعالجة المتوازية لتمكين طريقة أسرع وأسهل لإكمال مهمة معينة.
يسمح Apache Hadoop للمبرمجين باستخدام MapReduce لتنفيذ النماذج على مجموعات البيانات الكبيرة الموزعة واستخدام التعلم الآلي المتقدم والتقنيات الإحصائية للعثور على الأنماط وإجراء التنبؤات والارتباطات الموضعية والمزيد.
ميزات MapReduce
بعض الميزات الرئيسية لبرنامج MapReduce هي:
- واجهة المستخدم: ستحصل على واجهة مستخدم سهلة الاستخدام توفر تفاصيل معقولة عن كل جانب من جوانب إطار العمل. سيساعدك على تكوين مهامك وتطبيقها وضبطها بسلاسة.

- الحمولة الصافية: تستخدم التطبيقات واجهات Mapper و Reducer لتمكين الخريطة وتقليل الوظائف. يقوم مخطط الخرائط بإدخال أزواج القيمة الرئيسية إلى أزواج القيمة الرئيسية الوسيطة. يستخدم المخفض لتقليل أزواج القيمة الرئيسية المتوسطة التي تشترك في المفتاح مع القيم الأصغر الأخرى. يؤدي ثلاث وظائف - الفرز والخلط والتقليل.
- التقسيم: يتحكم في تقسيم مفاتيح إخراج الخرائط الوسيطة.
- المراسل: إنها وظيفة للإبلاغ عن التقدم وتحديث العدادات وتعيين رسائل الحالة.
- العدادات: تمثل العدادات العامة التي يحددها تطبيق MapReduce.
- OutputCollector: تجمع هذه الوظيفة بيانات الإخراج من Mapper أو Reducer بدلاً من المخرجات الوسيطة.
- RecordWriter: يكتب إخراج البيانات أو أزواج القيمة الرئيسية إلى ملف الإخراج.
- DistributedCache: يوزع بكفاءة ملفات أكبر للقراءة فقط خاصة بالتطبيق.
- ضغط البيانات: يمكن لكاتب التطبيق ضغط مخرجات الوظيفة ومخرجات الخريطة الوسيطة.
- تخطي السجل السيئ: يمكنك تخطي العديد من السجلات السيئة أثناء معالجة مدخلات الخريطة. يمكن التحكم في هذه الميزة من خلال الفصل الدراسي - SkipBadRecords.
- تصحيح الأخطاء: ستحصل على خيار تشغيل البرامج النصية المعرفة من قبل المستخدم وتمكين تصحيح الأخطاء. إذا فشلت مهمة في MapReduce ، يمكنك تشغيل البرنامج النصي لتصحيح الأخطاء والعثور على المشكلات.
هندسة MapReduce
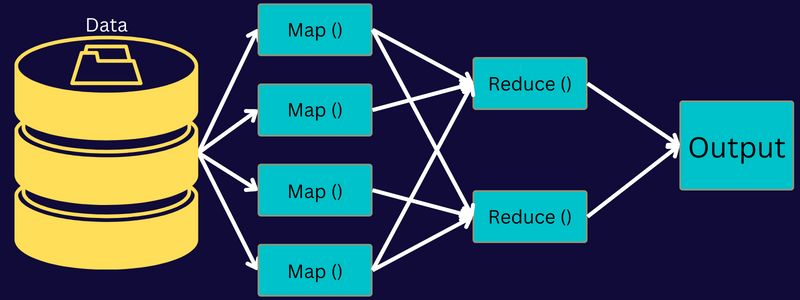
دعونا نفهم بنية MapReduce من خلال التعمق في مكوناته:
- الوظيفة: الوظيفة في MapReduce هي المهمة الفعلية التي يريد عميل MapReduce تنفيذها. وهو يتألف من عدة مهام أصغر تتحد لتشكل المهمة النهائية.
- خادم محفوظات الوظيفة: إنها عملية خفية لتخزين وحفظ جميع البيانات التاريخية حول تطبيق أو مهمة ، مثل السجلات التي تم إنشاؤها بعد أو قبل تنفيذ مهمة ما.
- العميل: يقوم العميل (البرنامج أو API) بإحضار وظيفة إلى MapReduce للتنفيذ أو المعالجة. في MapReduce ، يمكن لعميل واحد أو أكثر إرسال المهام باستمرار إلى MapReduce Manager للمعالجة.
- MapReduce Master: يقوم MapReduce Master بتقسيم الوظيفة إلى عدة أجزاء أصغر ، مما يضمن تقدم المهام في وقت واحد.
- أجزاء الوظيفة: يتم الحصول على الوظائف الفرعية أو أجزاء الوظيفة عن طريق قسمة الوظيفة الأساسية. يتم العمل عليها وتجميعها أخيرًا لإنشاء المهمة النهائية.
- بيانات الإدخال: إنها مجموعة البيانات التي يتم تغذيتها إلى MapReduce لمعالجة المهام.
- بيانات الإخراج: هي النتيجة النهائية التي يتم الحصول عليها بمجرد معالجة المهمة.
لذلك ، ما يحدث بالفعل في هذه البنية هو أن العميل يرسل وظيفة إلى MapReduce Master ، الذي يقسمها إلى أجزاء أصغر متساوية. يتيح ذلك معالجة المهمة بشكل أسرع حيث تستغرق المهام الأصغر وقتًا أقل لمعالجتها بدلاً من المهام الأكبر.
ومع ذلك ، تأكد من عدم تقسيم المهام إلى مهام صغيرة جدًا لأنه إذا قمت بذلك ، فقد تضطر إلى مواجهة عبء أكبر لإدارة الانقسامات وإضاعة وقت كبير في ذلك.
بعد ذلك ، يتم توفير أجزاء الوظيفة للمضي قدمًا في مهام الخريطة والتقليل. علاوة على ذلك ، فإن مهام الخريطة والتقليل لها برنامج مناسب يعتمد على حالة الاستخدام التي يعمل عليها الفريق. يطور المبرمج الكود المنطقي للوفاء بالمتطلبات.
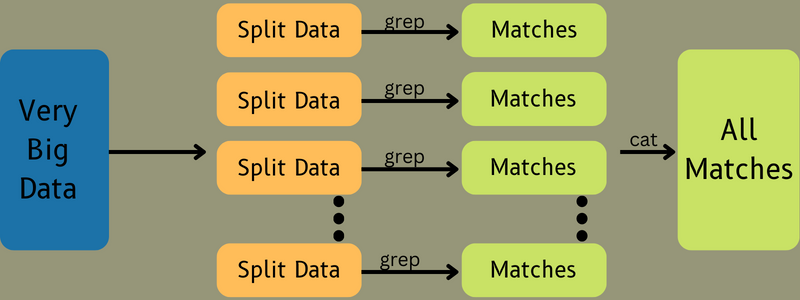
بعد ذلك ، يتم تغذية بيانات الإدخال إلى مهمة الخريطة بحيث يمكن للخريطة أن تولد المخرجات بسرعة كزوج ذي قيمة مفتاح. بدلاً من تخزين هذه البيانات على HDFS ، يتم استخدام قرص محلي لتخزين البيانات للقضاء على فرصة النسخ المتماثل.
بمجرد اكتمال المهمة ، يمكنك التخلص من الإخراج. ومن ثم ، فإن النسخ المتماثل سيصبح مبالغة عند تخزين الإخراج على HDFS. سيتم تغذية ناتج كل مهمة خريطة بمهمة تقليل ، وسيتم توفير إخراج الخريطة للجهاز الذي يقوم بتشغيل مهمة التقليل.
بعد ذلك ، سيتم دمج الإخراج وتمريره إلى وظيفة التصغير التي يحددها المستخدم. أخيرًا ، سيتم تخزين المخرجات المخفضة على HDFS.
علاوة على ذلك ، يمكن أن تحتوي العملية على العديد من مهام الخرائط والتقليل لمعالجة البيانات اعتمادًا على الهدف النهائي. تم تحسين خوارزميات Map and Reduce للحفاظ على الحد الأدنى من الوقت أو المساحة المعقدة.
نظرًا لأن MapReduce يتضمن بشكل أساسي مهام Map and Reduce ، فمن المناسب فهم المزيد عنها. لذا ، دعونا نناقش مراحل MapReduce للحصول على فكرة واضحة عن هذه المواضيع.
مراحل MapReduce
خريطة
يتم تعيين بيانات الإدخال في أزواج المخرجات أو القيمة الرئيسية في هذه المرحلة. هنا ، يمكن أن يشير المفتاح إلى معرف العنوان بينما يمكن أن تكون القيمة هي القيمة الفعلية لذلك العنوان.
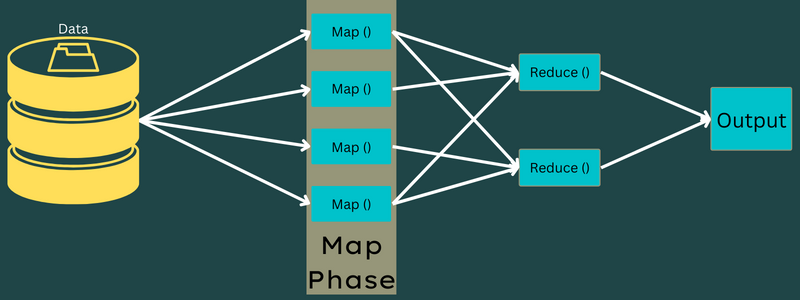
هناك مهمة واحدة فقط ولكن مهمتين في هذه المرحلة - الانقسامات والتخطيط. الانقسامات تعني الأجزاء الفرعية أو أجزاء العمل المقسمة من الوظيفة الرئيسية. وتسمى هذه أيضًا تقسيمات الإدخال. لذلك ، يمكن تسمية تقسيم الإدخال بقطعة إدخال تستهلكها الخريطة.

بعد ذلك ، تتم مهمة التعيين. تعتبر المرحلة الأولى أثناء تنفيذ برنامج تقليل الخريطة. هنا ، سيتم تمرير البيانات الموجودة في كل تقسيم إلى وظيفة الخريطة لمعالجة وإنشاء المخرجات.
يتم تنفيذ الوظيفة - Map () في مستودع الذاكرة على أزواج الإدخال والقيمة ، مما يؤدي إلى إنشاء زوج متوسط-قيمة. سيعمل هذا الزوج الجديد ذو القيمة الرئيسية كمدخل يتم تغذيته بوظيفة Reduce () أو Reducer.
خفض
تعمل أزواج القيمة الرئيسية الوسيطة التي تم الحصول عليها في مرحلة التعيين كمدخل لوظيفة Reduce أو Reducer. على غرار مرحلة رسم الخرائط ، يتم تضمين مهمتين - التبديل والتقليل.
لذلك ، يتم فرز أزواج القيمة الرئيسية التي تم الحصول عليها وخلطها لتغذية المخفض. بعد ذلك ، يقوم Reducer بتجميع البيانات أو تجميعها وفقًا لزوج القيمة الرئيسية بناءً على خوارزمية المخفض التي كتبها المطور.
هنا ، يتم دمج القيم من مرحلة الخلط لإرجاع قيمة الإخراج. تلخص هذه المرحلة مجموعة البيانات بأكملها.
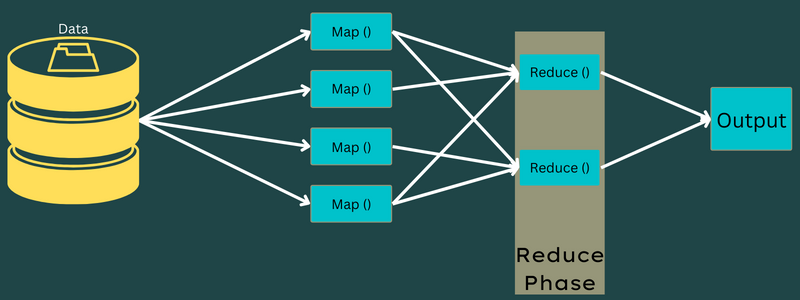
الآن ، يتم التحكم في العملية الكاملة لتنفيذ مهام الخريطة والتقليل من قبل بعض الكيانات. هؤلاء هم:
- متعقب الوظيفة: بكلمات بسيطة ، يعمل متعقب الوظائف بصفته سيدًا مسؤولاً عن تنفيذ وظيفة مقدمة بالكامل. يقوم متعقب الوظائف بإدارة جميع الوظائف والموارد عبر مجموعة. بالإضافة إلى ذلك ، يقوم متتبع الوظائف بجدولة كل خريطة تتم إضافتها على Task Tracker والتي تعمل على عقدة بيانات محددة.
- متتبعات المهام المتعددة: بكلمات بسيطة ، تعمل أدوات تعقب المهام المتعددة كعبيد يؤدون المهمة باتباع تعليمات متعقب الوظائف. يتم نشر أداة تعقب المهام على كل عقدة بشكل منفصل في المجموعة التي تقوم بتنفيذ الخريطة وتقليل المهام.
إنه يعمل لأنه سيتم تقسيم المهمة إلى عدة مهام يتم تشغيلها على عقد بيانات مختلفة من مجموعة. يعد Job Tracker مسؤولاً عن تنسيق المهمة عن طريق جدولة المهام وتشغيلها على عقد بيانات متعددة. بعد ذلك ، يقوم Task Tracker الموجود على كل عقدة بيانات بتنفيذ أجزاء من المهمة ويهتم بكل مهمة.
علاوة على ذلك ، يرسل متتبعو المهام تقارير مرحلية إلى متعقب الوظائف. أيضًا ، يرسل Task Tracker بشكل دوري إشارة "نبضات القلب" إلى Job Tracker ويبلغهم بحالة النظام. في حالة حدوث أي فشل ، يكون متعقب الوظائف قادرًا على إعادة جدولة الوظيفة في متتبع مهمة آخر.
مرحلة الإخراج: عندما تصل إلى هذه المرحلة ، سيكون لديك أزواج المفتاح والقيمة النهائية التي تم إنشاؤها من المخفض. يمكنك استخدام مُنسق الإخراج لترجمة أزواج المفتاح والقيمة وكتابتها في ملف بمساعدة كاتب السجلات.
لماذا تستخدم MapReduce؟
فيما يلي بعض مزايا MapReduce ، موضحًا الأسباب التي تجعلك تستخدمه في تطبيقات البيانات الضخمة الخاصة بك:
المعالجة المتوازية
يمكنك تقسيم مهمة ما إلى عقد مختلفة حيث تعالج كل عقدة في وقت واحد جزءًا من هذه الوظيفة في MapReduce. لذا ، فإن تقسيم المهام الأكبر إلى مهام أصغر يقلل من التعقيد. أيضًا ، نظرًا لأن المهام المختلفة تعمل بالتوازي في أجهزة مختلفة بدلاً من جهاز واحد ، فإن معالجة البيانات تستغرق وقتًا أقل بشكل ملحوظ.
منطقة البيانات
في MapReduce ، يمكنك نقل وحدة المعالجة إلى البيانات ، وليس العكس.
بالطرق التقليدية ، يتم إحضار البيانات إلى وحدة المعالجة للمعالجة. ومع ذلك ، مع النمو السريع للبيانات ، بدأت هذه العملية في طرح العديد من التحديات. كان بعضها أعلى تكلفة ، ويستغرق وقتًا أطول ، ويثقل كاهل العقدة الرئيسية ، والفشل المتكرر ، وأداء الشبكة المنخفض.
لكن MapReduce يساعد في التغلب على هذه المشكلات باتباع نهج عكسي - جلب وحدة معالجة للبيانات. بهذه الطريقة ، يتم توزيع البيانات بين العقد المختلفة حيث يمكن لكل عقدة معالجة جزء من البيانات المخزنة.
ونتيجة لذلك ، فإنه يوفر فعالية من حيث التكلفة ويقلل من وقت المعالجة نظرًا لأن كل عقدة تعمل بالتوازي مع جزء البيانات المقابل لها. بالإضافة إلى ذلك ، نظرًا لأن كل عقدة تعالج جزءًا من هذه البيانات ، فلن تكون هناك عقدة مثقلة بالأعباء.
حماية

يوفر نموذج MapReduce أمانًا أعلى. يساعد في حماية التطبيق الخاص بك من البيانات غير المصرح بها مع تعزيز أمان المجموعة.
قابلية التوسع والمرونة
MapReduce هو إطار عمل قابل للتطوير بدرجة كبيرة. يسمح لك بتشغيل التطبيقات من عدة أجهزة ، باستخدام بيانات بآلاف تيرابايت. كما يوفر مرونة معالجة البيانات التي يمكن أن تكون منظمة أو شبه منظمة أو غير منظمة وبأي تنسيق أو حجم.
بساطة
يمكنك كتابة برامج MapReduce بأي لغة برمجة مثل Java و R و Perl و Python والمزيد. لذلك ، من السهل على أي شخص تعلم البرامج وكتابتها مع ضمان تلبية متطلبات معالجة البيانات الخاصة بهم.
حالات استخدام MapReduce
- فهرسة النص الكامل: يستخدم MapReduce لإجراء فهرسة نص كامل. يمكن لمخططه تعيين كل كلمة أو عبارة في مستند واحد. ويستخدم المخفض لكتابة جميع العناصر المعينة إلى فهرس.
- حساب Pagerank: يستخدم Google MapReduce لحساب Pagerank.
- تحليل السجل: يمكن لـ MapReduce تحليل ملفات السجل. يمكنه تقسيم ملف سجل كبير إلى أجزاء أو تقسيمات مختلفة أثناء بحث مصمم الخرائط عن صفحات الويب التي تم الوصول إليها.
سيتم تغذية زوج المفتاح ذي القيمة إلى جهاز التخفيض إذا تم رصد صفحة ويب في السجل. هنا ، ستكون صفحة الويب هي المفتاح ، والفهرس "1" هو القيمة. بعد إعطاء زوج ذي قيمة رئيسية إلى Reducer ، سيتم تجميع صفحات الويب المختلفة. الناتج النهائي هو العدد الإجمالي للزيارات لكل صفحة ويب.

- الرسم البياني لرابط الويب العكسي: يجد إطار العمل أيضًا الاستخدام في الرسم البياني لرابط الويب العكسي. هنا ، تنتج الخريطة () هدف URL والمصدر وتأخذ المدخلات من المصدر أو صفحة الويب.
بعد ذلك ، يعمل Reduce () على تجميع قائمة كل عنوان URL مصدر مرتبط بعنوان URL الهدف. أخيرًا ، يُخرج المصادر والهدف.
- عد الكلمات: يستخدم MapReduce لحساب عدد المرات التي تظهر فيها كلمة في مستند معين.
- الاحتباس الحراري: يمكن للمنظمات والحكومات والشركات استخدام MapReduce لحل مشكلات الاحتباس الحراري.
على سبيل المثال ، قد ترغب في معرفة ارتفاع مستوى درجة حرارة المحيط بسبب الاحتباس الحراري. لهذا ، يمكنك جمع آلاف البيانات من جميع أنحاء العالم. يمكن أن تكون البيانات ذات درجة حرارة عالية ، ودرجة حرارة منخفضة ، وخط عرض ، وخط طول ، وتاريخ ، ووقت ، وما إلى ذلك ، وسيستغرق ذلك عدة خرائط ويقلل من المهام لحساب الناتج باستخدام MapReduce.
- تجارب الأدوية: تقليديًا ، عمل علماء البيانات وعلماء الرياضيات معًا لصياغة دواء جديد يمكنه محاربة المرض. من خلال نشر الخوارزميات و MapReduce ، يمكن لأقسام تكنولوجيا المعلومات في المؤسسات بسهولة معالجة المشكلات التي لم يتم التعامل معها إلا بواسطة أجهزة الكمبيوتر العملاقة ، دكتوراه. العلماء ، إلخ. الآن ، يمكنك فحص فعالية الدواء لمجموعة من المرضى.
- التطبيقات الأخرى: يمكن لـ MapReduce معالجة البيانات الكبيرة الحجم التي لن تتناسب مع قاعدة البيانات العلائقية. كما أنه يستخدم أدوات علم البيانات ويسمح بتشغيلها عبر مجموعات بيانات مختلفة وموزعة ، والتي كانت ممكنة سابقًا على جهاز كمبيوتر واحد فقط.
نتيجة لمتانة MapReduce وبساطته ، فإنه يجد تطبيقات في الجيش ، والأعمال التجارية ، والعلوم ، وما إلى ذلك.
استنتاج
يمكن أن يثبت MapReduce أنه اختراق في التكنولوجيا. إنها ليست فقط عملية أسرع وأبسط ولكنها أيضًا فعالة من حيث التكلفة وأقل استهلاكا للوقت. نظرًا لمزاياها وزيادة استخدامها ، فمن المحتمل أن تشهد اعتمادًا أعلى عبر الصناعات والمؤسسات.
يمكنك أيضًا استكشاف بعض أفضل الموارد لتعلم البيانات الضخمة و Hadoop.