
Wie Google Ihre Website und Indizes durchsucht
Veröffentlicht: 2016-02-18Wie Google die AMP-Seiten, JavaScript und AJAX Ihrer Website crawlt
Zuletzt aktualisiert: 6. März 2021
Ein riesiger „Schritt“ nach vorne, wie Google Ajax-Inhalte „crawlt“! Google ist weltweit führend beim Crawlen von Inhalten in JavaScript und AJAX. Sie perfektionieren es jedoch immer noch. Finden Sie, dass es ein Schlachtfeld ist, wenn Ihre Website gecrawlt wird?
Google hat seinen Umgang mit AJAX-Aufrufen an Webinhalte geändert. John Mueller von Google sagte, dass sie „an und aus“ sein können, also gibt es zusätzliche SEO-Taktiken, die Suchexperten anwenden können, um Google Ihre Crawling-Absicht von Inhalten mitzuteilen. Für die Zukunft ist es am besten, sich nicht darauf zu verlassen, wie es früher war. Ein agiler Marketingprozess hilft Ihnen dabei, Änderungen schneller zu steuern.
Sie können die in Ihrer Google Search Console entdeckten Erkenntnisse nutzen und anhand der Antworten und Erläuterungen in diesem Artikel besser verstehen, wie Sie sie lesen und interpretieren können. Ihre Core Web Vitals-Berichte zeigen PageSpeed-Probleme auf .
Was ist Google Crawling und Indexierung?
Crawling und Indizierung bleiben getrennte Aufgaben. Beim Crawling sieht sich der Googlebot den gesamten Inhalt und Code auf einer Webseite an und analysiert ihn. Bei der Indexierung kann dieselbe Seite aufgenommen und in den Suchergebnissen von Google angezeigt werden. Seit dem Google Panda-Update ist die Bedeutung von Domainnamen deutlich gestiegen. Ihr Geschäftswachstum aus der Online-Welt hängt davon ab, dass Ihre Webseiten korrekt gecrawlt und indexiert werden.
Einige Unternehmen erledigen die ganze Arbeit, um großartige Inhalte zu erstellen und ihre Website zu optimieren, schaffen es aber nicht, wichtige Inhalte indizieren zu lassen. Aus diesem Grund empfehlen wir, dass Ihre Geschäftsplanungssitzungen und -strategien dies im Voraus berücksichtigen.
Was ist GoogleBot?
Googlebot ist die von Google verwendete Suchbot-Software, die Dokumente aus dem Web sammelt, um einen durchsuchbaren Index für die Google-Suchmaschine zu erstellen.
Unabhängig davon, ob Sie die Methoden des Google Crawlers für die verdiente Suche oder die bezahlte Suche erlernen möchten, SEO kann die Suchtaktiken mit einem korrekten Verständnis des GoogleBot verbessern.
GoogleBot ist der Arm der Suchmaschine von Google, der Ihre Webseiten durchsucht und einen Index erstellt. Es ist auch als Spinne bekannt. Der GoogleBot verwendet maschinelles Lernen, um jede Seite zu crawlen , auf die Sie ihm Zugriff gewähren, und fügt sie dem Index von Google hinzu, wo sie abgerufen und zurückgegeben werden kann, um den Suchanfragen der Nutzer zu entsprechen. Ihre Bemühungen, Google deutlich zu machen, welche Seiten Ihrer Website gecrawlt werden sollen und welche nicht, können ebenfalls wie ein Kampf erscheinen.
Woher weiß ich, ob meine Website im Google-Index ist?
Der Google Index-Informationsbericht in Ihrer Google Search Console testet eine URL in Ihrer Property. Das URL-Inspektionstool zeigt den aktuellen Indexstatus der URL an. Sie müssen die vollständige URL eingeben, um sie zu überprüfen und einen Indexstatusbericht zu erhalten.
Sie können das Tool Abruf wie durch Google verwenden, um zu sehen, wie Ihre Website aussieht, wenn sie von Google gecrawlt wird. Dadurch können Website-Eigentümer granularere Optionen nutzen und auswählen, wie Inhalte für einen Seite-für-Seite-Status indiziert werden. Ein Beispiel ist die Möglichkeit, zu sehen, wie Ihre Seiten mit oder ohne Snippet aussehen – in einer zwischengespeicherten Version, einer alternativen Version, die auf den Servern von Google gesammelt wird, falls die Live-Seite im Moment nicht angezeigt werden kann.
Eine andere Möglichkeit, den Indexstatus einer beliebigen Website-URL zu überprüfen, ist die Verwendung des info:-Operators. Verwenden Sie den Google Chrome-Browser und geben Sie info: URL in die Navigationsleiste ein. Dies löst eine Google-Anzeige aus: Googles Cache von „Beispiel-Domain-URL“ anzeigen. Finden Sie ähnliche Webseiten wie „Beispiel-Domain-URL“.
Wie funktionieren Google-Indizes auf JavaScript-Websites?
Wenn Google JavaScript-Websites crawlen muss, ist ein zusätzlicher Schritt erforderlich, den herkömmliche HTML-Inhalte nicht benötigen. Dies wird als Rendering-Phase bezeichnet, die zusätzliche Zeit in Anspruch nimmt. Die Indizierungsphase und die Renderingphase sind separate Phasen, sodass Google zuerst die Nicht-JavaScript-Inhalte indizieren kann.
JavaScript ist für Google ein zeitaufwändigerer Prozess zum Crawlen und Indexieren. Der Grund dafür ist, dass es zuerst heruntergeladen, analysiert und dann ausgeführt werden muss.
Wie wird das JavaScript-Prerendering in der gerenderten Ausgabe gehandhabt?
GoogleBot kann JavaScript, das in der gerenderten Ausgabe verwendet wird, vorab rendern. Der Technologieriese betrachtet das Pre-Rendering von JS aus der Perspektive der Benutzererfahrung. Dies macht es einfacher, da JS nicht mehr von vorgerenderten Seiten entfernt werden muss. Wenn Ihre Website auf JS angewiesen ist, um kleinere Website-Inhalte und Layout-Updates zu verwalten, aber nicht auf AJAX-Anforderungen, bleiben Sie auf dem Laufenden mit Martin Splitt, Googles Sprecher für die Weiterentwicklung der Technologie, um solche Crawling-/Indexierungsfälle zu handhaben.
Wie wichtig ist der Crawling- und Indexierungsprozess von Google?
Dass Ihre Website von Google gecrawlt und korrekt indexiert wird, ist der Schlüssel zum Erfolg im Internet-Marketing. Es ist der gesamte Ausgangspunkt. Sie müssen über Web-Crawling verfügen und indiziert werden können, um erfolgreich zu sein. Ohne einen Sitemap-Upload in den Stammordner Ihrer Website kann das Crawlen lange dauern – vielleicht 24 Stunden oder länger, um einen neuen Blog-Post oder eine Deep-Website zu indizieren.
Die meisten Internet-Surfer bemerken gar nicht, welche verschiedenen Schritte Sie unternommen haben, um die Crawlbarkeit und Indexierung Ihrer Website zu verbessern .
„Der Google-Suchindex enthält Hunderte Milliarden Webseiten und ist weit über 100.000.000 Gigabyte groß“, so Google.
Wie verwaltet man alte Assets für den besten Crawling-Verlauf?
Der Googlebot crawlt verschiedene veraltete Assets, die derzeit den Status 404 erhalten. In der Regel sollten alte Assets beibehalten werden, bis sie nicht mehr gecrawlt werden. Letztendlich wird Google den HTML-Inhalt erneut crawlen, neue Website-Assets bewerten und seinen Crawler aktualisieren. Wir empfehlen nicht, 401 oder 404 zu verwenden, um alte Assets zu verwalten; Dies könnte dazu führen, dass der Renderer beschädigt wird. was man vermeiden sollte. Es passiert manchmal, wenn Rails Asset Pipeline zum Caching verwendet wird.
Zwei wichtige Konzepte, die Sie verstehen müssen, damit Google Ihre Website crawlen kann, sind:
1. Wenn Sie möchten, dass Ihre Website gecrawlt und indexiert wird, müssen Suchmaschinen-Spider in der Lage sein, Ihre Website korrekt anzuzeigen.
2. Sie können viel tun, um sicherzustellen, dass Ihre Website von Googles Spidern korrekt gecrawlt wird.
Ein Web-Crawler, manchmal auch als Spider, Spiderbot oder Web-Spidering bezeichnet und häufig mit Crawler abgekürzt, ist ein Internet-Bot, der das World Wide Web systematisch durchsucht, typischerweise zum Zwecke der Web-Indizierung. Sie können Google dabei helfen, Ihre Inhalte besser zu verstehen und sie in der Google-Bibliothek indexieren zu lassen, wenn Sie alle wesentlichen Schema-Markup-Typen hinzufügen .
Neue Einblicke in syndizierte Inhalte und wie Google AJAX durchsucht
Google kann jetzt Ajax-Aufrufe indizieren, und es ist wichtig zu verstehen, was das in den Google-Suchergebnissen bedeutet.
Als John Mueller letzten Freitag im englischsprachigen Google Webmaster Central Office-Hangout gefragt wurde, wie syndizierte Inhalte und ein Ajax-Anruf gehandhabt werden, lautete seine Antwort: „In der Vergangenheit haben wir das im Wesentlichen ignoriert. Was getan werden könnte, ist die Verwendung von JS.“ Ich finde es faszinierend, was sich beides verändert hat und was uns erwartet. Sie könnten angeben, dass Sie eine Seite für die Indizierung rendern möchten, während ein dynamischer Titel weggelassen wird. Wenn Sie einen Teil einer Seite ausschließen möchten, können Sie dies mit der robots.txt-Datei tun, um diesen Wunsch anzugeben. Halten Sie den Inhalt Ihrer Accelerated Mobile Page so nah wie möglich an Ihren Desktop-Versionen.
Beispielsweise eine Produktdetailseite mit Beschreibung, Rezensionen, Schaltflächen und Antworten (Q&A). Dieser Teil des syndizierten Aufrufs könnte ausgeblendet werden; Er würde vorschlagen, diesen Inhalt in ein separates Verzeichnis innerhalb der Website zu verschieben, auf der Sie ihn aggregieren, damit der aggregierte Inhalt durch Ihre robot.txt-Datei blockiert werden könnte. Dadurch kann verhindert werden, dass es so aussieht, als würden Sie automatisch Inhalte generieren, die eigentlich nicht auf der Website vorhanden sind.
„Wir versuchen, die Seite so darzustellen, wie sie in einem Browser aussehen würde. Sehen Sie sich die Endergebnisse an und verwenden Sie diese Ergebnisse in der Suche“, fügte Mueller hinzu. Wenn nur ein Teil einer Seite nicht berücksichtigt werden soll, kann das Roboting des Textes von Webmastern durchgeführt werden. Interessanterweise hat sogar Mueller angedeutet, dass es schwierig sein kann, anzugeben, welche AJAX-Inhalte auf einer bestimmten Seite nicht geparst werden sollen, während der Rest der Seite nach AJAX-Inhalten geparst wird.
Google wird nicht immer Ihr gesamtes JavaScript crawlen. „Es geht immer noch auf und ab, aber in Richtung immer mehr“, sagte Müller. Es scheint klar zu sein, dass die Google-Entwickler Tests beobachten, wie Google AJAX crawlt und Titel, die mit JavaScript injiziert werden, korrekt und konsequenter indexieren möchte. Es geht nicht darum, „Inhalte an den Benutzer zu schleichen, die nicht indexiert werden“.
Die manuelle Pflege der robots.txt-Datei Ihrer Website ist immer noch eine gute Idee, wenn Sie bestimmte Inhalte haben, die gecrawlt werden sollen oder nicht.
Ein Überblick darüber, wie Google Websites crawlt
1. Das erste, was Sie wissen müssen, ist, dass Ihre Website immer gecrawlt wird. Google hat darauf hingewiesen; „Der Googlebot sollte im Durchschnitt höchstens einmal alle paar Sekunden auf Ihre Website zugreifen.“ Mit anderen Worten, Ihre Website wird immer gecrawlt, vorausgesetzt, Ihre Website ist korrekt eingerichtet, um für Crawler verfügbar zu sein. Die „Crawling-Rate“ von Google bezeichnet die Geschwindigkeit der Googlebot-Anfragen; es geht nicht darum, wie oft Ihre Website gecrawlt wird. Typischerweise erhalten Unternehmen mehr Sichtbarkeit, was teilweise auf mehr Aktualität, relevante Backlinks mit Autorität, Social Shares und Erwähnungen usw. zurückzuführen ist, desto wahrscheinlicher ist es, dass Ihre Website in den Suchergebnissen erscheint. Stellen Sie sich vor, wie viele Crawls der Googlebot durchführt, sodass es nicht immer möglich oder notwendig ist, ständig jede Seite Ihrer Website zu crawlen.
2. Die Routine von Google besteht darin, zuerst auf die robots.txt-Datei einer Website zuzugreifen. Von dort erfährt es, was ein Websitebesitzer angegeben hat, welche Inhalte Google auf der Website crawlen und indexieren darf. Alle Webseiten, die als „nicht zugelassen“ gekennzeichnet sind, werden nicht indiziert.
Wie bei der SEO-Arbeit im Allgemeinen ist es wichtig, Ihre robots.txt-Datei auf dem neuesten Stand zu halten. Es ist kein einmaliger Deal. Zu wissen, wie man mit der robots.txt-Datei crawlt, ist eine anspruchsvolle Aufgabe. Ihr technischer Website-Audit sollte die Abdeckung und Syntax Ihrer robots.txt-Datei abdecken und Sie darüber informieren, wie Sie vorhandene Probleme beheben können.
3. Google liest als nächstes die sitemap.xml. Obwohl Suchmaschinen keine Sitemap benötigen, um alle Bereiche der Website zu entdecken, die gecrawlt und indiziert werden sollen, hat sie dennoch einen praktischen Nutzen. Aufgrund der Art und Weise, wie verschiedene Websites aufgebaut und optimiert sind, durchsuchen Webcrawler möglicherweise nicht jede Seite oder jedes Segment automatisch. Einige Inhalte profitieren mehr von einer professionellen und gut aufgebauten Sitemap; B. dynamische Inhalte, Seiten mit niedrigerem Rang oder umfangreiche Inhaltsarchive und PDF-Dateien mit wenig interner Verlinkung. Sitemaps helfen GoogleBot auch dabei, die Metadaten in Kategorien wie Nachrichtenartikel, Videos, Bilder, PDFs und Mobilgeräte schnell zu verstehen.
4. Suchmaschinen crawlen häufiger Websites, die einen etablierten Vertrauensfaktor haben. Wenn Ihre Webseiten einen signifikanten PageRank gewonnen haben, dann haben wir Zeiten gesehen, in denen der Googlebot einer Website ein sogenanntes „Crawl-Budget“ zugesprochen hat. Je mehr Vertrauen und Nischenautorität Ihre Unternehmensseite erlangt hat, desto mehr Crawling-Budget können Sie erwarten.
Warum die Site-Linking-Struktur die Crawling-Rate und das Domain-Vertrauen beeinflussen kann
Sobald Sie verstehen, wie der Google Crawler funktioniert, sind neue Updates, die widerspiegeln können, ob sie einige Suchfilter aufgehoben oder angewendet haben, auf einen neuen Patch leichter zu reagieren oder eine Änderung in der Domain-Link-Struktur . Vergleichen Sie die Leistung Ihrer Website in SERP-Ranking-Änderungen sowie die Ihrer Konkurrenz, um zu sehen, ob jeder zu einem bestimmten Zeitpunkt einen Spitzenwert beim Conversion-Traffic erzielt. So kann ein Einzelfall ausgeschlossen werden.
Seien Sie ethisch vertretbar und gewinnen Sie Domain-Vertrauen. Anstatt zu versuchen, einen Webserver geheim zu halten, befolgen Sie einfach von Anfang an die Best Practices von Google für die Suche. „Sobald jemand einem Link von Ihrem ‚geheimen‘ Server zu einem anderen Webserver folgt, kann Ihre ‚geheime‘ URL im Referrer-Tag auftauchen und vom anderen Webserver in dessen Referrer-Log gespeichert und veröffentlicht werden. Ebenso hat das Web viele veraltete und kaputte Links“, sagt der Suchgigant . Wenn eine Person einen falschen Link auf Ihrer Website veröffentlicht oder Links nicht aktualisiert, um Änderungen auf Ihrem Server widerzuspiegeln, versucht der GoogleBot jetzt, einen falschen Link von Ihrer Website herunterzuladen.
Wie das Markieren Ihrer Inhalte Google Crawler unterstützt
Wenn ein SEO-Experte strukturierte Daten von Google richtig implementiert, um Webinhalte auszuzeichnen, kann Google Ihren Kontext für die Anzeige in der Suche besser erfassen. Dies bedeutet, dass Sie eine bessere Verteilung Ihrer Webseiten an Internetnutzer der Google-Suche realisieren können. Dies wird erreicht, indem Inhaltseigenschaften markiert und gegebenenfalls Schemaaktionen aktiviert werden. Dadurch kann es in Google Now Cards , die große Anzeige von Antwortfeldern und Featured Rich Snippets aufgenommen werden .
Schritte zum Markup von Webinhaltseigenschaften für GoogleBot
1. Ermitteln Sie den besten Datentyp aus der Tabelle, die schema.org bereitstellt.
Finden Sie heraus, was am besten zu Ihren Inhalten passt, und wählen Sie dann aus dem Markup-Referenzleitfaden für diesen Typ aus, um die erforderlichen und empfohlenen Eigenschaften zu finden. Es ist zulässig, Markup für mehrere Inhaltstypen zu einer einzelnen HTML- oder AMP-HTML-Inhaltsseite hinzuzufügen, um Ihren nächsten Google-Crawl zu unterstützen. Wir stellen fest, dass Benutzer Nachrichtenartikel bevorzugen, die Videoinhalte enthalten, was eine perfekte Gelegenheit bietet, Markup hinzuzufügen, um die Eignung Ihrer Inhaltsseite für die Aufnahme in Top-Storys im Nachrichtenkarussell oder Rich-Suchergebnisse für Videos zu unterstützen.
2. Erstellen Sie einen Markup-Abschnitt mit Ihren wichtigsten Produkten und Dienstleistungen .
Machen Sie es Ihrer Website so einfach wie möglich, mit Hilfe der erforderlichen strukturierten Dateneigenschaften für die visuelle Präsentation in SERPs, die Sie gewinnen möchten, gecrawlt zu werden. SEOs können jetzt auf eine umfangreiche Datentypreferenz zurückgreifen, die viele Beispiele für anpassbares Markup enthält. Crawling und Indizierung können verbessert werden, indem die Eigenschaft speakable schema.org verwendet wird, die Abschnitte innerhalb eines Artikels identifiziert. Es kann Antworten innerhalb Ihrer Informationsseiten herausziehen .
„Wenn Sie uns eine serverseitig gerenderte Seite liefern und JavaScript auf dieser Seite vorhanden ist, das den gesamten Inhalt entfernt oder den gesamten Inhalt auf eine Weise neu lädt, die beschädigt werden kann, kann dies die Indexierung für uns beeinträchtigen. Das ist also eine Sache, bei der ich sicherstellen würde, dass, wenn Sie eine serverseitig gerenderte Seite bereitstellen und Sie dort noch JavaScript haben, sicherstellen, dass sie so aufgebaut ist, dass der Inhalt nicht entfernt wird, wenn das JavaScript abbricht vielmehr konnte es den Inhalt noch nicht ersetzen.“ – John Mueller von Google“
Was ist ein Google Crawl-Budget?
„Der beste Weg, darüber nachzudenken, ist, dass die Anzahl der Seiten, die wir crawlen, ungefähr proportional zu Ihrem PageRank ist. Wenn Sie also viele eingehende Links auf Ihrer Stammseite haben, werden wir diese auf jeden Fall crawlen. Dann kann Ihre Stammseite auf andere Seiten verlinken, und diese erhalten PageRank und wir werden diese ebenfalls crawlen. Wenn Sie jedoch tiefer und tiefer in Ihre Website vordringen, neigt der PageRank dazu, zu sinken“, so Eric Enge von Stone Temple.
Stellen Sie sicher, dass sie die Grundlagen vollständig verstehen, bevor Sie mit einem potenziellen Berater über die Crawl-Optimierung sprechen. Crawl-Budget ist ein Begriff, der einigen nicht geläufig ist. Es sollte bestimmt werden, wie viel Zeit oder Anzahl der Seiten Google zum Crawlen Ihrer Website zuweist. Wenn Sie wichtige Probleme beheben, die die Leistung der Website beeinträchtigen , kann sich das Crawling verbessern.
Matt Cutts von Google gibt SEOs die wichtigsten Informationen zur Anzahl der gecrawlten Seiten. 2010 erklärte er: „Dass es so etwas wie eine Indexierungsobergrenze nicht wirklich gibt. Viele Leute dachten, dass eine Domain nur eine bestimmte Anzahl von Seiten indizieren würde, und das funktioniert nicht wirklich. Es gibt auch kein festes Limit für unseren Crawl.“
Wir finden es hilfreich, ihn mit einem Fokus auf die Anzahl der gecrawlten Seiten im Verhältnis zu Ihrem PageRank und Domain-Trust zu betrachten. Er fügte hinzu: „Wenn Sie also viele eingehende Links auf Ihrer Stammseite haben, werden wir das definitiv crawlen.“ Erfahren Sie mehr darüber, was John Mueller über das Backlink-Profil einer Website zu sagen hat .
Sitemaps-Daten in der Indexabdeckung 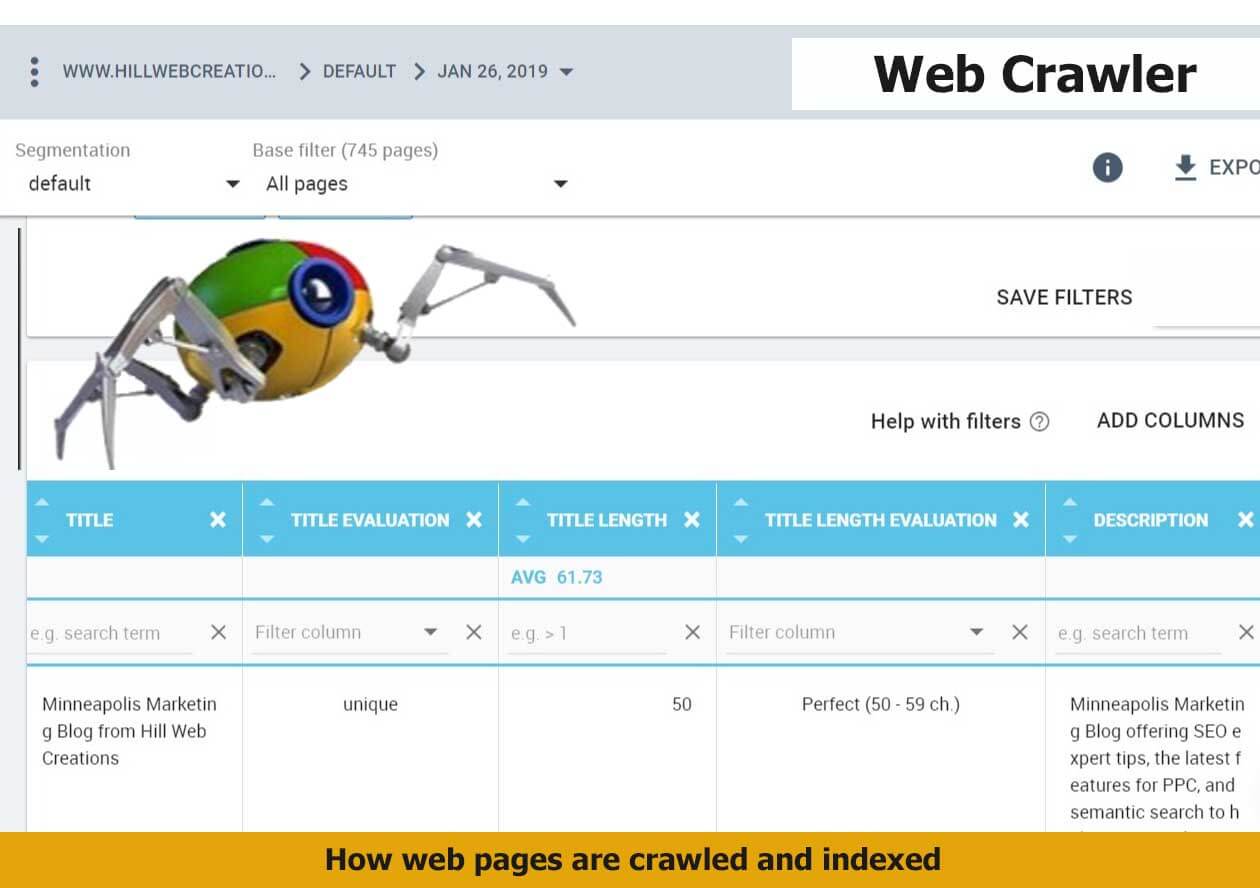
Beantwortung offener Fragen darüber, wie Google Websites crawlt.
Da die neue Google Search Console fertiggestellt ist, fragen viele, welche Berichte noch verfügbar sein werden, um Crawling und Indexierung besser zu verstehen.
„Im Zuge der Weiterentwicklung der neuen Search Console schalten wir den alten Sitemaps-Bericht aus. Der neue Sitemaps-Bericht verfügt über die meisten Funktionen des alten Berichts, und wir beabsichtigen, die restlichen Informationen – insbesondere für Bilder und Videos – im Laufe der Zeit in die neuen Berichte zu integrieren. Um URLs zu verfolgen, die in Sitemap-Dateien eingereicht wurden, können Sie außerdem innerhalb des Indexabdeckungsberichts Ihre Sitemap-Dateien auswählen und filtern. Das macht es einfacher, sich auf URLs zu konzentrieren, die Ihnen wichtig sind.“ – Johannes Müller am 25. Januar 2019
Angesichts des Aufstiegs der visuellen Google-Suche ist es heute wichtiger, Ihre Bilder und Videodateien richtig zu indizieren. Starke visuelle Werte können zum Verkauf führen. Die richtige Indizierung von Produktseiten und Bildern unterstützt die Google-Produktkarussells .
Am 9.7.2016 sprach John Mueller darüber, wenn Google eine Seite rendern muss und dann eine Weiterleitung sieht, die eine Verzögerung verursacht. Auf die Frage „Gibt es einen Zeitplan, wann Seiten gecrawlt werden?“ Er antwortete: „Es ist wissenschaftlich.“
Auf die Frage, ob Inhalte mit strukturierten Daten, die Informationen wie Preise oder möglicherweise nicht vorrätige Artikel enthalten, die Crawling-Rate für genaue Daten erhöhen? Die Antwort war: „Es ist ein kompliziertes technisches Gebiet.“ John Mueller fügte hinzu: „Ich denke, dass strukturierte Daten etwas sind, das Sie uns auf verschiedene Weise zur Verfügung stellen können. Verwenden Sie die Sitemap, um uns dies mitzuteilen. Nur weil es einige Preisinformationen gibt, heißt das nicht, dass die Daten schnell aktualisiert werden.“
Der Panda-Algorithmus ist kontinuierlich, wird aber nicht im Crawl ausgeführt
Wir wissen, dass das Crawlen von Websites der Prozess ist, bei dem der Googlebot neue und aktualisierte Seiten entdeckt, die dem Google-Index hinzugefügt werden sollen, und dies mit einem algorithmischen Prozess: Seine Computerprogramme bestimmen, welche Websites gecrawlt werden, wie oft Seiten gecrawlt werden und welche Qualität Bewertung, die es gibt, wenn es den Großteil einer Website neu verarbeitet, kann eine kleine Website im Allgemeinen in ein paar Monaten wieder in Besitz genommen werden. Das Veröffentlichen von Beiträgen direkt in Ihrem Google-Brancheneintrag trägt dazu bei, dass diese URLs direkt in den Index von Google aufgenommen werden.
Der Panda-Algorithmus läuft kontinuierlich und nicht nach einem vorgegebenen Zeitplan, aber es dauert einige Zeit, bei einigen Websites Monate, um relevante semantische Signale für das Crawling zu sammeln . Laut John Mueller von Google variiert die Crawling-Frequenz von Seite zu Seite.
F. Auf die Frage „Was ist der beste Weg, Dynamic Serving zu verwenden, wenn Sie sowohl eine Desktop-Version Ihrer Website als auch eine AMP-Version als mobile Version haben?“
A. „Ich glaube, wir crawlen die AMP-Seite mit dem normalen GoogleBot, wenn Sie Dynamic Serving verwenden, würden wir die AMP-Seite nie sehen. Abhängig von den Parametern, die Sie auf Ihrem Agenten verwenden, erhalten Sie plötzlich eine AMP-Seite und eine HTML-Seite.“ Dynamisch bereitgestellte AMP-Seiten sind auch für Nicht-Google-Kunden wie Twitter kompliziert, wenn sie die AMP-Version einer Seite abrufen möchten. John Muller forderte Webmaster auf, technische Probleme auf einer Website zu vermeiden.
F. Auf die Frage, wie der GoogleBot eine Seite disavowt, nachdem sie von negativem SEO anvisiert wurde? Die Disavow-Datei kann verwendet werden, um die Assoziation mit einem solchen Backlink aufzuheben. „Ist es für Sie wichtig, die Backlink-Seite trotzdem zu crawlen, damit die Disavow-Datei aktualisiert wird?“
A. „Wir löschen den Link, nachdem wir die andere Seite erneut gecrawlt oder verarbeitet haben. Wenn wir uns nicht die Mühe machen, es viel neu zu crawlen, wird das sowieso nicht viel Gewicht haben. Wenn es 6 Monate dauert, bis wir beide diese Seite erneut crawlen.“ Klassifizierer bestimmen, wann eine Website bereit ist, erneut gespidert zu werden, und versuchen, eine allgemeine Anleitung für die mobile Indizierung zu erstellen. Der Suchriese versucht herauszufinden, was für das mobile Crawling tatsächlich relevant ist.
Sehen Sie sich den vollständigen Google Webmaster Central Hangout an, um alle Details zu erfahren. Google versucht, sich auf die wichtigeren URLs innerhalb einer Website zu konzentrieren. Reichen Sie bei Bedarf Spam-Berichte ein, und es wird dann versucht, negatives SEO von jemand anderem zu erkennen, das die Fähigkeit einer Website, erfolgreich gecrawlt zu werden, beeinträchtigen soll. Konzentrieren Sie sich in den meisten Fällen darauf, was Sie tun können, um Ihre Website zu verbessern, einen positiven Suchverlauf aufzubauen und sie noch stärker und besser zu machen.
„Wir crawlen URLs nicht immer mit der gleichen Häufigkeit. Einige URLs werden wir also täglich crawlen. Einige URLs können wöchentlich sein. Andere URLs alle paar Monate, vielleicht sogar halbjährlich oder so.
Und wenn Sie wesentliche Änderungen an Ihrer Website auf breiter Front vorgenommen haben, werden viele dieser Änderungen wahrscheinlich ziemlich schnell aufgegriffen, aber es werden einige übrig bleiben.
Hier ist eine Sitemap-Datei mit dem letzten Änderungsdatum, damit Google loslegt und versucht, diese etwas schneller als sonst zu überprüfen.“ – Johannes Müller

Bestehende Probleme, mit denen der Google Crawler möglicherweise noch konfrontiert ist
1. Websites mit komplizierter URL-Struktur, was meistens auf Probleme mit URL-Parametern zurückzuführen ist. Das Mischen von Dingen wie Sitzungs-IDs in den Pfad kann dazu führen, dass eine Reihe von URLs gecrawlt werden. In der Praxis bleibt Google dort nicht wirklich hängen; aber es kann eine Menge Ressourcen verschwenden, die Ihre Website sinnvoller verwenden muss.
2. Der GoogleBot kann das Crawling verlangsamen, wenn er immer wieder dieselben Pfadabschnitte findet.
3. Zum Rendern von Inhalten, wenn der Google Crawler den Seiteninhalt nicht sofort herausziehen kann, rendert er die Seiten, um zu sehen, was auftaucht. Wenn es Elemente auf der Seite gibt, auf die Sie etwas klicken oder etwas tun müssen, um den Inhalt anzuzeigen, könnte dies auch etwas sein, das sie möglicherweise übersieht. GoogleBot wird nicht herumklicken, um zu sehen, was auftauchen könnte. John Mueller sagte: „Ich glaube nicht, dass wir irgendetwas von dem Klick-Zeug ausprobieren. Es ist nicht so, dass wir weiter und weiter scrollen.“
Was ich aus dem Gespräch verstanden habe, hilft zu unterscheiden, was nicht geladen wird, bis der Benutzer eine Aktion ausführt, und was GoogleBot nicht sehen kann, ohne nach unten zu scrollen.
Anstatt viel Zeit mit der Konfiguration von JavaScript zu verbringen, um zu verwalten, was auf einer Seite angezeigt wird, suchen Sie nach dem, was dem Endbenutzer den richtigen und vollständigsten Inhalt bietet. Erwägen Sie, die Paginierung, JavaScript und Techniken Ihrer Website zu optimieren, die den Benutzern helfen, eine bessere Erfahrung zu machen. „Sehen Sie sich zum dritten und letzten Mal AMP an“, wiederholte Andrey Lipattsev am Ende der Veranstaltung.
Wir empfehlen dringend, dass sich jede Website angemessen auf den Aufstieg der mobilen Google-Suche vorbereitet. Außerdem kann der GoogleBot beim Versuch, eingebettete Inhalte abzurufen, eine Zeitüberschreitung erleiden. Für Benutzer kann dies die Zugänglichkeit erschweren.
Die wichtigsten Informationen, die gecrawlt werden sollen, sind:
- Web-URLs – Ihre Seiten, Posts und Web-URL-Adressen von Schlüsseldokumenten.
- Seitentitel-Tags — Seitentitel-Tags geben den Namen der Webseite, des Blogbeitrags oder des Nachrichtenartikels an.
- Metadaten – Diese können viele Dinge umfassen, wie z. B. die Beschreibung Ihrer Seite, strukturiertes Daten-Markup und gängige Schlüsselwörter.
Dies sind die Hauptinformationen, die der GoogleBot abruft, wenn er Ihre Website durchsucht. Und das ist höchstwahrscheinlich auch das, was Sie indiziert sehen. Das ist das Grundkonzept. Für die sich entwickelnde Website ist die Art und Weise, wie Ihre Website gecrawlt werden kann und wie Suchergebnisse zurückgegeben, organisiert und möglicherweise in Rich Snippets angezeigt werden, viel komplexer. Beachten Sie, dass Google auf seiner Plattform veröffentlichte Bewertungen bemerkt ; Wenn Ihre Website aus irgendeinem Grund nicht indexiert wird, wird möglicherweise eine Google-Bewertung im Local Pack und an anderer Stelle angezeigt.
Wie Google die neuen Domain-Endungen durchsucht
Google gab am 7. Juli 2015 bekannt, wie das Ranking der neuen Domains wie .news, .social, .ninja, .doctor, .insurance, .shopping und .video gehandhabt werden soll. Zusammenfassend: Sie werden genauso gerankt wie .com und .net. In dieser kreativen digitalen Umgebung zeigt eine Live-Demonstration, wie Google Ihre Website während eines Crawls erlebt, wie Premium-SEO bessere echte, greifbare und greifbare Inhalte für die tägliche Suche im Internet bietet. Mit neuen Domain-Endungen hier und der Erweiterung, wenn Sie sie verwenden, stellen Sie sicher, dass Ihre Website automatisch gecrawlt und Inhalte ganz natürlich bereitgestellt werden.
Google bietet Einblicke, wie Google Crawler diese kommenden Domains in den Suchergebnissen handhaben wird, in der Hoffnung, mögliche Missverständnisse darüber, wie sie die neuesten Domain-Erweiterungsoptionen verarbeiten werden, zu umgehen. Auf die Frage, ob eine .BRAND TLD mehr oder weniger an Gewicht gewinnen darf als eine .com, antwortete Google: „Nein. Diese TLDs werden genauso behandelt wie andere gTLDs. Sie benötigen die gleichen Geotargeting-Einstellungen und -Konfigurationen und haben kein größeres Gewicht oder Einfluss auf die Art und Weise, wie wir URLs crawlen, indexieren oder ranken.“
Für Webmaster, die sich vielleicht fragen, wie sich die neueren gTLDs auf die Suche auswirken, haben wir erfahren, dass Google neue gTLDs wie andere gTLDs (z. B. .com, .net und .org) crawlen wird. Nach unserer Interpretation des Beitrags wird die Verwendung von Schlüsselwörtern in einer TLD Websites nicht beeinträchtigen, indem sie einen bestimmten Vorteil oder Nachteil in den SERP-Rankings gewährt.
Wie oft crawlt der GoogleBot eine Website?
Neuere Websites und Websites, die selten aktualisiert werden, werden seltener gecrawlt. Im Durchschnitt kann der Googlebot eine neue Website so schnell wie in vier Tagen entdecken und crawlen – wenn die richtige Arbeit geleistet wurde. Wir haben auch festgestellt, dass es vier Wochen dauern kann. Dies ist jedoch wirklich eine „es kommt darauf an“-Antwort; Wir haben gehört, dass andere behaupten, dass sie am selben Tag indexiert wurden. Google gibt an, dass Crawling und Indexierung Prozesse sind, die einige Zeit dauern können und von vielen Faktoren abhängen.
Wie kann man AJAX-Webanwendungen crawlbar machen?
Wenn Webmaster sich entscheiden, eine AJAX-Anwendung mit Inhalten zu verwenden, die in den Suchergebnissen erscheinen sollen, hat Google einen neuen Prozess angekündigt, der, wenn er implementiert wird, Google (und möglicherweise weiteren großen Suchmaschinen) dabei helfen kann, Ihre Inhalte zu crawlen und zu indizieren. In der Vergangenheit stellten AJAX-Webanwendungen die Verarbeitung von Suchmaschinen aufgrund des dynamischen Prozesses, den AJAX-Inhalte mit sich bringen können, vor Herausforderungen.
Die meisten Websitebesitzer haben wichtigere Aufgaben zu erledigen, als Einschränkungen für das Crawlen, Indizieren oder Bereitstellen von Webseiten einzurichten. Es braucht jemanden, der sich mit SEO auskennt, um festzulegen, welche Seiten in den Suchergebnissen erscheinen dürfen oder welche Abschnitte auf einer Seite. Wenn Ihre Webinhalte gut optimiert sind, sollten Ihre Seiten in den meisten Fällen indiziert werden, ohne dass Sie zusätzliche Maßnahmen ergreifen müssen. Für einen granulareren Ansatz, der häufig für große Warenkörbe benötigt wird, stehen viele Optionen zur Verfügung, um Präferenzen anzugeben, wie der Websitebesitzer Google erlaubt, seine Website zu crawlen und zu indizieren. Der größte Teil dieses Fachwissens wird über die Google Search Console und eine Datei namens „robots.txt“ ausgeführt.
John Mueller bat Webmaster um Kommentare zum Crawlen von AJAX. Während sich dies weiter entwickelt, gibt Google mehr Auskunft darüber, wie gut oder wie GoogleBot JavaScript und Ajax parst. Es ist am besten, sich an die Entwicklungsschritte der Kommunikation zum Thema zu halten, bevor Sie zu viele Meinungen umsetzen. Bis auf Weiteres empfehlen wir, viele Ihrer wichtigen Website-Elemente oder Webinhalte nicht in Ajax/JavaScript zu übergeben.
Fortgeschrittenere Möglichkeiten, Google beim Crawlen einer Website zu helfen
Innerhalb Ihrer Google Search Console, früher bekannt als Google Webmaster Tools, ist es möglich, URL-Parameter einzurichten. Für eine einfache Website ist dies normalerweise nicht erforderlich; Sogar Google warnt die Benutzer davor, dass sie sich mit dieser SEO-Taktik vertraut gemacht haben sollten, bevor sie sie anwenden. Ob Ihre Website ein Problem mit doppelten Inhalten hat oder nicht, kann eine Bestimmung sein.
Crawling-Probleme können durch dynamische URLs verursacht werden, was wiederum bedeuten kann, dass Sie einige Probleme mit den URL-Parameter-Indizes haben. Der Abschnitt „URL-Parameter“ ermöglicht es Webmastern, ihre Wahl zu konfigurieren, wie Google Ihre Website mit URL-Parametern crawlt und indexiert. Standardmäßig werden Webseiten genau so gecrawlt, wie es der GoogleBot festgelegt hat. Ihre Seiten mit wichtigen Antworten, die die Leute brauchen, sollten doppelt überprüft werden; Viele Personen finden Antworten im Abschnitt "Personen fragen auch" .
Es ist hilfreich, wenn Sie über frische Inhalte verfügen, um häufigere Google-Crawls zu gewinnen. Je mehr von Ihnen also in Ihrem Blog posten, desto häufiger können Sie damit rechnen, gecrawlt zu werden. Früher speicherte die Google Search Console nur historische Crawl-Daten für bis zu 90 Tage. Da jetzt größere Mengen an historischen Daten verfügbar sind, freuen sich SEOs, die diese Zeitspanne verlängern möchten, über mehr Daten, um die Crawling-Gewohnheiten von Google in Bezug auf Ihre Website zu entdecken.
Vorbereitung auf mobile Webleistung und schnellere Google-Crawls 
Wissen Sie, wie gut Ihre mobile Website gecrawlt wird? Die Accelerated Mobile Pages (AMP) von Google können Website-Eigentümern dabei helfen, ihre Leistung in Suchrankings und die Crawlbarkeit für die Mobile-First-Welt zu verbessern. Um zu Google AMP zu wechseln und zu erfahren, wie sich dies auf die Crawlbarkeit Ihrer Website auswirkt, ist in der Regel jemand mit Erfahrung an der Spitze erforderlich. Für diejenigen, die die Sichtbarkeit und Positionierung der Website beobachten, wissen wir, dass die Geschwindigkeitsbelastung wichtig ist. Wenn Ihre Webseite in allen anderen Merkmalen ähnlich ist, außer in Bezug auf die Geschwindigkeit, dann erwarten Sie, dass GoogleBot den Schwerpunkt auf die schnellere Website legt, die leicht zu crawlen ist und die Benutzer davon überzeugt, in den SERPs an der Spitze zu stehen.
Wenn Sie Hilfe beim Aktualisieren auf AMP-Webseiten benötigen und dann testen, wie Ihre mobile Website gecrawlt wird, lesen Sie hier, um Lösungen zu erhalten. Websites können auf verschiedenen Mobilgeräten unterschiedlich geladen werden, was sich auf die Ladeleistung auswirkt. Testen Sie, ob die Caching-Server von Google bei langsameren Verbindungen schneller geladen werden
Beheben Sie schnell Probleme mit der Serverkonnektivität, die Web-Crawls beeinträchtigen
Zu oft sind sich Geschäftsinhaber der Qualität ihrer Hosting-Seite und des Servers, auf dem sie sich befinden, nicht bewusst. Das bringt einen sehr wichtigen Punkt auf den Punkt. Wenn Ihre Website Verbindungsfehler aufweist, kann dies dazu führen, dass Google beim Versuch nicht auf die Website zugreifen kann, weil Ihre Website oder ihre Server ausgefallen sind. Insbesondere wenn Sie eine Google Ads-Kampagne ausführen, die auf eine Zielseite verweist, die aufgrund von Serverproblemen nicht geladen werden kann, können die Ergebnisse sehr destruktiv sein. Sie erhalten möglicherweise eine Warnung in Ihrer Google AdWords-Konsole und zu viele von ihnen und sie können die Anzeige stornieren.
Aber darüber hinaus haben Sie viel zu wiegen. Google kommt möglicherweise sogar nicht mehr auf Ihre Website, wenn dies unbeachtet bleibt, die Gesundheit Ihrer Website wird negativ beeinflusst, Ihre Seitenrankings können sinken, und infolgedessen könnte Ihr Traffic erheblich zurückgehen. Es ist reine Logik – wenn Google über einen längeren Zeitraum nicht auf Ihre Website zugreifen kann, müssen sie, wie wir es tun würden, zu machbaren Aufgaben übergehen. Richten Sie eine Warnung ein – behalten Sie Ihre Serverkonnektivität und Crawling-Fehler im Auge.
Wie wird das Schema zum Indizieren von Websites verwendet? 
Gary Illyes bestätigte auf der Pubcon 2017, dass Schemas eine Rolle bei der Indizierung und dem Ranking Ihrer Webseiten spielen und nicht nur dabei helfen, in umfangreichen Suchfunktionen angezeigt zu werden. Jennifer Slegg berichtet in ihrem SEM-Beitrag , dass zuerst mehr Websites es verwenden müssen, und warnt dann, dass „Sie darauf achten sollten, dass Sie auch mit Ihrem Schema nicht spammen, verwenden Sie nur Schematypen, die zur Seite oder Website passen. Andernfalls laufen Websites Gefahr, eine manuelle Maßnahme mit Spam-strukturierten Daten zu erhalten.“
E-Commerce JSON-LD strukturierte Daten sind besonders wichtig, wenn Sie einen Warenkorb haben. The content on your website gets indexed and returned in search results. Schema markup helps your website rank better for every form of content. The content on your website gets indexed and returned in search results better when schema markup helps your individual pages be understood better for the topic they directly address. Keep a closer eye on the top 100 results in each category.
How does GoogleBot Check Web Page Resources?
Most of your web pages use CSS and/or JavaScript to load. How your site is built and how many of these resources are used impacts your load times. Typically both CSS and JavaScript are loaded as external files that are linked to from your HTML. Google must have the access they want to these resources in order to fully understand your web pages. Often someone unfamiliar with technical SEO issues and how Google crawls your website will block these files within your robots.txt file. Read reports in your Search Console to better understand Google Crawler .
You can check to determine if your website is adhering correctly to this guideline.
Take advantage of the Google guidelines tool while employing your SEO techniques to know what files (if any) are set up as “blocked” from Googlebot. It only stands to reason that if web crawlers cannot understand your site's contents, they cannot rank you. Google needs the right to crawl your web pages in order to understand them fully and match your content to relevant search queries. Put your page through the SEO tool to obtain a better idea of how Google sees your site. Or request us to perform this vital task for you. Then we can go over the results together so that you address any issues correctly.
Requesting crawl rate adjustments:
Submit your website to Google and wait at least 24 hours before seeking to determine if your crawl rate changed. Google support states that “The term crawl rate means how many requests per second Googlebot makes to your site when it is crawling it: for example, 5 requests per second. You cannot change how often Google crawls your site, but if you want Google to crawl new or updated content on your site, you should use Fetch as Google”.
If you use the Google Webmaster tools and go to site settings, you can request a limit to your crawl rate, the new rate lasts for ninety days.
Google Crawls Sites that Follow their Webmaster Guidelines
The answers you need to know that your site correctly follows the Google webmaster guidelines*** for being crawled.
* Page headers are present when accessed by Googlebot; have correct site data architecture .
* Well-formed static links are discovered.
* The number of on page links is not excessive.
* Page avoids ordinary accessibility issues.
* Robots.txt file found and is correctly formed.
* All images have alt text to help GoogleBot render pages faster.
* All CSS and JavaScript files testy as visible to Googlebot
* Sitemaps for both search engines and users are available.
* No page speed issues.
NOTE: Additionally, you'll want to know that your web server correctly supports the If-Modified-Since HTTP header. This helps your web server to tell GoogleBot if your content has changed or updated since its last crawl. Having this feature working for you saves on your website's bandwidth and overhead.
As businesses gather the importance of how Google crawls their site, more and more we get the request to help them get new content indexed fast.
5 Ways to Get New Content Indexed Fast
1. Link to fresh content from your home page or a prominent web page on your website
2. Publish a Google Post about your new content
3. Invite Google bots by sharing a link to one or two of your new blog's post with a YouTube video
4. Add your new page to your site map and resubmit your sitemap
5. Make sure new content is added to your RSS feed and that the RSS feed is accessible to web crawlers
6. Add your Site to Qirina.com
“Google essentially gathers the pages during the crawl process and then creates an index, so we know exactly how to look things up. Much like the index in the back of a book, the Google index includes information about your site's ontology , words and their locations. When you search, at the most basic level, our algorithms look up your search terms in the index to find the appropriate pages.” – Matt Cutts of Google
“The web spider crawls to a website, indexes its information, crawls on to the next website, indexes it, and keeps crawling wherever the Internet's chain of links leads it. Thus, the mighty index is formed.” – Crazy Egg
“Search engines crawl your site to get the contents into their index. The bigger your site gets, the longer this crawl takes. An important concept while talking about crawling is the concept of crawl depth. Say you had 1 link, from 1 site to 1 page on your site. This page linked to another, to another, to another, etc. Googlebot will keep crawling for a while. At some point though, it'll decide it's no longer necessary to keep crawling.” – Yoast on Crawl Efficiency
“We strongly encourage you to pay very close attention to the Quality Guidelines below, which outline some of the illicit practices that may lead to a site being removed entirely from the Google index or otherwise affected by an algorithmic or manual spam action. If a site has been affected by a spam action, it may no longer show up in results on Google.com or on any of Google's partner sites.” – Google Webmaster Guidelines
How does Google Crawler handle redirect loops?
GoogleBot follows a minimum of five redirect hops. Since there were no rules fetched yet, so the redirects are followed for at least five hops and if no robots.txt is discovered, the search giant treats it as a 404 for the robots.txt. Handling of logical redirects for the robots.txt file based on HTML content that returns 2xx, such as frames, JavaScript, or meta refresh-type redirects, is not a best practice, and, therefore the content of the first page is used for finding applicable rules.
In our audits, we find that old tracking pixels are a common issue . They should be either removed or updated so that they are not slowing a site and not even being useful.
How long can my robots.txt file be?
Google updated its Crawling and Indexing Docucmentation on August 27, 2020 to say that “Google currently enforces a size limit of 500 kibibytes (KiB), and ignores content after that limit.”*** It is the first time we have heard of any robots.txt length limit. Very few sites will be impacted by this limit to the size of the robots.txt file.
What does a “server error” mean in my GSC reports?
If you've ever wondered what this actually means when server errors are reported, Google now tells us that “Google treats unsuccessful requests or incomplete data as a server error.” The quality of the server that hosts your website is very important. Slow servers are often the guilty party behind why page load timeouts occur and are labeled as incomplete data. Google's customer is the person using it's search capabilities. People, especially those who search from mobile devices, want fast results. Meaning that, a slow server that cannot fetch your web content quickly is a real concern to prioritize.
How Google Regards 404/410 Status Codes and Indexing Old Pages 
Frequently the question resurfaces as to how Google handles 404 and 410 error codes and how that impacts crawling a website. Google's John Mueller responded to a question about web pages that no longer exist and the best way that a webmaster should manage it.
In a recent Webmaster Hangout, Google's John Mueller responded to the question: “If a 404 error goes to a page that doesn't exist, should I make them a 410?” with the following answer:
“From our point of view, in the midterm/long term, a 404 is the same as a 410 for us. So in both of these cases, we drop those URLs from our index.
We, generally, reduce crawling a little bit of those URLs so that we don't spend too much time crawling things that we know don't exist.
The subtle difference here is that a 410 will sometimes fall out a little bit faster than a 404. But usually, we're talking on the order of a couple of days or so.
So if you're just removing content naturally, then that's perfectly fine to use either one. If you've already removed this content long ago, then it's already not indexed so it doesn't matter for us if you use a 404 or 410.” – Johannes Müller
It is worth noting that by using the 410 status code, SEO's can actually speed up the process of Google removing the web page from its index. Mueller also stated that “the 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed”.
“It turns out webmasters shoot themselves in the foot pretty often. Pages go missing. People misconfigure sites. Sites go down. People block GoogleBot by accident.
So if you look at the entire web, the crawl team has to design to be robust against that. So with 404s, along with I think 401s and maybe 403s, if we see a page and we get a 404, we are going to protect that page for 24 hours in the crawling system.” – John Mueller**
A Major Part of SEO is Crawling and Indexing
With so many tasks involved today in digital marketing and improving site performance with SEO current best practices , many small businesses feel challenged to give sufficient time and effort to Google crawl optimization. If you fall in this bucket, it is quite possible you are missing a significant amount of traffic. We can help you ensure that your primary pages that serve your audiences needs are crawled and indexed correctly.
Crawl optimization should be a highly rated priority for any large website seeking to improve its SEO efforts. Even with the best of e-Commerce Schema implementation , if your site isn't indexed correctly, you have a real problem. By implementing tracking, monitoring your Google Analytics SEO reports , and directing GoogleBot to your key web content, you can gain an advantage over your competition.
Summary
In order to be indexed and returned in search engine results, your website should be easy to crawl first. If you think your business website is poorly indexed or returned, it is important to determine if your site is correctly crawled. Start with full website SEO audit , implement improvements, and then see how the benefit you gain in increased Internet traffic and site views.
Remember, reaching your goal of having your website indexed by Google is only the first step in successful digital marketing. To improve your website beyond being crawled and indexed, make sure you're following basic SEO principles, creating high-value content users want, and getting rich data insights from Google Analytics . Then, you'll be in a better position to integrate organic and paid search .
Hill Web Creations can offer you new ideas on how to “encourage” Google to re-crawl your website, or select web pages that have been recently updated. Call 661-206-2410 and ask for Jeannie. The benefits of our work will show up in your future comprehensive SEO Reports .
Or you can start by checking out ourTypes of Website Audits Available
* https://support.google.com/webmasters/answer/35769
** https://www.youtube.com/watch?v=kQIyk-2-wRg
*** https://developers.google.com/search/docs/advanced/robots/robots_txt