
Come Google esegue la scansione del tuo sito Web e indicizza
Pubblicato: 2016-02-18Come Google esegue la scansione delle pagine AMP, JavaScript e AJAX del tuo sito web
Ultimo aggiornamento: 6 marzo 2021
Un enorme "passo" in avanti nel modo in cui Google "scansiona" i contenuti Ajax! Google è il migliore al mondo nella scansione dei contenuti all'interno di JavaScript e AJAX. Tuttavia, lo stanno ancora perfezionando. Trovi che sia un campo di battaglia per la scansione del tuo sito?
Google ha cambiato il suo modo di gestire le chiamate AJAX ai contenuti web. John Mueller di Google ha affermato che possono essere "on e off", quindi ci sono tattiche SEO aggiuntive che gli esperti di ricerca possono utilizzare per far conoscere a Google l'intento di scansione dei contenuti. Andando avanti, è meglio non fare affidamento su come era una volta. Avere un processo di marketing agile in atto ti aiuterà a navigare i cambiamenti più velocemente.
Puoi sfruttare gli approfondimenti scoperti nella tua Google Search Console e sapere meglio come leggerli e interpretarli dalle risposte e dalle spiegazioni in questo articolo. I tuoi rapporti Core Web Vitals rivelano problemi con PageSpeed .
Che cos'è la scansione e l'indicizzazione di Google?
La scansione e l'indicizzazione rimangono attività distinte. La scansione è quando Googlebot esamina tutto il contenuto e il codice di una pagina Web e lo analizza. L'indicizzazione è quando quella stessa pagina può essere inclusa e mostrata nei risultati di ricerca di Google. Dall'aggiornamento di Google Panda, l'importanza del nome di dominio è aumentata in modo significativo. La crescita della tua attività dal mondo online dipende dalla scansione e dall'indicizzazione delle tue pagine web correttamente.
Alcune aziende fanno tutto il lavoro per creare ottimi contenuti e ottimizzare il proprio sito, ma non riescono a ottenere l'indicizzazione dei contenuti chiave. Ecco perché consigliamo che le sessioni e la strategia di pianificazione aziendale considerino questo in anticipo.
Cos'è GoogleBot?
Googlebot è il software del bot di ricerca utilizzato da Google, che raccoglie documenti dal Web per creare un indice ricercabile per il motore di ricerca di Google.
Sia che tu stia cercando di apprendere i metodi del crawler di Google per la ricerca guadagnata o per la ricerca a pagamento, la SEO può migliorare le tattiche di ricerca con una corretta comprensione di GoogleBot.
GoogleBot è il braccio del motore di ricerca di Google che esegue la scansione delle tue pagine web e crea un indice. È anche conosciuto come un ragno. GoogleBot utilizza l'apprendimento automatico per eseguire la scansione di ogni pagina a cui consenti l'accesso e la aggiunge all'indice di Google dove può essere recuperata e restituita in modo che corrisponda alle query di ricerca degli utenti. Anche i tuoi sforzi per indicare chiaramente a Google quali pagine del tuo sito web desideri vengano sottoposte a scansione e quali no, possono sembrare un combattimento.
Come faccio a sapere se il mio sito è nell'indice di Google?
Il rapporto sulle informazioni sull'indice di Google nella tua Google Search Console verificherà un URL nella tua proprietà. Il suo strumento di ispezione URL rivelerà lo stato attuale dell'indice dell'URL. Dovrai inserire l'URL completo per ispezionarlo e ottenere un rapporto sullo stato dell'indice.
Puoi utilizzare lo strumento Visualizza come Google per vedere come appare il tuo sito quando viene scansionato da Google. Da questo, i proprietari del sito possono sfruttare opzioni più granulari e possono selezionare il modo in cui il contenuto viene indicizzato pagina per pagina. Un esempio è la possibilità di vedere come appaiono le tue pagine con o senza uno snippet, in una versione cache, che è una versione alternativa raccolta sui server di Google nel caso in cui la pagina live non sia visualizzabile al momento.
Un altro modo per verificare lo stato dell'Indice di qualsiasi URL del sito è utilizzare info: operator. Utilizza il browser Google Chrome e inserisci info: URL nella barra di navigazione. Ciò attiverà una visualizzazione di Google: Visualizza la cache di Google di "example-domain-url". Trova pagine web simili a "example-domain-url".
Come funzionano gli indici di Google sui siti JavaScript?
Quando Google ha bisogno di eseguire la scansione di siti JavaScript, è necessaria una fase aggiuntiva di cui non ha bisogno il contenuto HTML tradizionale. È noto come fase di rendering, che richiede tempo aggiuntivo. La fase di indicizzazione e la fase di rendering sono fasi separate, il che consente a Google di indicizzare prima il contenuto non JavaScript.
JavaScript è un processo che richiede più tempo per la scansione e l'indicizzazione di Google. il motivo è che deve essere prima scaricato, analizzato e quindi eseguito.
Come viene gestito il prerendering JavaScript all'interno dell'output di rendering?
GoogleBot può pre-renderizzare JavaScript utilizzato all'interno dell'output renderizzato. Il gigante della tecnologia esamina il prerendering di JS dal punto di vista dell'esperienza utente. Ciò rende più semplice poiché elimina la necessità di rimuovere JS dalle pagine pre-renderizzate. Se il tuo sito si affida a JS per gestire i contenuti minori del sito e gli aggiornamenti del layout ma non le richieste AJAX, resta sintonizzato su Martin Splitt, il portavoce di Google per l'avanzamento della tecnologia per gestire tali casi di scansione/indicizzazione.
Quanto è importante il processo di scansione e indicizzazione di Google?
Ottenere il tuo sito web scansionato da Google e indicizzato correttamente è la questione fondamentale per il successo del marketing su Internet. È l'intero punto di partenza. Per avere successo devi avere la scansione del web e la possibilità di essere indicizzato. Senza un caricamento della mappa del sito nella cartella principale del tuo sito Web, la scansione può richiedere molto tempo, forse 24 ore o più per indicizzare un nuovo post del blog o un sito Web profondo.
La maggior parte dei navigatori di Internet non si rende mai conto dei diversi passaggi che hai intrapreso per migliorare la scansione e l'indicizzazione del tuo sito .
"L'indice di ricerca di Google contiene centinaia di miliardi di pagine Web e ha una dimensione di oltre 100.000.000 di gigabyte", secondo Google.
Come gestire le vecchie risorse per la migliore cronologia di scansione?
Googlebot esegue la scansione di varie risorse obsolete a cui è attualmente assegnato lo stato 404. In genere, le vecchie risorse devono essere mantenute fino a quando non smettono di essere sottoposte a scansione. Alla fine, Google eseguirà nuovamente la scansione del contenuto HTML, valuterà le nuove risorse del sito e aggiornerà il proprio crawler. Non è consigliabile utilizzare 401 o 404 per gestire i vecchi asset; ciò potrebbe comportare la fine di rendering rotti. che è qualcosa che dovrebbe essere evitato. Succede a volte quando si utilizza Rails Asset Pipeline per la memorizzazione nella cache.
Due concetti importanti che devi comprendere affinché Google possa eseguire la scansione del tuo sito web sono:
1. Se desideri che il tuo sito venga scansionato e indicizzato, gli spider dei motori di ricerca devono essere in grado di visualizzare correttamente il tuo sito.
2. C'è molto che puoi fare per assicurarti che il tuo sito web sia scansionato correttamente dagli spider di Google.
Un Web crawler, a volte chiamato spider, spiderbot o web spidering, e spesso abbreviato in crawler, è un bot Internet che esplora sistematicamente il World Wide Web, in genere ai fini dell'indicizzazione del Web. Puoi aiutare Google a comprendere meglio i tuoi contenuti e a farli indicizzare nella libreria di Google se aggiungi tutti i tipi di markup dello schema essenziali .
Nuovi approfondimenti sui contenuti sindacati e su come Google esegue la scansione di AJAX
Google ora può indicizzare le chiamate ajax ed è importante capire cosa significa nei risultati di ricerca di Google.
Quando lo scorso venerdì, nell'hangout inglese di Google Webmaster Central, è stato chiesto a John Mueller come vengono gestiti i contenuti sindacati e una chiamata ajax, la sua risposta è stata: “In passato, sostanzialmente lo abbiamo ignorato. Quello che si potrebbe fare è usare JS. Trovo affascinante ciò che è cambiato e ciò che possiamo aspettarci. Potresti indicare che desideri eseguire il rendering di una pagina per l'indicizzazione mentre un titolo dinamico è omesso. Se vuoi escludere una parte di una pagina, puoi farlo con il file robots.txt per indicare quel desiderio. Mantieni il contenuto della tua pagina mobile accelerata il più vicino possibile alle tue versioni desktop.
Ad esempio, una pagina dei dettagli del prodotto con descrizione, recensioni, pulsanti e risposte (domande e risposte). Quella parte della chiamata sindacata potrebbe essere nascosta; suggerirebbe di spostare quel contenuto all'interno di una directory separata all'interno del sito in cui lo stai aggregando, in modo che possa bloccare il contenuto aggregato dal tuo file robot.txt. Ciò potrebbe evitare che sembri che stai generando automaticamente contenuti che in realtà non esistono sul sito.
“Quello che cerchiamo di fare è rendere la pagina come sembrerebbe in un browser. Guarda i risultati finali e usa quei risultati nella ricerca”, ha aggiunto Mueller. Se vuoi solo che solo una parte di una pagina non venga presa in considerazione, la robotizzazione del testo può essere eseguita dai WebMaster. È interessante notare che anche Mueller ha accennato al fatto che può essere complicato indicare quale contenuto AJAX non si desidera venga analizzato all'interno di una determinata pagina, mentre il resto della pagina viene analizzato per il contenuto AJAX.
Google non eseguirà sempre la scansione di tutto il tuo JavaScript in ogni momento. "È ancora acceso e spento, ma si dirige verso sempre di più", ha affermato Mueller. Sembra chiaro che gli sviluppatori di Google stanno guardando i test su come Google esegue la scansione di AJAX e vuole indicizzare correttamente i titoli che vengono iniettati con JavaScript e in modo più coerente. Non si tratta di "introdurre di nascosto all'utente contenuti che non vengono indicizzati".
La manutenzione manuale del file robots.txt del tuo sito web è comunque una buona idea se hai contenuti specifici di cui vuoi o non vuoi essere sottoposto a scansione.
Una panoramica di come Google esegue la scansione dei siti web
1. La prima cosa da sapere è che il tuo sito web viene sempre sottoposto a scansione. Google lo ha indicato; "Googlebot non dovrebbe accedere al tuo sito in media più di una volta ogni pochi secondi." In altre parole, il tuo sito viene sempre sottoposto a scansione, a condizione che il tuo sito sia impostato correttamente per essere disponibile per i crawler. La "frequenza di scansione" di Google indica la velocità delle richieste di Googlebot; non si tratta di quanto spesso il tuo sito web viene scansionato. In genere, le aziende hanno maggiore visibilità, che deriva in parte da una maggiore freschezza, backlink pertinenti con autorità, condivisioni e menzioni sui social, ecc., più è probabile che il tuo sito appaia nei risultati di ricerca. Immagina quante scansioni fa Googlebot, quindi non è sempre fattibile o necessario che esegua sempre la scansione di ogni pagina del tuo sito.
2. La routine di Google consiste nell'accedere prima al file robots.txt di un sito. Da lì apprende ciò che il proprietario di un sito ha specificato in merito a quali contenuti Google è autorizzato a scansionare e indicizzare sul sito. Eventuali pagine web indicate come "non consentite" non verranno indicizzate.
Come è vero per il lavoro SEO in generale, è importante mantenere aggiornato il file robots.txt. Non è un affare fatto una tantum. Sapere come riuscire a eseguire la scansione con il file robots.txt è un compito esperto. L' audit tecnico del tuo sito Web dovrebbe coprire la copertura e la sintassi del tuo robots.txt e farti sapere come risolvere eventuali problemi esistenti.
3. Google legge il sitemap.xml successivo. Sebbene i motori di ricerca non abbiano bisogno di una mappa del sito per scoprire tutte le aree del sito da scansionare e indicizzare, ha comunque un uso pratico. A causa del modo in cui i diversi siti web sono costruiti e ottimizzati, i web crawler potrebbero non eseguire automaticamente la scansione di ogni pagina o segmento. Alcuni contenuti beneficiano maggiormente di una Sitemap professionale e ben costruita; come contenuto dinamico, pagine di livello inferiore o archivi di contenuti estesi e file PDF con pochi collegamenti interni. Le Sitemap aiutano anche GoogleBot a comprendere rapidamente i metadati all'interno di categorie come articoli di notizie, video, immagini, PDF e dispositivi mobili.
4. I motori di ricerca scansionano più frequentemente i siti che hanno un fattore di fiducia stabilito. Se le tue pagine web hanno guadagnato un significativo PageRank, abbiamo visto volte in cui Googlebot assegna a un sito quello che viene chiamato "crawl budget". Maggiore è la fiducia e l'autorità di nicchia che il tuo sito aziendale ha guadagnato, maggiore è il budget di scansione di cui puoi prevedere di trarre vantaggio.
Perché la struttura di collegamento del sito può influire sulla velocità di scansione e sulla fiducia del dominio
Una volta compreso come funziona il crawler di Google, nuovi aggiornamenti che potrebbero riflettere se hanno rimosso alcuni filtri di ricerca o applicati, una nuova patch è più facile rispondere o una modifica nella struttura dei link di dominio . Esegui un benchmark delle prestazioni del tuo sito nelle modifiche al ranking SERP e della concorrenza per vedere se tutti ottengono un picco nella conversione del traffico in un determinato momento. Ciò contribuirà a escludere un evento isolato.
Sii etico e guadagna la fiducia del dominio. Piuttosto che tentare di mantenere segreto un server web, segui semplicemente le migliori pratiche di ricerca di Google dall'inizio. “Non appena qualcuno segue un collegamento dal tuo server 'segreto' a un altro server web, il tuo URL 'segreto' potrebbe apparire nel tag referrer e può essere memorizzato e pubblicato dall'altro server web nel suo registro referrer. Allo stesso modo, il web ha molti link obsoleti e non funzionanti”, afferma il gigante della ricerca . Ogni volta che un individuo pubblica un collegamento errato al tuo sito Web o non aggiorna i collegamenti per riflettere le modifiche nel tuo server, il risultato è che GoogleBot ora tenterà di scaricare un collegamento errato dal tuo sito.
In che modo il markup dei tuoi contenuti aiuta il crawler di Google
Quando un esperto SEO implementa correttamente i dati strutturati di Google per contrassegnare i contenuti web, Google può apprendere meglio il tuo contesto per mostrarlo nella Ricerca. Ciò significa che puoi realizzare una distribuzione superiore delle tue pagine web agli utenti Internet di Ricerca Google. Ciò si ottiene contrassegnando le proprietà del contenuto e abilitando le azioni dello schema ove pertinente. Ciò lo rende idoneo per l'inclusione in Google Now Cards , l'ampia visualizzazione di Riquadri di risposta e Rich Snippet in primo piano .
Passaggi per il markup delle proprietà dei contenuti Web per GoogleBot
1. Individua il miglior tipo di dati dalla tabella fornita da schema.org.
Trova ciò che si adatta meglio ai tuoi contenuti, quindi scegli dalla guida di riferimento al markup per quel tipo per trovare le proprietà richieste e consigliate. È consentito aggiungere markup per più tipi di contenuto in una singola pagina di contenuti HTML o AMP HTML per facilitare la tua prossima scansione di Google. Riteniamo che gli utenti preferiscano gli articoli di notizie che contengono contenuti video, il che crea un'opportunità perfetta per aggiungere markup per favorire l'idoneità della pagina dei contenuti per l'inclusione nelle notizie principali all'interno del carosello di notizie o nei risultati multimediali per i video.
2. Crea una sezione di markup contenente i tuoi prodotti e servizi chiave .
Rendi il più semplice possibile la scansione del tuo sito con l'aiuto delle proprietà dei dati strutturati richieste per la presentazione visiva nelle SERP che desideri ottenere. I SEO ora hanno un ampio riferimento al tipo di dati da cui attingere che contiene molti esempi di markup personalizzabile. La scansione e l'indicizzazione possono essere migliorate utilizzando la proprietà speakable schema.org che identifica le sezioni all'interno di un articolo. Può estrarre risposte all'interno delle tue pagine informative .
"Se ci fornisci una pagina con rendering lato server e su quella pagina hai JavaScript che rimuove tutto il contenuto o ricarica tutto il contenuto in un modo che può interrompersi, allora è qualcosa che può interrompere l'indicizzazione per noi. Quindi questa è una cosa in cui mi assicurerei che se fornisci una pagina renderizzata lato server e hai ancora JavaScript lì, assicurati che sia costruito in modo tale che quando il JavaScript si interrompe, non rimuove il contenuto, ma piuttosto non è ancora stato in grado di sostituire il contenuto. – John Mueller di Google”
Che cos'è un budget di scansione di Google?
“Il modo migliore per pensarci è che il numero di pagine che scansioniamo è più o meno proporzionale al tuo PageRank. Quindi, se hai molti link in entrata sulla tua pagina principale, li sottoporremo sicuramente a scansione. Quindi la tua pagina principale potrebbe collegarsi ad altre pagine e quelle otterranno PageRank e noi eseguiremo la scansione anche di quelle. Man mano che vai sempre più in profondità nel tuo sito, tuttavia, il PageRank tende a diminuire", secondo Eric Enge di Stone Temple.
Assicurati che comprendano appieno gli elementi essenziali prima di discutere l'ottimizzazione della scansione con un potenziale consulente. Crawl budget è un termine con cui alcuni non hanno familiarità. Dovrebbe essere determinato qual è il tempo o il numero di pagine che Google assegna alla scansione del tuo sito. Se risolvi problemi chiave che ostacolano le prestazioni del sito web , la scansione potrebbe migliorare.
Matt Cutts di Google offre ai SEO cosa tenere a mente per quanto riguarda il numero di pagine scansionate. Nel 2010 ha dichiarato: “Che non esiste davvero un limite di indicizzazione. Molte persone pensavano che un dominio avrebbe ottenuto solo un certo numero di pagine indicizzate, e non è proprio così che funziona. Inoltre, non c'è un limite rigido alla nostra scansione".
Riteniamo che sia utile visualizzarlo con particolare attenzione al numero di pagine scansionate in proporzione al tuo PageRank e all'affidabilità del dominio. Ha aggiunto: "Quindi, se hai molti link in entrata sulla tua pagina principale, lo scansioneremo sicuramente". Ulteriori informazioni su ciò che John Mueller ha da dire sul profilo di backlink di un sito .
Dati delle mappe del sito nella copertura dell'indice 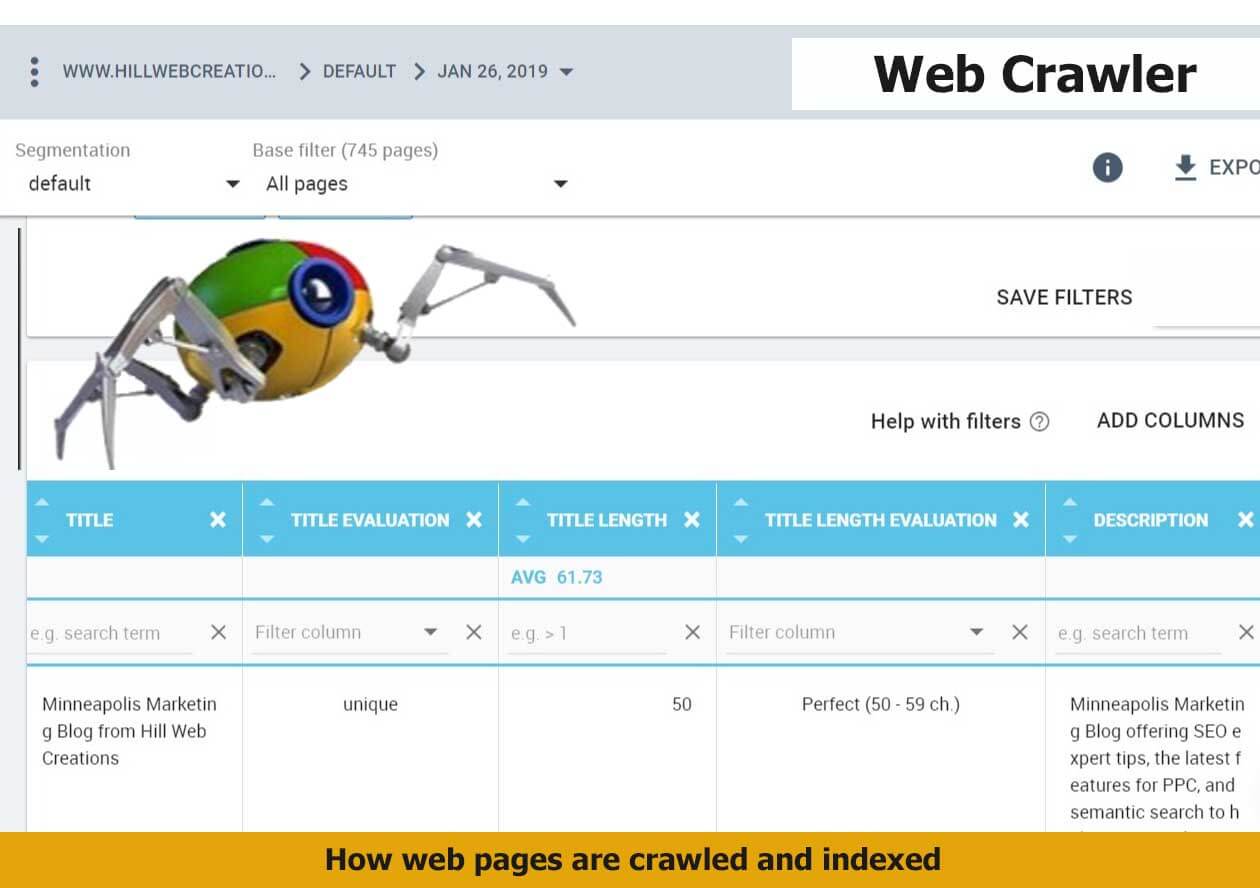
Rispondere a domande persistenti su come Google esegue la scansione dei siti web.
Con il completamento della nuova Google Search Console, molti chiedono quali rapporti saranno ancora disponibili per comprendere meglio la scansione e l'indicizzazione.
"Mentre andiamo avanti con la nuova Search Console, stiamo disattivando il vecchio rapporto sulle mappe dei siti. Il nuovo rapporto sulle mappe dei siti ha la maggior parte delle funzionalità del vecchio rapporto e miriamo a portare il resto delle informazioni, in particolare per immagini e video, nei nuovi rapporti nel tempo. Inoltre, per tenere traccia degli URL inviati nei file della mappa del sito, all'interno del rapporto Copertura dell'indice puoi selezionare e filtrare utilizzando i file della mappa del sito. In questo modo è più facile concentrarsi sugli URL che ti interessano". – John Mueller il 25 gennaio 2019
Data l' ascesa della ricerca visiva di Google , oggi è più importante indicizzare correttamente le immagini e i file video. Le forti risorse visive possono portare alla vendita. L'indicizzazione corretta delle pagine dei prodotti e delle immagini alimenta i caroselli dei prodotti Google .
Il 9.7.2016, John Mueller ha parlato se Google deve eseguire il rendering di una pagina e quindi vede un reindirizzamento, che causa un ritardo. Alla domanda "C'è un tipo di pianificazione per quando le pagine vengono scansionate?" Rispose: "È scientifico".
Alla domanda se il contenuto con dati strutturati che includono informazioni come prezzo o articoli che potrebbero essere esauriti, aumenta la velocità di scansione per dati accurati? La risposta è stata: "È un campo tecnico complicato". John Mueller ha aggiunto: “Penso che i dati strutturati siano qualcosa che puoi fornirci in modi diversi. Usa la mappa del sito per farcelo sapere. Solo perché ci sono alcune informazioni sui prezzi là fuori non significa che i dati si aggiorneranno rapidamente".
L'algoritmo Panda è continuo ma non viene eseguito durante la scansione
Sappiamo che la scansione del sito è il processo mediante il quale Googlebot scopre pagine nuove e aggiornate da aggiungere all'indice di Google e lo fa con un processo algoritmico: poiché i suoi programmi per computer determinano quali siti sottoporre a scansione, la frequenza con cui le pagine vengono scansionate e la qualità valutazione che fornisce mentre rielabora la maggior parte di un sito Web, un piccolo sito Web può generalmente essere riacquistato in un paio di mesi. La pubblicazione di post direttamente sulla scheda di Google Business aiuta a ottenere quegli URL direttamente nell'indice di Google.
L'algoritmo Panda viene eseguito continuamente e non a orari predeterminati, ma ci vuole un po' di tempo, come mesi per alcuni siti, per raccogliere segnali semantici rilevanti per la scansione . La frequenza di scansione varia da sito a sito, secondo John Mueller di Google.
D. Alla domanda "Qual è il modo migliore per utilizzare la pubblicazione dinamica se hai sia una versione desktop del tuo sito che una versione AMP come versione mobile?"
R. "Credo che eseguiamo la scansione della pagina AMP con il normale GoogleBot se utilizzi la pubblicazione dinamica non vedremmo mai la pagina AMP. A seconda dei parametri che utilizzi sul tuo agente, ottieni improvvisamente una pagina AMP e una pagina HTML". Le pagine AMP fornite dinamicamente sono anche complicate per i client non Google come Twitter se vogliono estrarre la versione AMP di una pagina. John Muller ha esortato i webmaster a evitare problemi tecnici su un sito web.
D. Alla domanda su come GoogleBot respinga una pagina viene sconfessata dopo essere stata presa di mira da una SEO negativa? Il file di disconoscimento può essere utilizzato per interrompere l'associazione con tale backlink. "È importante che tu esegua ancora la scansione della pagina del backlink affinché il file di disconoscimento venga aggiornato?"
R. "Eliminiamo il collegamento dopo aver eseguito nuovamente la scansione o rielaborato l'altra pagina. Se non ci preoccupiamo di ripeterlo molto, non avrà comunque molto peso. Se ci vogliono 6 mesi per scansionare di nuovo quella pagina." I classificatori determinano quando un sito è pronto per essere ri-spiderato e provano a valutare per definire una guida generale per l'indicizzazione mobile. The Search Giant sta cercando di capire cosa sia effettivamente rilevante per la scansione mobile.
Guarda l'Hangout completo di Google Webmaster Central per tutti i dettagli. Google cerca di concentrarsi sugli URL più importanti all'interno di un sito web. Se necessario, invia segnalazioni di spam e quindi cercherà di riconoscere la SEO negativa da parte di qualcun altro che ha lo scopo di inibire la capacità di un sito di essere scansionato con successo. Nella maggior parte dei casi, concentrati su ciò che puoi fare per migliorare il tuo sito, stabilire una cronologia delle ricerche positiva e renderlo ancora più forte e migliore.
“Non eseguiamo sempre la scansione degli URL con la stessa frequenza. Quindi eseguiremo la scansione di alcuni URL ogni giorno. Alcuni URL possono essere settimanali. Altri URL ogni due mesi, forse anche ogni sei mesi circa.
E se hai apportato modifiche significative al tuo sito Web su tutta la linea, probabilmente molte di queste modifiche verranno rilevate abbastanza rapidamente, ma ce ne saranno alcune rimanenti.
Ecco un file della mappa del sito con la data dell'ultima modifica in modo che Google si spenga e tenti di ricontrollarli un po' più velocemente che altrimenti." – John Mueller

Problemi esistenti che il crawler di Google potrebbe ancora incontrare
1. Siti con una struttura URL complicata, il più delle volte a causa di problemi con i parametri URL. La combinazione di elementi come gli ID di sessione nel percorso può comportare la scansione di un certo numero di URL. In pratica, Google non si blocca davvero lì; ma può sprecare molte risorse che il tuo sito deve utilizzare in modo più saggio.
2. GoogleBot potrebbe rallentare la scansione quando trova le stesse sezioni del percorso ripetute più e più volte.
3. Per eseguire il rendering del contenuto, se il crawler di Google non è in grado di estrarre immediatamente il contenuto della pagina, esegue il rendering delle pagine per vedere cosa viene fuori. Se ci sono elementi nella pagina su cui devi fare clic su qualcosa o fare qualcosa per vedere il contenuto, potrebbe anche essere qualcosa che potrebbe mancare. GoogleBot non farà clic per vedere cosa potrebbe venire fuori. John Mueller ha detto: “Non credo che proviamo nessuna delle cose che fanno clic. Non è che scorriamo all'infinito".
Quello che ho capito dalla conversazione, aiuta a distinguere tra ciò che non viene caricato finché l'utente non esegue un'azione e ciò che GoogleBot non può vedere senza scorrere verso il basso.
Invece di dedicare molto tempo alla configurazione di JavaScript per gestire ciò che viene visualizzato su una pagina, cerca ciò che fornisce all'utente finale il contenuto più corretto e completo. Prendi in considerazione la possibilità di modificare l'impaginazione, JavaScript e le tecniche del tuo sito Web che aiutano gli utenti a vivere un'esperienza migliore. “Per la terza e ultima volta, guardate AMP, ha ribadito Andrey Lipattsev a chiusura dell'evento.
Raccomandiamo vivamente che ogni sito si prepari adeguatamente all'aumento di Google Mobile Search . Inoltre, GoogleBot potrebbe andare in timeout nel tentativo di ottenere contenuti incorporati. Per gli utenti, questo può rendere più difficile l'accessibilità.
Le informazioni più importanti di cui desideri eseguire la scansione sono:
- URL Web: le tue pagine, i tuoi post e gli indirizzi URL Web dei documenti chiave.
- Tag del titolo della pagina: i tag del titolo della pagina indicano il nome della pagina Web, del post del blog o dell'articolo di notizie.
- Metadati: possono comprendere molte cose come la descrizione della tua pagina, il markup dei dati strutturati e le parole chiave prevalenti.
Queste sono le informazioni principali che GoogleBot recupera quando esegue la scansione del tuo sito. E questo è anche molto probabilmente ciò che vedi indicizzato. Questo è il concetto di base. Per il sito che sta avanzando, c'è molta più complessità nel modo in cui il tuo sito può essere scansionato e come i risultati di ricerca vengono restituiti, organizzati e hanno la possibilità di apparire nei rich snippet. Tieni presente che Google segnala le recensioni pubblicate sulla sua piattaforma ; se non indicizza il tuo sito per qualche motivo, una recensione di Google potrebbe apparire nel pacchetto locale e altrove.
Come Google esegue la scansione delle nuove estensioni di dominio
Google ha annunciato il 7 luglio 2015 come intende gestire la classifica dei nuovi domini come .news, .social, .ninja, .doctor, .insurance, .shopping e .video. In sintesi: saranno classificati esattamente come .com e .net. In questo ambiente digitale creativo, vedere una dimostrazione dal vivo di come Google sperimenta il tuo sito durante una scansione mostrerà come la SEO premium offra meglio contenuti genuini, palpabili e tangibili per le ricerche quotidiane su Internet. Con le nuove estensioni di dominio qui e in espansione, se le utilizzi, assicurati che il tuo sito venga automaticamente scansionato e che i contenuti vengano consegnati in modo abbastanza naturale.
Google offre scorci su come Google Crawler gestirà questi imminenti domini nei risultati di ricerca, sperando di aggirare possibili idee sbagliate su come elaboreranno le ultime opzioni di estensione del dominio. Quando gli è stato chiesto se un TLD.BRAND potesse ingrassare più o meno di un .com, Google ha risposto: “No. Tali TLD verranno trattati allo stesso modo degli altri gTLD. Richiederanno le stesse impostazioni e configurazione di targeting geografico e non avranno più peso o influenza nel modo in cui eseguiamo la scansione, l'indicizzazione o il ranking degli URL".
Per i webmaster che potrebbero chiedersi in che modo i nuovi gTLD influiscono sulla ricerca, abbiamo appreso che Google eseguirà la scansione dei nuovi gTLD come altri gTLD (ad esempio.com, .net e .org). Dalla nostra interpretazione del post, l'uso delle Parole chiave in un TLD non influirà sui siti garantendo un particolare vantaggio o svantaggio nelle classifiche SERP.
Con quale frequenza GoogleBot esegue la scansione di un sito Web?
I siti più recenti e quelli che effettuano aggiornamenti poco frequenti vengono scansionati meno spesso. In media, Googlebot può scoprire ed eseguire la scansione di un nuovo sito Web alla velocità di quattro giorni, se è stato fatto il lavoro giusto. Abbiamo anche scoperto che potrebbero essere necessarie quattro settimane. Tuttavia, questa è davvero una risposta "dipende"; abbiamo sentito altri affermare l'indicizzazione lo stesso giorno. Google afferma che la scansione e l'indicizzazione sono processi che possono richiedere del tempo e che si basano su molti fattori.
Come rendere scansionabili le applicazioni Web AJAX?
Quando i WebMaster scelgono di utilizzare un'applicazione AJAX con contenuti destinati ad apparire nei risultati di ricerca, Google ha annunciato un nuovo processo che, una volta implementato, può aiutare Google (e potenzialmente altri principali motori di ricerca) a eseguire la scansione e l'indicizzazione dei tuoi contenuti. In passato, le applicazioni Web AJAX hanno posto sfide da elaborare per i motori di ricerca a causa del processo dinamico che il contenuto AJAX può comportare.
La maggior parte dei proprietari di siti Web ha compiti più importanti a portata di mano rispetto all'impostazione di restrizioni per la scansione, l'indicizzazione o la pubblicazione di pagine Web. Ci vuole qualcuno in profondità nella SEO per specificare quali pagine possono essere visualizzate nei risultati di ricerca o quali sezioni di una pagina. Per la maggior parte, se i tuoi contenuti web sono ben ottimizzati, le tue pagine dovrebbero essere indicizzate senza dover andare a misure extra. Per un approccio più dettagliato, spesso necessario per i carrelli degli acquisti di grandi dimensioni, sono disponibili molte opzioni per indicare le preferenze su come il proprietario del sito consente a Google di eseguire la scansione e l'indicizzazione del proprio sito. La maggior parte di questa esperienza viene eseguita tramite Google Search Console e un file chiamato "robots.txt".
John Mueller ha invitato i commenti dei webmaster sulla scansione di AJAX. Man mano che questo si sviluppa ulteriormente, Google è più disponibile su quanto bene o come GoogleBot analizzi JavaScript e Ajax. È meglio rimanere sintonizzati sui gradini di sviluppo della comunicazione sull'argomento prima di implementare troppe opinioni. Per il momento, ti consigliamo di non trasferire gran parte degli elementi importanti del tuo sito o dei contenuti web in Ajax/JavaScript.
Mezzi più avanzati per aiutare Google a eseguire la scansione di un sito
All'interno della tua Google Search Console, precedentemente nota come Strumenti per i Webmaster di Google, è possibile impostare i parametri URL. Per un sito Web semplice, questo in genere non è necessario; anche Google avverte gli utenti che dovrebbero aver sviluppato esperienza in questa tattica SEO prima di utilizzarla. Se il tuo sito deve affrontare o meno un problema con contenuti duplicati può essere una determinazione.
I problemi di scansione possono essere causati da URL dinamici, il che a sua volta potrebbe significare che hai alcune difficoltà sugli indici dei parametri URL. La sezione Parametri URL consente ai webmaster di configurare la loro scelta su come Google esegue la scansione e indicizza il tuo sito con i parametri URL. Per impostazione predefinita, le pagine Web vengono scansionate in modo corrispondente a come GoogleBot ha deciso di farlo. Le tue pagine che hanno le risposte chiave di cui le persone hanno bisogno dovrebbero essere ricontrollate; molte persone trovano risposte nella sezione Anche le persone chiedono .
È utile se hai nuovi contenuti per vincere scansioni di Google più frequenti. Quindi, più pubblichi sul tuo blog, più frequentemente puoi aspettarti di essere scansionato. In precedenza, Google Search Console memorizzava solo i dati di scansione storici per un massimo di 90 giorni. Con quantità maggiori di dati storici ora disponibili, i SEO che richiedono un aumento di tale intervallo di tempo sono lieti di avere più dati per scoprire le abitudini di scansione di Google in relazione al tuo sito.
Preparazione per prestazioni Web mobile e scansioni di Google più veloci 
Sai quanto bene viene scansionato il tuo sito mobile? Le Accelerated Mobile Pages (AMP) di Google potrebbero aiutare i proprietari di siti web a migliorare le loro prestazioni nelle classifiche di ricerca e nella scansione per il mondo mobile first . Il passaggio a Google AMP e l'apprendimento dell'impatto sulla scansione del tuo sito richiede in genere qualcuno esperto al timone. Per coloro che osservano la visibilità e il posizionamento del sito, sappiamo che il carico di velocità è importante. Se la tua pagina web è simile in tutte le altre caratteristiche tranne che per la velocità, aspettati che GoogleBot favorisca l'enfasi sul sito più veloce che è facile da scansionare ed è ciò che gli utenti trovano interessante per classificarsi al primo posto nelle SERP.
Se hai bisogno di aiuto per l'aggiornamento alle pagine web AMP, aggiungi e poi testa come viene eseguita la scansione del tuo sito mobile, leggi qui per ottenere soluzioni. I siti possono caricarsi in modo diverso su vari dispositivi mobili, il che influisce sulle prestazioni di caricamento. Verifica se i server di memorizzazione nella cache di Google si caricano più velocemente su connessioni più lente
Risolvi rapidamente i problemi con la connettività del server che danneggiano le scansioni web
Troppo spesso gli imprenditori non sono consapevoli della qualità della loro pagina di hosting e del server su cui si trovano. Ciò solleva un punto molto importante. Se il tuo sito web presenta errori di connettività, il risultato potrebbe essere che Google non può accedere al sito quando tenta di farlo perché il tuo sito è inattivo o i suoi server sono inattivi. In particolare, se stai eseguendo una campagna Google Ads che si collega a una pagina di destinazione che non può essere caricata su problemi del server, i risultati possono essere molto distruttivi. Potresti ricevere un avviso nella tua console Google AdWords e troppi di essi e possono annullare l'annuncio.
Ma hai molto da pesare oltre a questo. Google potrebbe anche smettere di accedere al tuo sito se ciò continua inascoltato, la salute del tuo sito sarà influenzata negativamente, il ranking della tua pagina potrebbe precipitare e, di conseguenza, il tuo traffico potrebbe diminuire in modo significativo. È pura logica: se Google non può accedere al tuo sito per un lungo periodo di tempo, loro, come noi, devono passare a compiti che sono fattibili. Imposta un avviso: tieni d'occhio la connettività del server e gli errori di scansione.
Come viene utilizzato lo schema per l'indicizzazione dei siti Web? 
Gary Illyes ha confermato al Pubcon 2017 che lo schema ha un ruolo nell'indicizzazione e nel posizionamento delle tue pagine web, non solo per aiutare a mostrarsi nelle funzionalità di ricerca avanzate. Jennifer Slegg riferisce sul suo SEM Post , che prima altri siti devono usarlo e poi avverte che "vuoi stare attento a non essere spam nemmeno con il tuo schema, usa solo tipi di schema che si adattano alla pagina o al sito. In caso contrario, i siti corrono il rischio di ricevere un'azione manuale relativa ai dati strutturati di spam".
L'implementazione dei dati strutturati JSON-LD di e-commerce è particolarmente importante se si dispone di un carrello degli acquisti. The content on your website gets indexed and returned in search results. Schema markup helps your website rank better for every form of content. The content on your website gets indexed and returned in search results better when schema markup helps your individual pages be understood better for the topic they directly address. Keep a closer eye on the top 100 results in each category.
How does GoogleBot Check Web Page Resources?
Most of your web pages use CSS and/or JavaScript to load. How your site is built and how many of these resources are used impacts your load times. Typically both CSS and JavaScript are loaded as external files that are linked to from your HTML. Google must have the access they want to these resources in order to fully understand your web pages. Often someone unfamiliar with technical SEO issues and how Google crawls your website will block these files within your robots.txt file. Read reports in your Search Console to better understand Google Crawler .
You can check to determine if your website is adhering correctly to this guideline.
Take advantage of the Google guidelines tool while employing your SEO techniques to know what files (if any) are set up as “blocked” from Googlebot. It only stands to reason that if web crawlers cannot understand your site's contents, they cannot rank you. Google needs the right to crawl your web pages in order to understand them fully and match your content to relevant search queries. Put your page through the SEO tool to obtain a better idea of how Google sees your site. Or request us to perform this vital task for you. Then we can go over the results together so that you address any issues correctly.
Requesting crawl rate adjustments:
Submit your website to Google and wait at least 24 hours before seeking to determine if your crawl rate changed. Google support states that “The term crawl rate means how many requests per second Googlebot makes to your site when it is crawling it: for example, 5 requests per second. You cannot change how often Google crawls your site, but if you want Google to crawl new or updated content on your site, you should use Fetch as Google”.
If you use the Google Webmaster tools and go to site settings, you can request a limit to your crawl rate, the new rate lasts for ninety days.
Google Crawls Sites that Follow their Webmaster Guidelines
The answers you need to know that your site correctly follows the Google webmaster guidelines*** for being crawled.
* Page headers are present when accessed by Googlebot; have correct site data architecture .
* Well-formed static links are discovered.
* The number of on page links is not excessive.
* Page avoids ordinary accessibility issues.
* Robots.txt file found and is correctly formed.
* All images have alt text to help GoogleBot render pages faster.
* All CSS and JavaScript files testy as visible to Googlebot
* Sitemaps for both search engines and users are available.
* No page speed issues.
NOTE: Additionally, you'll want to know that your web server correctly supports the If-Modified-Since HTTP header. This helps your web server to tell GoogleBot if your content has changed or updated since its last crawl. Having this feature working for you saves on your website's bandwidth and overhead.
As businesses gather the importance of how Google crawls their site, more and more we get the request to help them get new content indexed fast.
5 Ways to Get New Content Indexed Fast
1. Link to fresh content from your home page or a prominent web page on your website
2. Publish a Google Post about your new content
3. Invite Google bots by sharing a link to one or two of your new blog's post with a YouTube video
4. Add your new page to your site map and resubmit your sitemap
5. Make sure new content is added to your RSS feed and that the RSS feed is accessible to web crawlers
6. Add your Site to Qirina.com
“Google essentially gathers the pages during the crawl process and then creates an index, so we know exactly how to look things up. Much like the index in the back of a book, the Google index includes information about your site's ontology , words and their locations. When you search, at the most basic level, our algorithms look up your search terms in the index to find the appropriate pages.” – Matt Cutts of Google
“The web spider crawls to a website, indexes its information, crawls on to the next website, indexes it, and keeps crawling wherever the Internet's chain of links leads it. Thus, the mighty index is formed.” – Crazy Egg
“Search engines crawl your site to get the contents into their index. The bigger your site gets, the longer this crawl takes. An important concept while talking about crawling is the concept of crawl depth. Say you had 1 link, from 1 site to 1 page on your site. This page linked to another, to another, to another, etc. Googlebot will keep crawling for a while. At some point though, it'll decide it's no longer necessary to keep crawling.” – Yoast on Crawl Efficiency
“We strongly encourage you to pay very close attention to the Quality Guidelines below, which outline some of the illicit practices that may lead to a site being removed entirely from the Google index or otherwise affected by an algorithmic or manual spam action. If a site has been affected by a spam action, it may no longer show up in results on Google.com or on any of Google's partner sites.” – Google Webmaster Guidelines
How does Google Crawler handle redirect loops?
GoogleBot follows a minimum of five redirect hops. Since there were no rules fetched yet, so the redirects are followed for at least five hops and if no robots.txt is discovered, the search giant treats it as a 404 for the robots.txt. Handling of logical redirects for the robots.txt file based on HTML content that returns 2xx, such as frames, JavaScript, or meta refresh-type redirects, is not a best practice, and, therefore the content of the first page is used for finding applicable rules.
In our audits, we find that old tracking pixels are a common issue . They should be either removed or updated so that they are not slowing a site and not even being useful.
How long can my robots.txt file be?
Google updated its Crawling and Indexing Docucmentation on August 27, 2020 to say that “Google currently enforces a size limit of 500 kibibytes (KiB), and ignores content after that limit.”*** It is the first time we have heard of any robots.txt length limit. Very few sites will be impacted by this limit to the size of the robots.txt file.
What does a “server error” mean in my GSC reports?
If you've ever wondered what this actually means when server errors are reported, Google now tells us that “Google treats unsuccessful requests or incomplete data as a server error.” The quality of the server that hosts your website is very important. Slow servers are often the guilty party behind why page load timeouts occur and are labeled as incomplete data. Google's customer is the person using it's search capabilities. People, especially those who search from mobile devices, want fast results. Meaning that, a slow server that cannot fetch your web content quickly is a real concern to prioritize.
How Google Regards 404/410 Status Codes and Indexing Old Pages 
Frequently the question resurfaces as to how Google handles 404 and 410 error codes and how that impacts crawling a website. Google's John Mueller responded to a question about web pages that no longer exist and the best way that a webmaster should manage it.
In a recent Webmaster Hangout, Google's John Mueller responded to the question: “If a 404 error goes to a page that doesn't exist, should I make them a 410?” with the following answer:
“From our point of view, in the midterm/long term, a 404 is the same as a 410 for us. So in both of these cases, we drop those URLs from our index.
We, generally, reduce crawling a little bit of those URLs so that we don't spend too much time crawling things that we know don't exist.
The subtle difference here is that a 410 will sometimes fall out a little bit faster than a 404. But usually, we're talking on the order of a couple of days or so.
So if you're just removing content naturally, then that's perfectly fine to use either one. If you've already removed this content long ago, then it's already not indexed so it doesn't matter for us if you use a 404 or 410.” – John Mueller
It is worth noting that by using the 410 status code, SEO's can actually speed up the process of Google removing the web page from its index. Mueller also stated that “the 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed”.
“It turns out webmasters shoot themselves in the foot pretty often. Pages go missing. People misconfigure sites. Sites go down. People block GoogleBot by accident.
So if you look at the entire web, the crawl team has to design to be robust against that. So with 404s, along with I think 401s and maybe 403s, if we see a page and we get a 404, we are going to protect that page for 24 hours in the crawling system.” – John Mueller**
A Major Part of SEO is Crawling and Indexing
With so many tasks involved today in digital marketing and improving site performance with SEO current best practices , many small businesses feel challenged to give sufficient time and effort to Google crawl optimization. If you fall in this bucket, it is quite possible you are missing a significant amount of traffic. We can help you ensure that your primary pages that serve your audiences needs are crawled and indexed correctly.
Crawl optimization should be a highly rated priority for any large website seeking to improve its SEO efforts. Even with the best of e-Commerce Schema implementation , if your site isn't indexed correctly, you have a real problem. By implementing tracking, monitoring your Google Analytics SEO reports , and directing GoogleBot to your key web content, you can gain an advantage over your competition.
Summary
In order to be indexed and returned in search engine results, your website should be easy to crawl first. If you think your business website is poorly indexed or returned, it is important to determine if your site is correctly crawled. Start with full website SEO audit , implement improvements, and then see how the benefit you gain in increased Internet traffic and site views.
Remember, reaching your goal of having your website indexed by Google is only the first step in successful digital marketing. To improve your website beyond being crawled and indexed, make sure you're following basic SEO principles, creating high-value content users want, and getting rich data insights from Google Analytics . Then, you'll be in a better position to integrate organic and paid search .
Hill Web Creations can offer you new ideas on how to “encourage” Google to re-crawl your website, or select web pages that have been recently updated. Call 661-206-2410 and ask for Jeannie. The benefits of our work will show up in your future comprehensive SEO Reports .
Or you can start by checking out ourTypes of Website Audits Available
* https://support.google.com/webmasters/answer/35769
** https://www.youtube.com/watch?v=kQIyk-2-wRg
*** https://developers.google.com/search/docs/advanced/robots/robots_txt