
Cum Google vă accesează cu crawlere site-ul și indexează
Publicat: 2016-02-18Cum accesează Google cu crawlere paginile AMP, JavaScript și AJAX ale site-ului dvs
Ultima actualizare: 6 martie 2021
Un „pas” uriaș înainte în modul în care Google „accesează” cu crawlere conținutul Ajax! Google este cel mai bun din lume la accesarea cu crawlere a conținutului în JavaScript și AJAX. Cu toate acestea, ei încă îl perfecţionează. Considerați că este un câmp de luptă pentru ca site-ul dvs. să fie accesat cu crawlere?
Google și-a schimbat modul de a gestiona apelurile AJAX către conținut web. John Mueller de la Google a spus că acestea pot fi „pornite și dezactivate”, așa că există tactici SEO suplimentare pe care experții în căutare le pot angaja pentru a-i anunța pe Google intenția ta de accesare cu crawlere a conținutului. Mergând înainte, cel mai bine este să nu te bazezi pe așa cum a fost înainte. Având un proces de marketing agil în vigoare, vă va ajuta să navigați mai rapid prin schimbări.
Puteți profita de statisticile descoperite în Google Search Console și puteți ști mai bine cum să le citiți și să le interpretați din răspunsurile și explicațiile din acest articol. Rapoartele tale Core Web Vitals dezvăluie probleme legate de PageSpeed .
Ce este accesarea cu crawlere și indexarea Google?
Crawlingul și indexarea rămân sarcini distincte. Accesarea cu crawlere este atunci când Googlebot se uită la tot conținutul și codul de pe o pagină web și le analizează. Indexarea are loc atunci când aceeași pagină este eligibilă pentru a fi inclusă și afișată în rezultatele căutării Google. De la actualizarea Google Panda, importanța numelui de domeniu a crescut semnificativ. Creșterea afacerii tale din lumea online depinde de accesarea cu crawlere și indexarea corectă a paginilor tale web.
Unele companii fac toată munca de a crea conținut grozav și de a-și optimiza site-ul, dar nu reușesc să indexeze conținutul cheie. De aceea, vă recomandăm ca sesiunile și strategia dvs. de planificare a afacerii să ia în considerare acest lucru din timp.
Ce este GoogleBot?
Googlebot este software-ul robot de căutare utilizat de Google, care colectează documente de pe web pentru a construi un index care poate fi căutat pentru motorul de căutare Google.
Indiferent dacă doriți să învățați metodele Google Crawler pentru căutarea câștigată sau pentru căutarea plătită, SEO poate îmbunătăți tacticile de căutare cu o înțelegere corectă a GoogleBot.
GoogleBot este brațul motorului de căutare Google care accesează cu crawlere paginile dvs. web și creează un index. Este cunoscut și sub numele de păianjen. GoogleBot folosește învățarea automată pentru a accesa cu crawlere fiecare pagină pe care îi permiteți să o acceseze și o adaugă la indexul Google de unde poate fi preluată și returnată pentru a se potrivi cu interogările de căutare ale utilizatorilor. Eforturile dvs. de a indica în mod clar Google care sunt paginile de pe site-ul dvs. web pe care doriți să fie accesate cu crawlere și care nu vă pot părea de luptă.
Cum știu dacă site-ul meu este în indexul Google?
Raportul de informații Google Index din Google Search Console va testa o adresă URL în proprietatea dvs. Instrumentul său de inspecție URL va dezvălui starea curentă a indexului URL-ului. Va trebui să introduceți adresa URL completă pentru a o inspecta și a obține un raport de stare a indexului.
Puteți utiliza Instrumentul Preluare ca Google pentru a vedea cum arată site-ul dvs. atunci când este accesat cu crawlere de Google. Din aceasta, proprietarii de site-uri pot profita de opțiuni mai detaliate și pot selecta modul în care conținutul este indexat într-o stare pagină cu pagină. Un exemplu este capacitatea de a vedea cum apar paginile dvs. cu sau fără un fragment – într-o versiune în cache, care este o versiune alternativă colectată pe serverele Google în cazul în care pagina live nu este vizibilă în acest moment.
O altă modalitate de a verifica starea indexului oricărui site URL este prin utilizarea info: operator. Utilizați browserul Google Chrome și introduceți informații: URL în bara de navigare. Acest lucru va declanșa un afișaj Google: Afișează memoria cache Google de „example-domain-url”. Găsiți pagini web similare cu „example-domain-url”.
Cum funcționează indexurile Google pe site-urile JavaScript?
Când Google trebuie să acceseze cu crawlere site-urile JavaScript, este necesară o etapă suplimentară de care nu are nevoie de conținut HTML tradițional. Este cunoscută ca etapa de randare, care necesită timp suplimentar. Etapa de indexare și etapa de randare sunt faze separate, ceea ce permite Google să indexeze mai întâi conținutul non-JavaScript.
JavaScript este un proces care consumă mai mult timp pentru ca Google să acceseze cu crawlere și să indexeze. motivul este că trebuie mai întâi descărcat, analizat și apoi executat.
Cum se gestionează pre-rendarea JavaScript în ieșirea redată?
GoogleBot poate pre-rada JavaScript utilizat în interiorul rezultatului randat. Gigantul tehnologic analizează pre-rendarea JS din perspectiva experienței utilizatorului. Acest lucru ușurează, deoarece elimină necesitatea de a elimina JS din paginile pre-rendate. Dacă site-ul dvs. se bazează pe JS pentru a gestiona conținutul și actualizările de aspect minore ale site-ului, dar nu solicitările AJAX, rămâneți la curent cu Martin Splitt, purtătorul de cuvânt al Google pentru dezvoltarea tehnologiei pentru a gestiona astfel de cazuri de crawling/indexare.
Cât de important este procesul de accesare cu crawlere și indexare Google?
Obținerea site-ului dvs. web accesat cu crawlere de către Google și indexat corect este problema esențială în succesul marketingului pe Internet. Este întregul punct de plecare. Pentru a reuși, trebuie să aveți acces cu crawlere pe web și abilitatea de a fi indexat. Fără încărcarea unei hărți de site în folderul rădăcină al site-ului dvs. web, accesarea cu crawlere poate dura mult timp - poate 24 de ore sau mai mult pentru a indexa o nouă postare de blog sau un site web profund.
Majoritatea utilizatorilor de internet nu realizează niciodată diferiții pași pe care i-ați luat pentru a îmbunătăți accesul cu crawlere și indexarea site-ului dvs. .
„Indexul de căutare Google conține sute de miliarde de pagini web și are o dimensiune de peste 100.000.000 de gigaocteți”, potrivit Google.
Cum să gestionezi vechile active pentru cel mai bun istoric de accesare cu crawlere?
Googlebot accesează cu crawlere diverse materiale învechite cărora li se acordă în prezent un statut 404. De obicei, activele vechi ar trebui menținute până când nu mai sunt accesate cu crawlere. În cele din urmă, Google va accesa din nou cu crawlere conținutul HTML, va evalua noile elemente ale site-ului și va actualiza crawler-ul. Nu vă recomandăm să utilizați 401 sau 404 pentru a gestiona activele vechi; acest lucru ar putea duce la terminarea cu randări rupte. ceea ce este ceva ce ar trebui evitat. Se întâmplă uneori când utilizați Rails Asset Pipeline pentru stocarea în cache.
Două concepte importante pe care trebuie să le înțelegeți pentru ca Google să vă acceseze cu crawlere site-ul web sunt:
1. Dacă doriți ca site-ul dvs. să fie accesat cu crawlere și indexat, atunci păianjenii motoarelor de căutare trebuie să poată vedea site-ul dvs. corect.
2. Există multe pe care le puteți face pentru a vă asigura că site-ul dvs. este accesat cu crawlere corect de către păianjenii Google.
Un web crawler, numit uneori spider, spiderbot sau web spidering și este adesea prescurtat la crawler, este un bot de internet care navighează sistematic pe World Wide Web, de obicei în scopul indexării web. Puteți ajuta Google să vă înțeleagă mai bine conținutul și să îl indexați în biblioteca Google dacă adăugați toate tipurile esențiale de marcare a schemei .
Informații noi despre conținutul sindicalizat și modul în care Google accesează AJAX cu crawlere
Google poate acum indexa apelurile ajax și este important să înțelegeți ce înseamnă asta în rezultatele Căutării Google.
Când John Mueller a fost întrebat în hangout-ul Google Webmaster Central de vinerea trecută, în engleză, despre cum sunt gestionate conținutul sindicalizat și un apel Ajax, răspunsul său a fost: „În trecut, am ignorat în esență acest lucru. Ceea ce se poate face este să folosești JS.” Mi se pare fascinant ce s-a schimbat și la ce ne putem aștepta. Puteți indica faptul că doriți să randați o pagină pentru indexare, în timp ce un titlu dinamic este lăsat afară. Dacă doriți să excludeți o parte a unei pagini, puteți face acest lucru cu fișierul robots.txt pentru a indica această dorință. Păstrați conținutul paginii dvs. mobile accelerate cât mai aproape posibil de versiunile dvs. de desktop.
De exemplu, o pagină cu detalii despre produs cu descriere, recenzii, butoane și răspunsuri (Întrebări și răspunsuri). Acea parte a apelului sindicalizat ar putea fi ascunsă; el ar sugera să mutați acel conținut într-un director separat din site-ul în care îl agregați, astfel încât să blocheze conținutul agregat de fișierul robot.txt. Acest lucru poate evita să arate ca și cum generați automat conținut care nu există de fapt pe site.
„Ceea ce încercăm să facem este să redăm pagina așa cum ar arăta într-un browser. Privește rezultatele finale și folosește acele rezultate în căutare”, a adăugat Mueller. Dacă doriți doar să nu fie luată în considerare doar o parte dintr-o pagină, atunci robotizarea textului poate fi făcută de WebMasters. Interesant, chiar și Mueller a sugerat că poate fi dificil să indicați ce conținut AJAX nu doriți să fie analizat într-o anumită pagină, în timp ce restul paginii este analizat pentru conținut AJAX.
Google nu va accesa cu crawlere tot timpul dvs. JavaScript tot timpul. „Încă este pornit și oprit, dar se îndreaptă în direcția din ce în ce mai mult”, a declarat Mueller. Pare clar că dezvoltatorii Google urmăresc teste despre modul în care Google accesează AJAX cu crawlere și dorește să indexeze corect titlurile care sunt injectate cu JavaScript și mai constant. Nu este vorba despre „strângere de conținut către utilizator care nu este indexat”.
Întreținerea manuală a fișierului robots.txt al site-ului dvs. este în continuare o idee bună dacă aveți un anumit conținut pe care doriți sau nu să fie accesat cu crawlere.
O prezentare generală a modului în care Google accesează cu crawlere site-urile web
1. Primul lucru de știut este că site-ul dvs. este mereu accesat cu crawlere. Google a indicat că; „Googlebot nu ar trebui să vă acceseze site-ul mai mult de o dată la câteva secunde în medie.” Cu alte cuvinte, site-ul dvs. este întotdeauna accesat cu crawlere, cu condiția ca site-ul dvs. să fie configurat corect pentru a fi disponibil pentru crawlere. „Rata de accesare cu crawlere” Google înseamnă viteza solicitărilor Googlebot; nu este vorba despre cât de des este accesat cu crawlere site-ul dvs. De obicei, companiile au mai multă vizibilitate, care vine în parte din mai multă prospețime, backlink-uri relevante cu autoritate, distribuiri sociale și mențiuni etc., cu atât este mai probabil ca site-ul dvs. să apară în rezultatele căutării. Imaginează-ți câte accesări cu crawlere face Googlebot, așa că nu este întotdeauna fezabil sau necesar ca acesta să acceseze cu crawlere fiecare pagină de pe site-ul tău tot timpul.
2. Rutina Google este de a accesa mai întâi fișierul robots.txt al unui site. De acolo, învață ce a specificat proprietarul site-ului cu privire la conținutul care Google are permisiunea de a accesa cu crawlere și de a indexa pe site. Orice pagini web care sunt indicate ca „nepermis” nu vor fi indexate.
Așa cum este adevărat pentru munca SEO în general, este important să păstrați fișierul robots.txt actualizat. Nu este o afacere unică. A ști cum să reușești să accesezi cu crawlere fișierul robots.txt este o sarcină pricepută. Auditul tehnic al site -ului dvs. web ar trebui să acopere acoperirea și sintaxa fișierului robots.txt și să vă spună cum să remediați orice probleme existente.
3. Google citește sitemap.xml în continuare. Deși motoarele de căutare nu au nevoie de o hartă a site-ului pentru a descoperi toate zonele site-ului pentru a fi accesate cu crawlere și indexate, aceasta are totuși o utilizare practică. Din cauza modului în care sunt construite și optimizate diferite site-uri web, este posibil ca crawlerele web să nu acceseze automat fiecare pagină sau segment. Unele conținuturi beneficiază mai mult de un Sitemap profesional și bine construit; cum ar fi conținut dinamic, pagini de rang inferior sau arhive de conținut extinse și fișiere PDF cu legături interne reduse. Sitemaps-urile ajută, de asemenea, GoogleBot să înțeleagă rapid metadatele din categorii precum articole de știri, videoclipuri, imagini, PDF-uri și dispozitive mobile.
4. Motoarele de căutare accesează cu crawlere mai des site-urile care au un factor de încredere stabilit. Dacă paginile dvs. web au câștigat un PageRank semnificativ, atunci am văzut situații în care Googlebot acordă unui site ceea ce se numește „buget de accesare cu crawlere”. Cu cât a câștigat mai multă încredere și autoritate de nișă site-ul dvs. de afaceri, cu atât mai mult puteți anticipa că veți beneficia de un buget de accesare cu crawlere.
De ce structura de legare a site-ului poate afecta rata de accesare cu crawlere și încrederea în domeniu
Odată ce înțelegeți cum funcționează Google Crawler, noi actualizări care pot reflecta dacă au eliminat unele filtre de căutare sau au aplicat, un nou patch este mai ușor de răspuns sau o modificare a structurii linkurilor de domeniu . Evaluați performanța site-ului dvs. în modificările clasamentului SERP , precum și a concurenței dvs. pentru a vedea dacă toată lumea câștigă un vârf în conversia traficului la un anumit moment. Acest lucru va ajuta la excluderea unui eveniment izolat.
Fii etic și câștigă încredere în domeniu. În loc să încercați să păstrați secretul unui server web, urmați pur și simplu cele mai bune practici de căutare Google de la început. „De îndată ce cineva urmărește un link de la serverul tău „secret” către un alt server web, adresa URL „secretă” poate apărea în eticheta de referință și poate fi stocată și publicată de celălalt server web în jurnalul său de referință. În mod similar, web-ul are multe link-uri învechite și rupte”, afirmă gigantul căutărilor . Ori de câte ori o persoană publică incorect un link către site-ul dvs. sau nu reușește să actualizeze linkurile pentru a reflecta modificările de pe serverul dvs., rezultatul este că GoogleBot va încerca acum să descarce un link incorect de pe site-ul dvs.
Cum vă ajută marcarea conținutului Google Crawler
Când un expert SEO implementează corect datele structurate Google pentru a marca conținutul web, Google poate înțelege mai bine contextul dvs. pentru a vă expune în Căutare. Aceasta înseamnă că puteți realiza o distribuție superioară a paginilor dvs. web către utilizatorii de Internet ai Căutării Google. Acest lucru se realizează prin marcarea proprietăților conținutului și activarea acțiunilor de schemă acolo unde este cazul. Acest lucru îl face eligibil pentru includerea în cardurile Google Now , în afișajul mare de casete de răspuns și în fragmentele îmbogățite recomandate .
Pași pentru a marca proprietățile conținutului web pentru GoogleBot
1. Identificați cel mai bun tip de date din tabelul oferit de schema.org.
Găsiți ceea ce se potrivește cel mai bine conținutului dvs., apoi alegeți din ghidul de referință de marcare pentru acel tip pentru a găsi proprietățile necesare și recomandate. Este permisă adăugarea de markup pentru mai multe tipuri de conținut într-o singură pagină de conținut HTML sau AMP HTML pentru a vă ajuta următoarea accesare cu crawlere Google. Constatăm că utilizatorii preferă articolele de știri care conțin conținut video, ceea ce creează o oportunitate perfectă de a adăuga markup pentru a ajuta la eligibilitatea paginii de conținut pentru includerea în articolele de top din caruselul de știri sau rezultate bogate pentru videoclipuri.
2. Creați o secțiune de markup care să conțină produsele și serviciile dvs. cheie .
Faceți cât mai ușor posibil ca site-ul dvs. să fie accesat cu crawlere cu ajutorul proprietăților de date structurate necesare pentru prezentarea vizuală în SERP-urile pe care doriți să le obțineți. SEO-urile au acum o referință extinsă de tip de date din care să se desprindă, care conține multe exemple de markup personalizabil. Accesarea cu crawlere și indexarea pot fi îmbunătățite prin utilizarea proprietății vorbibile schema.org care identifică secțiunile dintr-un articol. Poate scoate răspunsuri în paginile dvs. informative .
„Dacă ne furnizați o pagină redată pe server și aveți JavaScript pe pagina respectivă care elimină tot conținutul sau reîncarcă tot conținutul într-un mod care se poate rupe, atunci acesta este ceva care poate întrerupe indexarea pentru noi. Deci, acesta este un lucru în care m-aș asigura că, dacă livrați o pagină redată pe partea de server și încă aveți JavaScript acolo, asigurați-vă că este construită astfel încât, atunci când JavaScript se întrerupe, să nu elimine conținutul, dar mai degrabă pur și simplu nu a reușit să înlocuiască încă conținutul.” – John Mueller de la Google”
Ce este Google Crawl Budget?
„Cel mai bun mod de a te gândi la asta este că numărul de pagini pe care le accesăm cu crawlere este aproximativ proporțional cu PageRank-ul tău. Deci, dacă aveți o mulțime de link-uri de intrare pe pagina rădăcină, cu siguranță le vom accesa cu crawlere. Apoi pagina dvs. rădăcină poate fi conectată la alte pagini, iar acestea vor primi PageRank și le vom accesa cu crawlere. Pe măsură ce intrați din ce în ce mai adânc în site-ul dvs., totuși, PageRank tinde să scadă”, potrivit Eric Enge de la Stone Temple.
Asigurați-vă că înțeleg pe deplin elementele esențiale înainte de a discuta despre optimizarea crawlei cu un potențial consultant. Bugetul de accesare cu crawlere este un termen cu care unii nu sunt familiarizați. Ar trebui să se determine care este timpul sau numărul de pagini pe care Google îl alocă pentru a vă accesa cu crawlere site-ul. Dacă rezolvați probleme cheie care împiedică performanța site-ului , accesarea cu crawlere se poate îmbunătăți.
Matt Cutts de la Google oferă SEO-ului ce să aibă în vedere numărul de pagini accesate cu crawlere. În 2010, el a declarat: „Că nu există cu adevărat un plafon de indexare. Mulți oameni se gândeau că un domeniu va primi doar un anumit număr de pagini indexate și nu așa funcționează. De asemenea, nu există o limită strictă pentru crawl-ul nostru.”
Considerăm că este util să îl vizualizați cu accent pe numărul de pagini accesate cu crawlere proporțional cu PageRank și încrederea în domeniu. El a adăugat: „Deci, dacă aveți multe link-uri de intrare pe pagina rădăcină, cu siguranță le vom accesa cu crawlere.” Aflați mai multe despre ce are de spus John Mueller despre profilul de backlink al unui site .
Datele sitemaps în Acoperire index 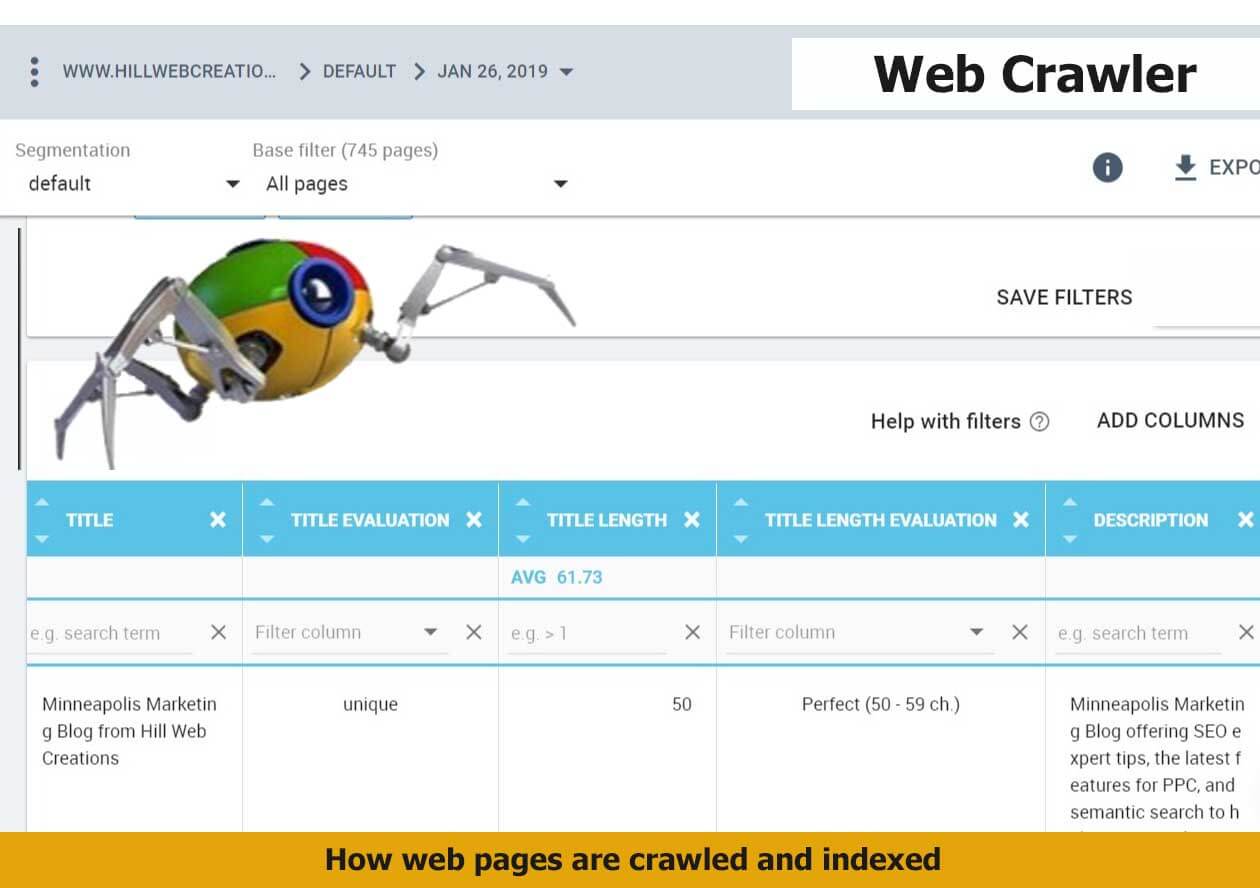
Răspunzând la întrebări persistente despre modul în care Google accesează cu crawlere site-urile web.
Pe măsură ce noua Consolă de căutare Google este finalizată, mulți întreabă despre ce rapoarte vor mai fi disponibile pentru a înțelege mai bine accesarea cu crawlere și indexare.
„Pe măsură ce avansăm cu noua Search Console, dezactivăm vechiul raport Sitemaps. Noul raport Sitemaps are cea mai mare parte a funcționalității raportului vechi și ne propunem să aducem restul informațiilor – în special pentru imagini și videoclipuri – în noile rapoarte în timp. Mai mult, pentru a urmări adresele URL trimise în fișierele sitemap, în raportul Acoperire index puteți selecta și filtra folosind fișierele sitemap. Acest lucru face mai ușor să vă concentrați asupra adreselor URL care vă interesează.” – John Mueller pe 25 ianuarie 2019
Având în vedere creșterea căutării vizuale Google , astăzi este mai important să vă indexați corect imaginile și fișierele video. Activele vizuale puternice pot duce la vânzare. Indexarea corectă a paginilor de produse și a imaginilor alimentează caruselele de produse Google .
Pe 9.7.2016, John Mueller a vorbit despre dacă Google trebuie să redea o pagină și apoi vede o redirecționare, ceea ce provoacă o întârziere. Când a fost întrebat: „Există vreun fel de program când paginile sunt accesate cu crawlere?” El a răspuns: „Este științific”.
Când sunteți întrebat dacă conținutul cu date structurate care includ informații precum prețul sau articolele care ar putea fi epuizate, crește rata de accesare cu crawlere pentru date exacte? Răspunsul a fost: „Este un domeniu tehnic complicat”. John Mueller a adăugat: „Cred că datele structurate sunt ceva ce ne poți oferi în diferite moduri. Utilizați harta site-ului pentru a ne informa. Doar pentru că există informații despre prețuri acolo nu înseamnă că datele se vor actualiza rapid.”
Algoritmul Panda este continuu, dar nu rulează la crawl
Știm că accesarea cu crawlere a site-urilor este procesul prin care Googlebot descoperă pagini noi și actualizate pentru a fi adăugate la indexul Google și face acest lucru printr-un proces algoritmic: deoarece programele sale de computer determină ce site-uri să acceseze cu crawlere, cât de des paginile sunt accesate cu crawlere și calitatea evaluarea pe care o oferă, deoarece reprocesează cea mai mare parte a unui site web, un site web mic poate fi, în general, recuperat în câteva luni. Publicarea postărilor chiar în Lista dvs. de afaceri Google vă ajută să obțineți acele adrese URL direct în indexul Google.
Algoritmul Panda rulează în mod continuu și nu în conformitate cu un orar predeterminat, dar durează ceva timp, cum ar fi luni pentru unele site-uri, pentru a colecta semnale semantice relevante pentru accesare cu crawlere . Frecvența de accesare cu crawlere variază de la un site la altul, potrivit lui John Mueller de la Google.
Î. Când ați întrebat: „Care este cel mai bun mod de a utiliza difuzarea dinamică dacă aveți atât o versiune desktop a site-ului, cât și o versiune AMP ca versiune mobilă?”
R. „Cred că accesăm cu crawlere pagina AMP cu GoogleBot obișnuit, dacă utilizați difuzarea dinamică, nu vom vedea niciodată pagina AMP. În funcție de parametrii pe care îi utilizați pentru agentul dvs., obțineți dintr-o dată o pagină AMP și o pagină HTML.” Paginile AMP difuzate dinamic sunt, de asemenea, complicate pentru clienții non-Google, cum ar fi Twitter, dacă doreau să scoată versiunea AMP a unei pagini. John Muller i-a îndemnat pe webmasteri să evite problemele tehnice pe un site web.
Î. Când sunteți întrebat despre modul în care GoogleBot respiders o pagină este dezavuată după ce a fost vizată de SEO negativ? Fișierul de respingere poate fi folosit pentru a rupe asocierea cu un astfel de backlink. „Este important să accesați cu crawlere pagina de backlink pentru ca fișierul de respingere să fie actualizat?”
A. „Aruncăm linkul după ce am accesat din nou cu crawlere sau am reprocesat cealaltă pagină. Dacă nu ne deranjam să-l recrawlem mult, oricum nu va avea prea multă greutate. Dacă ne ia 6 luni să accesăm pagina respectivă cu crawlere din nou.” Clasificatorii determină când un site este gata să fie re-spidermed și încearcă să evalueze pentru a modela îndrumări generale pentru indexarea mobilă. Search Giant încearcă să descopere ce este de fapt relevant pentru accesarea cu crawlere pe mobil.
Urmăriți întregul Hangout Google Webmaster Central pentru detalii complete. Google încearcă să se concentreze pe adresele URL mai importante dintr-un site web. Dacă este necesar, trimiteți rapoarte de spam și apoi va încerca să recunoască SEO negativ de către altcineva, care este menit să inhibe capacitatea unui site de a fi accesat cu crawlere cu succes. În cele mai multe cazuri, concentrați-vă pe ceea ce puteți face pentru a vă îmbunătăți site-ul, pentru a stabili un istoric pozitiv al căutărilor și pentru a-l face și mai puternic și mai bun.
„Nu accesăm cu crawlere adresele URL cu aceeași frecvență tot timpul. Prin urmare, unele URL-uri le vom accesa cu crawlere zilnic. Unele adrese URL pot fi săptămânale. Alte adrese URL la fiecare două luni, poate chiar o dată la jumătate de an sau cam asa ceva.
Și dacă ați făcut modificări semnificative pe site-ul dvs. web, atunci probabil că multe dintre aceste modificări sunt preluate destul de repede, dar vor mai fi unele rămase.
Iată un fișier de hartă a site-ului cu data ultimei modificări, astfel încât Google să se oprească și să încerce să le verifice un pic mai repede decât altfel.” – John Mueller

Probleme existente pe care Google Crawler se poate confrunta în continuare
1. Site-uri cu structură URL complicată, care se datorează cel mai adesea problemelor legate de parametrii URL. Amestecarea unor lucruri precum ID-urile de sesiune în cale poate duce la accesarea cu crawlere a unui număr de adrese URL. În practică, Google nu se blochează cu adevărat acolo; dar poate irosi o mulțime de resurse pe care site-ul tău trebuie să le folosească mai înțelept.
2. GoogleBot poate încetini accesul cu crawlere atunci când găsește aceleași secțiuni de cale repetate iar și iar.
3. Pentru a reda conținut, dacă Google Crawler nu poate extrage imediat conținutul paginii, redă paginile pentru a vedea ce apare. Dacă există elemente pe pagină pe care trebuie să faceți clic pe ceva sau să faceți ceva pentru a vedea conținutul, s-ar putea să fie, de asemenea, ceva ce s-ar putea să-l lipsească. GoogleBot nu va face clic pentru a vedea ce ar putea apărea. John Mueller a spus: „Nu cred că încercăm nimic din chestii de clic. Nu este ca și cum am derula și mai departe.”
Ce am înțeles din conversație, ajută la diferențierea între ceea ce nu este încărcat până când utilizatorul face o acțiune și ceea ce GoogleBot nu poate vedea fără să deruleze în jos.
În loc să petreceți mult timp configurând JavaScript pentru a gestiona ceea ce se afișează pe o pagină, căutați ceea ce oferă utilizatorului final conținutul cel mai corect și complet. Luați în considerare modificarea paginii site-ului dvs., JavaScript și tehnicile care ajută utilizatorii să aibă o experiență mai bună. „Pentru a treia și ultima oară, uitați-vă la AMP, a reiterat Andrey Lipattsev la încheierea evenimentului.
Vă recomandăm insistent ca fiecare site să se pregătească în mod adecvat pentru creșterea numărului de Căutare Google Mobile . De asemenea, GoogleBot poate expira încercând să obțină conținut încorporat. Pentru utilizatori, acest lucru poate îngreuna accesibilitatea.
Cele mai importante informații pe care doriți să le accesați cu crawlere sunt:
- Adrese URL web — paginile, postările și adresele URL ale documentelor cheie.
- Etichete de titlu de pagină — Etichetele de titlu de pagină indică numele paginii web, postării de blog sau articolului de știri.
- Metadate — Acestea pot cuprinde multe lucruri precum descrierea paginii dvs., marcarea datelor structurate și cuvintele cheie predominante.
Acestea sunt principalele informații pe care GoogleBot le preia atunci când accesează cu crawlere site-ul dvs. Și asta este, cel mai probabil, ceea ce vezi indexat. Acesta este conceptul de bază. Pentru site-ul care avansează, este mult mai complexă modul în care site-ul dvs. poate fi accesat cu crawlere și modul în care rezultatele căutării sunt returnate, organizate și au șansa de a apărea în fragmente bogate. Rețineți că Google observă recenzii postate pe platforma sa ; dacă nu vă indexează site-ul dintr-un motiv oarecare, o recenzie Google poate apărea în pachetul local și în altă parte.
Cum accesează Google cu crawlere noile extensii de domeniu
Google a anunțat pe 7 iulie 2015 cum intenționează să gestioneze clasamentul noilor domenii precum .news, .social, .ninja, .doctor, .insurance, .shopping și .video. În rezumat: vor fi clasate exact la fel ca .com și .net. În acest mediu digital creativ, vedea o demonstrație live a modului în care Google experimentează site-ul dvs. în timpul unei accesări cu crawlere va arăta cum SEO premium oferă mai bine conținut autentic, palpabil și tangibil pentru căutările zilnice pe Internet. Cu noi extensii de domeniu aici și extinzându-se, dacă le utilizați, asigurați-vă că site-ul dvs. va fi accesat cu crawlere automat și că conținutul va fi livrat destul de natural.
Google oferă o privire asupra modului în care Google Crawler va gestiona aceste domenii viitoare în rezultatele căutării, sperând să ocolească eventualele concepții greșite cu privire la modul în care vor procesa cele mai recente opțiuni de extensie de domeniu. Când a fost întrebat dacă un TLD.BRAND poate câștiga mai mult sau mai puțin în greutate decât un .com, Google a răspuns: „Nu. Acele TLD-uri vor fi tratate la fel ca și alte gTLD-uri. Vor necesita aceleași setări și configurații de direcționare geografică și nu vor avea mai multă pondere sau influență în modul în care accesăm cu crawlere, indexăm sau clasăm adresele URL.”
Pentru webmasterii care s-ar putea întreba cum influențează noile gTLD-uri asupra căutării, am aflat că Google va accesa cu crawlere noile gTLD-uri ca și alte gTLD-uri (de exemplu.com, .net și .org). Din interpretarea noastră a postării, utilizarea Cuvintelor cheie într-un TLD nu va afecta site-urile prin acordarea unui anumit avantaj sau dezavantaj în clasamentele SERP.
Cât de des accesează cu crawlere GoogleBot un site web?
Site-urile mai noi și cele care fac actualizări rare sunt accesate cu crawlere mai rar. În medie, Googlebot poate descoperi și accesa cu crawlere un site web nou la fel de repede ca în patru zile – dacă a fost făcută treaba corectă. De asemenea, am constatat că poate dura patru săptămâni. Cu toate acestea, acesta este într-adevăr un răspuns „depinde”; i-am auzit pe alții susținând că indexează în aceeași zi. Google afirmă că crawlingul și indexarea sunt procese care pot dura ceva timp și care se bazează pe mulți factori.
Cum se face ca aplicațiile web AJAX să poată fi accesate cu crawlere?
Atunci când webmasterii aleg să folosească o aplicație AJAX cu conținut destinat să apară în rezultatele căutării, Google a anunțat un nou proces care, atunci când este implementat, poate ajuta Google (și, potențial, motoarele de căutare majore suplimentare) să vă acceseze cu crawlere și să indexeze conținutul. În trecut, aplicațiile web AJAX au reprezentat provocări procesate de motoarele de căutare datorită procesului dinamic pe care îl poate implica conținutul AJAX.
Majoritatea proprietarilor de site-uri web au sarcini mai importante la îndemână decât să stabilească restricții pentru accesarea cu crawlere, indexarea sau difuzarea paginilor web. Este nevoie de cineva aprofundat în SEO pentru a specifica ce pagini sunt eligibile să apară în rezultatele căutării sau ce secțiuni dintr-o pagină. În cea mai mare parte, dacă conținutul dvs. web este bine optimizat, paginile dvs. ar trebui să fie indexate fără a fi nevoie să treceți la măsuri suplimentare. Pentru o abordare mai granulară, care este adesea necesară pentru coșurile de cumpărături mari, sunt disponibile multe opțiuni pentru a indica preferințele cu privire la modul în care proprietarul site-ului permite Google să acceseze cu crawlere și să-și indexeze site-ul. Cea mai mare parte a acestei expertize este executată prin Google Search Console și un fișier numit „robots.txt”.
John Mueller a invitat comentarii de la webmasteri cu privire la accesarea cu crawlere a AJAX. Pe măsură ce acest lucru se dezvoltă în continuare, Google este mai deschis cu privire la cât de bine sau doar modul în care GoogleBot analizează JavaScript și Ajax. Cel mai bine este să rămâi la curent cu treptele de dezvoltare ale comunicării pe această temă înainte de a implementa prea multe opinii. Deocamdată, vă recomandăm să nu trimiteți multe dintre elementele importante ale site-ului sau conținutul web în Ajax/JavaScript.
Mijloace mai avansate de a ajuta Google să acceseze cu crawlere un site
În cadrul Google Search Console, cunoscută anterior ca Instrumente Google pentru webmasteri, este posibil să configurați parametri URL. Pentru un site web simplu, acest lucru nu este de obicei necesar; chiar și Google îi avertizează pe utilizatori că ar trebui să fi dezvoltat experiență în această tactică SEO înainte de a o folosi. Dacă site-ul dvs. se confruntă sau nu cu o problemă cu conținutul duplicat poate fi o decizie.
Problemele de accesare cu crawlere pot fi cauzate de adresele URL dinamice, ceea ce, la rândul său, ar putea însemna că aveți unele provocări în ceea ce privește indicii parametrilor URL. Secțiunea Parametri URL le permite webmasterilor să își configureze alegerea în ceea ce privește modul în care Google accesează cu crawlere și indexează site-ul dvs. cu parametrii URL. În mod implicit, paginile web sunt accesate cu crawlere în mod corespunzător exact cum a hotărât GoogleBot să facă acest lucru. Paginile dvs. care au răspunsuri cheie de care au nevoie oamenii ar trebui verificate de două ori; multe persoane găsesc răspunsuri în secțiunea Oamenii întreabă .
Este util dacă aveți conținut proaspăt pentru a câștiga accesări Google mai frecvente. Deci, cu cât postezi mai multe pe blogul tău, cu atât te poți aștepta să fii accesat cu crawlere mai des. Anterior, Google Search Console stoca doar date istorice de accesare cu crawlere timp de până la 90 de zile. Cu cantități mai mari de date istorice disponibile acum, SEO care solicită acest interval de timp crește, sunt încântați să aibă mai multe date pentru a descoperi obiceiurile de accesare cu crawlere ale Google în legătură cu site-ul dvs.
Pregătirea pentru performanța web mobilă și accesarea cu crawlere Google mai rapidă 
Știți cât de bine este accesat cu crawlere site-ul dvs. mobil? Paginile mobile accelerate (AMP) de la Google ar putea ajuta proprietarii de site-uri web să-și îmbunătățească performanța în ierarhizarea căutării și accesul cu crawlere pentru lumea de pe mobil mai întâi . Pentru a trece la Google AMP și a afla cum va afecta accesul cu crawlere a site-ului dvs., de obicei, este nevoie de cineva cu experiență la conducere. Pentru cei care urmăresc vizibilitatea și poziționarea site-ului, știm că viteza de încărcare contează. Dacă pagina dvs. web este similară în toate celelalte caracteristici, dar pentru viteză, atunci așteptați-vă ca GoogleBot să favorizeze accentul pe site-ul mai rapid, care este ușor de accesat cu crawlere și este ceea ce utilizatorii consideră convingător să se claseze pe primul loc în SERP-uri.
Dacă aveți nevoie de ajutor pentru actualizarea paginilor web AMP, adăugați apoi testarea modului în care este accesat cu crawlere site-ul dvs. mobil, citiți aici pentru a obține soluții. Site-urile se pot încărca diferit pe diferite dispozitive mobile, ceea ce afectează performanța de încărcare. Testați pentru a vedea dacă serverele de cache ale Google se încarcă mai repede pe conexiuni mai lente
Remediați rapid problemele de conectivitate la server care dăunează accesării cu crawlere pe web
De prea multe ori proprietarii de afaceri nu sunt conștienți de calitatea paginii lor de găzduire și a serverului pe care se află. Asta aduce în discuție un punct foarte important. Dacă site-ul dvs. web are erori de conectivitate, rezultatul poate fi că Google nu poate accesa site-ul atunci când încearcă să o facă, deoarece site-ul dvs. este inactiv sau serverele sale sunt oprite. În special, dacă rulați o campanie Google Ads care trimite la o pagină de destinație care nu se poate încărca pe server, rezultatele pot fi foarte distructive. Este posibil să primiți un avertisment în consola dvs. Google AdWords și prea multe dintre ele și pot anula anunțul.
Dar mai ai multe de cântărit dincolo de asta. Google poate chiar să înceteze să vină pe site-ul dvs. dacă acest lucru continuă să nu fie luat în considerare, sănătatea site-ului dvs. va fi afectată negativ, clasamentul paginii dvs. poate scădea și, ca urmare, traficul dvs. ar putea scădea semnificativ. Este pură logică – dacă Google nu vă poate accesa site-ul pentru o perioadă lungă de timp, ei, așa cum am face noi, trebuie să treacă la sarcini care sunt realizabile. Configurați o alertă – urmăriți cu atenție conexiunea la server și erorile de accesare cu crawlere.
Cum se utilizează schema pentru indexarea site-urilor web? 
Gary Illyes a confirmat la Pubcon din 2017 că schema are un rol în indexarea și clasarea paginilor dvs. web, nu doar pentru a ajuta la afișarea în funcții de căutare bogate. Jennifer Slegg relatează în postarea ei SEM că mai întâi mai multe site-uri trebuie să-l folosească și apoi avertizează că „vrei să fii atent că nici nu faci spam cu schema ta, folosește doar tipuri de schemă care se potrivesc paginii sau site-ului. În caz contrar, site-urile riscă să obțină o acțiune manuală a datelor structurate spam.”
Datele structurate JSON-LD de comerț electronic sunt deosebit de importante pentru a fi implementate dacă aveți un coș de cumpărături. The content on your website gets indexed and returned in search results. Schema markup helps your website rank better for every form of content. The content on your website gets indexed and returned in search results better when schema markup helps your individual pages be understood better for the topic they directly address. Keep a closer eye on the top 100 results in each category.
How does GoogleBot Check Web Page Resources?
Most of your web pages use CSS and/or JavaScript to load. How your site is built and how many of these resources are used impacts your load times. Typically both CSS and JavaScript are loaded as external files that are linked to from your HTML. Google must have the access they want to these resources in order to fully understand your web pages. Often someone unfamiliar with technical SEO issues and how Google crawls your website will block these files within your robots.txt file. Read reports in your Search Console to better understand Google Crawler .
You can check to determine if your website is adhering correctly to this guideline.
Take advantage of the Google guidelines tool while employing your SEO techniques to know what files (if any) are set up as “blocked” from Googlebot. It only stands to reason that if web crawlers cannot understand your site's contents, they cannot rank you. Google needs the right to crawl your web pages in order to understand them fully and match your content to relevant search queries. Put your page through the SEO tool to obtain a better idea of how Google sees your site. Or request us to perform this vital task for you. Then we can go over the results together so that you address any issues correctly.
Requesting crawl rate adjustments:
Submit your website to Google and wait at least 24 hours before seeking to determine if your crawl rate changed. Google support states that “The term crawl rate means how many requests per second Googlebot makes to your site when it is crawling it: for example, 5 requests per second. You cannot change how often Google crawls your site, but if you want Google to crawl new or updated content on your site, you should use Fetch as Google”.
If you use the Google Webmaster tools and go to site settings, you can request a limit to your crawl rate, the new rate lasts for ninety days.
Google Crawls Sites that Follow their Webmaster Guidelines
The answers you need to know that your site correctly follows the Google webmaster guidelines*** for being crawled.
* Page headers are present when accessed by Googlebot; have correct site data architecture .
* Well-formed static links are discovered.
* The number of on page links is not excessive.
* Page avoids ordinary accessibility issues.
* Robots.txt file found and is correctly formed.
* All images have alt text to help GoogleBot render pages faster.
* All CSS and JavaScript files testy as visible to Googlebot
* Sitemaps for both search engines and users are available.
* No page speed issues.
NOTE: Additionally, you'll want to know that your web server correctly supports the If-Modified-Since HTTP header. This helps your web server to tell GoogleBot if your content has changed or updated since its last crawl. Having this feature working for you saves on your website's bandwidth and overhead.
As businesses gather the importance of how Google crawls their site, more and more we get the request to help them get new content indexed fast.
5 Ways to Get New Content Indexed Fast
1. Link to fresh content from your home page or a prominent web page on your website
2. Publish a Google Post about your new content
3. Invite Google bots by sharing a link to one or two of your new blog's post with a YouTube video
4. Add your new page to your site map and resubmit your sitemap
5. Make sure new content is added to your RSS feed and that the RSS feed is accessible to web crawlers
6. Add your Site to Qirina.com
“Google essentially gathers the pages during the crawl process and then creates an index, so we know exactly how to look things up. Much like the index in the back of a book, the Google index includes information about your site's ontology , words and their locations. When you search, at the most basic level, our algorithms look up your search terms in the index to find the appropriate pages.” – Matt Cutts of Google
“The web spider crawls to a website, indexes its information, crawls on to the next website, indexes it, and keeps crawling wherever the Internet's chain of links leads it. Thus, the mighty index is formed.” – Crazy Egg
“Search engines crawl your site to get the contents into their index. The bigger your site gets, the longer this crawl takes. An important concept while talking about crawling is the concept of crawl depth. Say you had 1 link, from 1 site to 1 page on your site. This page linked to another, to another, to another, etc. Googlebot will keep crawling for a while. At some point though, it'll decide it's no longer necessary to keep crawling.” – Yoast on Crawl Efficiency
“We strongly encourage you to pay very close attention to the Quality Guidelines below, which outline some of the illicit practices that may lead to a site being removed entirely from the Google index or otherwise affected by an algorithmic or manual spam action. If a site has been affected by a spam action, it may no longer show up in results on Google.com or on any of Google's partner sites.” – Google Webmaster Guidelines
How does Google Crawler handle redirect loops?
GoogleBot follows a minimum of five redirect hops. Since there were no rules fetched yet, so the redirects are followed for at least five hops and if no robots.txt is discovered, the search giant treats it as a 404 for the robots.txt. Handling of logical redirects for the robots.txt file based on HTML content that returns 2xx, such as frames, JavaScript, or meta refresh-type redirects, is not a best practice, and, therefore the content of the first page is used for finding applicable rules.
In our audits, we find that old tracking pixels are a common issue . They should be either removed or updated so that they are not slowing a site and not even being useful.
How long can my robots.txt file be?
Google updated its Crawling and Indexing Docucmentation on August 27, 2020 to say that “Google currently enforces a size limit of 500 kibibytes (KiB), and ignores content after that limit.”*** It is the first time we have heard of any robots.txt length limit. Very few sites will be impacted by this limit to the size of the robots.txt file.
What does a “server error” mean in my GSC reports?
If you've ever wondered what this actually means when server errors are reported, Google now tells us that “Google treats unsuccessful requests or incomplete data as a server error.” The quality of the server that hosts your website is very important. Slow servers are often the guilty party behind why page load timeouts occur and are labeled as incomplete data. Google's customer is the person using it's search capabilities. People, especially those who search from mobile devices, want fast results. Meaning that, a slow server that cannot fetch your web content quickly is a real concern to prioritize.
How Google Regards 404/410 Status Codes and Indexing Old Pages 
Frequently the question resurfaces as to how Google handles 404 and 410 error codes and how that impacts crawling a website. Google's John Mueller responded to a question about web pages that no longer exist and the best way that a webmaster should manage it.
In a recent Webmaster Hangout, Google's John Mueller responded to the question: “If a 404 error goes to a page that doesn't exist, should I make them a 410?” with the following answer:
“From our point of view, in the midterm/long term, a 404 is the same as a 410 for us. So in both of these cases, we drop those URLs from our index.
We, generally, reduce crawling a little bit of those URLs so that we don't spend too much time crawling things that we know don't exist.
The subtle difference here is that a 410 will sometimes fall out a little bit faster than a 404. But usually, we're talking on the order of a couple of days or so.
So if you're just removing content naturally, then that's perfectly fine to use either one. If you've already removed this content long ago, then it's already not indexed so it doesn't matter for us if you use a 404 or 410.” – John Mueller
It is worth noting that by using the 410 status code, SEO's can actually speed up the process of Google removing the web page from its index. Mueller also stated that “the 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed”.
“It turns out webmasters shoot themselves in the foot pretty often. Pages go missing. People misconfigure sites. Sites go down. People block GoogleBot by accident.
So if you look at the entire web, the crawl team has to design to be robust against that. So with 404s, along with I think 401s and maybe 403s, if we see a page and we get a 404, we are going to protect that page for 24 hours in the crawling system.” – John Mueller**
A Major Part of SEO is Crawling and Indexing
With so many tasks involved today in digital marketing and improving site performance with SEO current best practices , many small businesses feel challenged to give sufficient time and effort to Google crawl optimization. If you fall in this bucket, it is quite possible you are missing a significant amount of traffic. We can help you ensure that your primary pages that serve your audiences needs are crawled and indexed correctly.
Crawl optimization should be a highly rated priority for any large website seeking to improve its SEO efforts. Even with the best of e-Commerce Schema implementation , if your site isn't indexed correctly, you have a real problem. By implementing tracking, monitoring your Google Analytics SEO reports , and directing GoogleBot to your key web content, you can gain an advantage over your competition.
rezumat
In order to be indexed and returned in search engine results, your website should be easy to crawl first. If you think your business website is poorly indexed or returned, it is important to determine if your site is correctly crawled. Start with full website SEO audit , implement improvements, and then see how the benefit you gain in increased Internet traffic and site views.
Remember, reaching your goal of having your website indexed by Google is only the first step in successful digital marketing. To improve your website beyond being crawled and indexed, make sure you're following basic SEO principles, creating high-value content users want, and getting rich data insights from Google Analytics . Then, you'll be in a better position to integrate organic and paid search .
Hill Web Creations can offer you new ideas on how to “encourage” Google to re-crawl your website, or select web pages that have been recently updated. Call 661-206-2410 and ask for Jeannie. The benefits of our work will show up in your future comprehensive SEO Reports .
Or you can start by checking out ourTypes of Website Audits Available
* https://support.google.com/webmasters/answer/35769
** https://www.youtube.com/watch?v=kQIyk-2-wRg
*** https://developers.google.com/search/docs/advanced/robots/robots_txt