
Google이 웹사이트 및 색인을 크롤링하는 방법
게시 됨: 2016-02-18Google이 웹사이트의 AMP 페이지, JavaScript 및 AJAX를 크롤링하는 방법
최종 업데이트: 2021년 3월 6일
Google이 Ajax 콘텐츠를 "크롤링"하는 방법의 거대한 "진보"입니다! Google은 JavaScript 및 AJAX 내에서 콘텐츠를 크롤링하는 데 있어 세계 최고입니다. 그러나 그들은 여전히 완벽합니다. 귀하의 사이트가 크롤링되는 전쟁터라고 생각하십니까?
Google은 웹 콘텐츠에 대한 AJAX 호출을 처리하는 방식을 변경했습니다. Google의 John Mueller는 검색 전문가가 콘텐츠의 크롤링 의도를 Google에 알리기 위해 참여할 수 있는 추가 SEO 전술이 있으므로 "켜기 및 끄기"가 가능하다고 말했습니다. 앞으로는 예전 방식에 의존하지 않는 것이 좋습니다. 민첩한 마케팅 프로세스 를 마련하면 변경 사항을 더 빠르게 탐색하는 데 도움이 됩니다.
Google Search Console에서 발견한 인사이트를 활용 하고 이 문서의 답변과 설명을 통해 이를 읽고 해석하는 방법을 더 잘 알 수 있습니다. 핵심 성능 보고서에 PageSpeed 문제가 나와 있습니다 .
Google 크롤링 및 색인 생성이란 무엇입니까?
크롤링과 인덱싱은 별개의 작업으로 남아 있습니다. 크롤링은 Googlebot이 웹페이지의 모든 콘텐츠와 코드를 보고 분석하는 것입니다. 인덱싱은 동일한 페이지가 Google 검색 결과에 포함될 수 있고 표시될 수 있는 경우입니다. Google Panda 업데이트 이후 도메인 이름의 중요성이 크게 높아졌습니다. 온라인 세계에서 귀하의 비즈니스 성장은 웹 페이지가 올바르게 크롤링되고 인덱싱되는지에 달려 있습니다.
일부 기업은 훌륭한 콘텐츠를 만들고 사이트를 최적화하는 모든 작업을 수행하지만 주요 콘텐츠의 색인을 생성하지 못합니다. 그렇기 때문에 비즈니스 계획 세션 및 전략에서 이를 미리 고려하는 것이 좋습니다.
구글봇이란?
Googlebot은 Google에서 사용하는 검색 봇 소프트웨어로, 웹에서 문서를 수집하여 Google 검색 엔진에 대한 검색 가능한 색인을 구축합니다.
획득 검색 또는 유료 검색을 위한 Google Crawler의 방법을 배우고자 하는 경우 SEO는 GoogleBot에 대한 올바른 이해를 통해 검색 전술을 개선 할 수 있습니다.
GoogleBot은 웹페이지를 크롤링하고 색인을 생성하는 Google 검색 엔진의 일부입니다. 거미라고도 합니다. GoogleBot은 기계 학습을 사용하여 액세스를 허용한 모든 페이지를 크롤링 하고 사용자의 검색어와 일치하도록 검색 및 반환할 수 있는 Google 색인에 추가합니다. 웹사이트에서 크롤링하려는 페이지와 그렇지 않은 페이지를 Google에 명확하게 나타내려는 노력도 전투처럼 보일 수 있습니다.
내 사이트가 Google 색인에 있는지 어떻게 알 수 있습니까?
Google Search Console의 Google 색인 정보 보고서는 속성의 URL을 테스트합니다. URL 검사 도구는 URL의 현재 색인 상태를 표시합니다. 전체 URL을 입력하여 검사하고 색인 상태 보고서를 받아야 합니다.
Fetch as Google 도구를 사용하여 Google에서 크롤링할 때 사이트가 어떻게 보이는지 확인할 수 있습니다. 이를 통해 사이트 소유자는 보다 세분화된 옵션을 활용하고 페이지별 상태에서 콘텐츠를 색인화하는 방법을 선택할 수 있습니다. 한 가지 예는 현재 라이브 페이지를 볼 수 없는 경우에 대비하여 Google 서버에서 수집되는 대체 버전인 캐시된 버전에서 스니펫이 있거나 없이 페이지가 어떻게 나타나는지 확인할 수 있는 기능입니다.
사이트 URL의 색인 상태를 확인하는 또 다른 방법은 info: operator를 사용하는 것입니다. Google Chrome 브라우저를 사용하고 탐색 모음에 info: URL을 입력합니다. 그러면 Google 디스플레이가 실행됩니다. Google의 "example-domain-url" 캐시를 표시합니다. "example-domain-url"과 유사한 웹 페이지를 찾습니다.
Google 색인은 JavaScript 사이트에서 어떻게 작동합니까?
Google이 JavaScript 사이트를 크롤링해야 하는 경우 기존 HTML 콘텐츠에는 필요하지 않은 추가 단계가 필요합니다. 추가 시간이 소요되는 렌더링 단계라고 합니다. 인덱싱 단계와 렌더링 단계는 별도의 단계이므로 Google에서 자바스크립트가 아닌 콘텐츠를 먼저 인덱싱할 수 있습니다.
JavaScript는 Google이 크롤링하고 색인을 생성하는 데 더 많은 시간이 소요되는 프로세스입니다. 그 이유는 먼저 다운로드하고 구문 분석한 다음 실행해야 하기 때문입니다.
JavaScript 사전 렌더링은 렌더링된 출력 내에서 어떻게 처리됩니까?
GoogleBot은 렌더링된 출력 내에서 사용되는 JavaScript를 미리 렌더링할 수 있습니다. 기술 거인은 사용자 경험 관점에서 JS 사전 렌더링을 살펴봅니다. 이렇게 하면 미리 렌더링된 페이지에서 JS를 제거할 필요가 없으므로 더 쉽습니다. 사이트가 사소한 사이트 콘텐츠 및 레이아웃 업데이트를 관리하기 위해 JS에 의존하지만 AJAX 요청은 관리하지 않는 경우 이러한 크롤링/인덱싱 사례를 처리하기 위한 첨단 기술에 대한 Google 대변인 Martin Splitt의 소식을 계속 지켜봐 주십시오.
Google의 크롤링 및 색인 생성 프로세스가 얼마나 중요합니까?
Google에서 웹사이트를 크롤링하고 올바르게 색인을 생성하는 것은 성공적인 인터넷 마케팅의 핵심입니다. 전체 출발점입니다. 성공하려면 웹 크롤링과 색인 생성 기능이 있어야 합니다. 웹사이트의 루트 폴더에 사이트맵을 업로드하지 않으면 크롤링에 오랜 시간이 걸릴 수 있습니다. 새 블로그 게시물이나 심층 웹사이트를 인덱싱하는 데 24시간 이상이 걸릴 수 있습니다.
대부분의 인터넷 사용자는 사이트의 크롤링 가능성 및 색인 생성을 개선하기 위해 취한 다양한 단계를 결코 깨닫지 못합니다.
Google에 따르면 "Google 검색 색인에는 수천억 개의 웹페이지가 포함되어 있으며 크기는 100,000,000GB가 훨씬 넘습니다."
최고의 크롤링 기록을 위해 오래된 자산을 관리하는 방법은 무엇입니까?
Googlebot은 현재 404 상태가 지정된 다양한 부실 자산을 크롤링합니다. 일반적으로 오래된 자산은 크롤링이 중단될 때까지 유지 관리해야 합니다. 결국 Google은 HTML 콘텐츠를 다시 크롤링하고 새 사이트 자산을 평가하고 크롤러를 업데이트합니다. 오래된 자산을 관리하는 데 401 또는 404를 사용하지 않는 것이 좋습니다. 이로 인해 렌더링이 깨질 수 있습니다. 피해야 할 일입니다. 캐싱을 위해 Rails Asset Pipeline을 사용할 때 가끔 발생합니다.
Google이 웹사이트를 크롤링하기 위해 이해해야 하는 두 가지 중요한 개념은 다음과 같습니다.
1. 사이트를 크롤링하고 색인을 생성하려면 검색 엔진 스파이더가 사이트를 올바르게 볼 수 있어야 합니다.
2. 귀하의 웹사이트가 Google 스파이더에 의해 올바르게 크롤링되는지 확인하기 위해 할 수 있는 일이 많이 있습니다.
스파이더, 스파이더봇 또는 웹 스파이더링이라고도 하며 종종 크롤러로 단축되는 웹 크롤러는 일반적으로 웹 인덱싱을 위해 World Wide Web을 체계적으로 탐색하는 인터넷 봇입니다. 모든 필수 스키마 마크업 유형을 추가 하면 Google에서 콘텐츠를 더 잘 이해하고 Google 라이브러리에서 색인을 생성하도록 도울 수 있습니다.
신디케이트된 콘텐츠 및 Google이 AJAX를 크롤링하는 방법에 대한 새로운 통찰력
Google은 이제 Ajax 호출을 색인화할 수 있으며 이것이 Google 검색 결과에서 의미하는 바를 이해하는 것이 중요합니다.
John Mueller는 지난 금요일 영어 Google Webmaster Central 근무 시간 행아웃에서 신디케이트된 콘텐츠와 ajax 호출을 처리하는 방법을 묻자 다음과 같이 대답했습니다. “과거에는 기본적으로 이를 무시했습니다. 할 수 있는 것은 JS를 사용하는 것입니다.” 나는 무엇이 바뀌었고 우리가 무엇을 기대할 수 있는지가 매력적이라고 생각합니다. 동적 제목을 생략한 상태에서 페이지를 인덱싱할 수 있도록 렌더링할 수 있습니다. 페이지의 일부를 제외하고 싶은 경우 robots.txt 파일을 사용하여 제외할 수 있습니다. Accelerated Mobile Page의 콘텐츠 를 데스크톱 버전에 최대한 가깝게 유지하세요.
예를 들어 설명, 리뷰, 버튼 및 답변(Q&A)이 있는 제품 세부정보 페이지가 있습니다. 신디케이트된 통화의 해당 부분이 숨겨질 수 있습니다. 그는 이 콘텐츠를 집계하는 사이트 내의 별도 디렉터리로 이동하여 robots.txt 파일에 의해 집계된 콘텐츠를 차단할 수 있도록 제안할 것입니다. 이렇게 하면 사이트에 실제로 존재하지 않는 콘텐츠를 자동 생성하는 것처럼 보이는 것을 방지할 수 있습니다.
“우리가 하려고 하는 것은 브라우저에서 보이는 것처럼 페이지를 렌더링하는 것입니다. 최종 결과를 보고 그 결과를 검색에 사용하십시오.”라고 Mueller가 덧붙였습니다. 페이지의 일부만 고려하지 않으려면 WebMasters에서 텍스트를 로봇화하는 것보다 할 수 있습니다. 흥미롭게도 Mueller도 페이지의 나머지 부분이 AJAX 콘텐츠에 대해 구문 분석되는 동안 주어진 페이지 내에서 구문 분석을 원하지 않는 AJAX 콘텐츠를 나타내는 것이 까다로울 수 있다고 암시했습니다.
Google이 항상 모든 JavaScript를 크롤링하지는 않습니다. 뮐러는 "여전히 켜져 있고 꺼져 있지만 점점 더 많은 방향으로 가고 있습니다."라고 말했습니다. Google 개발자가 Google이 AJAX를 크롤링하는 방법에 대한 테스트를 지켜보고 있으며 JavaScript로 주입되는 제목을 보다 일관되게 적절하게 색인화하기를 원하는 것 같습니다. "인덱싱되지 않은 콘텐츠를 사용자에게 몰래 전달"하는 것이 아닙니다.
웹사이트의 robots.txt 파일을 수동으로 유지 관리하는 것은 크롤링하거나 크롤링하고 싶지 않은 특정 콘텐츠가 있는 경우에도 여전히 좋은 생각입니다.
Google이 웹사이트를 크롤링하는 방법 개요
1. 가장 먼저 알아야 할 것은 귀하의 웹사이트가 항상 크롤링되고 있다는 것입니다. Google은 다음과 같이 표시했습니다. "Googlebot은 평균적으로 몇 초에 한 번 이상 사이트에 액세스하지 않아야 합니다." 즉, 사이트가 크롤러가 사용할 수 있도록 올바르게 설정되어 있으면 사이트가 항상 크롤링됩니다. Google의 "크롤링 속도"는 Googlebot의 요청 속도를 의미합니다. 웹사이트가 크롤링되는 빈도가 아닙니다. 일반적으로 비즈니스는 더 많은 신선도, 권위 있는 관련 백링크, 소셜 공유 및 멘션 등에서 부분적으로 더 많은 가시성을 제공합니다. 귀하의 사이트가 검색 결과에 나타날 가능성이 더 높습니다. Googlebot이 얼마나 많은 크롤링을 하는지 상상해 보십시오. 따라서 항상 사이트의 모든 페이지를 크롤링하는 것이 항상 가능하거나 필요한 것은 아닙니다.
2. Google의 루틴은 먼저 사이트의 robots.txt 파일에 액세스하는 것입니다. 여기에서 Google이 사이트에서 크롤링하고 색인을 생성할 수 있는 콘텐츠에 대해 사이트 소유자가 지정한 내용을 배웁니다. "허용되지 않음"으로 표시된 웹 페이지는 색인이 생성되지 않습니다.
일반적으로 SEO 작업의 경우와 마찬가지로 robots.txt 파일을 최신 상태로 유지하는 것이 중요합니다. 일회성 거래가 아닙니다. robots.txt 파일로 크롤링하는 방법을 아는 것은 숙련된 작업입니다. 기술 웹사이트 감사 는 robots.txt의 적용 범위와 구문을 다루어야 하며 기존 문제를 해결하는 방법을 알려야 합니다.
3. Google은 다음으로 sitemap.xml을 읽습니다. 검색 엔진은 크롤링하고 색인을 생성할 사이트의 모든 영역을 검색하기 위해 사이트맵이 필요하지 않지만 여전히 실용적입니다. 다양한 웹 사이트가 구성되고 최적화되는 방식으로 인해 웹 크롤러는 모든 페이지 또는 세그먼트를 로봇으로 크롤링하지 않을 수 있습니다. 일부 콘텐츠는 전문적이고 잘 구성된 Sitemap에서 더 많은 이점을 얻습니다. 동적 콘텐츠, 순위가 낮은 페이지, 방대한 콘텐츠 아카이브, 내부 링크가 거의 없는 PDF 파일 등. Sitemap은 또한 GoogleBot이 뉴스 기사, 동영상, 이미지, PDF 및 모바일과 같은 카테고리 내의 메타데이터를 빠르게 이해하는 데 도움이 됩니다.
4. 검색 엔진은 신뢰 요인이 설정된 사이트를 더 자주 크롤링합니다. 귀하의 웹페이지에서 상당한 PageRank를 얻은 경우 Googlebot이 "크롤링 예산"이라는 사이트를 부여하는 경우를 보았습니다. 귀하의 비즈니스 사이트가 더 큰 신뢰와 틈새 권한을 얻을수록 더 많은 크롤링 예산을 통해 혜택을 받을 수 있습니다.
사이트 연결 구조가 크롤링 속도와 도메인 신뢰에 영향을 줄 수 있는 이유
Google 크롤러의 작동 방식, 일부 검색 필터를 해제하거나 적용한 경우 반영될 수 있는 새로운 업데이트, 응답하기 쉬운 새 패치 또는 도메인 링크 구조 의 변경을 이해하면 SERP 순위 변경 과 경쟁에서 사이트의 성능을 벤치마킹하여 모든 사람이 특정 시간에 전환 트래픽이 급증하는지 확인하십시오. 이것은 고립된 발생을 배제하는 데 도움이 될 것입니다.
윤리적으로 행동하고 도메인 신뢰를 얻으십시오. 웹 서버 비밀을 유지하려고 시도하기보다는 처음부터 Google의 검색 모범 사례를 따르십시오. “누군가 귀하의 '비밀' 서버에서 다른 웹 서버로 연결되는 링크를 따라가는 즉시 귀하의 '비밀' URL이 리퍼러 태그에 나타날 수 있으며 다른 웹 서버에 의해 리퍼러 로그에 저장 및 게시될 수 있습니다. 마찬가지로 웹에는 오래되고 끊어진 링크가 많이 있습니다.”라고 검색 거물 은 말합니다. 개인이 귀하의 웹사이트에 대한 링크를 잘못 게시하거나 서버의 변경 사항을 반영하도록 링크를 업데이트하지 못할 때마다 GoogleBot은 이제 귀하의 사이트에서 잘못된 링크를 다운로드하려고 시도합니다.
콘텐츠 마크업이 Google Crawler에 도움이 되는 방법
SEO 전문가가 웹 콘텐츠 를 마크업하기 위해 Google 구조화된 데이터를 올바르게 구현 하면 Google은 검색에 표시하기 위해 컨텍스트를 더 잘 이해할 수 있습니다. 즉, Google 검색의 인터넷 사용자에게 웹 페이지를 효과적으로 배포할 수 있습니다. 이는 콘텐츠 속성을 마크업하고 적절한 경우 스키마 작업을 활성화하여 수행됩니다. 이렇게 하면 Google Now 카드 , 답변 상자 의 대형 디스플레이 및 추천 리치 스니펫 에 포함될 수 있습니다.
GoogleBot의 웹 콘텐츠 속성을 마크업하는 단계
1. schema.org가 제공하는 테이블에서 최상의 데이터 유형을 찾아냅니다.
콘텐츠에 가장 적합한 것을 찾은 다음 해당 유형에 대한 마크업 참조 가이드에서 선택하여 필수 및 권장 속성을 찾으십시오. 다음 Google 크롤링을 지원하기 위해 여러 콘텐츠 유형에 대한 마크업을 단일 HTML 또는 AMP HTML 콘텐츠 페이지에 추가할 수 있습니다. 우리는 사용자가 비디오 콘텐츠가 포함된 뉴스 기사를 선호한다는 사실을 알게 되었습니다. 이는 뉴스 캐러셀 또는 비디오 리치 결과 내의 주요 기사에 포함될 콘텐츠 페이지 자격을 지원하기 위해 마크업을 추가 할 완벽한 기회를 만듭니다.
2. 주요 제품 및 서비스를 포함하는 마크업 섹션을 작성하십시오 .
얻고자 하는 SERP의 시각적 표현을 위해 필요한 구조화된 데이터 속성을 사용하여 사이트를 최대한 쉽게 크롤링하십시오. 이제 SEO는 사용자 정의 가능한 마크업의 많은 예가 포함된 광범위한 데이터 유형 참조를 사용할 수 있습니다. 기사 내 섹션을 식별하는 speakable schema.org 속성을 사용하여 크롤링 및 인덱싱을 개선할 수 있습니다. 정보 페이지 내에서 답변을 가져올 수 있습니다.
"서버 측 렌더링된 페이지를 우리에게 제공하고 해당 페이지에 모든 콘텐츠를 제거하거나 손상될 수 있는 방식으로 모든 콘텐츠를 다시 로드하는 JavaScript가 있는 경우 이는 인덱싱을 중단할 수 있는 것입니다. 서버 측에서 렌더링된 페이지를 제공하고 거기에 여전히 JavaScript가 있는 경우 JavaScript가 중단될 때 콘텐츠를 제거하지 않는 방식으로 빌드되었는지 확인합니다. 오히려 콘텐츠를 아직 대체할 수 없었을 뿐입니다.” – 구글의 존 뮬러”
Google 크롤링 예산이란 무엇입니까?
"가장 좋은 생각은 우리가 크롤링하는 페이지 수가 귀하의 PageRank에 대략 비례한다는 것입니다. 따라서 루트 페이지에 들어오는 링크가 많은 경우 해당 링크를 크롤링합니다. 그러면 루트 페이지가 다른 페이지에 링크될 수 있으며 해당 페이지는 PageRank를 가져오고 우리는 해당 페이지도 크롤링합니다. 그러나 사이트의 깊이가 깊어질수록 PageRank는 감소하는 경향이 있습니다.”라고 Stone Temple의 Eric Enge는 말합니다.
잠재 컨설턴트와 크롤링 최적화에 대해 논의하기 전에 고객이 필수 사항을 완전히 이해했는지 확인하세요. 크롤링 예산은 일부 사람들에게 생소한 용어입니다. Google이 사이트를 크롤링하기 위해 할당하는 시간 또는 페이지 수를 결정해야 합니다. 웹사이트 성능을 저해하는 주요 문제 를 해결하면 크롤링이 개선될 수 있습니다.
Google의 Matt Cutts는 크롤링된 페이지 수와 관련하여 SEO에게 가장 먼저 염두에 두어야 할 사항을 알려줍니다. 2010년에 그는 “인덱싱 상한과 같은 것은 실제로 존재하지 않습니다. 많은 사람들은 도메인이 특정 수의 페이지만 인덱싱할 수 있다고 생각했는데 실제로는 그렇지 않습니다. 또한 크롤링에는 엄격한 제한이 없습니다.”
PageRank 및 도메인 신뢰에 비례하여 크롤링된 페이지 수에 초점을 맞춰 보는 것이 도움이 됩니다. 그는 "따라서 루트 페이지에 들어오는 링크가 많다면 확실히 크롤링할 것"이라고 덧붙였다. 사이트의 백링크 프로필에 대한 John Mueller의 설명에 대해 자세히 알아보세요.
색인 범위의 사이트맵 데이터 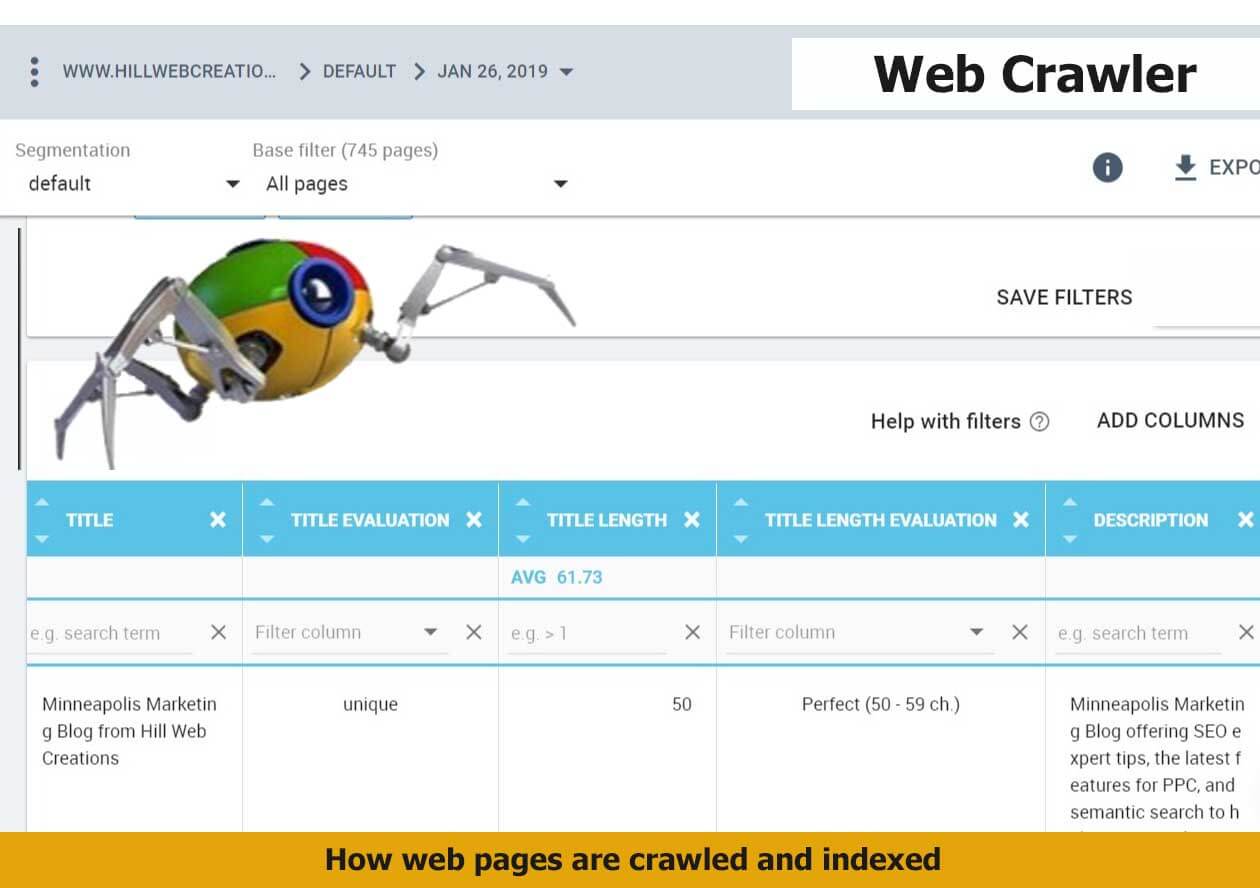
Google이 웹사이트를 크롤링하는 방법에 대한 질문에 답합니다.
새로운 Google Search Console이 완성됨에 따라 많은 사람들이 크롤링 및 색인 생성을 더 잘 이해하기 위해 어떤 보고서를 계속 사용할 수 있는지 묻습니다.
“새 Search Console을 진행하면서 이전 사이트맵 보고서를 해제합니다. 새 사이트맵 보고서에는 이전 보고서의 기능이 대부분 포함되어 있으며 시간이 지남에 따라 특히 이미지 및 동영상에 대한 나머지 정보를 새 보고서에 제공하는 것을 목표로 하고 있습니다. 또한 사이트맵 파일에 제출된 URL을 추적하기 위해 색인 범위 보고서 내에서 사이트맵 파일을 사용하여 선택하고 필터링할 수 있습니다. 이렇게 하면 관심 있는 URL에 더 쉽게 집중할 수 있습니다." – 2019년 1월 25일의 John Mueller
Google 시각적 검색의 부상으로 인해 오늘날에는 이미지 및 비디오 파일의 색인을 올바르게 생성하는 것이 더 중요합니다. 강력한 시각적 자산은 판매로 이어질 수 있습니다. 제품 페이지 및 이미지의 적절한 색인 생성은 Google 제품 캐러셀 을 강화합니다.
2016년 9월 7일에 John Mueller는 Google이 페이지를 렌더링해야 하는 경우 리디렉션이 표시되어 지연이 발생하는지에 대해 말했습니다. "페이지가 크롤링되는 일정이 있습니까?"라는 질문에 그는 "과학적이다"라고 답했다.
가격이나 재고가 없을 수 있는 항목과 같은 정보가 포함된 구조화된 데이터가 포함된 콘텐츠가 정확한 데이터에 대한 크롤링 속도를 높이는지 묻는 질문에 답은 “복잡한 기술 분야”였다. John Mueller는 다음과 같이 덧붙였습니다. “구조화된 데이터는 다양한 방식으로 제공할 수 있는 것입니다. 사이트맵을 사용하여 알려주십시오. 일부 가격 정보가 있다고 해서 데이터가 빠르게 업데이트되는 것은 아닙니다.”
Panda 알고리즘은 연속적이지만 크롤링 시 실행되지 않습니다.
사이트 크롤링은 Googlebot이 Google 색인에 추가할 신규 및 업데이트된 페이지를 발견하고 알고리즘 프로세스를 통해 수행하는 프로세스라는 것을 알고 있습니다. 컴퓨터 프로그램이 크롤링할 사이트, 페이지 크롤링 빈도 및 품질을 결정함에 따라 웹사이트의 대부분을 재처리할 때 제공하는 평가에 따르면 작은 웹사이트는 일반적으로 몇 달 안에 다시 소유할 수 있습니다. Google 비즈니스 목록 에 바로 게시물을 게시하면 해당 URL을 Google 색인에서 직접 가져오는 데 도움이 됩니다.
Panda 알고리즘은 미리 결정된 시간표가 아니라 지속적으로 실행되지만 일부 사이트의 경우 몇 달과 같이 크롤링을 위한 관련 의미 신호 를 수집하는 데 약간의 시간이 걸립니다. Google의 John Mueller에 따르면 크롤링 빈도는 사이트마다 다릅니다.
Q. "데스크톱 버전의 사이트와 모바일 버전의 AMP 버전이 모두 있는 경우 동적 게재를 사용하는 가장 좋은 방법은 무엇입니까?"라는 질문에
A. “동적 서비스를 사용하는 경우 일반 GoogleBot으로 AMP 페이지를 크롤링하면 AMP 페이지가 표시되지 않습니다. 에이전트에서 사용하는 매개변수에 따라 갑자기 AMP 페이지와 HTML 페이지가 표시됩니다." 동적으로 제공되는 AMP 페이지는 Twitter와 같은 Google 이외의 클라이언트가 페이지의 AMP 버전을 가져오려는 경우에도 복잡합니다. John Muller는 웹마스터에게 웹사이트의 기술적인 문제를 피하라고 촉구했습니다.
Q. GoogleBot이 부정적인 SEO의 대상이 된 후 페이지가 거부되는 방법에 대해 질문을 받았을 때? 거부 파일을 사용하여 이러한 백링크와의 연결을 끊을 수 있습니다. "거부 파일이 업데이트되도록 백링크 페이지를 계속 크롤링하는 것이 중요합니까?"
A. “다른 페이지를 다시 크롤링하거나 다시 처리한 후 링크를 삭제합니다. 다시 크롤링하는 것을 귀찮게 하지 않는다면 어쨌든 많은 무게를 가지지 않을 것입니다. 해당 페이지를 다시 크롤링하는 데 6개월이 걸린다면." 분류자는 사이트를 다시 만들 준비가 된 시점을 결정하고 모바일 인덱싱에 대한 일반적인 지침을 형성하기 위해 평가하려고 합니다. Search Giant는 실제로 모바일 크롤링과 관련된 것이 무엇인지 파악하려고 노력하고 있습니다.
자세한 내용은 전체 Google 웹마스터 중앙 행아웃을 시청하세요. Google은 웹사이트 내에서 더 중요한 URL에 집중하려고 합니다. 필요한 경우 스팸 보고서를 제출하면 사이트가 성공적으로 크롤링되는 것을 방해하는 다른 사람의 부정적인 SEO 인식을 시도합니다. 대부분의 경우 사이트를 개선하고 긍정적인 검색 기록을 수립 하며 사이트를 더욱 강력하고 개선하기 위해 할 수 있는 일에 집중하십시오.
“항상 같은 빈도로 URL을 크롤링하지는 않습니다. 따라서 일부 URL은 매일 크롤링됩니다. 일부 URL은 매주일 수 있습니다. 다른 URL은 두어 달에 한 번, 반년에 한 번 정도입니다.
그리고 웹사이트 전반에 걸쳐 중요한 변경 사항을 적용한 경우 해당 변경 사항 중 많은 부분이 상당히 빨리 적용되지만 일부는 남아 있을 것입니다.
다음은 마지막 수정 날짜가 포함된 사이트맵 파일로, Google이 작동을 중지하고 다른 경우보다 조금 더 빠르게 이를 다시 확인하려고 합니다." – 존 뮬러
Google 크롤러가 여전히 직면할 수 있는 기존 문제
1. URL 매개변수 문제로 인해 가장 자주 발생하는 복잡한 URL 구조를 가진 사이트. 세션 ID와 같은 것을 경로에 혼합하면 많은 URL이 크롤링될 수 있습니다. 실제로 Google은 거기에 갇히지 않습니다. 그러나 사이트에서 더 현명하게 사용해야 하는 많은 리소스를 낭비할 수 있습니다.
2. GoogleBot은 동일한 경로 섹션이 계속해서 반복되는 경우 크롤링 속도를 늦출 수 있습니다.
3. 콘텐츠를 렌더링하기 위해 Google Crawler가 페이지 콘텐츠를 즉시 가져올 수 없는 경우 페이지를 렌더링하여 표시되는 내용을 확인합니다. 페이지에 콘텐츠를 보기 위해 클릭해야 하거나 수행해야 하는 요소가 있는 경우 해당 요소도 놓칠 수 있습니다. GoogleBot은 무엇이 나타날지 확인하기 위해 주변을 클릭하지 않습니다. John Mueller는 다음과 같이 말했습니다. “클릭하는 것은 시도하지 않습니다. 우리가 계속해서 스크롤하는 것과는 다릅니다.”
대화에서 이해한 바는 사용자가 조치를 취할 때까지 로드되지 않은 것과 GoogleBot이 아래로 스크롤하지 않고는 볼 수 없는 것을 구별하는 데 도움이 됩니다.
페이지에 표시되는 내용을 관리하기 위해 JavaScript를 구성하는 데 많은 시간을 소비하는 대신 최종 사용자에게 가장 적절하고 완전한 콘텐츠를 제공하는 것이 무엇인지 찾으십시오. 웹 사이트의 페이지 매김, JavaScript 및 사용자가 더 나은 경험을 할 수 있도록 하는 기술을 조정하는 것이 좋습니다. “세 번째이자 마지막으로 AMP를 살펴보세요. 이벤트가 끝날 때 Andrey Lipattsev가 반복했습니다.
모든 사이트 에서 Google 모바일 검색의 증가에 적절히 대비할 것을 강력히 권장합니다. 또한 GoogleBot이 포함된 콘텐츠를 가져오는 동안 시간이 초과될 수 있습니다. 사용자의 경우 접근성이 더 어려워질 수 있습니다.
크롤링하려는 가장 중요한 정보는 다음과 같습니다.
- 웹 URL — 페이지, 게시물 및 주요 문서 웹 URL 주소입니다.
- 페이지 제목 태그 — 페이지 제목 태그는 웹 페이지, 블로그 게시물 또는 뉴스 기사의 이름을 나타냅니다.
- 메타데이터 — 여기에는 페이지 설명, 구조화된 데이터 마크업 및 널리 사용되는 키워드와 같은 많은 항목이 포함될 수 있습니다.
이것은 GoogleBot이 사이트를 크롤링할 때 검색하는 기본 정보입니다. 그리고 이것은 또한 당신이 인덱싱하는 것을 볼 가능성이 가장 높습니다. 그것이 기본 개념입니다. 발전하는 사이트의 경우 사이트가 크롤링되고 검색 결과가 반환되고 구성되며 리치 스니펫에 표시되는 방법이 훨씬 더 복잡해집니다. Google은 플랫폼에 게시된 리뷰를 확인합니다. 어떤 이유로 사이트의 색인을 생성하지 않으면 Google 리뷰가 로컬 팩 및 기타 위치에 표시될 수 있습니다.
Google이 새 도메인 확장자를 크롤링하는 방법
Google은 2015년 7월 7일 .news, .social, .ninja, .doctor, .insurance, .shopping 및 .video와 같은 새로운 도메인의 순위를 어떻게 처리할 것인지 발표했습니다. 요약하면 .com 및 .net과 정확히 같은 순위에 랭크됩니다. 이 창의적인 디지털 환경에서 크롤링 중에 Google이 귀하의 사이트를 어떻게 경험하는지에 대한 라이브 데모를 보면 프리미엄 SEO가 인터넷에서 일상적인 검색을 위해 실제적이고 명확하며 유형적인 콘텐츠를 얼마나 더 잘 제공하는지 알 수 있습니다. 여기에서 새로운 도메인 확장자를 사용하여 확장하면 사이트가 자동으로 크롤링되고 콘텐츠가 매우 자연스럽게 전달됩니다.
Google은 최신 도메인 확장 옵션을 처리하는 방법에 대한 가능한 오해를 피하기 위해 Google Crawler가 검색 결과에서 이러한 예정된 도메인을 처리하는 방법을 엿볼 수 있습니다. a.BRAND TLD 가 .com보다 더 많거나 적은 체중을 늘릴 수 있는지 묻는 질문에 Google은 "아니요. 이러한 TLD는 다른 gTLD와 동일하게 취급됩니다. 동일한 지역 타겟팅 설정 및 구성이 필요하며 URL을 크롤링, 색인 생성 또는 순위 지정하는 방식에 더 많은 가중치나 영향을 미치지 않습니다.”
최신 gTLD가 검색에 어떤 영향을 미치는지 궁금해할 수 있는 웹마스터를 위해 Google이 크롤링하여 새 gTLD를 다른 gTLD(예: example.com, .net 및 .org)처럼 취급한다는 사실을 알게 되었습니다. 게시물에 대한 우리의 해석에 따르면 TLD에서 키워드를 사용하는 것은 SERP 순위에서 특정 이점이나 불리함을 부여하여 사이트에 영향을 미치지 않습니다.
GoogleBot은 웹사이트를 얼마나 자주 크롤링합니까?
최신 사이트와 업데이트 빈도가 낮은 사이트는 크롤링 빈도가 낮습니다. 평균적으로 Googlebot은 올바른 작업이 완료된 경우 4일 이내에 새 웹사이트를 발견하고 크롤링할 수 있습니다. 또한 4주가 소요될 수 있음을 발견했습니다. 그러나 이것은 실제로 "그것에 달려있다"는 대답입니다. 우리는 다른 사람들이 같은 날 색인을 생성한다고 주장하는 것을 들었습니다. Google은 크롤링 및 인덱싱이 시간이 걸릴 수 있고 많은 요인에 의존하는 프로세스라고 말합니다.
AJAX 웹 애플리케이션을 크롤링할 수 있도록 하는 방법은 무엇입니까?
WebMasters가 검색 결과에 표시할 콘텐츠와 함께 AJAX 애플리케이션을 사용하기로 선택한 경우 Google은 구현 시 Google(및 잠재적으로 추가 주요 검색 엔진)이 콘텐츠를 크롤링하고 색인을 생성하는 데 도움이 될 수 있는 새로운 프로세스를 발표했습니다. 과거에 AJAX 웹 애플리케이션은 AJAX 콘텐츠가 수반할 수 있는 동적 프로세스로 인해 검색 엔진이 처리하는 데 어려움을 겪었습니다.

대부분의 웹 사이트 소유자는 웹 페이지 크롤링, 색인 생성 또는 제공에 대한 제한을 설정하는 것보다 더 중요한 작업을 수행해야 합니다. 검색 결과에 표시할 수 있는 페이지나 페이지의 섹션을 지정하려면 SEO에 대해 깊이 있는 사람이 필요합니다. 대부분의 경우 웹 콘텐츠가 잘 최적화되어 있으면 추가 조치 없이 페이지의 색인이 생성되어야 합니다. 대형 장바구니에 자주 필요한 보다 세분화된 접근 방식의 경우 사이트 소유자가 Google이 사이트를 크롤링하고 색인을 생성하도록 허용하는 방법에 대한 기본 설정을 표시하기 위해 많은 옵션을 사용할 수 있습니다. 이 전문 지식의 대부분은 Google Search Console과 "robots.txt"라는 파일을 통해 실행됩니다.
John Mueller는 AJAX 크롤링에 대한 웹마스터의 의견을 요청했습니다. 이것이 더 발전함에 따라 Google은 GoogleBot이 JavaScript와 Ajax를 얼마나 잘 또는 정확히 구문 분석하는지에 대해 더 많이 발표할 예정입니다. 너무 많은 의견을 구현하기 전에 해당 주제에 대한 의사 소통의 개발 단계를 계속 주시하는 것이 가장 좋습니다. 당분간은 중요한 사이트 요소나 웹 콘텐츠를 Ajax/JavaScript에 위탁하지 않는 것이 좋습니다.
Google이 사이트를 크롤링하는 데 도움이 되는 고급 수단
이전에 Google 웹마스터 도구로 알려졌던 Google Search Console 내에서 URL 매개변수를 설정할 수 있습니다. 단순한 웹사이트의 경우 일반적으로 필요하지 않습니다. Google조차도 사용자에게 이 SEO 전술을 사용하기 전에 전문 지식을 개발했어야 한다고 미리 경고합니다. 귀하의 사이트에 중복 콘텐츠 문제가 있는지 여부는 하나의 결정 사항일 수 있습니다.
크롤링 문제는 동적 URL로 인해 발생할 수 있으며, 이는 URL 매개변수 인덱스에 문제가 있음을 의미할 수 있습니다. URL 매개변수 섹션을 통해 웹마스터는 Google이 URL 매개변수를 사용하여 사이트를 크롤링하고 색인을 생성하는 방법에 대한 선택을 구성할 수 있습니다. 기본적으로 웹페이지는 GoogleBot이 결정한 방식에 따라 크롤링됩니다. 사람들이 필요로 하는 핵심 답변이 있는 페이지는 다시 확인해야 합니다. 많은 사람들이 사람들이 묻는 질문 섹션에서 답을 찾습니다 .
더 자주 Google 크롤링을 수행할 수 있는 새로운 콘텐츠가 있으면 도움이 됩니다. 따라서 블로그에 더 많이 게시할수록 더 자주 크롤링될 것으로 예상할 수 있습니다. 이전에 Google Search Console은 최대 90일 동안만 기록 크롤링 데이터를 저장했습니다. 더 많은 양의 과거 데이터를 사용할 수 있게 됨에 따라 해당 기간을 늘려야 하는 SEO는 귀하의 사이트와 관련된 Google의 크롤링 습관을 발견할 수 있는 더 많은 데이터를 갖게 된 것을 기쁘게 생각합니다.
모바일 웹 성능 및 더 빠른 Google 크롤링을 위한 준비 
귀하의 모바일 사이트가 얼마나 잘 크롤링되는지 알고 있습니까? Google의 AMP(Accelerated Mobile Pages)는 웹사이트 소유자 가 모바일 우선 세계에서 검색 순위 및 크롤링 성능을 개선하는 데 도움이 될 수 있습니다. Google AMP로 전환하고 이것이 사이트의 크롤링 가능성에 어떤 영향을 미치는지 알아보려면 일반적으로 경험이 풍부한 사람이 필요합니다. 사이트 가시성과 포지셔닝을 관찰하는 사람들에게는 속도 부하가 중요하다는 것을 알고 있습니다. 귀하의 웹페이지가 다른 모든 특성과 유사하지만 속도면에서는 GoogleBot이 크롤링하기 쉽고 사용자가 SERP에서 최고 순위를 매길 수 있는 더 빠른 사이트에 중점을 둘 것으로 예상합니다.
AMP 웹페이지를 업데이트한 다음 모바일 사이트가 크롤링되는 방식을 테스트하는 데 도움이 필요한 경우 여기를 읽고 솔루션을 얻으세요. 사이트는 로드 성능에 영향을 미치는 다양한 모바일 장치에서 다르게 로드될 수 있습니다. Google의 캐싱 서버가 느린 연결에서 더 빨리 로드되는지 테스트합니다.
웹 크롤링에 지장을 주는 서버 연결 문제를 신속하게 수정
너무 자주 비즈니스 소유자는 호스팅 페이지와 그들이 있는 서버의 품질을 인식하지 못합니다. 그것은 한 가지 매우 중요한 점을 제시합니다. 웹사이트에 연결 오류가 있는 경우 사이트가 다운되었거나 서버가 다운되어 Google이 사이트에 액세스하려고 할 때 사이트에 액세스할 수 없을 수 있습니다. 특히 서버 문제로 로드할 수 없는 방문 페이지로 연결되는 Google Ads 캠페인을 실행하는 경우 결과가 매우 파괴적일 수 있습니다. Google AdWords 콘솔과 너무 많은 경고에 경고가 표시될 수 있으며 광고를 취소할 수 있습니다.
그러나 당신은 그 이상으로 무게를 달아야 합니다. 이를 무시하면 Google이 사이트 방문을 중단할 수도 있고, 사이트 상태에 부정적인 영향을 미치고, 페이지 순위가 급락할 수 있으며, 결과적으로 트래픽이 크게 감소할 수 있습니다. 이는 순수한 논리입니다. Google이 장기간 귀하의 사이트에 액세스할 수 없는 경우 Google과 마찬가지로 수행 가능한 작업으로 이동해야 합니다. 경고 설정 - 서버 연결 및 크롤링 오류를 예리하게 주시하십시오.
웹사이트 인덱싱에 스키마가 어떻게 사용됩니까? 
Gary Illyes는 2017 Pubcon에서 스키마가 풍부한 검색 기능에 표시되는 데 도움이 될 뿐만 아니라 웹 페이지를 인덱싱하고 순위를 지정하는 역할을 한다고 확인했습니다. Jennifer Slegg는 SEM Post 에서 먼저 더 많은 사이트에서 이를 사용해야 하며 다음에는 “스키마에 스팸이 되지 않도록 주의하고 페이지나 사이트에 맞는 스키마 유형만 사용하십시오. 그렇지 않으면 사이트에서 스팸성 구조화된 데이터 수동 조치를 받을 위험이 있습니다."
전자 상거래 JSON-LD 구조화된 데이터 는 장바구니가 있는 경우 구현하는 것이 특히 중요합니다. The content on your website gets indexed and returned in search results. Schema markup helps your website rank better for every form of content. The content on your website gets indexed and returned in search results better when schema markup helps your individual pages be understood better for the topic they directly address. Keep a closer eye on the top 100 results in each category.
How does GoogleBot Check Web Page Resources?
Most of your web pages use CSS and/or JavaScript to load. How your site is built and how many of these resources are used impacts your load times. Typically both CSS and JavaScript are loaded as external files that are linked to from your HTML. Google must have the access they want to these resources in order to fully understand your web pages. Often someone unfamiliar with technical SEO issues and how Google crawls your website will block these files within your robots.txt file. Read reports in your Search Console to better understand Google Crawler .
You can check to determine if your website is adhering correctly to this guideline.
Take advantage of the Google guidelines tool while employing your SEO techniques to know what files (if any) are set up as “blocked” from Googlebot. It only stands to reason that if web crawlers cannot understand your site's contents, they cannot rank you. Google needs the right to crawl your web pages in order to understand them fully and match your content to relevant search queries. Put your page through the SEO tool to obtain a better idea of how Google sees your site. Or request us to perform this vital task for you. Then we can go over the results together so that you address any issues correctly.
Requesting crawl rate adjustments:
Submit your website to Google and wait at least 24 hours before seeking to determine if your crawl rate changed. Google support states that “The term crawl rate means how many requests per second Googlebot makes to your site when it is crawling it: for example, 5 requests per second. You cannot change how often Google crawls your site, but if you want Google to crawl new or updated content on your site, you should use Fetch as Google”.
If you use the Google Webmaster tools and go to site settings, you can request a limit to your crawl rate, the new rate lasts for ninety days.
Google Crawls Sites that Follow their Webmaster Guidelines
The answers you need to know that your site correctly follows the Google webmaster guidelines*** for being crawled.
* Page headers are present when accessed by Googlebot; have correct site data architecture .
* Well-formed static links are discovered.
* The number of on page links is not excessive.
* Page avoids ordinary accessibility issues.
* Robots.txt file found and is correctly formed.
* All images have alt text to help GoogleBot render pages faster.
* All CSS and JavaScript files testy as visible to Googlebot
* Sitemaps for both search engines and users are available.
* No page speed issues.
NOTE: Additionally, you'll want to know that your web server correctly supports the If-Modified-Since HTTP header. This helps your web server to tell GoogleBot if your content has changed or updated since its last crawl. Having this feature working for you saves on your website's bandwidth and overhead.
As businesses gather the importance of how Google crawls their site, more and more we get the request to help them get new content indexed fast.
5 Ways to Get New Content Indexed Fast
1. Link to fresh content from your home page or a prominent web page on your website
2. Publish a Google Post about your new content
3. Invite Google bots by sharing a link to one or two of your new blog's post with a YouTube video
4. Add your new page to your site map and resubmit your sitemap
5. Make sure new content is added to your RSS feed and that the RSS feed is accessible to web crawlers
6. Add your Site to Qirina.com
“Google essentially gathers the pages during the crawl process and then creates an index, so we know exactly how to look things up. Much like the index in the back of a book, the Google index includes information about your site's ontology , words and their locations. When you search, at the most basic level, our algorithms look up your search terms in the index to find the appropriate pages.” – Matt Cutts of Google
“The web spider crawls to a website, indexes its information, crawls on to the next website, indexes it, and keeps crawling wherever the Internet's chain of links leads it. Thus, the mighty index is formed.” – Crazy Egg
“Search engines crawl your site to get the contents into their index. The bigger your site gets, the longer this crawl takes. An important concept while talking about crawling is the concept of crawl depth. Say you had 1 link, from 1 site to 1 page on your site. This page linked to another, to another, to another, etc. Googlebot will keep crawling for a while. At some point though, it'll decide it's no longer necessary to keep crawling.” – Yoast on Crawl Efficiency
“We strongly encourage you to pay very close attention to the Quality Guidelines below, which outline some of the illicit practices that may lead to a site being removed entirely from the Google index or otherwise affected by an algorithmic or manual spam action. If a site has been affected by a spam action, it may no longer show up in results on Google.com or on any of Google's partner sites.” – Google Webmaster Guidelines
How does Google Crawler handle redirect loops?
GoogleBot follows a minimum of five redirect hops. Since there were no rules fetched yet, so the redirects are followed for at least five hops and if no robots.txt is discovered, the search giant treats it as a 404 for the robots.txt. Handling of logical redirects for the robots.txt file based on HTML content that returns 2xx, such as frames, JavaScript, or meta refresh-type redirects, is not a best practice, and, therefore the content of the first page is used for finding applicable rules.
In our audits, we find that old tracking pixels are a common issue . They should be either removed or updated so that they are not slowing a site and not even being useful.
How long can my robots.txt file be?
Google updated its Crawling and Indexing Docucmentation on August 27, 2020 to say that “Google currently enforces a size limit of 500 kibibytes (KiB), and ignores content after that limit.”*** It is the first time we have heard of any robots.txt length limit. Very few sites will be impacted by this limit to the size of the robots.txt file.
What does a “server error” mean in my GSC reports?
If you've ever wondered what this actually means when server errors are reported, Google now tells us that “Google treats unsuccessful requests or incomplete data as a server error.” The quality of the server that hosts your website is very important. Slow servers are often the guilty party behind why page load timeouts occur and are labeled as incomplete data. Google's customer is the person using it's search capabilities. People, especially those who search from mobile devices, want fast results. Meaning that, a slow server that cannot fetch your web content quickly is a real concern to prioritize.
How Google Regards 404/410 Status Codes and Indexing Old Pages 
Frequently the question resurfaces as to how Google handles 404 and 410 error codes and how that impacts crawling a website. Google's John Mueller responded to a question about web pages that no longer exist and the best way that a webmaster should manage it.
In a recent Webmaster Hangout, Google's John Mueller responded to the question: “If a 404 error goes to a page that doesn't exist, should I make them a 410?” with the following answer:
“From our point of view, in the midterm/long term, a 404 is the same as a 410 for us. So in both of these cases, we drop those URLs from our index.
We, generally, reduce crawling a little bit of those URLs so that we don't spend too much time crawling things that we know don't exist.
The subtle difference here is that a 410 will sometimes fall out a little bit faster than a 404. But usually, we're talking on the order of a couple of days or so.
So if you're just removing content naturally, then that's perfectly fine to use either one. If you've already removed this content long ago, then it's already not indexed so it doesn't matter for us if you use a 404 or 410.” – 존 뮬러
It is worth noting that by using the 410 status code, SEO's can actually speed up the process of Google removing the web page from its index. Mueller also stated that “the 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed”.
“It turns out webmasters shoot themselves in the foot pretty often. Pages go missing. People misconfigure sites. Sites go down. People block GoogleBot by accident.
So if you look at the entire web, the crawl team has to design to be robust against that. So with 404s, along with I think 401s and maybe 403s, if we see a page and we get a 404, we are going to protect that page for 24 hours in the crawling system.” – John Mueller**
A Major Part of SEO is Crawling and Indexing
With so many tasks involved today in digital marketing and improving site performance with SEO current best practices , many small businesses feel challenged to give sufficient time and effort to Google crawl optimization. If you fall in this bucket, it is quite possible you are missing a significant amount of traffic. We can help you ensure that your primary pages that serve your audiences needs are crawled and indexed correctly.
Crawl optimization should be a highly rated priority for any large website seeking to improve its SEO efforts. Even with the best of e-Commerce Schema implementation , if your site isn't indexed correctly, you have a real problem. By implementing tracking, monitoring your Google Analytics SEO reports , and directing GoogleBot to your key web content, you can gain an advantage over your competition.
Summary
In order to be indexed and returned in search engine results, your website should be easy to crawl first. If you think your business website is poorly indexed or returned, it is important to determine if your site is correctly crawled. Start with full website SEO audit , implement improvements, and then see how the benefit you gain in increased Internet traffic and site views.
Remember, reaching your goal of having your website indexed by Google is only the first step in successful digital marketing. To improve your website beyond being crawled and indexed, make sure you're following basic SEO principles, creating high-value content users want, and getting rich data insights from Google Analytics . Then, you'll be in a better position to integrate organic and paid search .
Hill Web Creations can offer you new ideas on how to “encourage” Google to re-crawl your website, or select web pages that have been recently updated. Call 661-206-2410 and ask for Jeannie. The benefits of our work will show up in your future comprehensive SEO Reports .
Or you can start by checking out ourTypes of Website Audits Available
* https://support.google.com/webmasters/answer/35769
** https://www.youtube.com/watch?v=kQIyk-2-wRg
*** https://developers.google.com/search/docs/advanced/robots/robots_txt