
วิธีสร้าง Pandas DataFrame [พร้อมตัวอย่าง]
เผยแพร่แล้ว: 2022-12-08เรียนรู้พื้นฐานการทำงานกับ DataFrames ของ pandas: โครงสร้างข้อมูลพื้นฐานใน pandas ซึ่งเป็นไลบรารีการจัดการข้อมูลที่มีประสิทธิภาพ
หากคุณต้องการเริ่มต้นการวิเคราะห์ข้อมูลใน Python แพนด้าเป็นหนึ่งในไลบรารี่แรกๆ ที่คุณควรเรียนรู้การทำงานด้วย จากการนำเข้าข้อมูลจากหลายแหล่ง เช่น ไฟล์ CSV และฐานข้อมูล ไปจนถึงการจัดการข้อมูลที่ขาดหายไปและการวิเคราะห์เพื่อให้ได้ข้อมูลเชิงลึก – pandas ให้คุณทำทุกอย่างข้างต้น
ในการเริ่มวิเคราะห์ข้อมูลด้วยแพนด้า คุณควรเข้าใจโครงสร้างข้อมูลพื้นฐานในแพนด้า: เฟรมข้อมูล
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้พื้นฐานของ pandas dataframes และวิธีการทั่วไปในการสร้าง dataframes จากนั้น คุณจะได้เรียนรู้วิธีเลือกแถวและคอลัมน์จาก dataframe เพื่อเรียกข้อมูลชุดย่อย
ทั้งหมดนี้และอื่น ๆ มาเริ่มกันเลย
การติดตั้งและนำเข้าแพนด้า
เนื่องจาก pandas เป็นไลบรารีการวิเคราะห์ข้อมูลของบุคคลที่สาม คุณควรติดตั้งก่อน ขอแนะนำให้ติดตั้งแพ็คเกจภายนอกในสภาพแวดล้อมเสมือนสำหรับโครงการของคุณ
หากคุณใช้การแจกจ่าย Anaconda ของ Python คุณสามารถใช้ conda สำหรับการจัดการแพ็คเกจ
conda install pandasคุณยังสามารถติดตั้ง pandas โดยใช้ pip:
pip install pandasไลบรารีแพนด้าต้องการ NumPy เป็นข้อมูลอ้างอิง ดังนั้นหากยังไม่ได้ติดตั้ง NumPy ก็จะติดตั้งในระหว่างขั้นตอนการติดตั้งด้วย
หลังจากติดตั้งแพนด้าแล้ว คุณสามารถนำเข้าแพนด้าในสภาพแวดล้อมการทำงานของคุณได้ โดยทั่วไป หมีแพนด้าจะถูกนำเข้าภายใต้นามแฝง pd :
import pandas as pdDataFrame ใน Pandas คืออะไร?

โครงสร้างข้อมูลพื้นฐานใน pandas คือ data frame data frame คืออาร์เรย์ข้อมูลสองมิติที่มีดัชนี กำกับ และคอลัมน์ที่ มีชื่อ แต่ละคอลัมน์ใน data frame เรียกว่า pandas series แบ่งปันดัชนีร่วมกัน
ต่อไปนี้คือตัวอย่าง data frame ที่เราจะสร้างขึ้นมาใหม่ในอีกไม่กี่นาทีข้างหน้า กรอบข้อมูลนี้มีข้อมูลเกี่ยวกับการใช้จ่ายของนักเรียนหกคนในสี่สัปดาห์

ชื่อของนักเรียนเป็นป้ายชื่อแถว และตั้งชื่อคอลัมน์ว่า 'Week1' ถึง 'Week4' ขอให้สังเกตว่าคอลัมน์ทั้งหมดใช้ป้ายชื่อแถวชุดเดียวกันหรือที่เรียกว่า ดัชนี
วิธีสร้าง Pandas DataFrame
มีหลายวิธีในการสร้างกรอบข้อมูลแพนด้า ในบทช่วยสอนนี้ เราจะพูดถึงวิธีการต่อไปนี้:
- การสร้าง data frame จากอาร์เรย์ NumPy
- การสร้าง data frame จากพจนานุกรม Python
- การสร้าง data frame โดยการอ่านไฟล์ CSV
จากอาร์เรย์ NumPy
ให้เราสร้าง data frame จากอาร์เรย์ NumPy
มาสร้างอาร์เรย์ข้อมูลรูปร่าง (6,4) โดยสมมติว่าในสัปดาห์ใดก็ตาม นักเรียนแต่ละคนใช้จ่ายระหว่าง $0 ถึง $100 ฟังก์ชัน randint() จากโมดูล random ของ NumPy ส่งคืนอาร์เรย์ของจำนวนเต็มแบบสุ่มในช่วงเวลาที่กำหนด [low,high)
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) ในการสร้างเฟรมข้อมูลแพนด้า คุณสามารถใช้ตัวสร้าง DataFrame และส่งผ่านอาร์เรย์ NumPy เป็นอาร์กิวเมนต์ data ดังที่แสดง:
students_df = pd.DataFrame(data=data) ตอนนี้เราสามารถเรียกใช้ฟังก์ชัน type() ในตัวเพื่อตรวจสอบประเภทของ students_df เราเห็นว่ามันเป็นวัตถุ DataFrame
type(students_df) # pandas.core.frame.DataFrame print(students_df) 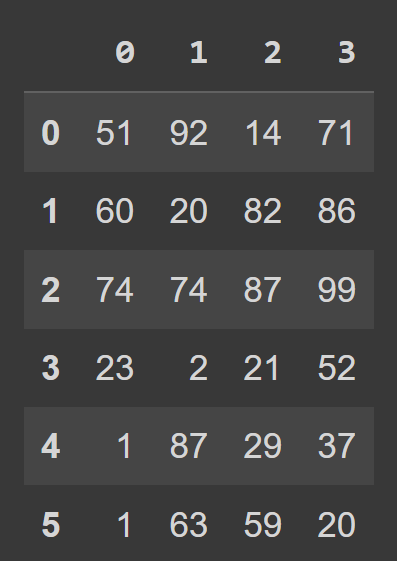
เราเห็นว่าโดยค่าเริ่มต้น เรามีการจัดทำดัชนีช่วงซึ่งเริ่มจาก 0 ถึง numRows – 1 และป้ายชื่อคอลัมน์คือ 0, 1, 2, …, numCols -1 อย่างไรก็ตามสิ่งนี้จะลดความสามารถในการอ่าน จะช่วยเพิ่มชื่อคอลัมน์ที่สื่อความหมายและป้ายชื่อแถวให้กับ data frame
มาสร้างสองรายการ: รายการหนึ่งสำหรับเก็บชื่อของนักเรียนและอีกรายการหนึ่งสำหรับจัดเก็บป้ายชื่อคอลัมน์
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] เมื่อเรียกใช้ตัวสร้าง DataFrame คุณสามารถตั้งค่า index และ columns เป็นรายการของป้ายชื่อแถวและป้ายชื่อคอลัมน์ที่จะใช้ตามลำดับ
students_df = pd.DataFrame(data = data,index = students,columns = cols) ขณะนี้เรามีกรอบข้อมูลของ students_df พร้อมป้ายชื่อแถวและคอลัมน์ที่สื่อความหมาย
print(students_df) 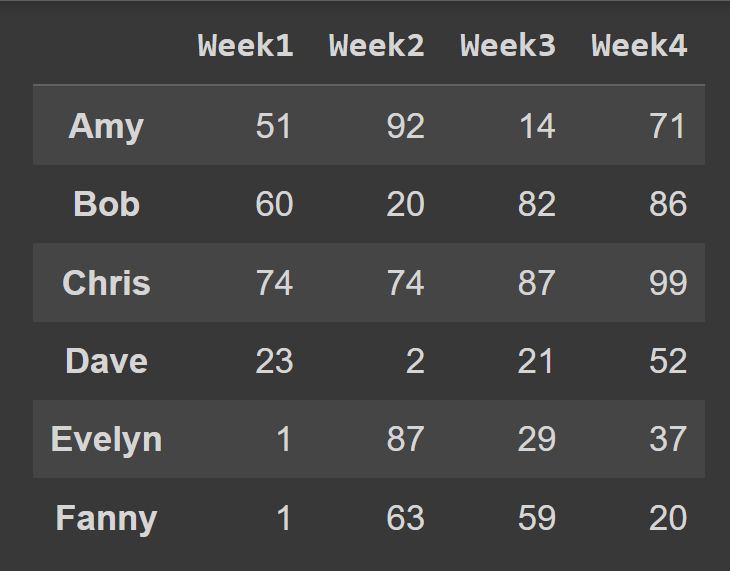
ในการรับข้อมูลพื้นฐานบางอย่างใน data frame เช่น ค่าและประเภทข้อมูลที่ขาดหายไป คุณสามารถเรียกใช้เมธอด info() บน data frame object
students_df.info() 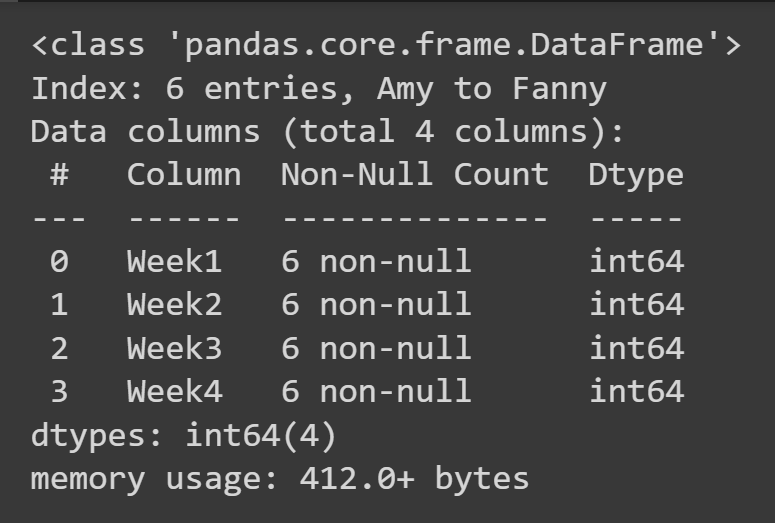
จากพจนานุกรม Python
คุณยังสามารถสร้าง data frame ของ pandas จากพจนานุกรม Python
ที่นี่ data_dict คือพจนานุกรมที่มีข้อมูลของนักเรียน:
- ชื่อของนักเรียนคือกุญแจสำคัญ
- แต่ละค่าคือรายการจำนวนเงินที่นักเรียนแต่ละคนใช้จ่ายตั้งแต่สัปดาห์ที่หนึ่งถึงสี่
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data หากต้องการสร้าง data frame จากพจนานุกรม Python ให้ใช้ from_dict ดังที่แสดงด้านล่าง อาร์กิวเมนต์แรกสอดคล้องกับพจนานุกรมที่มีข้อมูล ( data_dict ) ตามค่าเริ่มต้น คีย์จะใช้เป็น ชื่อคอลัมน์ ของ data frame เนื่องจากเราต้องการตั้งค่าคีย์เป็น ป้ายกำกับแถว ให้ตั้งค่า orient= 'index'
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 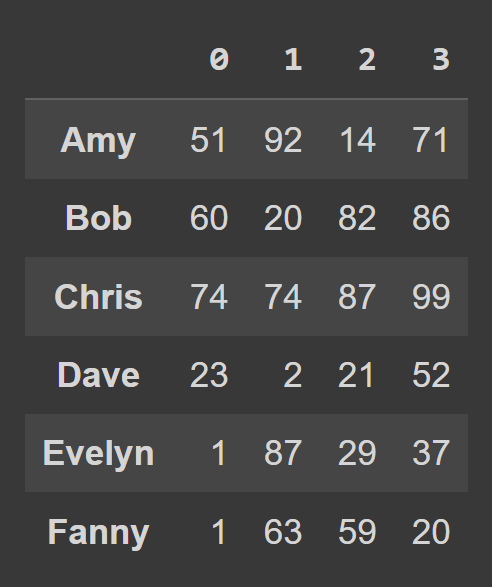
หากต้องการเปลี่ยนชื่อคอลัมน์เป็นหมายเลขสัปดาห์ เราจะตั้งค่าคอลัมน์เป็นรายการ cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 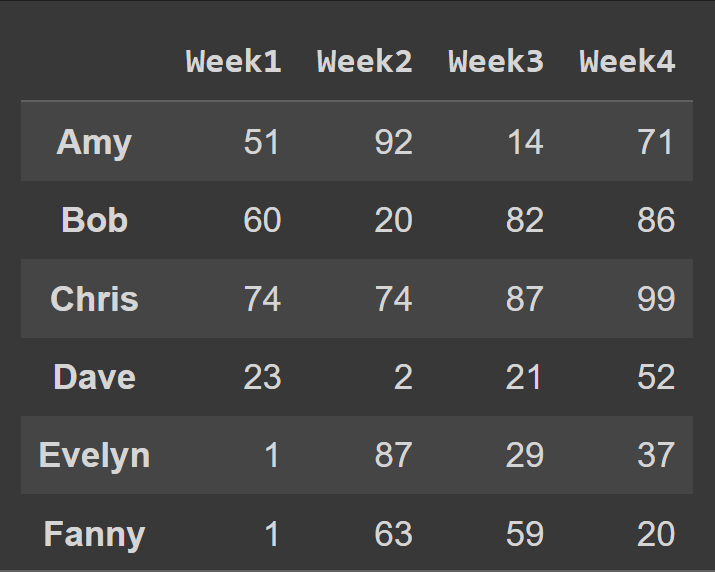
อ่านในไฟล์ CSV ลงใน Pandas DataFrame
สมมติว่าข้อมูลของนักเรียนเป็นไฟล์ CSV คุณสามารถใช้ read_csv() เพื่ออ่านข้อมูลจากไฟล์ไปยังเฟรมข้อมูลแพนด้า pd.read_csv('file-path') คือไวยากรณ์ทั่วไป โดยที่ file-path คือเส้นทางไปยังไฟล์ CSV เราสามารถตั้งค่าพารามิเตอร์ names เป็นรายชื่อคอลัมน์ที่จะใช้
students_df = pd.read_csv('/content/students.csv',names=cols)ตอนนี้เรารู้วิธีสร้าง data frame แล้ว เรามาเรียนรู้วิธีเลือกแถวและคอลัมน์กัน
เลือกคอลัมน์จาก Pandas DataFrame
มีหลายวิธีที่คุณสามารถใช้เพื่อเลือกแถวและคอลัมน์จาก data frame บทช่วยสอนนี้จะกล่าวถึงวิธีทั่วไปในการเลือกคอลัมน์ แถว และทั้งแถวและคอลัมน์จาก data frame
การเลือกคอลัมน์เดียว
หากต้องการเลือกคอลัมน์เดียว คุณสามารถใช้ df_name[col_name] โดยที่ col_name เป็นสตริงที่แสดงชื่อของคอลัมน์
ที่นี่ เราเลือกเฉพาะคอลัมน์ 'สัปดาห์ที่ 1'
week1_df = students_df['Week1'] print(week1_df) 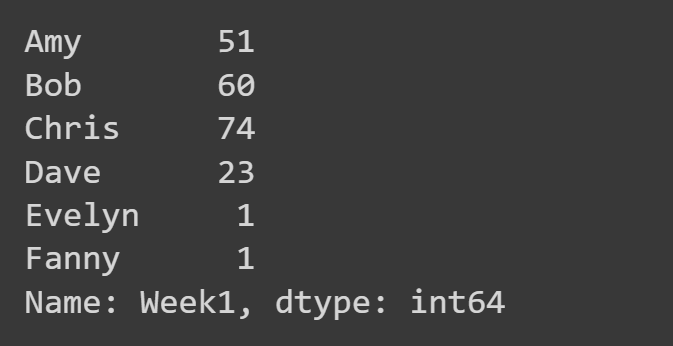
การเลือกหลายคอลัมน์
หากต้องการเลือกหลายคอลัมน์จาก data frame ให้ส่งรายการชื่อคอลัมน์ทั้งหมดเพื่อเลือก
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 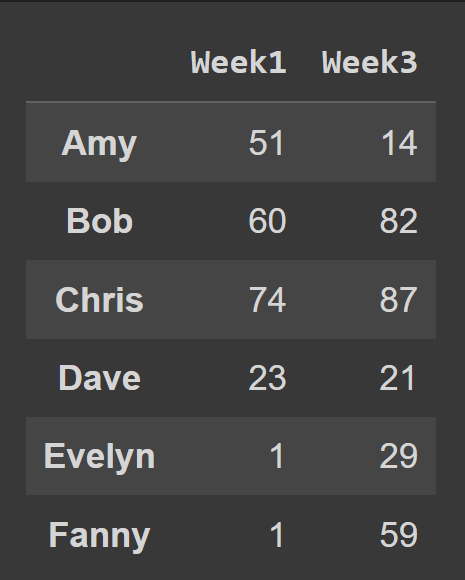
นอกจากวิธีนี้แล้ว คุณยังสามารถใช้ iloc() และ loc() เพื่อเลือกคอลัมน์ เราจะเขียนโค้ดตัวอย่างในภายหลัง
เลือกแถวจาก Pandas DataFrame

ใช้ .iloc() วิธีการ
ในการเลือกแถวโดยใช้ iloc() ให้ส่งดัชนีที่สอดคล้องกับแถวทั้งหมดเป็นรายการ
ในตัวอย่างนี้ เราเลือกแถวที่ดัชนีคี่
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 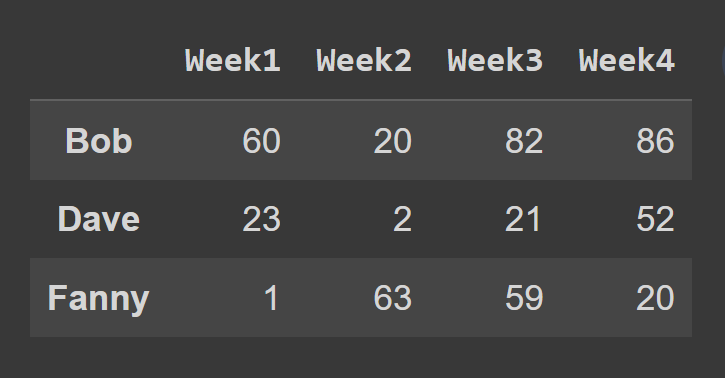
ต่อไป เราเลือกชุดย่อยของ data frame ที่มีแถวที่ดัชนี 0 ถึง 2 โดยค่าเริ่มต้นจะไม่รวมจุดสิ้นสุดที่ 3
slice1 = students_df.iloc[0:3] print(slice1) 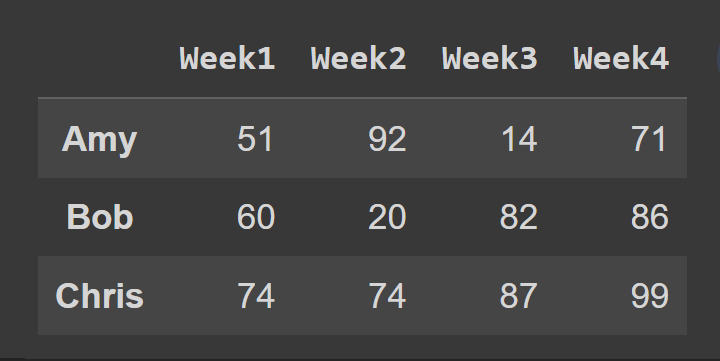
ใช้ .loc() วิธีการ
หากต้องการเลือกแถวของ data frame โดยใช้เมธอด loc() คุณควรระบุป้ายกำกับที่ตรงกับแถวที่คุณต้องการเลือก
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 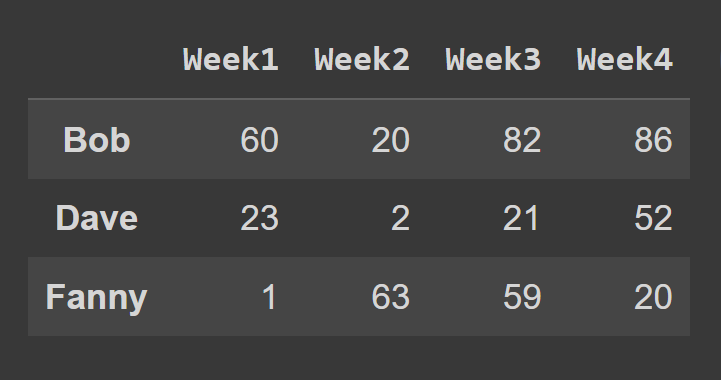
หากแถวของกรอบข้อมูลถูกจัดทำดัชนีโดยใช้ช่วงดีฟอลต์ 0, 1, 2 จนถึง
numRows-1 การใช้iloc()และloc()จะเทียบเท่ากัน
เลือกแถวและคอลัมน์จาก Pandas DataFrame
ถึงตอนนี้ คุณได้เรียนรู้วิธีเลือกแถวหรือคอลัมน์จากกรอบข้อมูลแพนด้าแล้ว อย่างไรก็ตาม บางครั้งคุณอาจต้องเลือกชุดย่อยของ ทั้ง แถวและคอลัมน์ แล้วคุณจะทำอย่างไร? คุณสามารถใช้ iloc() และ loc() ที่เราพูดถึง
ตัวอย่างเช่น ในข้อมูลโค้ดด้านล่าง เราเลือกแถวและคอลัมน์ ทั้งหมด ที่ดัชนี 2 และ 3
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 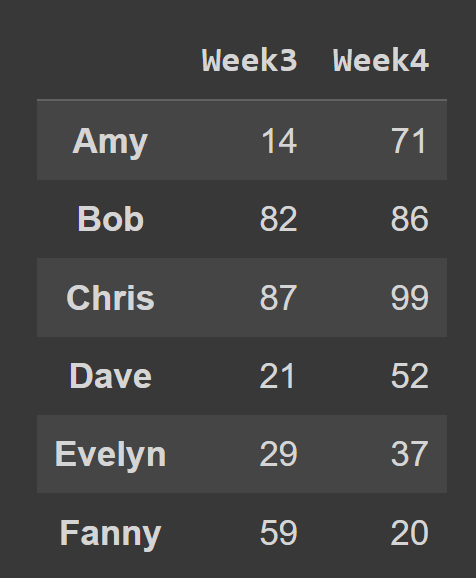
การใช้ start:stop สร้างชิ้นส่วนตั้งแต่ start จนถึงแต่ไม่รวม stop ดังนั้น เมื่อคุณละเว้นทั้งค่า start และค่า stop เมื่อคุณเพิกเฉยต่อค่าเริ่มต้นและค่าหยุด การแบ่งส่วนจะเริ่มที่จุดเริ่มต้น—และขยายไปจนถึงจุดสิ้นสุดของกรอบข้อมูล—การเลือกแถว ทั้งหมด
เมื่อใช้เมธอด loc() คุณต้องส่งป้ายกำกับของแถวและคอลัมน์ที่คุณต้องการเลือก ดังที่แสดง:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 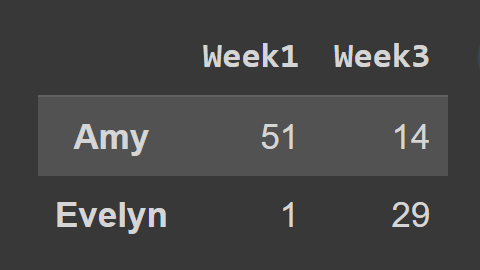
ที่นี่ dataframe subset_df2 มีบันทึกของ Amy และ Evelyn สำหรับสัปดาห์ที่ 1 และสัปดาห์ที่ 3
บทสรุป
นี่คือการทบทวนอย่างรวดเร็วเกี่ยวกับสิ่งที่คุณได้เรียนรู้ในบทช่วยสอนนี้:
- หลังจากติดตั้ง pandas แล้ว คุณสามารถนำเข้าภายใต้นามแฝง
pdในการสร้างออบเจ็กต์ data frame ของ pandas คุณสามารถใช้ตัวสร้างpd.DataFrame(data)โดยที่dataอ้างอิงถึงอาร์เรย์ N-dimensional หรือตัวสร้างที่วนซ้ำได้ซึ่งมีข้อมูลอยู่ คุณสามารถระบุแถวและดัชนีและป้ายชื่อคอลัมน์ได้โดยการตั้งค่าพารามิเตอร์ดัชนีและคอลัมน์ที่เป็น ทางเลือก ตามลำดับ - การใช้
pd.read_csv(path-to-the-file)อ่านเนื้อหาของไฟล์ลงใน data frame - คุณสามารถเรียกเมธอด
info()บน data frame object เพื่อรับข้อมูลเกี่ยวกับคอลัมน์ จำนวนของค่าที่หายไป ประเภทข้อมูล และขนาดของ data frame - หากต้องการเลือกคอลัมน์เดียว ให้ใช้
df_name[col_name]และหากต้องการเลือกหลายคอลัมน์ โดยเฉพาะคอลัมน์df_name[[col1,col2,...,coln]] - คุณยังสามารถเลือกคอลัมน์และแถวโดยใช้เมธอด
loc()และiloc() - ในขณะที่
iloc()ใช้ดัชนี (หรือส่วนดัชนี) ของแถวและคอลัมน์ที่จะเลือก เมธอดloc()จะใช้ป้ายกำกับแถวและคอลัมน์
คุณสามารถดูตัวอย่างที่ใช้ในบทแนะนำนี้ได้ในสมุดบันทึก Colab นี้
ต่อไป ลองดูรายชื่อสมุดบันทึกด้านวิทยาศาสตร์ข้อมูลเพื่อการทำงานร่วมกันนี้