
Pandas DataFrame을 만드는 방법 [예제 포함]
게시 됨: 2022-12-08강력한 데이터 조작 라이브러리인 pandas의 기본 데이터 구조인 pandas DataFrames 작업의 기본 사항을 알아보세요.
Python에서 데이터 분석을 시작하려는 경우 pandas는 작업 방법을 배워야 하는 첫 번째 라이브러리 중 하나입니다. CSV 파일 및 데이터베이스와 같은 여러 소스에서 데이터를 가져오는 것부터 누락된 데이터를 처리하고 이를 분석하여 통찰력을 얻는 것까지 - Pandas는 위의 모든 작업을 수행합니다.
pandas로 데이터 분석을 시작하려면 pandas의 기본 데이터 구조인 데이터 프레임 을 이해해야 합니다.
이 자습서에서는 pandas 데이터 프레임의 기본 사항과 데이터 프레임을 만드는 일반적인 방법을 배웁니다. 그런 다음 데이터 하위 집합을 검색하기 위해 데이터 프레임에서 행과 열을 선택하는 방법을 배웁니다.
이 모든 것을 시작하겠습니다.
Pandas 설치 및 가져오기
pandas는 타사 데이터 분석 라이브러리이므로 먼저 설치해야 합니다. 프로젝트의 가상 환경에 외부 패키지를 설치하는 것이 좋습니다.
Python의 Anaconda 배포판을 사용하는 경우 패키지 관리에 conda 를 사용할 수 있습니다.
conda install pandaspip를 사용하여 팬더를 설치할 수도 있습니다.
pip install pandaspandas 라이브러리에는 NumPy가 종속 항목으로 필요합니다. 따라서 NumPy가 아직 설치되지 않은 경우 설치 프로세스 중에 NumPy도 설치됩니다.
Pandas를 설치한 후 작업 환경으로 가져올 수 있습니다. 일반적으로 pandas는 pd 별칭으로 가져옵니다.
import pandas as pdPandas의 DataFrame이란 무엇입니까?

pandas의 기본 데이터 구조는 데이터 프레임 입니다. 데이터 프레임은 레이블 이 지정된 인덱스와 명명된 열이 있는 데이터의 2차원 배열입니다. pandas series 라는 데이터 프레임의 각 열은 공통 인덱스를 공유합니다.
다음은 앞으로 몇 분 동안 처음부터 새로 만들 예제 데이터 프레임입니다. 이 데이터 프레임에는 6명의 학생이 4주 동안 지출한 금액에 대한 데이터가 포함되어 있습니다.

학생의 이름은 행 레이블입니다. 그리고 열 이름은 'Week1'에서 'Week4'로 지정됩니다. 모든 열은 색인 이라고도 하는 동일한 행 레이블 집합을 공유합니다.
Pandas DataFrame을 만드는 방법
팬더 데이터 프레임을 만드는 방법에는 여러 가지가 있습니다. 이 자습서에서는 다음 방법에 대해 설명합니다.
- NumPy 배열에서 데이터 프레임 만들기
- Python 사전에서 데이터 프레임 만들기
- CSV 파일을 읽어서 데이터 프레임 만들기
NumPy 배열에서
NumPy 배열에서 데이터 프레임을 만들어 보겠습니다.
주어진 주에 각 학생이 $0에서 $100 사이를 지출한다고 가정하고 모양이 (6,4)인 데이터 배열을 만들어 봅시다. NumPy의 random 모듈에 있는 randint() 함수는 주어진 간격 [low,high) 에서 임의의 정수 배열을 반환합니다.
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) pandas 데이터 프레임을 만들려면 다음과 같이 DataFrame 생성자를 사용하고 NumPy 배열을 data 인수로 전달할 수 있습니다.
students_df = pd.DataFrame(data=data) 이제 내장된 type() 함수를 호출하여 Students_df 의 유형을 확인할 수 students_df . DataFrame 개체임을 알 수 있습니다.
type(students_df) # pandas.core.frame.DataFrame print(students_df) 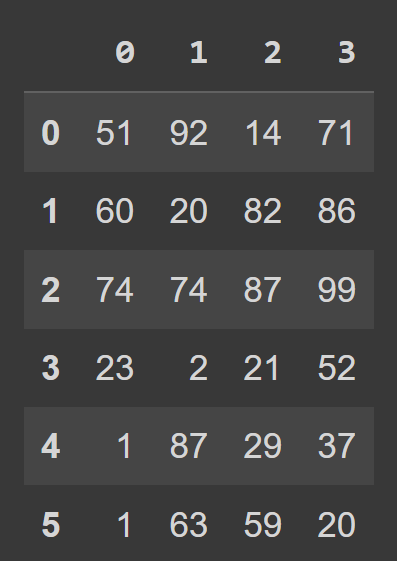
기본적으로 0에서 numRows – 1까지의 범위 인덱싱이 있고 열 레이블은 0, 1, 2, …, numCols -1임을 알 수 있습니다. 그러나 이것은 가독성을 떨어뜨립니다. 데이터 프레임에 설명 열 이름과 행 레이블을 추가하는 데 도움이 됩니다.
목록 두 개를 만들어 보겠습니다. 하나는 학생 이름을 저장하고 다른 하나는 열 레이블을 저장합니다.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] DataFrame 생성자를 호출할 때 index 와 columns 을 각각 사용할 행 레이블과 열 레이블 목록으로 설정할 수 있습니다.
students_df = pd.DataFrame(data = data,index = students,columns = cols) 이제 설명 행 및 열 레이블이 있는 Students_df 데이터 프레임이 students_df .
print(students_df) 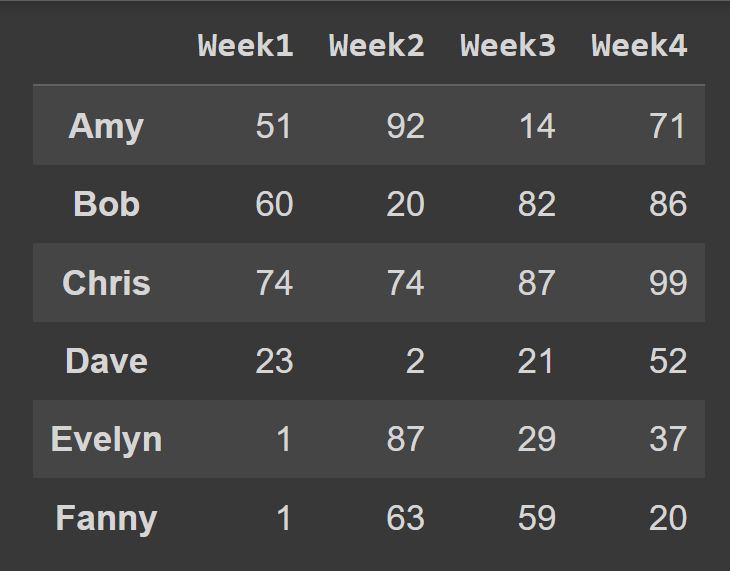
누락된 값 및 데이터 유형과 같은 데이터 프레임에 대한 일부 기본 정보를 얻으려면 데이터 프레임 객체에서 info() 메서드를 호출할 수 있습니다.
students_df.info() 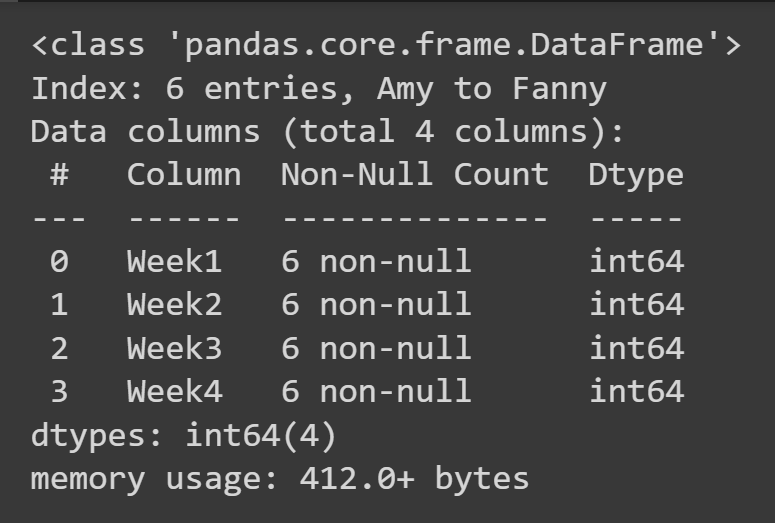
파이썬 사전에서
Python 사전에서 pandas 데이터 프레임을 만들 수도 있습니다.
여기서 data_dict 는 학생 데이터를 포함하는 사전입니다.
- 학생들의 이름이 열쇠입니다.
- 각 값은 각 학생이 1주에서 4주까지 지출한 금액 목록입니다.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Python 사전에서 데이터 프레임을 만들려면 아래와 같이 from_dict 를 사용합니다. 첫 번째 인수는 데이터( data_dict )를 포함하는 사전에 해당합니다. 기본적으로 키는 데이터 프레임의 열 이름 으로 사용됩니다. 키를 행 레이블 로 설정하려면 orient= 'index' 로 설정하십시오.
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 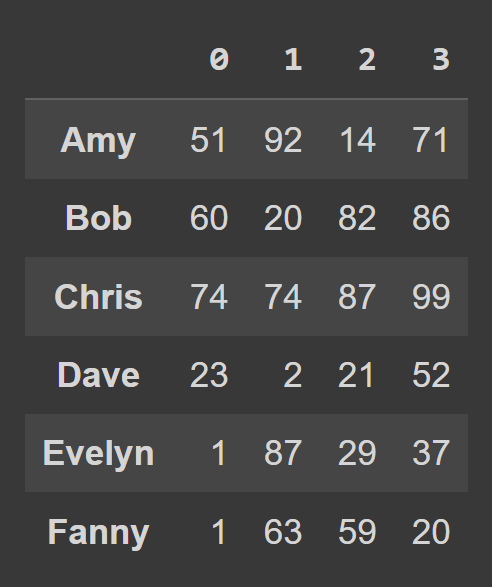
열 이름을 주 번호로 변경하려면 열을 cols 목록으로 설정합니다.

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 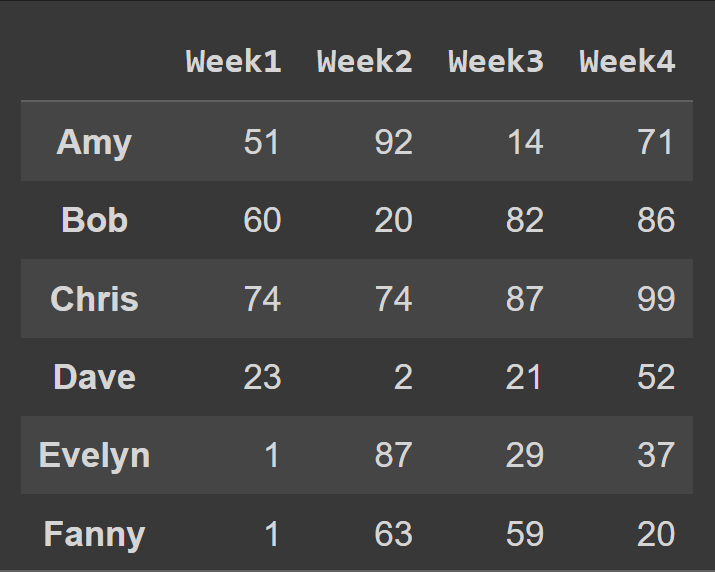
Pandas DataFrame으로 CSV 파일 읽기
학생 데이터를 CSV 파일로 사용할 수 있다고 가정합니다. read_csv() 함수를 사용하여 파일에서 pandas 데이터 프레임으로 데이터를 읽을 수 있습니다. pd.read_csv('file-path') 는 일반 구문이며 여기서 file-path 는 CSV 파일의 경로입니다. 사용할 열 이름 목록에 names 매개변수를 설정할 수 있습니다.
students_df = pd.read_csv('/content/students.csv',names=cols)이제 데이터 프레임을 만드는 방법을 알았으니 행과 열을 선택하는 방법을 알아보겠습니다.
Pandas DataFrame에서 열 선택
데이터 프레임에서 행과 열을 선택하는 데 사용할 수 있는 몇 가지 기본 제공 메서드가 있습니다. 이 자습서에서는 데이터 프레임에서 열, 행 및 행과 열을 모두 선택하는 가장 일반적인 방법을 살펴봅니다.
단일 열 선택
단일 열을 선택하려면 df_name[col_name] 을 사용할 수 있습니다. 여기서 col_name 은 열 이름을 나타내는 문자열입니다.
여기서는 'Week1' 열만 선택합니다.
week1_df = students_df['Week1'] print(week1_df) 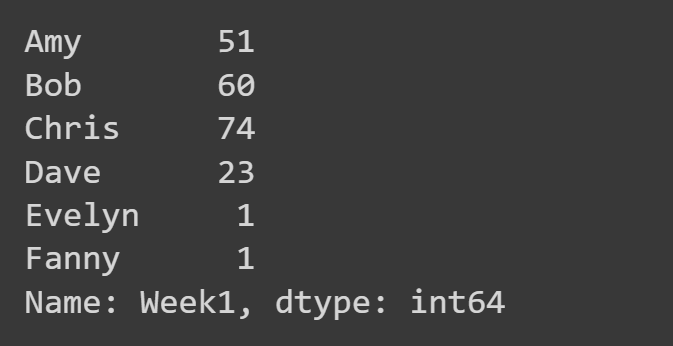
여러 열 선택
데이터 프레임에서 여러 열을 선택하려면 선택할 모든 열 이름 목록을 전달합니다.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 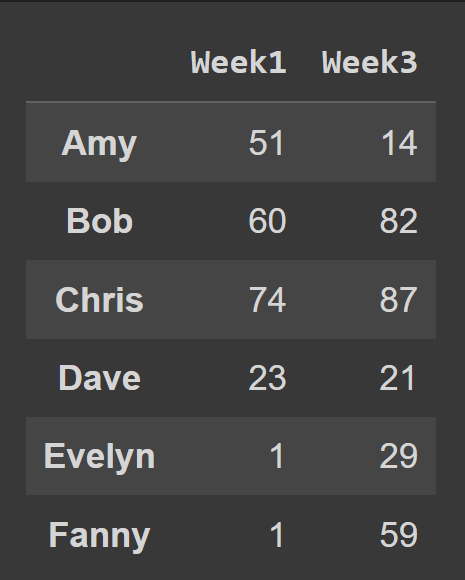
이 메서드 외에도 iloc() 및 loc() 메서드를 사용하여 열을 선택할 수도 있습니다. 나중에 예제를 코딩하겠습니다.
Pandas DataFrame에서 행 선택

.iloc() 메서드 사용
iloc() 메서드를 사용하여 행을 선택하려면 모든 행에 해당하는 인덱스를 목록으로 전달합니다.
이 예에서는 홀수 인덱스의 행을 선택합니다.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 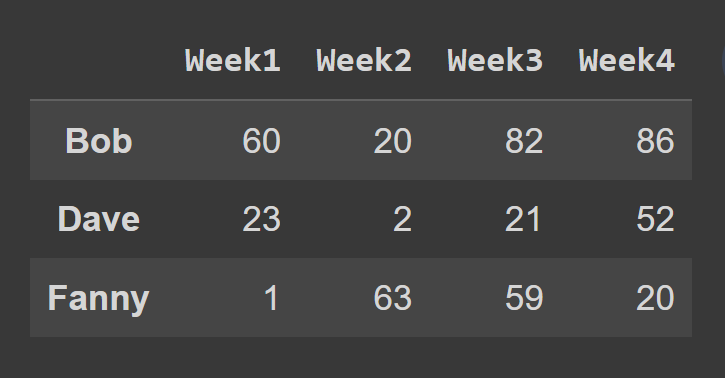
다음으로 인덱스 0에서 2까지의 행을 포함하는 데이터 프레임의 하위 집합을 선택합니다. 끝점 3은 기본적으로 제외됩니다.
slice1 = students_df.iloc[0:3] print(slice1) 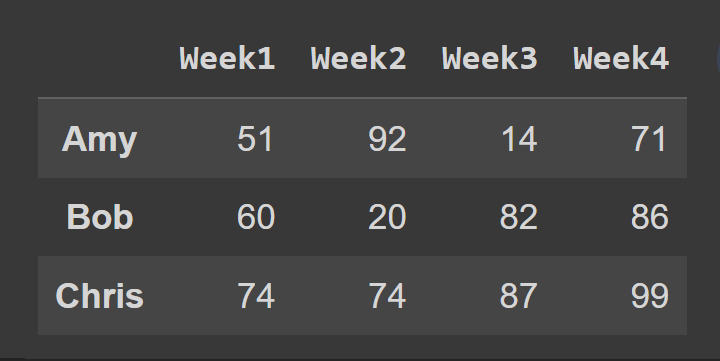
.loc() 메서드 사용
loc() 메서드를 사용하여 데이터 프레임의 행을 선택하려면 선택하려는 행에 해당하는 레이블을 지정해야 합니다.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 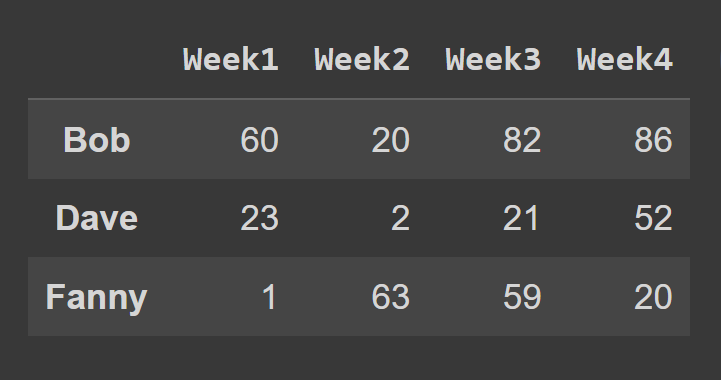
데이터 프레임의 행이 기본 범위 0, 1, 2, 최대
numRows-1을 사용하여 인덱싱되는 경우iloc()및loc()을 사용하는 것은 모두 동일합니다.
Pandas DataFrame에서 행과 열 선택
지금까지 pandas 데이터 프레임에서 행 또는 열을 선택하는 방법을 배웠습니다. 그러나 경우에 따라 행과 열 모두 의 하위 집합을 선택해야 할 수도 있습니다. 그래서 어떻게 합니까? 우리가 논의한 iloc() 및 loc() 메서드를 사용할 수 있습니다.
예를 들어 아래 코드 스니펫에서는 인덱스 2와 3에 있는 모든 행과 열을 선택합니다.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 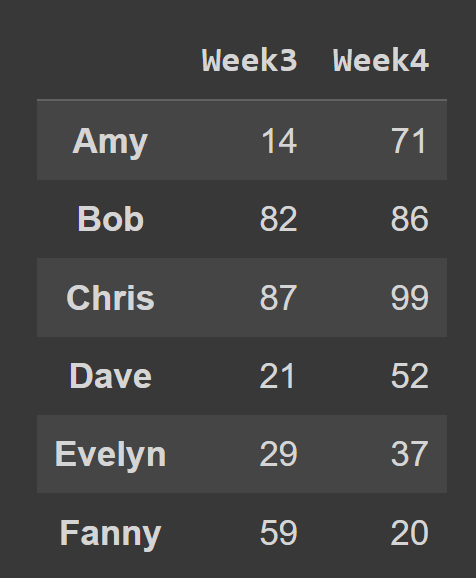
start:stop 을 사용하면 시작부터 start 까지 슬라이스가 생성되지만 stop 은 포함되지 않습니다. 따라서 시작 값과 중지 값을 모두 무시하면 start 값과 stop 값을 무시하면 조각이 처음부터 시작하여 데이터 프레임의 끝까지 확장되어 모든 행을 선택합니다.
loc() 메서드를 사용할 때 다음과 같이 선택하려는 행과 열의 레이블을 전달해야 합니다.
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 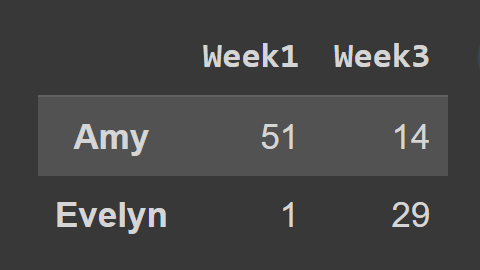
여기에서 subset_df2 데이터 프레임에는 1주차와 3주차에 대한 Amy와 Evelyn의 레코드가 포함되어 있습니다.
결론
다음은 이 자습서에서 배운 내용에 대한 간단한 검토입니다.
- pandas를 설치한 후 별칭
pd로 가져올 수 있습니다. pandas 데이터 프레임 객체를 생성하려면pd.DataFrame(data)생성자를 사용할 수 있습니다. 여기서data는 N차원 배열 또는 데이터를 포함하는 iterable을 나타냅니다. 선택적 인덱스 및 열 매개 변수를 각각 설정하여 행 및 인덱스와 열 레이블을 지정할 수 있습니다. -
pd.read_csv(path-to-the-file)를 사용하면 파일 내용을 데이터 프레임으로 읽어들입니다. - 데이터 프레임 개체에서
info()메서드를 호출하여 열, 누락된 값의 수, 데이터 유형 및 데이터 프레임 크기에 대한 정보를 얻을 수 있습니다. - 단일 열을 선택하려면
df_name[col_name]을 사용하고 여러 열, 특정 열을 선택하려면df_name[[col1,col2,...,coln]]을 사용합니다. -
loc()및iloc()메서드를 사용하여 열과 행을 선택할 수도 있습니다. -
iloc()메서드는 선택할 행과 열의 인덱스(또는 인덱스 슬라이스)를 가져오는 반면loc()메서드는 행과 열 레이블을 가져옵니다.
이 Colab 노트북에서 이 튜토리얼에 사용된 예제를 찾을 수 있습니다.
다음으로 협업 데이터 사이언스 노트북 목록을 확인하세요.