
Come creare un dataframe Pandas [con esempi]
Pubblicato: 2022-12-08Impara le basi per lavorare con i panda DataFrame: la struttura dei dati di base in panda, una potente libreria per la manipolazione dei dati.
Se desideri iniziare con l'analisi dei dati in Python, i panda sono una delle prime librerie con cui dovresti imparare a lavorare. Dall'importazione di dati da più fonti come file CSV e database alla gestione dei dati mancanti e all'analisi per ottenere approfondimenti: i panda ti permettono di fare tutto quanto sopra.
Per iniziare ad analizzare i dati con i panda, dovresti comprendere la struttura fondamentale dei dati nei panda: i frame di dati .
In questo tutorial imparerai le basi dei dataframe panda e i metodi comuni per creare dataframe. Imparerai quindi a selezionare righe e colonne dal dataframe per recuperare sottoinsiemi di dati.
Per tutto questo e molto altro, iniziamo.
Installazione e importazione di Panda
Poiché pandas è una libreria di analisi dei dati di terze parti, dovresti prima installarla. Si consiglia di installare pacchetti esterni in un ambiente virtuale per il progetto.
Se usi la distribuzione Anaconda di Python, puoi usare conda per la gestione dei pacchetti.
conda install pandasPuoi anche installare panda usando pip:
pip install pandasLa libreria Pandas richiede NumPy come dipendenza. Quindi, se NumPy non è già installato, verrà installato anche durante il processo di installazione.
Dopo aver installato i panda, puoi importarlo nel tuo ambiente di lavoro. In generale, i panda vengono importati con l'alias pd :
import pandas as pdCos'è un DataFrame in Pandas?

La struttura dati fondamentale nei panda è il data frame . Un frame di dati è un array bidimensionale di dati con indice etichettato e colonne denominate . Ogni colonna nel frame di dati chiamato pandas series condivide un indice comune.
Ecco un frame di dati di esempio che creeremo da zero nei prossimi minuti. Questo frame di dati contiene dati su quanto spendono sei studenti in quattro settimane.

I nomi degli studenti sono le etichette delle righe. E le colonne sono denominate da "Settimana 1" a "Settimana 4". Si noti che tutte le colonne condividono lo stesso set di etichette di riga, chiamato anche index .
Come creare un dataframe Pandas
Esistono diversi modi per creare un frame di dati Panda. In questo tutorial, discuteremo i seguenti metodi:
- Creazione di un frame di dati da array NumPy
- Creazione di un frame di dati da un dizionario Python
- Creazione di un frame di dati mediante la lettura di file CSV
Da NumPy Array
Creiamo un frame di dati da un array NumPy.
Creiamo l'array di dati di forma (6,4) supponendo che in una data settimana ogni studente spenda tra $0 e $100. La funzione randint() del modulo random di NumPy restituisce un array di numeri interi casuali in un dato intervallo, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Per creare un data frame pandas, puoi usare il costruttore DataFrame e passare l'array NumPy come argomento data , come mostrato:
students_df = pd.DataFrame(data=data) Ora possiamo chiamare la funzione incorporata type() per controllare il tipo di students_df . Vediamo che è un oggetto DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 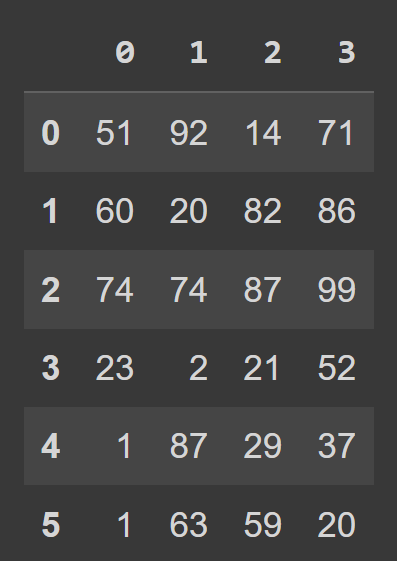
Vediamo che per impostazione predefinita abbiamo l'indicizzazione dell'intervallo che va da 0 a numRows – 1 e le etichette delle colonne sono 0, 1, 2, …, numCols -1. Tuttavia, questo riduce la leggibilità. Aiuterà ad aggiungere nomi di colonna descrittivi ed etichette di riga al frame di dati.
Creiamo due elenchi: uno per memorizzare i nomi degli studenti e un altro per memorizzare le etichette delle colonne.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Quando si chiama il costruttore DataFrame , è possibile impostare rispettivamente l' index e le columns sugli elenchi di etichette di riga e di etichette di colonna da usare.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Ora abbiamo il frame di dati students_df con etichette descrittive di righe e colonne.
print(students_df) 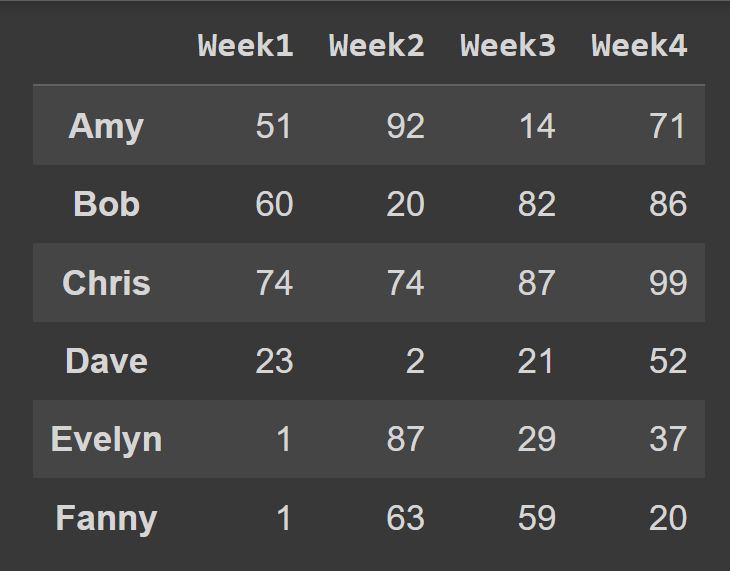
Per ottenere alcune informazioni di base sul frame di dati, come valori mancanti e tipi di dati, è possibile chiamare il metodo info() sull'oggetto frame di dati.
students_df.info() 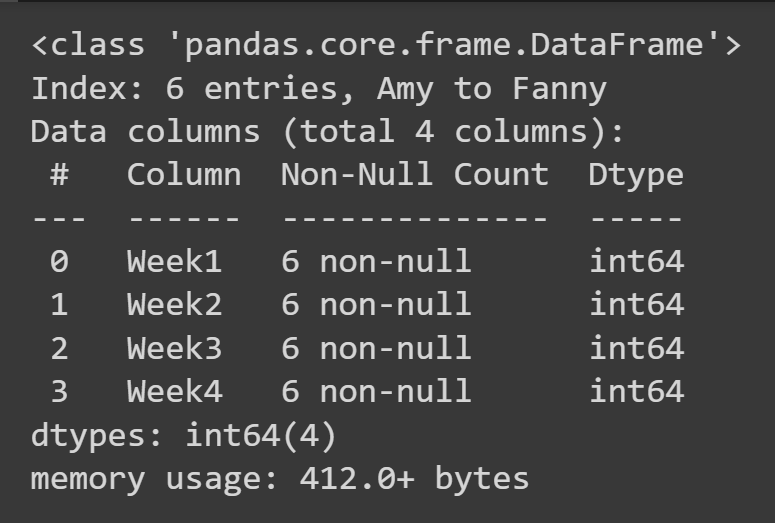
Da un dizionario Python
Puoi anche creare un frame di dati panda da un dizionario Python.
Qui, data_dict è il dizionario contenente i dati degli studenti:
- I nomi degli studenti sono le chiavi.
- Ogni valore è un elenco di quanto ogni studente spende dalla prima alla quarta settimana.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Per creare un frame di dati da un dizionario Python, utilizzare from_dict , come mostrato di seguito. Il primo argomento corrisponde al dizionario contenente i dati ( data_dict ). Per impostazione predefinita, le chiavi vengono utilizzate come nomi di colonna del frame di dati. Dato che vorremmo impostare le chiavi come etichette di riga , set orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 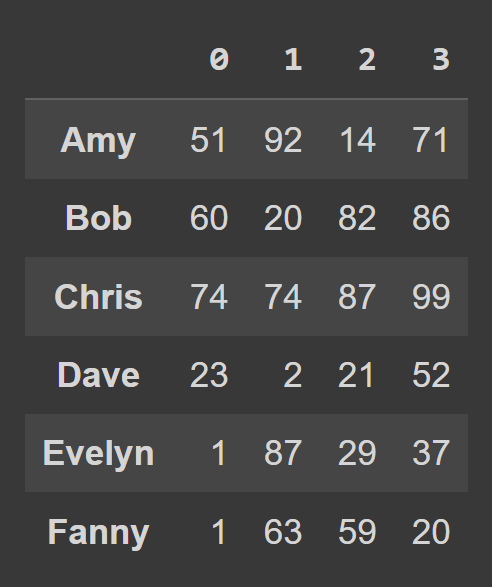
Per modificare i nomi delle colonne nel numero della settimana, cols le colonne nell'elenco delle colonne:

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 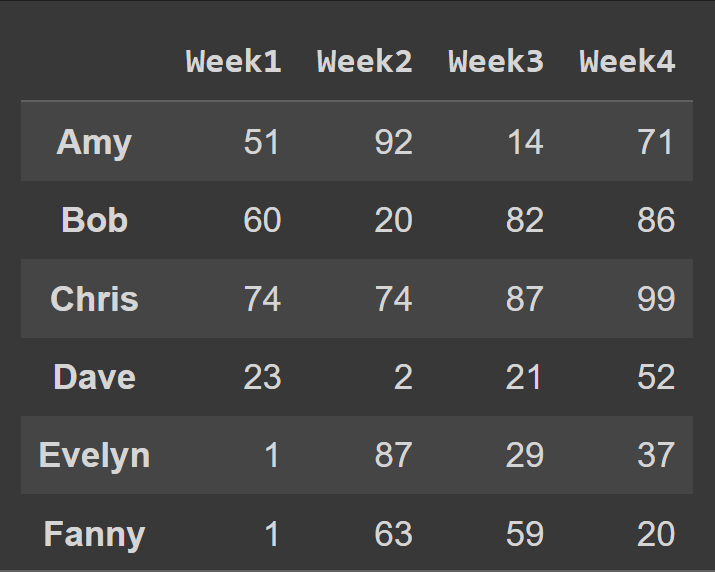
Leggi in un file CSV in un DataFrame Pandas
Supponiamo che i dati dello studente siano disponibili in un file CSV. È possibile utilizzare la funzione read_csv() per leggere i dati dal file in un frame di dati panda. pd.read_csv('file-path') è la sintassi generale, dove file-path è il percorso del file CSV. Possiamo impostare il parametro names sull'elenco dei nomi di colonna da utilizzare.
students_df = pd.read_csv('/content/students.csv',names=cols)Ora che sappiamo come creare un frame di dati, impariamo a selezionare righe e colonne.
Seleziona Colonne da un DataFrame Pandas
Esistono diversi metodi integrati che è possibile utilizzare per selezionare righe e colonne da un frame di dati. Questo tutorial esaminerà i modi più comuni per selezionare colonne, righe e sia righe che colonne da un frame di dati.
Selezione di una singola colonna
Per selezionare una singola colonna, puoi usare df_name[col_name] dove col_name è la stringa che denota il nome della colonna.
Qui selezioniamo solo la colonna "Settimana1".
week1_df = students_df['Week1'] print(week1_df) 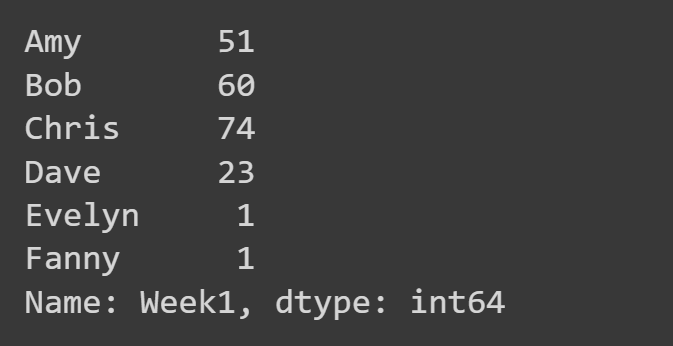
Selezione di più colonne
Per selezionare più colonne dal data frame, passare l'elenco di tutti i nomi delle colonne da selezionare.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 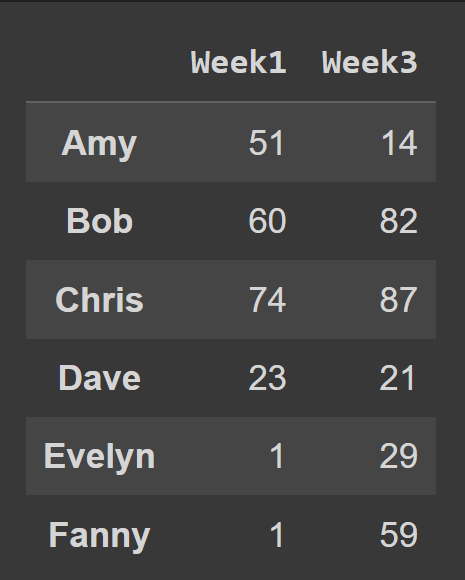
Oltre a questo metodo, puoi anche utilizzare i iloc() e loc() per selezionare le colonne. Codificheremo un esempio in seguito.
Seleziona Righe da un DataFrame Pandas

Utilizzando il metodo .iloc()
Per selezionare le righe utilizzando il metodo iloc() , passare gli indici corrispondenti a tutte le righe come un elenco.
In questo esempio, selezioniamo le righe con indice dispari.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 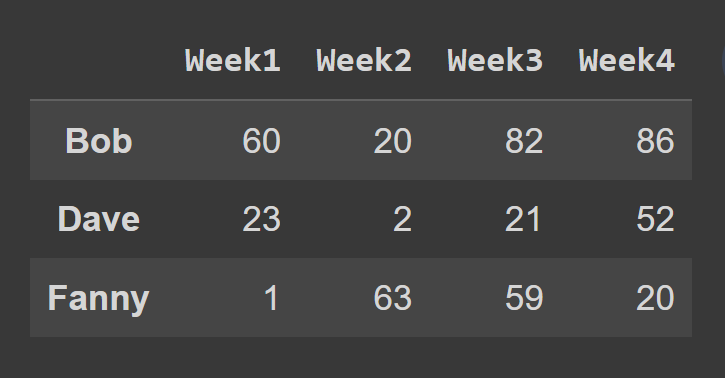
Successivamente, selezioniamo un sottoinsieme del frame di dati contenente le righe all'indice da 0 a 2, il punto finale 3 è escluso per impostazione predefinita.
slice1 = students_df.iloc[0:3] print(slice1) 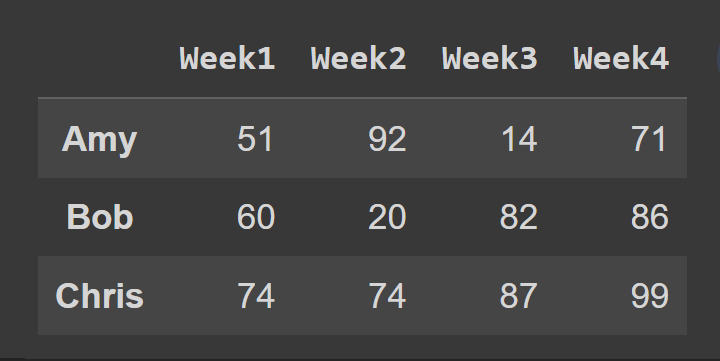
Utilizzando il metodo .loc()
Per selezionare le righe di un frame di dati utilizzando il metodo loc() , è necessario specificare le etichette corrispondenti alle righe che si desidera selezionare.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 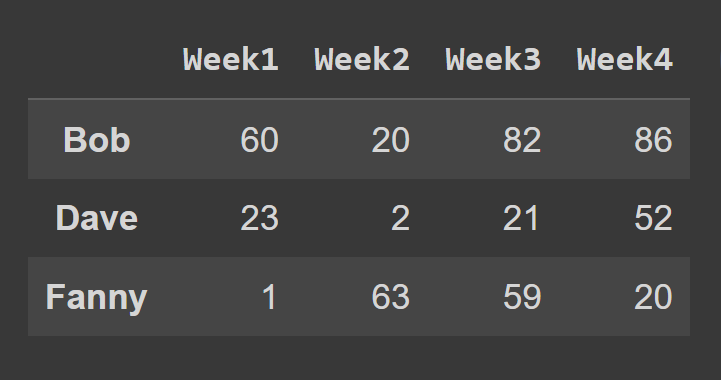
Se le righe del frame di dati sono indicizzate utilizzando l'intervallo predefinito 0, 1, 2, fino a
numRows-1, l'utilizzoiloc()eloc()sono entrambi equivalenti.
Seleziona righe e colonne da un dataframe Pandas
Finora, hai imparato a selezionare righe o colonne da un frame di dati panda. Tuttavia, a volte potrebbe essere necessario selezionare un sottoinsieme di righe e colonne. Quindi come lo fai? Puoi usare i iloc() e loc() di cui abbiamo parlato.
Ad esempio, nello snippet di codice seguente, selezioniamo tutte le righe e le colonne all'indice 2 e 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 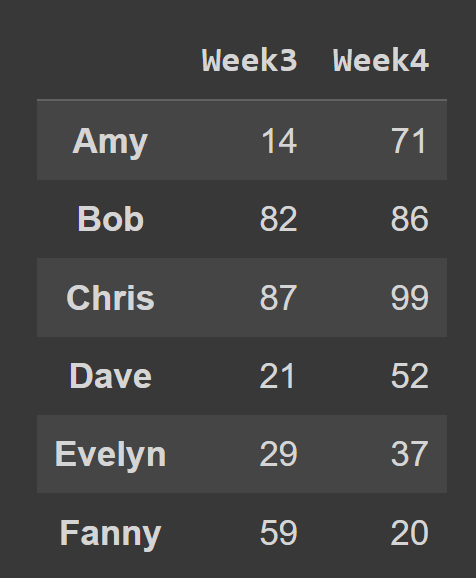
L'utilizzo di start:stop crea una sezione da start up a ma non includendo stop . Quindi, quando ignori entrambi i valori di start e di stop , quando ignori i valori di inizio e di fine, la sezione inizia dall'inizio e si estende fino alla fine del frame di dati, selezionando tutte le righe.
Quando si utilizza il metodo loc() , è necessario passare le etichette delle righe e delle colonne che si desidera selezionare, come mostrato:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 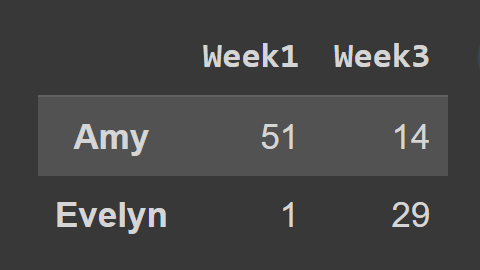
Qui, il dataframe subset_df2 contiene il record di Amy ed Evelyn per Week1 e Week3.
Conclusione
Ecco una rapida rassegna di ciò che hai imparato in questo tutorial:
- Dopo aver installato Pandas, puoi importarlo con l'alias
pd. Per creare un oggetto frame di dati pandas, è possibile utilizzare ilpd.DataFrame(data), dovedatafa riferimento all'array N-dimensionale o a un iterabile contenente i dati. È possibile specificare le etichette di riga, indice e colonna impostando rispettivamente i parametri facoltativi di indice e colonne. - L'utilizzo
pd.read_csv(path-to-the-file)legge il contenuto del file in un frame di dati. - È possibile chiamare il metodo
info()sull'oggetto data frame per ottenere informazioni sulle colonne, il numero di valori mancanti, i tipi di dati e la dimensione del data frame. - Per selezionare una singola colonna, utilizzare
df_name[col_name]e per selezionare più colonne, colonna particolare,df_name[[col1,col2,...,coln]]. - Puoi anche selezionare colonne e righe usando i metodi
loc()eiloc(). - Mentre il metodo
iloc()prende l'indice (o la porzione di indice) delle righe e delle colonne da selezionare, il metodoloc()prende le etichette di riga e colonna.
Puoi trovare gli esempi utilizzati in questo tutorial in questo taccuino Colab.
Successivamente, dai un'occhiata a questo elenco di quaderni collaborativi di data science.