
Pandas DataFrame Nasıl Oluşturulur [Örneklerle]
Yayınlanan: 2022-12-08Pandas DataFrames ile çalışmanın temellerini öğrenin: güçlü bir veri işleme kitaplığı olan pandas'taki temel veri yapısı.
Python'da veri analizine başlamak istiyorsanız, pandas, birlikte çalışmayı öğrenmeniz gereken ilk kitaplıklardan biridir. CSV dosyaları ve veritabanları gibi birden çok kaynaktan veri içe aktarmaktan eksik verileri işlemeye ve içgörü elde etmek için analiz etmeye kadar pandalar, yukarıdakilerin hepsini yapmanızı sağlar.
Verileri pandalarla analiz etmeye başlamak için pandalardaki temel veri yapısını anlamalısınız: veri çerçeveleri .
Bu öğreticide, panda veri çerçevelerinin temellerini ve veri çerçeveleri oluşturmak için yaygın yöntemleri öğreneceksiniz. Ardından, veri alt kümelerini almak için veri çerçevesinden satırları ve sütunları nasıl seçeceğinizi öğreneceksiniz.
Hepsi ve daha fazlası için haydi başlayalım.
Pandaları Yükleme ve İçe Aktarma
pandas üçüncü taraf bir veri analizi kitaplığı olduğundan, önce onu yüklemeniz gerekir. Projeniz için harici paketleri sanal ortamda kurmanız önerilir.
Python'un Anaconda dağıtımını kullanıyorsanız, paket yönetimi için conda kullanabilirsiniz.
conda install pandasPandaları pip kullanarak da kurabilirsiniz:
pip install pandasPandalar kitaplığı, bir bağımlılık olarak NumPy'yi gerektirir. Dolayısıyla, NumPy kurulu değilse, kurulum işlemi sırasında da kurulacaktır.
Pandaları yükledikten sonra çalışma ortamınıza aktarabilirsiniz. Genel olarak, pandalar pd takma adı altında içe aktarılır:
import pandas as pdPandalarda DataFrame Nedir?

Pandalardaki temel veri yapısı veri çerçevesidir . Veri çerçevesi, etiketli dizin ve adlandırılmış sütunlara sahip iki boyutlu bir veri dizisidir. Pandalar serisi adı verilen veri çerçevesindeki her sütun, ortak bir dizini paylaşır.
İşte önümüzdeki birkaç dakika içinde sıfırdan oluşturacağımız örnek bir veri çerçevesi. Bu veri çerçevesi, altı öğrencinin dört haftada ne kadar harcadığına ilişkin verileri içerir.

Öğrencilerin isimleri satır etiketleridir. Ve sütunlar 'Hafta1' ila 'Hafta4' olarak adlandırılır. Tüm sütunların, dizin olarak da adlandırılan aynı satır etiketleri kümesini paylaştığına dikkat edin.
Pandas DataFrame Nasıl Oluşturulur
Pandalar veri çerçevesi oluşturmanın birkaç yolu vardır. Bu eğitimde, aşağıdaki yöntemleri tartışacağız:
- NumPy dizilerinden veri çerçevesi oluşturma
- Python sözlüğünden veri çerçevesi oluşturma
- CSV dosyalarını okuyarak veri çerçevesi oluşturma
NumPy Dizilerinden
NumPy dizisinden bir veri çerçevesi oluşturalım.
Herhangi bir haftada her öğrencinin 0 ile 100 $ arasında bir harcama yaptığını varsayarak (6,4) şeklindeki veri dizisini oluşturalım. NumPy'nin random modülünden gelen randint() işlevi, belirli bir aralıkta [low,high) bir rasgele tamsayılar dizisi döndürür.
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Bir panda veri çerçevesi oluşturmak için, DataFrame yapıcısını kullanabilir ve gösterildiği gibi NumPy dizisini data bağımsız değişkeni olarak iletebilirsiniz:
students_df = pd.DataFrame(data=data) Şimdi, students_df türünü kontrol etmek için yerleşik type() işlevini çağırabiliriz. DataFrame nesnesi olduğunu görüyoruz.
type(students_df) # pandas.core.frame.DataFrame print(students_df) 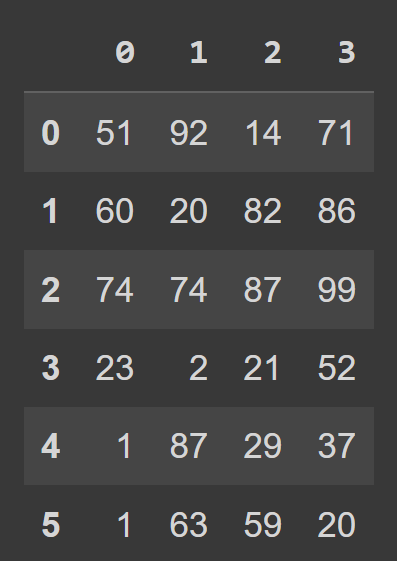
Varsayılan olarak, numRows - 1'e giden aralık indekslememiz olduğunu ve sütun etiketlerinin 0, 1, 2, …, numCols -1 olduğunu görüyoruz. Ancak bu okunabilirliği azaltır. Veri çerçevesine tanımlayıcı sütun adları ve satır etiketleri eklemek yardımcı olacaktır.
İki liste oluşturalım: biri öğrencilerin adlarını saklamak için, diğeri ise sütun etiketlerini saklamak için.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] DataFrame yapıcısını çağırırken, index ve columns sırasıyla kullanılacak satır etiketleri ve sütun etiketleri listelerine ayarlayabilirsiniz.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Artık, açıklayıcı satır ve sütun etiketleriyle birlikte students_df veri çerçevesine sahibiz.
print(students_df) 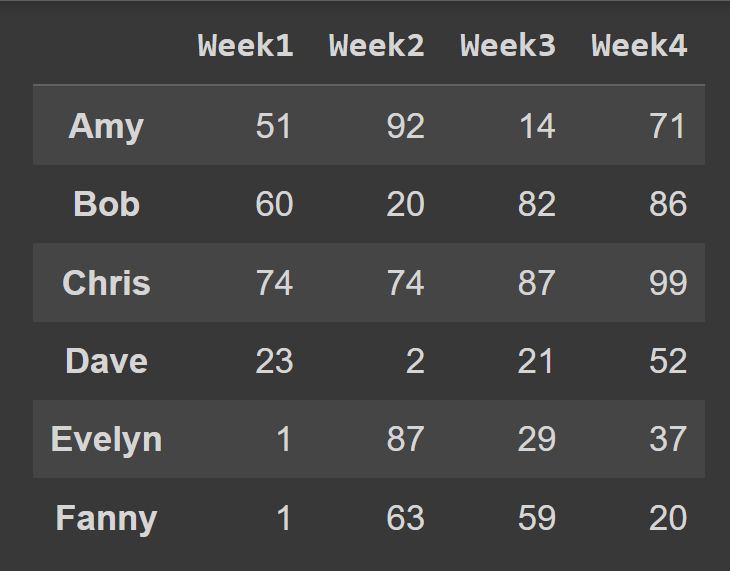
Veri çerçevesi hakkında eksik değerler ve veri türleri gibi bazı temel bilgileri almak için veri çerçevesi nesnesinde info() yöntemini çağırabilirsiniz.
students_df.info() 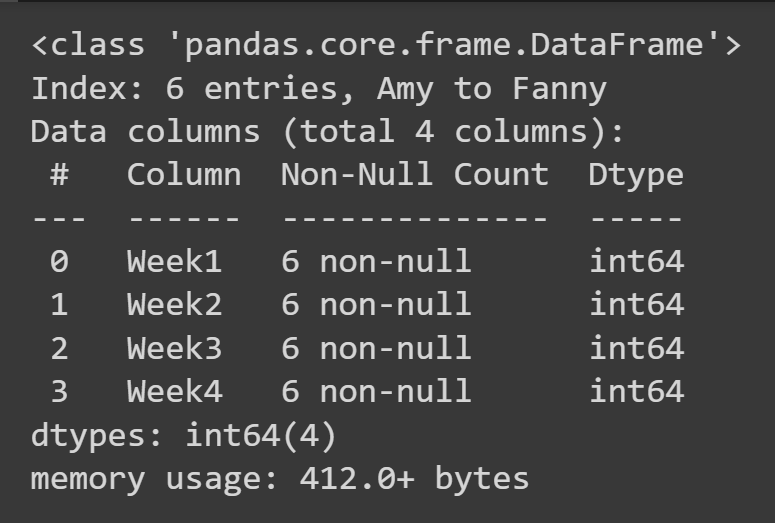
Bir Python Sözlüğünden
Python sözlüğünden bir panda veri çerçevesi de oluşturabilirsiniz.
Burada data_dict , öğrenci verilerini içeren sözlüktür:
- Öğrencilerin isimleri anahtardır.
- Her değer, her öğrencinin birinci ila dördüncü haftalar arasında ne kadar harcadığının bir listesidir.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Bir Python sözlüğünden bir veri çerçevesi oluşturmak için aşağıda gösterildiği gibi from_dict kullanın. İlk bağımsız değişken, verileri ( data_dict ) içeren sözlüğe karşılık gelir. Varsayılan olarak, veri çerçevesinin sütun adları olarak anahtarlar kullanılır. Tuşları satır etiketleri olarak ayarlamak istediğimiz için orient= 'index' ayarlayın.
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 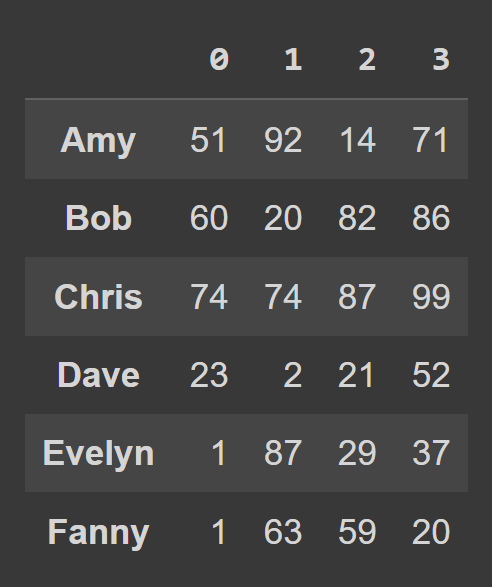
Sütun adlarını hafta sayısına değiştirmek için, sütunları cols listesine ayarladık:

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 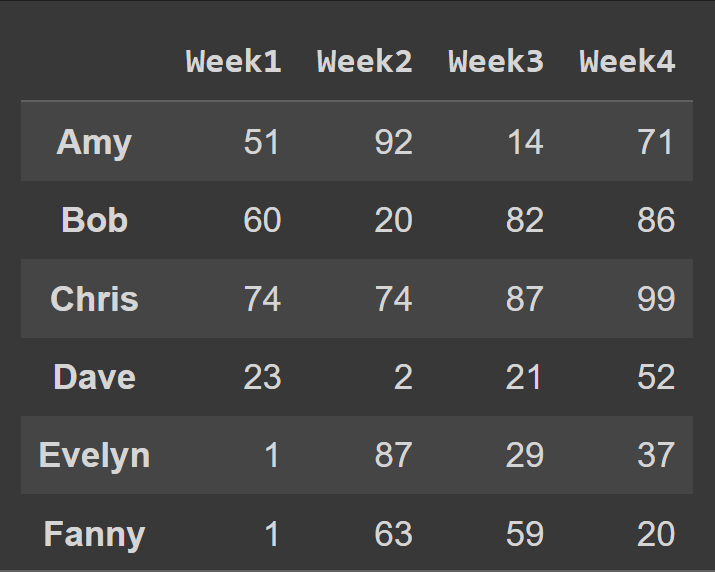
CSV Dosyasında Pandas DataFrame'e Okuma
Öğrenci verilerinin bir CSV dosyası olduğunu varsayalım. Dosyadaki verileri bir pandas veri çerçevesine okumak için read_csv() işlevini kullanabilirsiniz. pd.read_csv('file-path') genel sözdizimidir, burada file-path CSV dosyasının yoludur. Kullanılacak sütun adları listesine names parametresini ayarlayabiliriz.
students_df = pd.read_csv('/content/students.csv',names=cols)Artık bir veri çerçevesi oluşturmayı öğrendiğimize göre, satırları ve sütunları nasıl seçeceğimizi öğrenelim.
Pandas DataFrame'den Sütunları Seçin
Bir veri çerçevesinden satırları ve sütunları seçmek için kullanabileceğiniz birkaç yerleşik yöntem vardır. Bu öğretici, bir veri çerçevesinden sütunları, satırları ve hem satırları hem de sütunları seçmenin en yaygın yollarını ele alacaktır.
Tek Sütun Seçme
Tek bir sütun seçmek için df_name[col_name] kullanabilirsiniz; burada col_name , sütunun adını gösteren dizedir.
Burada sadece 'Hafta1' sütununu seçiyoruz.
week1_df = students_df['Week1'] print(week1_df) 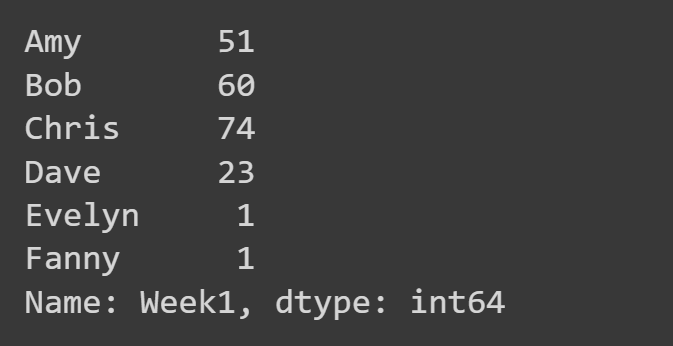
Birden Çok Sütun Seçme
Veri çerçevesinden birden çok sütun seçmek için, seçilecek tüm sütun adlarının listesini iletin.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 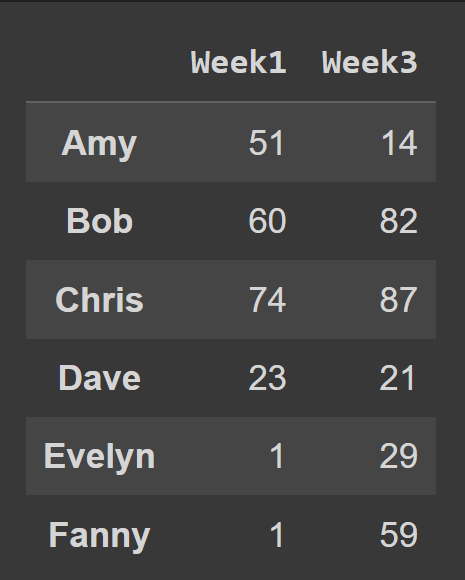
Sütun seçmek için bu yönteme ek olarak iloc() ve loc() yöntemlerini de kullanabilirsiniz. Daha sonra bir örnek kodlayacağız.
Pandas DataFrame'den Satırları Seçin

.iloc() Yöntemini Kullanma
iloc() yöntemini kullanarak satır seçmek için, tüm satırlara karşılık gelen indeksleri bir liste olarak iletin.
Bu örnekte, tek indeksteki satırları seçiyoruz.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 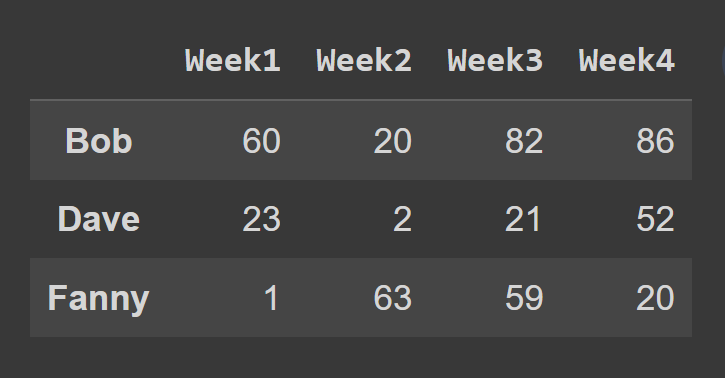
Ardından, veri çerçevesinin 0 ila 2 indeksindeki satırları içeren bir alt kümesini seçiyoruz, bitiş noktası 3 varsayılan olarak hariç tutuluyor.
slice1 = students_df.iloc[0:3] print(slice1) 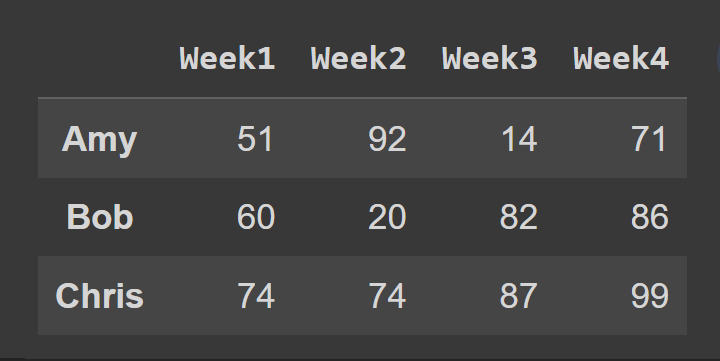
.loc() Yöntemini Kullanma
loc() yöntemini kullanarak bir veri çerçevesinin satırlarını seçmek için, seçmek istediğiniz satırlara karşılık gelen etiketleri belirtmelisiniz.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 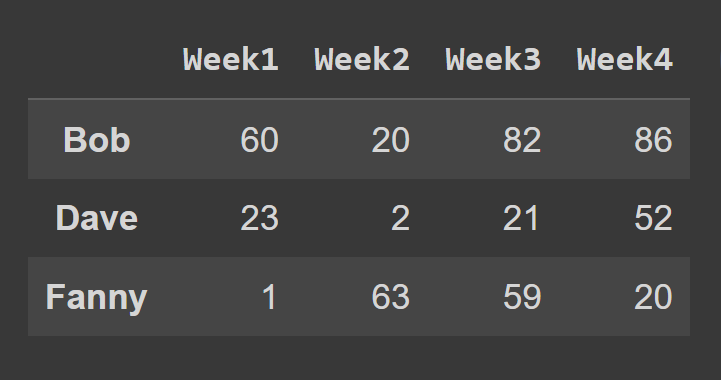
Veri çerçevesinin satırları, 0, 1, 2,
numRows-1'e kadar varsayılan aralık kullanılarak dizine ekleniyorsa,iloc()veloc()kullanmak eşdeğerdir.
Pandas DataFrame'den Satırları ve Sütunları Seçin
Şimdiye kadar, bir pandas veri çerçevesinden satırları veya sütunları nasıl seçeceğinizi öğrendiniz. Ancak, bazen hem satırların hem de sütunların bir alt kümesini seçmeniz gerekebilir. Peki bunu nasıl yapıyorsun? iloc() ve loc() yöntemlerini kullanabilirsiniz.
Örneğin aşağıdaki kod parçasında 2. ve 3. indeksteki tüm satır ve sütunları seçiyoruz.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 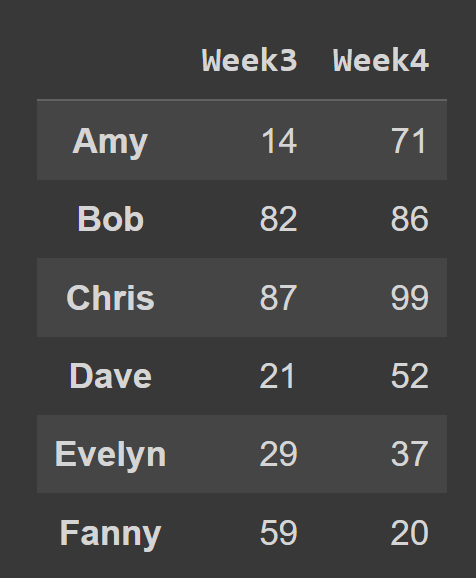
start:stop kullanmak, start up'tan stop içermeyen bir dilim oluşturur. Böylece, hem start hem de stop değerlerini yok saydığınızda, dilim baştan başlar ve tüm satırları seçerek veri çerçevesinin sonuna kadar uzanır.
loc() yöntemini kullanırken, gösterildiği gibi, seçmek istediğiniz satırların ve sütunların etiketlerini girmeniz gerekir:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 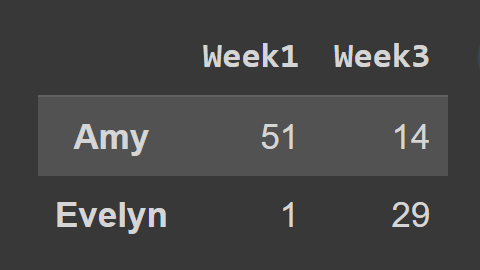
Burada subset_df2 Amy ve Evelyn'in 1. Hafta ve 3. Hafta kaydını içerir.
Çözüm
İşte bu eğitimde öğrendiklerinizin hızlı bir gözden geçirmesi:
- Pandaları yükledikten sonra, onu
pdtakma adı altında içe aktarabilirsiniz. Bir pandas veri çerçevesi nesnesi oluşturmak için,pd.DataFrame(data)yapıcısını kullanabilirsiniz; buradadata, N-boyutlu diziye veya verileri içeren yinelenebilir bir diziye başvurur. Sırasıyla isteğe bağlı dizin ve sütun parametrelerini ayarlayarak satır ve dizin ve sütun etiketlerini belirleyebilirsiniz. -
pd.read_csv(path-to-the-file)kullanılması, dosyanın içeriğini bir veri çerçevesine okur. - Sütunlar, eksik değerlerin sayısı, veri türleri ve veri çerçevesinin boyutu hakkında bilgi almak için veri çerçevesi nesnesinde
info()yöntemini çağırabilirsiniz. - Tek bir sütun seçmek için
df_name[col_name]öğesini ve birden çok sütun seçmek için, belirli sütunudf_name[[col1,col2,...,coln]]. -
loc()veiloc()yöntemlerini kullanarak da sütunları ve satırları seçebilirsiniz. -
iloc()yöntemi seçilecek satırların ve sütunların dizinini (veya dizin dilimini) alırken,loc()yöntemi satır ve sütun etiketlerini alır.
Bu eğitimde kullanılan örnekleri bu Colab not defterinde bulabilirsiniz.
Ardından, iş birliğine dayalı veri bilimi not defterlerinin bu listesine göz atın.