
كيفية إنشاء Pandas DataFrame [مع أمثلة]
نشرت: 2022-12-08تعلم أساسيات العمل مع pandas DataFrames: بنية البيانات الأساسية في الباندا ، مكتبة معالجة البيانات القوية.
إذا كنت ترغب في البدء في تحليل البيانات في Python ، فإن الباندا هي واحدة من المكتبات الأولى التي يجب أن تتعلم العمل معها. من استيراد البيانات من مصادر متعددة مثل ملفات CSV وقواعد البيانات إلى التعامل مع البيانات المفقودة وتحليلها لاكتساب الأفكار - يتيح لك الباندا القيام بكل ما سبق.
لبدء تحليل البيانات باستخدام الباندا ، يجب أن تفهم بنية البيانات الأساسية في حيوانات الباندا: إطارات البيانات .
في هذا البرنامج التعليمي ، ستتعلم أساسيات إطارات بيانات الباندا والطرق الشائعة لإنشاء إطارات بيانات. ستتعلم بعد ذلك كيفية تحديد الصفوف والأعمدة من إطار البيانات لاسترداد مجموعات فرعية من البيانات.
لكل هذا وأكثر ، لنبدأ.
تركيب واستيراد الباندا
نظرًا لأن الباندا هي مكتبة تحليل بيانات تابعة لجهة خارجية ، فيجب عليك أولاً تثبيتها. يوصى بتثبيت حزم خارجية في بيئة افتراضية لمشروعك.
إذا كنت تستخدم توزيع Anaconda في Python ، فيمكنك استخدام conda لإدارة الحزم.
conda install pandasيمكنك أيضًا تثبيت الباندا باستخدام النقطة:
pip install pandasتتطلب مكتبة الباندا NumPy كاعتماد. لذلك إذا لم يكن NumPy مثبتًا بالفعل ، فسيتم تثبيته أيضًا أثناء عملية التثبيت.
بعد تثبيت الباندا ، يمكنك استيرادها إلى بيئة العمل الخاصة بك. بشكل عام ، يتم استيراد الباندا تحت الاسم المستعار pd :
import pandas as pdما هو DataFrame في الباندا؟

هيكل البيانات الأساسي في الباندا هو إطار البيانات . إطار البيانات عبارة عن مصفوفة ثنائية الأبعاد من البيانات ذات فهرس معنون وأعمدة مسماة . كل عمود في إطار البيانات يسمى سلسلة الباندا ، يشترك في فهرس مشترك.
فيما يلي مثال لإطار البيانات الذي سننشئه من البداية خلال الدقائق القليلة القادمة. يحتوي إطار البيانات هذا على بيانات حول المبلغ الذي يقضيه ستة طلاب في أربعة أسابيع.

أسماء الطلاب هي تسميات الصفوف. وتسمى الأعمدة "Week1" إلى "Week4". لاحظ أن جميع الأعمدة تشترك في نفس مجموعة تسميات الصفوف ، والتي تسمى أيضًا الفهرس .
كيفية إنشاء Pandas DataFrame
هناك عدة طرق لإنشاء إطار بيانات الباندا. في هذا البرنامج التعليمي ، سنناقش الطرق التالية:
- إنشاء إطار بيانات من مصفوفات NumPy
- إنشاء إطار بيانات من قاموس Python
- إنشاء إطار بيانات من خلال القراءة في ملفات CSV
من NumPy Arrays
دعونا ننشئ إطار بيانات من مصفوفة NumPy.
لنقم بإنشاء مصفوفة بيانات للشكل (6،4) بافتراض أنه في أي أسبوع معين ، ينفق كل طالب ما بين 0 دولار و 100 دولار. ترجع الدالة randint() من الوحدة النمطية random في NumPy مصفوفة من الأعداد الصحيحة العشوائية في فترة زمنية معينة ، [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) لإنشاء إطار بيانات الباندا ، يمكنك استخدام مُنشئ DataFrame وتمرير مصفوفة NumPy كوسيطة data ، كما هو موضح:
students_df = pd.DataFrame(data=data) يمكننا الآن استدعاء وظيفة type() للتحقق من نوع students_df . نرى أنه كائن DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 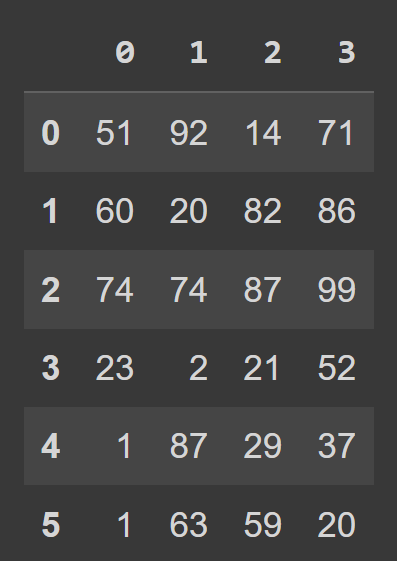
نرى أنه افتراضيًا ، لدينا فهرسة نطاق تمتد من 0 إلى numRows - 1 ، وتسميات الأعمدة هي 0 ، 1 ، 2 ، ... ، numCols -1. ومع ذلك ، هذا يقلل من إمكانية القراءة. سيساعد على إضافة أسماء الأعمدة الوصفية وتسميات الصفوف إلى إطار البيانات.
لنقم بإنشاء قائمتين: واحدة لتخزين أسماء الطلاب والأخرى لتخزين تسميات الأعمدة.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] عند استدعاء مُنشئ DataFrame ، يمكنك تعيين index columns على قوائم تسميات الصفوف وتسميات الأعمدة المراد استخدامها ، على التوالي.
students_df = pd.DataFrame(data = data,index = students,columns = cols) لدينا الآن إطار بيانات students_df مع تسميات وصفية وصفية للأعمدة.
print(students_df) 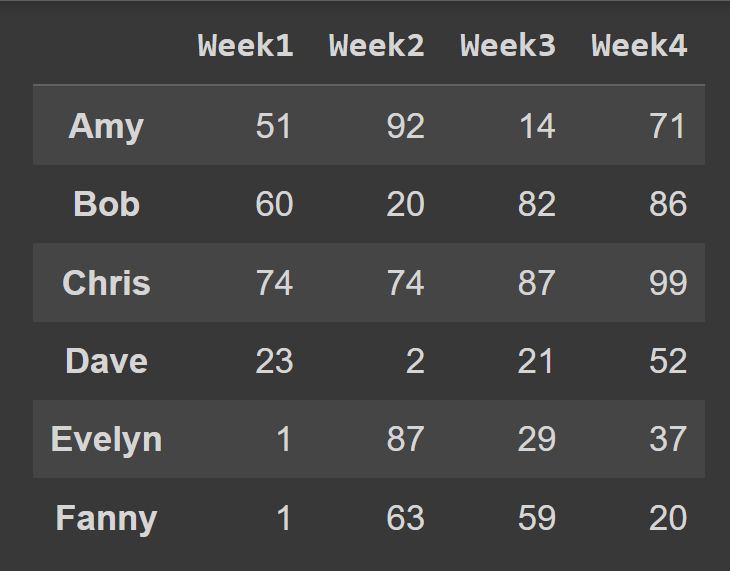
للحصول على بعض المعلومات الأساسية حول إطار البيانات ، مثل القيم المفقودة وأنواع البيانات ، يمكنك استدعاء طريقة info() في كائن إطار البيانات.
students_df.info() 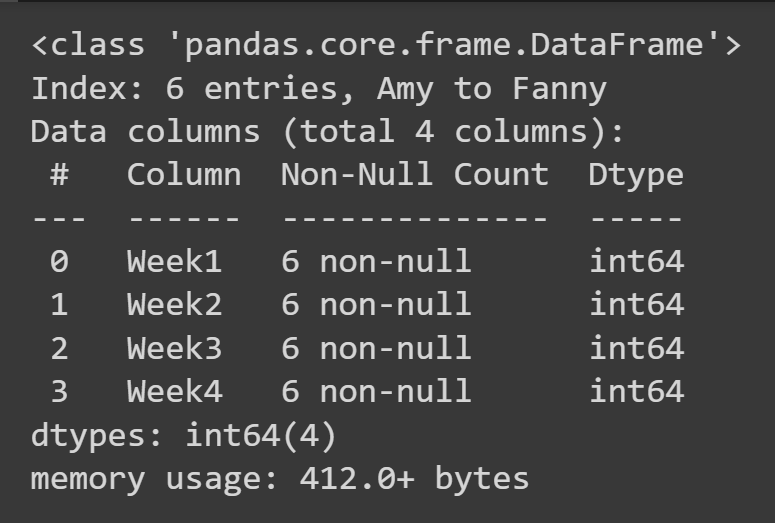
من قاموس بايثون
يمكنك أيضًا إنشاء إطار بيانات الباندا من قاموس Python.
هنا ، data_dict هو القاموس الذي يحتوي على بيانات الطالب:
- أسماء الطلاب هي المفاتيح.
- كل قيمة عبارة عن قائمة بالمبلغ الذي ينفقه كل طالب من الأسابيع الأول إلى الرابع.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data لإنشاء إطار بيانات من قاموس Python ، استخدم from_dict ، كما هو موضح أدناه. الوسيطة الأولى تتوافق مع القاموس الذي يحتوي على البيانات ( data_dict ). بشكل افتراضي ، يتم استخدام المفاتيح كأسماء أعمدة لإطار البيانات. نظرًا لأننا نرغب في تعيين المفاتيح كتسميات الصفوف ، فقم بتعيين orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 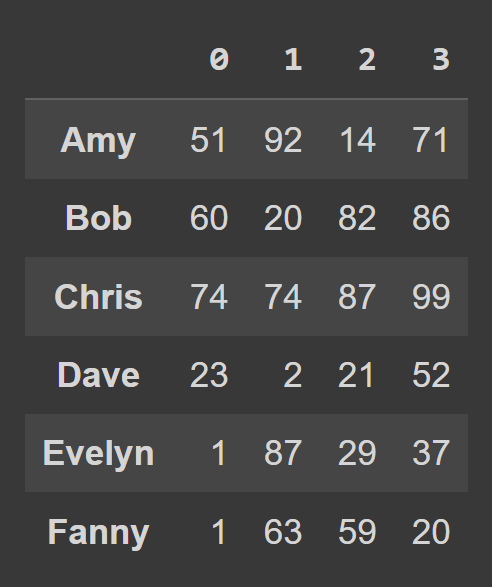
لتغيير أسماء الأعمدة إلى رقم الأسبوع ، قمنا بتعيين الأعمدة على قائمة cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 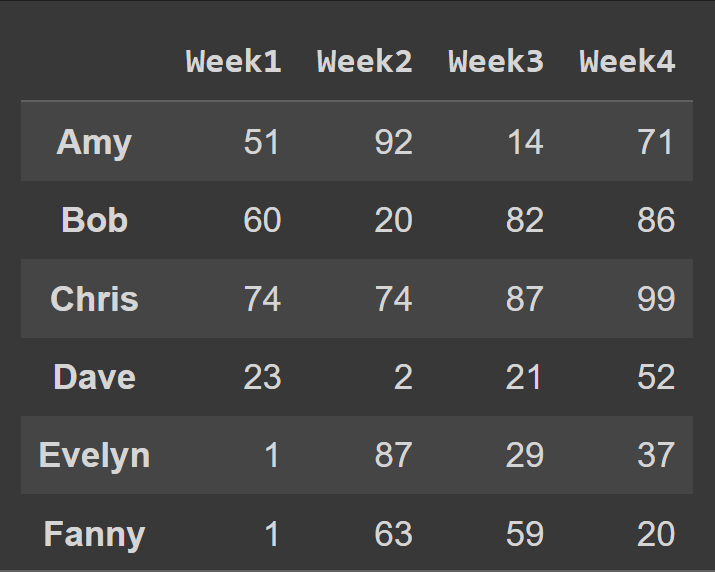
اقرأ في ملف CSV في إطار بيانات Pandas
افترض أن بيانات الطالب متوفرة في ملف CSV. يمكنك استخدام وظيفة read_csv() لقراءة البيانات من الملف في إطار بيانات الباندا. pd.read_csv('file-path') هو الصيغة العامة ، حيث يكون file-path هو المسار إلى ملف CSV. يمكننا ضبط معلمة names على قائمة أسماء الأعمدة المراد استخدامها.
students_df = pd.read_csv('/content/students.csv',names=cols)الآن بعد أن عرفنا كيفية إنشاء إطار بيانات ، دعنا نتعلم كيفية تحديد الصفوف والأعمدة.
حدد أعمدة من Pandas DataFrame
هناك العديد من الطرق المضمنة التي يمكنك استخدامها لتحديد الصفوف والأعمدة من إطار البيانات. سيتناول هذا البرنامج التعليمي الطرق الأكثر شيوعًا لتحديد الأعمدة والصفوف وكلا الصفوف والأعمدة من إطار البيانات.
اختيار عمود واحد
لتحديد عمود واحد ، يمكنك استخدام df_name[col_name] حيث col_name هي السلسلة التي تشير إلى اسم العمود.
هنا ، نختار فقط عمود "الأسبوع 1".
week1_df = students_df['Week1'] print(week1_df) 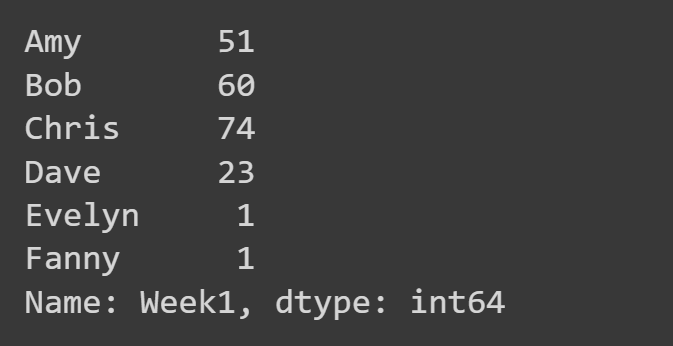
اختيار أعمدة متعددة
لتحديد عدة أعمدة من إطار البيانات ، قم بتمرير قائمة جميع أسماء الأعمدة المراد تحديدها.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 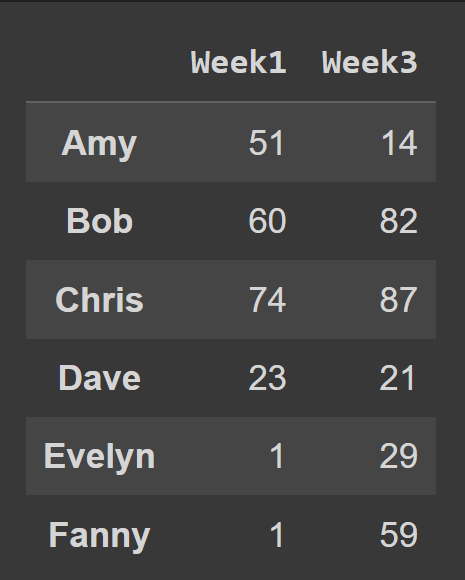
بالإضافة إلى هذه الطريقة ، يمكنك أيضًا استخدام iloc() و loc() لتحديد الأعمدة. سنقوم بتشفير مثال لاحقًا.
حدد صفوفًا من Pandas DataFrame

استخدام طريقة .iloc ()
لتحديد الصفوف باستخدام طريقة iloc() ، قم بتمرير المؤشرات المقابلة لجميع الصفوف كقائمة.
في هذا المثال ، نختار الصفوف في الفهرس الفردي.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 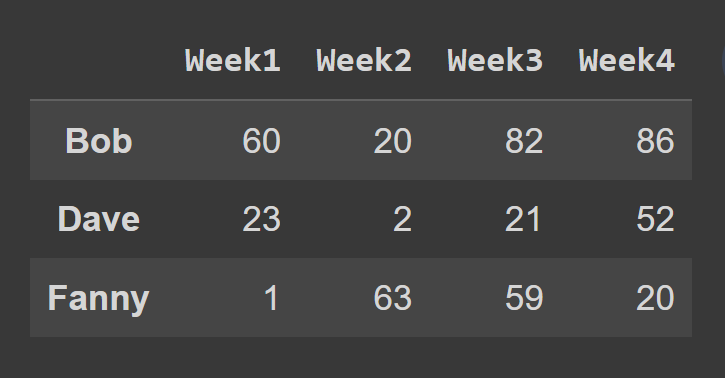
بعد ذلك ، نختار مجموعة فرعية من إطار البيانات تحتوي على الصفوف في الفهرس من 0 إلى 2 ، ويتم استبعاد نقطة النهاية 3 افتراضيًا.
slice1 = students_df.iloc[0:3] print(slice1) 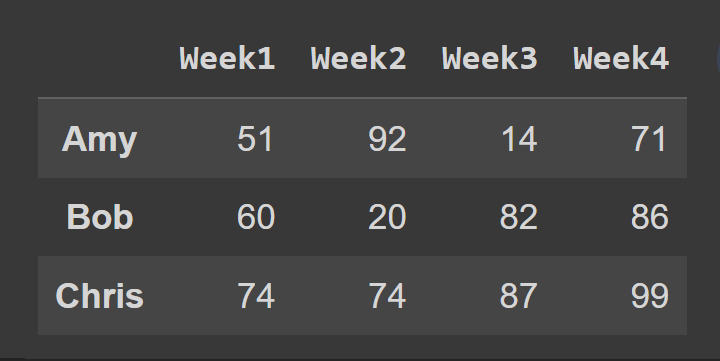
استخدام طريقة .loc ()
لتحديد صفوف إطار البيانات باستخدام طريقة loc() ، يجب عليك تحديد التسميات المقابلة للصفوف التي ترغب في تحديدها.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 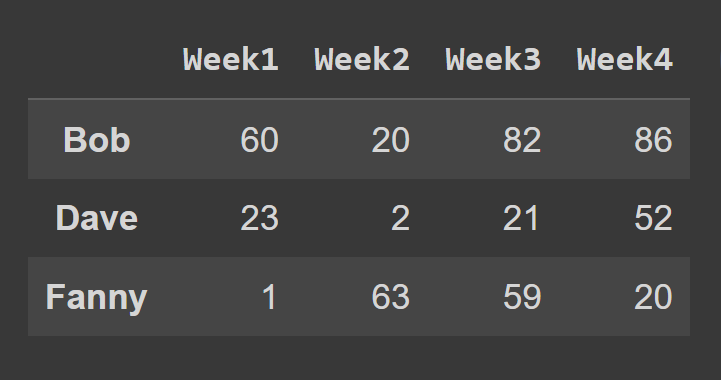
إذا تمت فهرسة صفوف إطار البيانات باستخدام النطاق الافتراضي 0 ، 1 ، 2 ، حتى
numRows-1 ، فإن استخدامiloc()وloc()كلاهما متكافئ.
حدد الصفوف والأعمدة من Pandas DataFrame
لقد تعلمت حتى الآن كيفية تحديد الصفوف أو الأعمدة من إطار بيانات الباندا. ومع ذلك ، قد تحتاج في بعض الأحيان إلى تحديد مجموعة فرعية من كل من الصفوف والأعمدة. فكيف يمكنك أن تفعل ذلك؟ يمكنك استخدام iloc() و loc() التي ناقشناها.
على سبيل المثال ، في مقتطف الشفرة أدناه ، نختار كل الصفوف والأعمدة في الفهرس 2 و 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 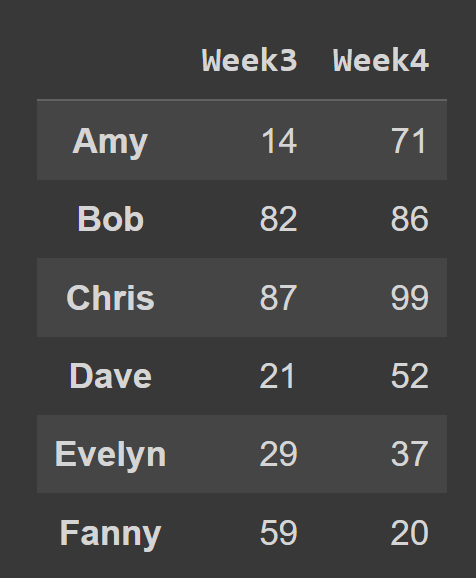
باستخدام start:stop شريحة من start إلى ولكن لا يشمل stop . لذلك عندما تتجاهل قيم start stop ، عندما تتجاهل قيم البداية والإيقاف ، تبدأ الشريحة في البداية - وتمتد حتى نهاية إطار البيانات - بتحديد كل الصفوف.
عند استخدام طريقة loc() ، يجب عليك تمرير تسميات الصفوف والأعمدة التي ترغب في تحديدها ، كما هو موضح:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 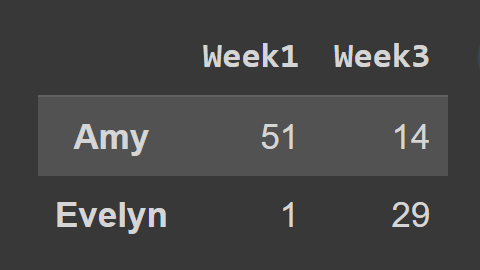
هنا ، يحتوي subset_df2 على سجل إيمي وإيفلين للأسبوعين الأول والثالث.
استنتاج
فيما يلي مراجعة سريعة لما تعلمته في هذا البرنامج التعليمي:
- بعد تثبيت الباندا ، يمكنك استيرادها تحت الاسم المستعار
pd. لإنشاء كائن إطار بيانات pandas ، يمكنك استخدامpd.DataFrame(data)، حيث تشيرdataإلى مصفوفة N-dimensional أو متكررة تحتوي على البيانات. يمكنك تحديد تسميات الصف والفهرس والأعمدة عن طريق تعيين معلمات الفهرس والأعمدة الاختيارية ، على التوالي. - يؤدي استخدام
pd.read_csv(path-to-the-file)إلى قراءة محتويات الملف في إطار بيانات. - يمكنك استدعاء طريقة
info()على كائن إطار البيانات للحصول على معلومات حول الأعمدة وعدد القيم المفقودة وأنواع البيانات وحجم إطار البيانات. - لتحديد عمود واحد ، استخدم
df_name[col_name]، ولتحديد أعمدة متعددة ، عمود معين ،df_name[[col1,col2,...,coln]]. - يمكنك أيضًا تحديد الأعمدة والصفوف باستخدام أساليب
loc()وiloc(). - بينما تأخذ طريقة
iloc()فهرس (أو شريحة فهرس) من الصفوف والأعمدة لتحديدها ، تأخذ طريقةloc()تسميات الصفوف والأعمدة.
يمكنك العثور على الأمثلة المستخدمة في هذا البرنامج التعليمي في دفتر ملاحظات Colab هذا.
بعد ذلك ، تحقق من هذه القائمة من دفاتر علوم البيانات التعاونية.