
Как создать Pandas DataFrame [с примерами]
Опубликовано: 2022-12-08Изучите основы работы с pandas DataFrames: базовая структура данных в pandas, мощная библиотека для работы с данными.
Если вы хотите начать анализ данных в Python, pandas — одна из первых библиотек, с которой вам следует научиться работать. От импорта данных из нескольких источников, таких как CSV-файлы и базы данных, до обработки отсутствующих данных и их анализа для получения информации — pandas позволяет вам делать все вышеперечисленное.
Чтобы начать анализировать данные с помощью pandas, вы должны понимать основную структуру данных в pandas: фреймы данных .
В этом руководстве вы изучите основы фреймов данных pandas и общие методы создания фреймов данных. Затем вы узнаете, как выбирать строки и столбцы из фрейма данных для извлечения подмножеств данных.
Для всего этого и многого другого, давайте начнем.
Установка и импорт панд
Поскольку pandas — это сторонняя библиотека анализа данных, вам следует сначала установить ее. Для вашего проекта рекомендуется устанавливать внешние пакеты в виртуальной среде.
Если вы используете дистрибутив Python Anaconda, вы можете использовать conda для управления пакетами.
conda install pandasВы также можете установить панд с помощью pip:
pip install pandasБиблиотека pandas требует NumPy в качестве зависимости. Поэтому, если NumPy еще не установлен, он также будет установлен в процессе установки.
После установки pandas вы можете импортировать его в свою рабочую среду. Обычно панды импортируются под псевдонимом pd :
import pandas as pdЧто такое DataFrame в Pandas?

Фундаментальной структурой данных в pandas является фрейм данных . Фрейм данных — это двумерный массив данных с помеченным индексом и именованными столбцами. Каждый столбец во фрейме данных, называемый серией pandas, имеет общий индекс.
Вот пример фрейма данных, который мы создадим с нуля в течение следующих нескольких минут. Этот фрейм данных содержит данные о том, сколько шесть студентов тратят за четыре недели.

Имена учеников являются метками строк. И столбцы называются от «Неделя1» до «Неделя4». Обратите внимание, что все столбцы используют один и тот же набор меток строк, также называемый индексом .
Как создать фрейм данных Pandas
Существует несколько способов создания фрейма данных pandas. В этом уроке мы обсудим следующие методы:
- Создание фрейма данных из массивов NumPy
- Создание фрейма данных из словаря Python
- Создание фрейма данных путем чтения файлов CSV
Из массивов NumPy
Давайте создадим фрейм данных из массива NumPy.
Давайте создадим массив данных формы (6,4), предполагая, что в любую неделю каждый студент тратит от 0 до 100 долларов. Функция randint() из random модуля NumPy возвращает массив случайных целых чисел в заданном интервале [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Чтобы создать фрейм данных pandas, вы можете использовать конструктор DataFrame и передать массив NumPy в качестве аргумента data , как показано ниже:
students_df = pd.DataFrame(data=data) Теперь мы можем вызвать встроенную функцию type() для проверки типа students_df . Мы видим, что это объект DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 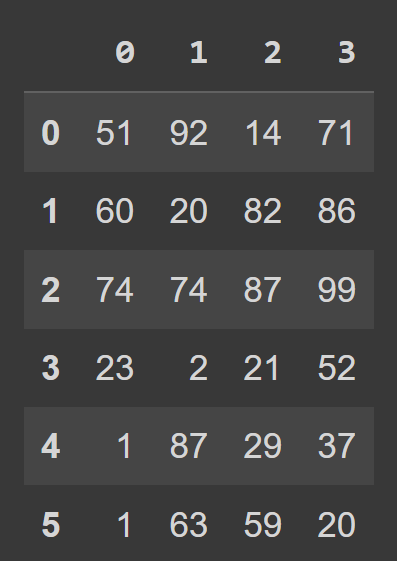
Мы видим, что по умолчанию у нас есть диапазон индексации, который идет от 0 до numRows — 1, а метки столбцов — 0, 1, 2, …, numCols -1. Однако это снижает читабельность. Это поможет добавить описательные имена столбцов и метки строк во фрейм данных.
Давайте создадим два списка: один для хранения имен учащихся, а другой для хранения меток столбцов.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] При вызове конструктора DataFrame вы можете установить index и columns для использования списков меток строк и меток столбцов соответственно.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Теперь у нас есть students_df данных student_df с описательными метками строк и столбцов.
print(students_df) 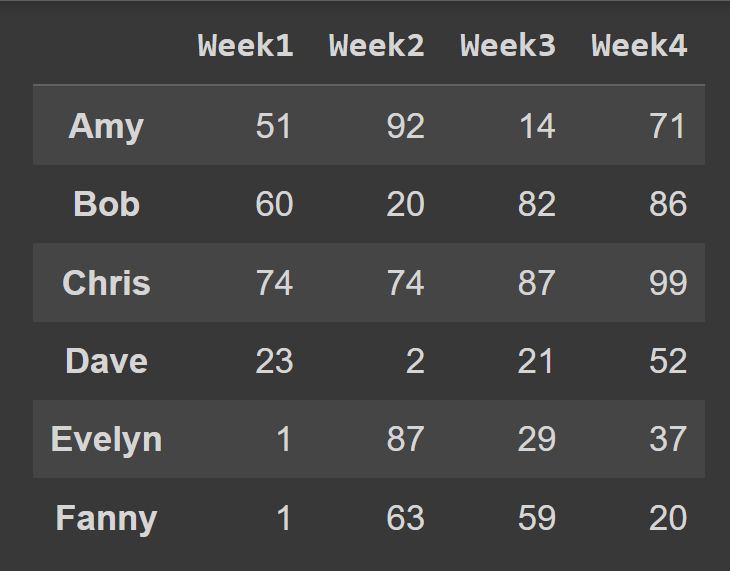
Чтобы получить базовую информацию о фрейме данных, такую как отсутствующие значения и типы данных, вы можете вызвать метод info() для объекта фрейма данных.
students_df.info() 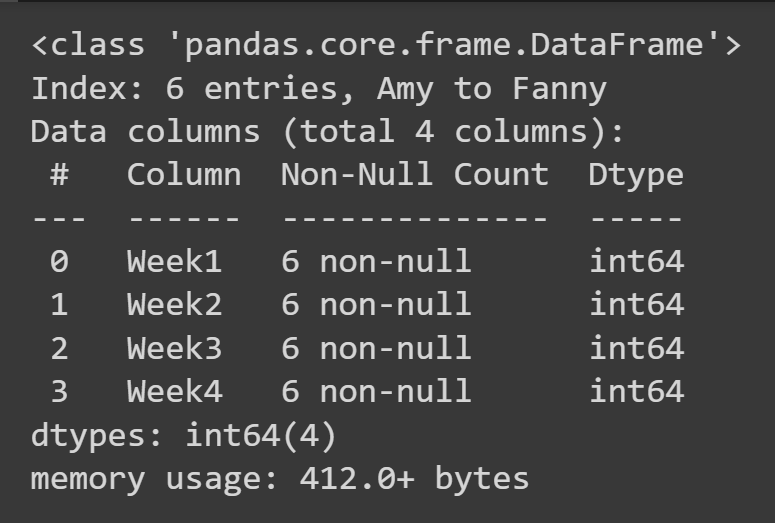
Из словаря Python
Вы также можете создать фрейм данных pandas из словаря Python.
Здесь data_dict — это словарь, содержащий данные о студентах:
- Имена студентов являются ключами.
- Каждое значение представляет собой список того, сколько каждый учащийся тратит с первой по четвертую неделю.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Чтобы создать фрейм данных из словаря Python, используйте from_dict , как показано ниже. Первый аргумент соответствует словарю, содержащему данные ( data_dict ). По умолчанию ключи используются в качестве имен столбцов фрейма данных. Поскольку мы хотим установить ключи в качестве меток строк , установите orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 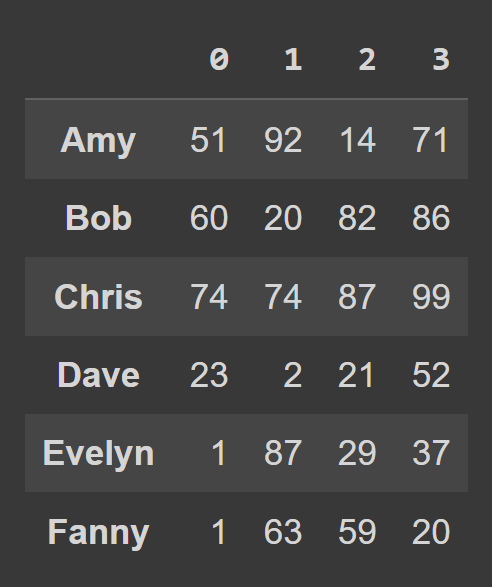
Чтобы изменить имена столбцов на номер недели, мы устанавливаем столбцы в список cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 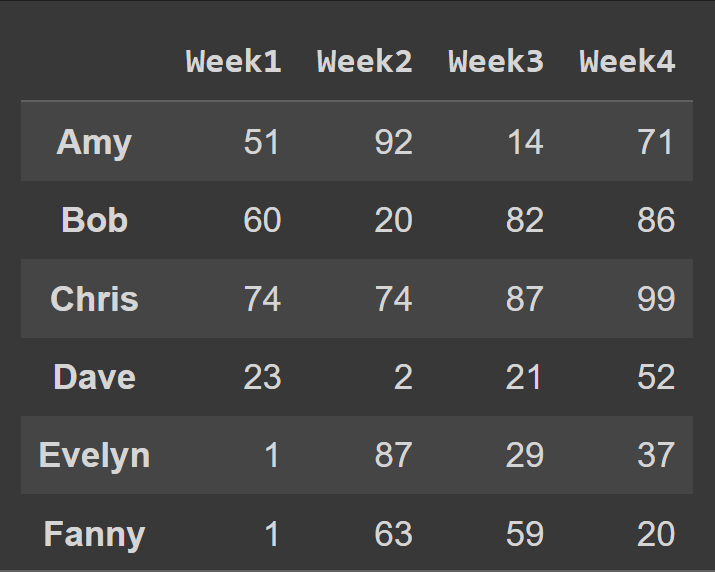
Чтение файла CSV в кадр данных Pandas
Предположим, что данные о студентах доступны в виде CSV-файла. Вы можете использовать read_csv() для чтения данных из файла во фрейм данных pandas. pd.read_csv('file-path') — это общий синтаксис, где file-path — это путь к CSV-файлу. Мы можем установить параметр name в список names столбцов для использования.
students_df = pd.read_csv('/content/students.csv',names=cols)Теперь, когда мы знаем, как создать фрейм данных, давайте научимся выбирать строки и столбцы.
Выберите столбцы из Pandas DataFrame
Существует несколько встроенных методов, которые можно использовать для выбора строк и столбцов из фрейма данных. В этом руководстве будут рассмотрены наиболее распространенные способы выбора столбцов, строк, а также строк и столбцов из фрейма данных.
Выбор одного столбца
Чтобы выбрать один столбец, вы можете использовать df_name[col_name] , где col_name — это строка, обозначающая имя столбца.
Здесь мы выбираем только столбец «Неделя1».
week1_df = students_df['Week1'] print(week1_df) 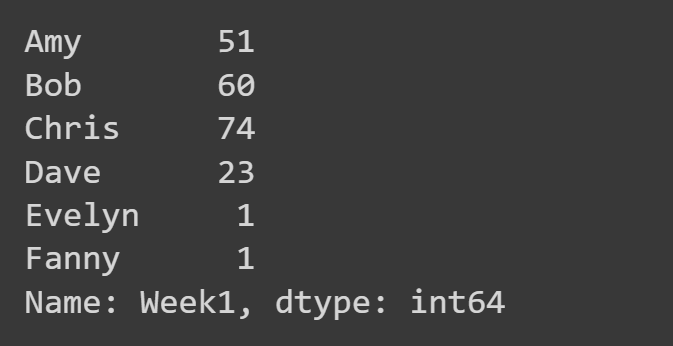
Выбор нескольких столбцов
Чтобы выбрать несколько столбцов из фрейма данных, передайте список всех имен столбцов для выбора.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 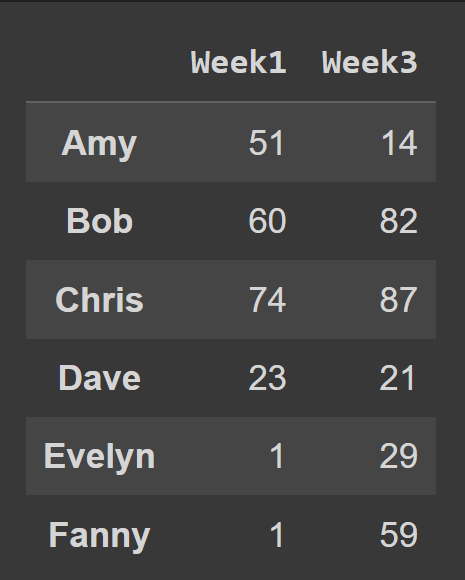
В дополнение к этому методу вы также можете использовать iloc() и loc() для выбора столбцов. Мы напишем пример позже.
Выберите строки из Pandas DataFrame

Использование метода .iloc()
Чтобы выбрать строки с помощью iloc() , передайте индексы, соответствующие всем строкам, в виде списка.
В этом примере мы выбираем строки с нечетным индексом.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 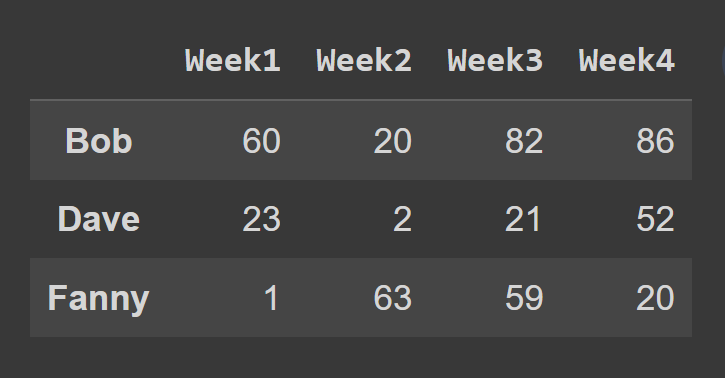
Затем мы выбираем подмножество фрейма данных, содержащее строки с индексами от 0 до 2, конечная точка 3 по умолчанию исключена.
slice1 = students_df.iloc[0:3] print(slice1) 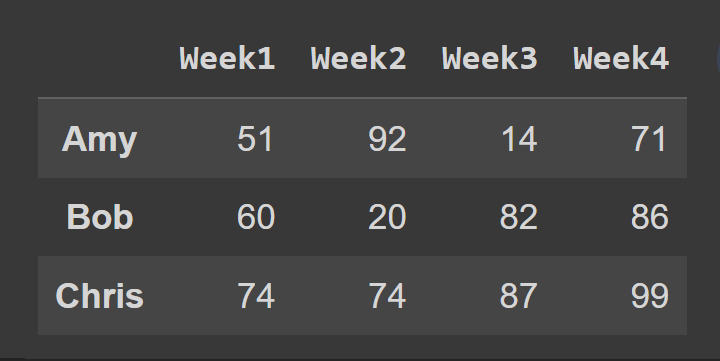
Использование метода .loc()
Чтобы выбрать строки фрейма данных с помощью метода loc() , вы должны указать метки, соответствующие строкам, которые вы хотите выбрать.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 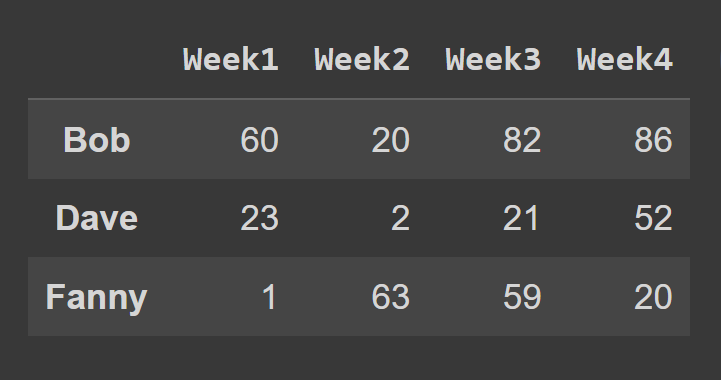
Если строки фрейма данных индексируются с использованием диапазона по умолчанию 0, 1, 2, вплоть до
numRows-1, то использованиеiloc()иloc()эквивалентно.
Выберите строки и столбцы из Pandas DataFrame
До сих пор вы узнали, как выбирать строки или столбцы из фрейма данных pandas. Однако иногда вам может понадобиться выбрать подмножество как строк, так и столбцов. Итак, как вы это делаете? Вы можете использовать рассмотренные iloc() и loc() .
Например, в приведенном ниже фрагменте кода мы выбираем все строки и столбцы с индексами 2 и 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 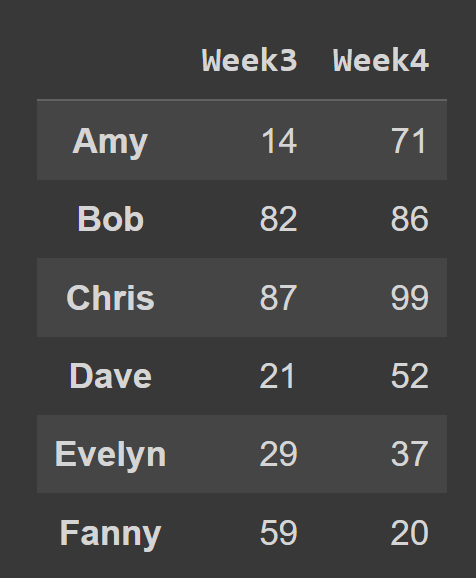
Использование start:stop создает срез от start до stop , но не включая ее. Поэтому, когда вы игнорируете как start , так и stop значения, когда вы игнорируете начальное и конечное значения, срез начинается с начала и продолжается до конца фрейма данных, выбирая все строки.
При использовании метода loc() вам необходимо передать метки строк и столбцов, которые вы хотите выбрать, как показано ниже:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 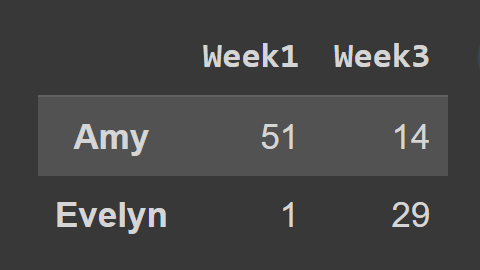
Здесь subset_df2 содержит записи Эми и Эвелин за неделю 1 и неделю 3.
Заключение
Вот краткий обзор того, что вы узнали в этом уроке:
- После установки pandas вы можете импортировать его под псевдонимом
pd. Чтобы создать объект фрейма данных pandas, вы можете использоватьpd.DataFrame(data), гдеdataотносятся к N-мерному массиву или итерации, содержащей данные. Вы можете указать строку и индекс, а также метки столбца, задав необязательные параметры индекса и столбца соответственно. - Использование
pd.read_csv(path-to-the-file)считывает содержимое файла во фрейм данных. - Вы можете вызвать метод
info()для объекта фрейма данных, чтобы получить информацию о столбцах, количестве пропущенных значений, типах данных и размере фрейма данных. - Чтобы выбрать один столбец, используйте
df_name[col_name], а чтобы выбрать несколько столбцов, конкретный столбец,df_name[[col1,col2,...,coln]]. - Вы также можете выбирать столбцы и строки, используя методы
loc()иiloc(). - В то время как метод
iloc()принимает индекс (или срез индекса) строк и столбцов для выбора, методloc()принимает метки строк и столбцов.
Вы можете найти примеры, используемые в этом руководстве, в этой записной книжке Colab.
Затем ознакомьтесь со списком блокнотов для совместной работы с данными.