
Cum se creează un cadru de date Pandas [cu exemple]
Publicat: 2022-12-08Aflați elementele de bază ale lucrului cu Pandas DataFrames: structura de bază a datelor în Pandas, o bibliotecă puternică de manipulare a datelor.
Dacă doriți să începeți cu analiza datelor în Python, panda este una dintre primele biblioteci cu care ar trebui să învățați să lucrați. De la importarea datelor din mai multe surse, cum ar fi fișierele CSV și bazele de date, până la gestionarea datelor lipsă și analizarea acestora pentru a obține informații – Pandas vă permite să faceți toate cele de mai sus.
Pentru a începe să analizați datele cu panda, ar trebui să înțelegeți structura fundamentală a datelor din panda: cadre de date .
În acest tutorial, veți învăța elementele de bază ale cadrelor de date panda și metodele obișnuite de a crea cadre de date. Veți învăța apoi cum să selectați rânduri și coloane din cadrul de date pentru a prelua subseturi de date.
Pentru toate acestea și multe altele, să începem.
Instalarea și importul Pandas
Întrucât Pandas este o bibliotecă de analiză a datelor terță parte, ar trebui mai întâi să o instalați. Este recomandat să instalați pachete externe într-un mediu virtual pentru proiectul dvs.
Dacă utilizați distribuția Anaconda din Python, puteți utiliza conda pentru gestionarea pachetelor.
conda install pandasDe asemenea, puteți instala panda folosind pip:
pip install pandasBiblioteca Pandas necesită NumPy ca dependență. Deci, dacă NumPy nu este deja instalat, va fi instalat și în timpul procesului de instalare.
După instalarea panda, îl puteți importa în mediul dvs. de lucru. În general, panda este importată sub pseudonimul pd :
import pandas as pdCe este un DataFrame în Pandas?

Structura fundamentală a datelor în panda este cadrul de date . Un cadru de date este o matrice bidimensională de date cu index etichetat și coloane denumite . Fiecare coloană din cadrul de date numită serie panda , are un index comun.
Iată un exemplu de cadru de date pe care îl vom crea de la zero în următoarele câteva minute. Acest cadru de date conține date despre cât cheltuiesc șase studenți în patru săptămâni.

Numele elevilor sunt etichetele rândurilor. Iar coloanele sunt denumite „Săptămâna1” până la „Săptămâna4”. Observați că toate coloanele au același set de etichete de rând, numit și index .
Cum se creează un Pandas DataFrame
Există mai multe moduri de a crea un cadru de date panda. În acest tutorial, vom discuta următoarele metode:
- Crearea unui cadru de date din matrice NumPy
- Crearea unui cadru de date dintr-un dicționar Python
- Crearea unui cadru de date prin citirea fișierelor CSV
Din NumPy Arrays
Să creăm un cadru de date dintr-o matrice NumPy.
Să creăm matricea de date cu forma (6,4) presupunând că, într-o săptămână dată, fiecare student cheltuiește între 0 USD și 100 USD. Funcția randint() din modulul random al lui NumPy returnează o matrice de numere întregi aleatoare într-un interval dat, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Pentru a crea un cadru de date Pandas, puteți utiliza constructorul DataFrame și puteți trece în matricea NumPy ca argument de data , după cum se arată:
students_df = pd.DataFrame(data=data) Acum putem apela funcția încorporată type() pentru a verifica tipul students_df . Vedem că este un obiect DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 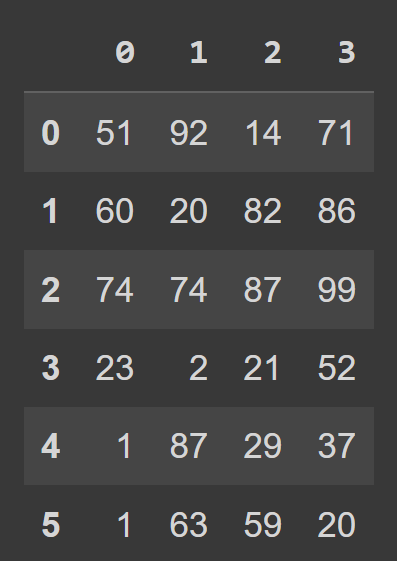
Vedem că în mod implicit, avem indexarea intervalului care merge de la 0 la numRows – 1, iar etichetele coloanei sunt 0, 1, 2, …, numCols -1. Cu toate acestea, acest lucru reduce lizibilitatea. Va ajuta să adăugați nume descriptive de coloane și etichete de rând în cadrul de date.
Să creăm două liste: una pentru a stoca numele elevilor și alta pentru a stoca etichetele coloanelor.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Când apelați constructorul DataFrame , puteți seta index și columns la listele de etichete de rând și, respectiv, etichete de coloană de utilizat.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Acum avem cadrul de date students_df cu etichete descriptive pentru rânduri și coloane.
print(students_df) 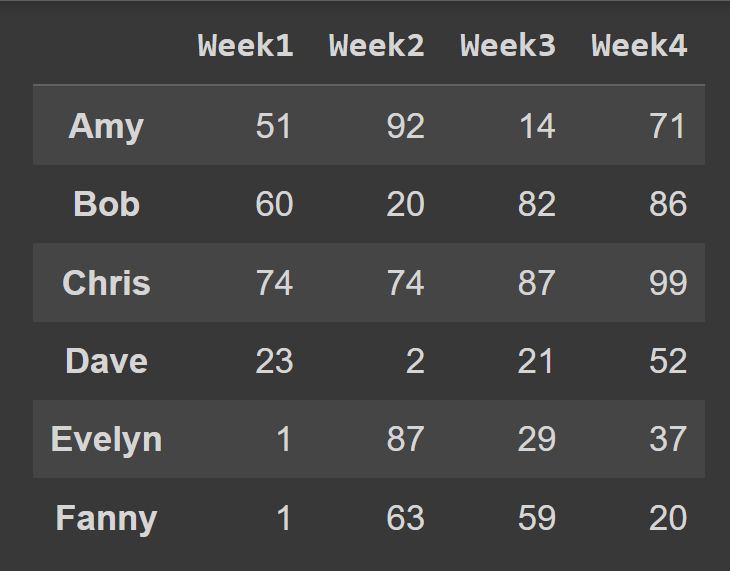
Pentru a obține câteva informații de bază despre cadrul de date, cum ar fi valorile lipsă și tipurile de date, puteți apela metoda info() pe obiectul cadru de date.
students_df.info() 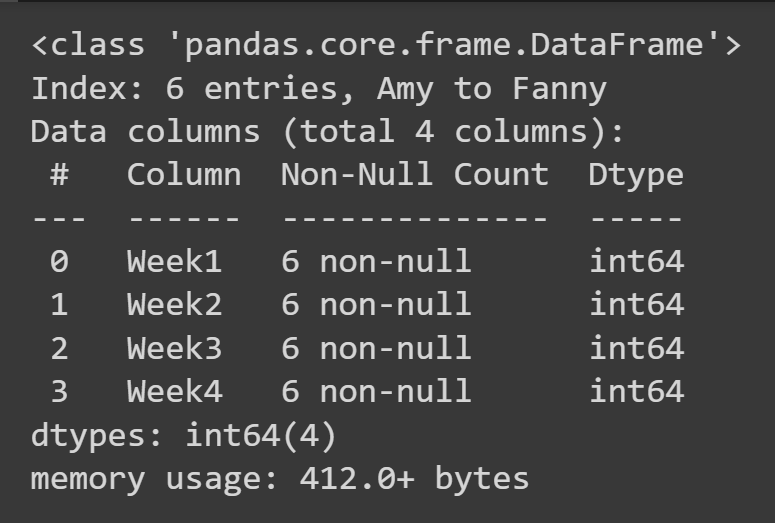
Dintr-un dicționar Python
De asemenea, puteți crea un cadru de date panda dintr-un dicționar Python.
Aici, data_dict este dicționarul care conține datele studenților:
- Numele elevilor sunt cheile.
- Fiecare valoare este o listă cu cât cheltuiește fiecare student din săptămânile unu până la patru.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Pentru a crea un cadru de date dintr-un dicționar Python, utilizați from_dict , așa cum se arată mai jos. Primul argument corespunde dicționarului care conține datele ( data_dict ). În mod implicit, cheile sunt folosite ca nume de coloane ale cadrului de date. Deoarece am dori să setăm cheile ca etichete de rând , setați orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 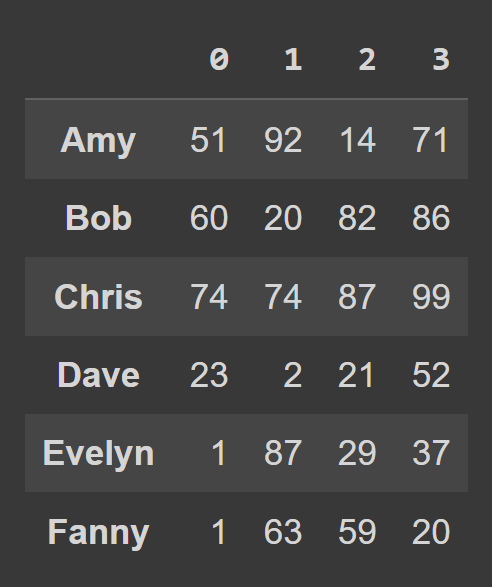
Pentru a schimba numele coloanelor în numărul săptămânii, cols coloanele în lista de coloane:

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 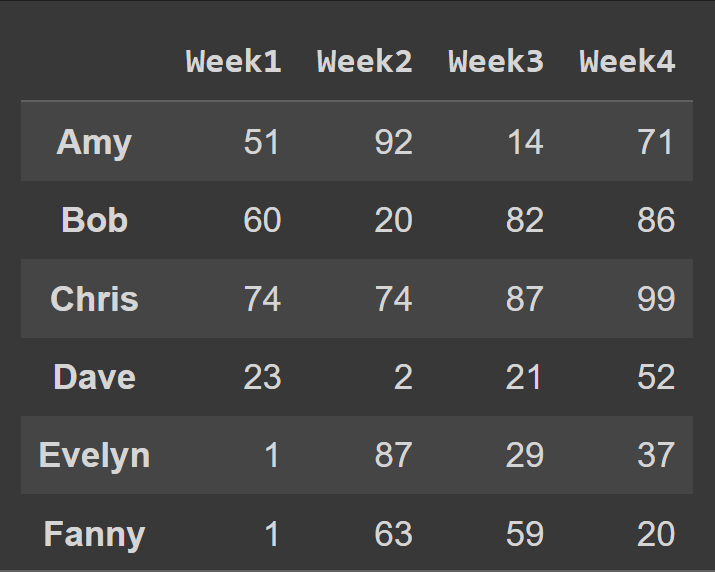
Citiți un fișier CSV într-un cadru de date Pandas
Să presupunem că datele elevului sunt disponibile într-un fișier CSV. Puteți utiliza funcția read_csv() pentru a citi datele din fișier într-un cadru de date Pandas. pd.read_csv('file-path') este sintaxa generală, unde file-path este calea către fișierul CSV. Putem seta parametrul names la lista de nume de coloane de utilizat.
students_df = pd.read_csv('/content/students.csv',names=cols)Acum că știm cum să creăm un cadru de date, să învățăm cum să selectăm rândurile și coloanele.
Selectați Coloane dintr-un cadru de date Pandas
Există mai multe metode încorporate pe care le puteți utiliza pentru a selecta rânduri și coloane dintr-un cadru de date. Acest tutorial va analiza cele mai comune moduri de a selecta coloane, rânduri și atât rânduri, cât și coloane dintr-un cadru de date.
Selectarea unei singure coloane
Pentru a selecta o singură coloană, puteți folosi df_name[col_name] unde col_name este șirul care indică numele coloanei.
Aici, selectăm doar coloana „Săptămâna1”.
week1_df = students_df['Week1'] print(week1_df) 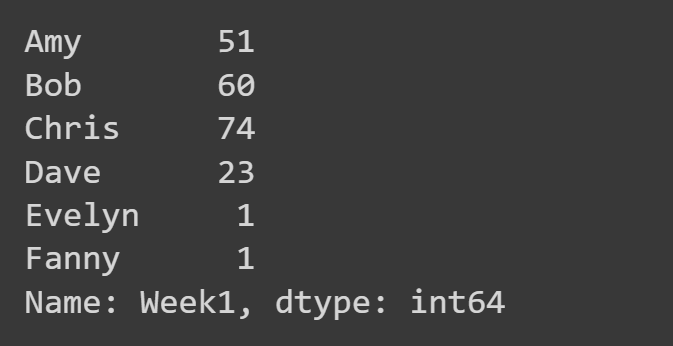
Selectarea coloanelor multiple
Pentru a selecta mai multe coloane din cadrul de date, treceți în lista tuturor numelor de coloane de selectat.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 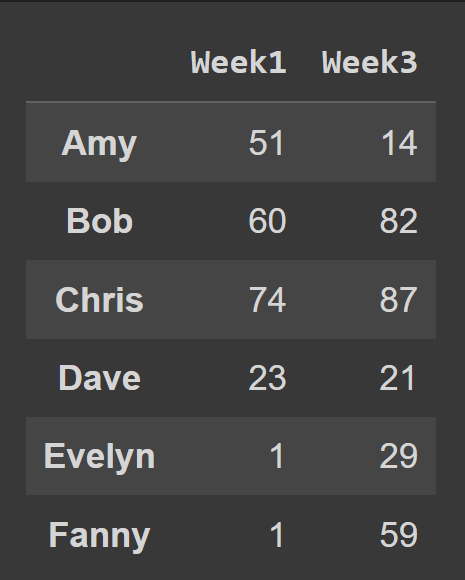
Pe lângă această metodă, puteți utiliza și iloc() și loc() pentru a selecta coloanele. Vom codifica un exemplu mai târziu.
Selectați Rânduri dintr-un cadru de date Pandas

Folosind metoda .iloc().
Pentru a selecta rânduri folosind metoda iloc() , introduceți indicii corespunzători tuturor rândurilor sub formă de listă.
În acest exemplu, selectăm rândurile la index impar.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 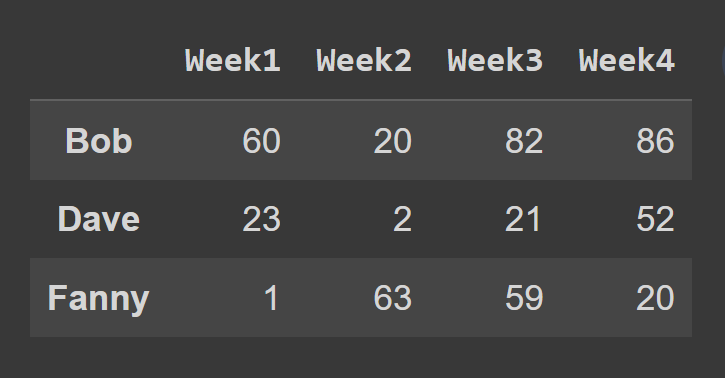
Apoi, selectăm un subset al cadrului de date care conține rândurile de la indexul 0 la 2, punctul final 3 este exclus implicit.
slice1 = students_df.iloc[0:3] print(slice1) 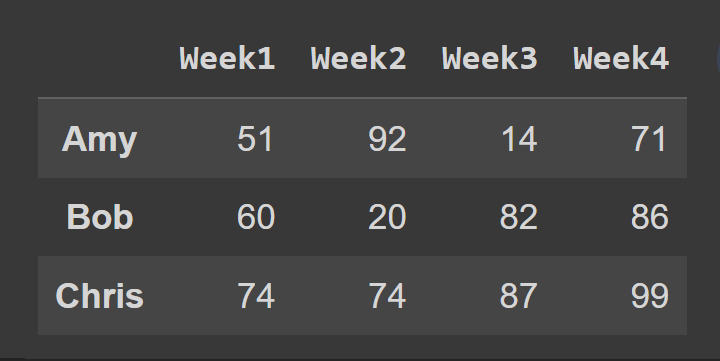
Folosind metoda .loc().
Pentru a selecta rândurile unui cadru de date folosind metoda loc() , trebuie să specificați etichetele corespunzătoare rândurilor pe care doriți să le selectați.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 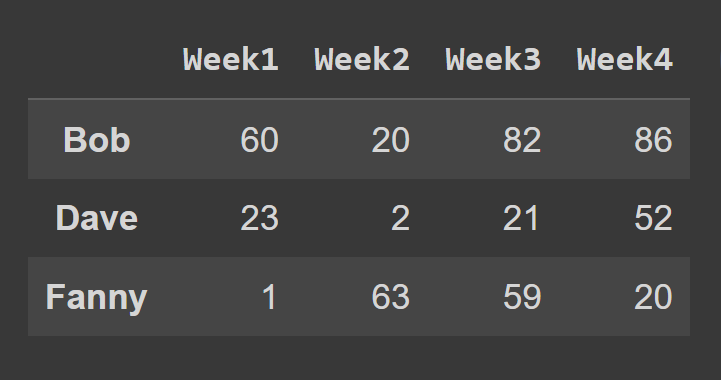
Dacă rândurile cadrului de date sunt indexate folosind intervalul implicit 0, 1, 2, până la
numRows-1, atunci folosindiloc()șiloc()sunt ambele echivalente.
Selectați Rânduri și coloane dintr-un cadru de date Pandas
Până acum, ați învățat cum să selectați fie rânduri, fie coloane dintr-un cadru de date panda. Cu toate acestea, uneori poate fi necesar să selectați un subset de rânduri și coloane. Deci cum o faci? Puteți folosi iloc() și loc() pe care le-am discutat.
De exemplu, în fragmentul de cod de mai jos, selectăm toate rândurile și coloanele de la indexul 2 și 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 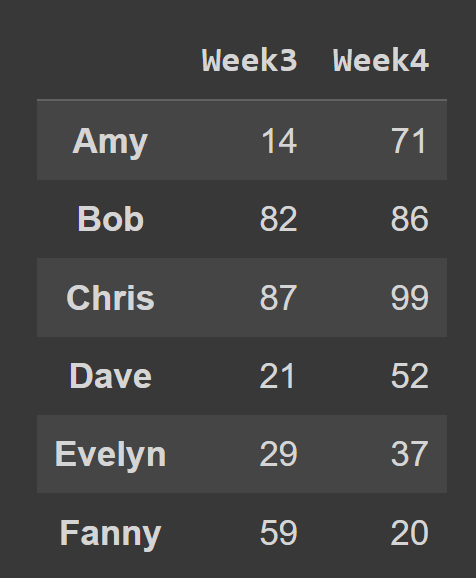
Folosind start:stop creează o porțiune de la start până la stop , dar fără a include. Deci, când ignorați atât valorile de start , cât și de stop , când ignorați valorile de început și de oprire, porțiunea începe de la început - și se extinde până la sfârșitul cadrului de date - selectând toate rândurile.
Când utilizați metoda loc() , trebuie să treceți etichetele rândurilor și coloanelor pe care doriți să le selectați, după cum se arată:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 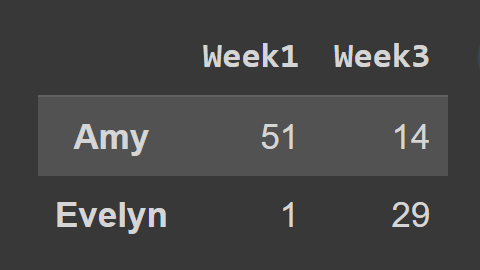
Aici, dataframe subset_df2 conține înregistrarea lui Amy și Evelyn pentru Săptămâna1 și Săptămâna3.
Concluzie
Iată o scurtă trecere în revistă a ceea ce ați învățat în acest tutorial:
- După instalarea panda, îl puteți importa sub aliasul
pd. Pentru a crea un obiect cadru de date panda, puteți utiliza constructorulpd.DataFrame(data), undedatase referă la o matrice N-dimensională sau la un iterabil care conține datele. Puteți specifica rândul și indexul și etichetele coloanei setând parametrii opționali pentru index și, respectiv, coloane. - Folosind
pd.read_csv(path-to-the-file)citește conținutul fișierului într-un cadru de date. - Puteți apela metoda
info()pe obiectul cadru de date pentru a obține informații despre coloane, numărul de valori lipsă, tipurile de date și dimensiunea cadrului de date. - Pentru a selecta o singură coloană, utilizați
df_name[col_name]și pentru a selecta mai multe coloane, o anumită coloană,df_name[[col1,col2,...,coln]]. - De asemenea, puteți selecta coloane și rânduri folosind metodele
loc()șiiloc(). - În timp ce metoda
iloc()preia indexul (sau porțiunea de index) al rândurilor și coloanelor de selectat, metodaloc()preia etichetele rândurilor și coloanelor.
Puteți găsi exemplele folosite în acest tutorial în acest caiet Colab.
Apoi, consultați această listă de caiete de știință a datelor colaborative.