
使用 Python 進行網頁抓取:分步指南
已發表: 2022-11-28Web 抓取是從網站中提取信息並將其用於特定用例的想法。
假設您正嘗試從網頁中提取表格,將其轉換為 JSON 文件並使用 JSON 文件構建一些內部工具。 在網絡抓取的幫助下,您可以通過定位網頁中的特定元素來提取所需的數據。 使用 Python 進行 Web 抓取是一種非常流行的選擇,因為 Python 提供了多個庫(如 BeautifulSoup 或 Scrapy)來有效地提取數據。

作為開發人員或數據科學家,擁有有效提取數據的技能也非常重要。 本文將幫助您了解如何有效地抓取網站並獲取必要的內容以根據需要對其進行操作。 對於本教程,我們將使用 BeautifulSoup 包。 它是一個用於在 Python 中抓取數據的流行包。
為什麼使用 Python 進行網頁抓取?
Python 是許多開發人員在構建網絡抓取工具時的首選。 Python 成為首選的原因有很多,但對於本文,我們將討論使用 Python 進行數據抓取的三個主要原因。
庫和社區支持:有幾個很棒的庫,如 BeautifulSoup、Scrapy、Selenium 等,它們提供了有效抓取網頁的強大功能。 它為網絡抓取構建了一個優秀的生態系統,也因為全球許多開發人員已經在使用 Python,所以當你遇到困難時可以快速獲得幫助。
自動化: Python 以其自動化功能而聞名。 如果您正在嘗試製作依賴於抓取的複雜工具,則需要的不僅僅是網絡抓取。 例如,如果您想構建一個工具來跟踪在線商店中的商品價格,您需要添加一些自動化功能,以便它可以每天跟踪費率並將它們添加到您的數據庫中。 Python 使您能夠輕鬆地自動化這些過程。
數據可視化:網絡抓取被數據科學家大量使用。 數據科學家經常需要從網頁中提取數據。 借助像 Pandas 這樣的庫,Python 使原始數據的數據可視化變得更簡單。
用於 Python 網頁抓取的庫
Python 中有幾個庫可用於簡化網絡抓取。 讓我們在這裡討論三個最受歡迎的庫。
#1。 美湯
最受歡迎的網絡抓取庫之一。 BeautifulSoup 自 2004 年以來一直在幫助開發人員抓取網頁。它提供了導航、搜索和修改解析樹的簡單方法。 Beautifulsoup 本身也對傳入和傳出數據進行編碼。 它維護良好,擁有一個很棒的社區。
#2。 廢料
另一個流行的數據提取框架。 Scrapy 在 GitHub 上有超過 43000 顆星。 它還可用於從 API 中抓取數據。 它還具有一些有趣的內置支持,例如發送電子郵件。
#3。 硒
Selenium 主要不是網絡抓取庫。 相反,它是一個瀏覽器自動化包。 但是我們可以很容易地擴展它的功能來抓取網頁。 它使用 WebDriver 協議來控制不同的瀏覽器。 Selenium 已經上市近 20 年了。 但是使用 Selenium,您可以輕鬆地從網頁中自動化和抓取數據。
Python Web 抓取的挑戰
嘗試從網站抓取數據時可能會面臨許多挑戰。 存在諸如網絡緩慢、反抓取工具、基於 IP 的阻止、驗證碼阻止等問題。在嘗試抓取網站時,這些問題可能會導致大量問題。
但是您可以通過以下一些方法有效地繞過挑戰。 例如,在大多數情況下,當在特定時間間隔內發送的請求超過一定數量時,IP 地址就會被網站屏蔽。 為避免 IP 阻塞,您需要對爬蟲進行編碼,使其在發送請求後冷卻下來。

開發人員還傾向於為爬蟲設置蜜罐陷阱。 這些陷阱通常是肉眼看不見的,但可以通過刮板爬行。 如果你正在抓取一個放置了這樣一個蜜罐陷阱的網站,你需要相應地編寫你的抓取程序的代碼。
驗證碼是爬蟲的另一個嚴重問題。 現在大多數網站都使用驗證碼來保護機器人對其頁面的訪問。 在這種情況下,您可能需要使用驗證碼求解器。
用 Python 抓取網站
正如我們所討論的,我們將使用 BeautifulSoup 來廢棄網站。 在本教程中,我們將從 Coingecko 中抓取以太坊的歷史數據並將表數據保存為 JSON 文件。 讓我們繼續構建刮板。
第一步是安裝 BeautifulSoup 和 Requests。 對於本教程,我將使用 Pipenv。 Pipenv 是 Python 的虛擬環境管理器。 如果需要,您也可以使用 Venv,但我更喜歡 Pipenv。 討論 Pipenv 超出了本教程的範圍。 但如果您想了解如何使用 Pipenv,請遵循本指南。 或者,如果您想了解 Python 虛擬環境,請遵循本指南。
通過運行命令pipenv shell 。 它將在您的虛擬環境中啟動一個子外殼。 現在,要安裝 BeautifulSoup,請運行以下命令:
pipenv install beautifulsoup4並且,對於安裝請求,運行類似於上面的命令:
pipenv install requests 安裝完成後,將必要的包導入到主文件中。 創建一個名為main.py的文件並導入如下所示的包:
from bs4 import BeautifulSoup import requests import json下一步是獲取歷史數據頁面的內容並使用 BeautifulSoup 中可用的 HTML 解析器解析它們。
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel') soup = BeautifulSoup(r.content, 'html.parser') 在上面的代碼中,使用請求庫中可用的get方法訪問頁面。 然後將解析的內容存儲在一個名為soup的變量中。
原來的抓取部分現在開始。 首先,您需要在 DOM 中正確識別表格。 如果您打開此頁面並使用瀏覽器中可用的開發人員工具對其進行檢查,您將看到該表具有這些類table table-striped text-sm text-lg-normal 。
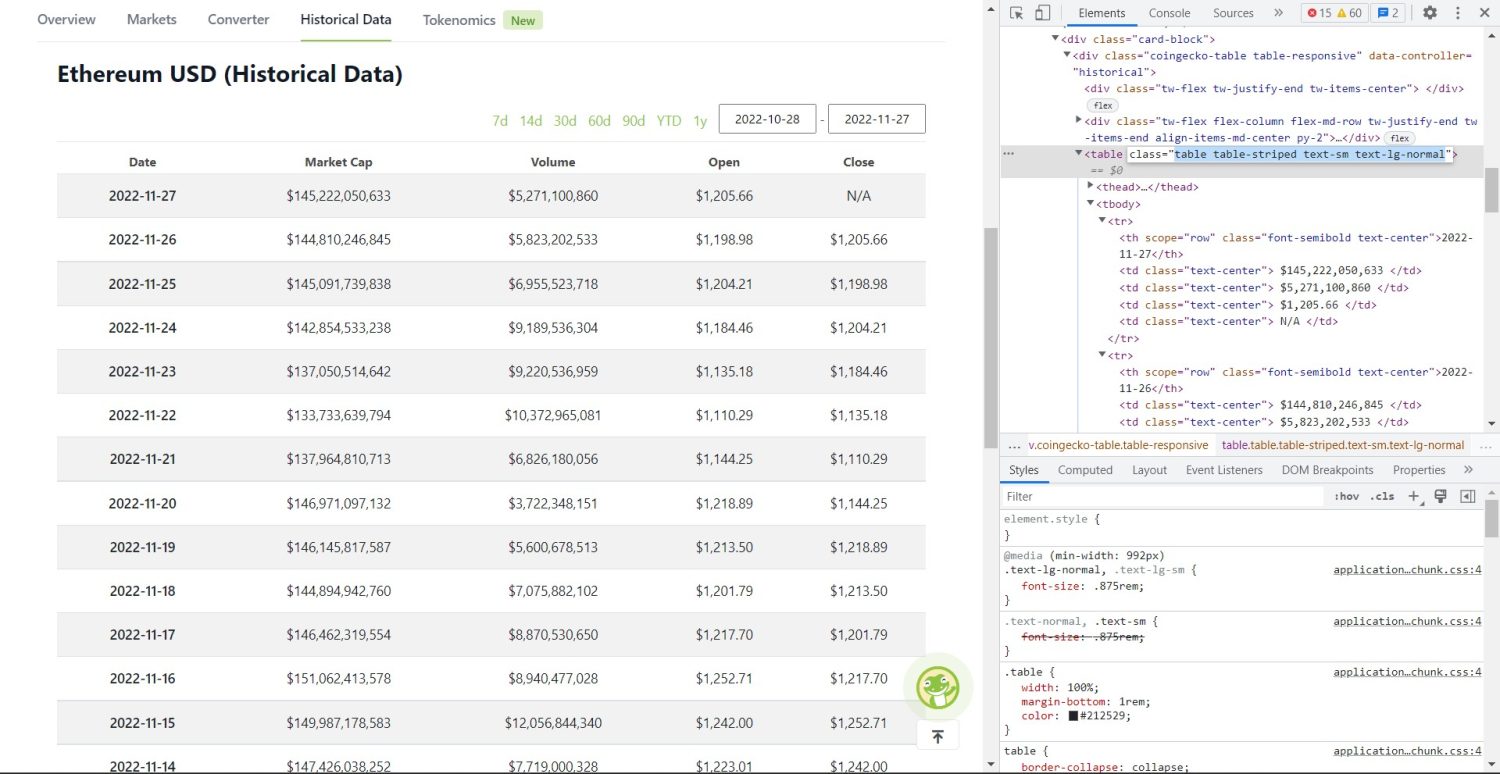
要正確定位此表,您可以使用find方法。

table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'}) table_data = table.find_all('tr') table_headings = [] for th in table_data[0].find_all('th'): table_headings.append(th.text) 在上面的代碼中,首先使用soup.find方法找到表格,然後使用find_all方法搜索表格內的所有tr元素。 這些tr元素存儲在一個名為table_data的變量中。 該表有幾個th元素。 一個名為table_headings的新變量被初始化以將標題保存在列表中。
然後對錶的第一行運行 for 循環。 在這一行中,搜索所有帶有th的元素,並將它們的文本值添加到table_headings列表中。 使用text方法提取文本。 如果您現在打印table_headings變量,您將能夠看到以下輸出:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']下一步是抓取其餘元素,為每一行生成一個字典,然後將這些行附加到列表中。
for tr in table_data: th = tr.find_all('th') td = tr.find_all('td') data = {} for i in range(len(td)): data.update({table_headings[0]: th[0].text}) data.update({table_headings[i+1]: td[i].text.replace('\n', '')}) if data.__len__() > 0: table_details.append(data) 這是代碼的基本部分。 對於table_data變量中的每個tr ,首先搜索th元素。 第th元素是表中顯示的日期。 這些th元素存儲在變量th中。 同樣,所有td元素都存儲在td變量中。
一個空的字典data被初始化。 初始化後,我們遍歷td元素的範圍。 對於每一行,首先,我們用th的第一項更新字典的第一個字段。 代碼table_headings[0]: th[0].text分配了 date 和第一個th元素的鍵值對。
初始化第一個元素後,使用data.update({table_headings[i+1]: td[i].text.replace('\\n', '')})分配其他元素。 這里首先使用text方法提取td元素文本,然後使用replace方法替換所有\\n 。 然後將該值分配給table_headings列表的第i+1個元素,因為第i個元素已經分配。
然後,如果data字典長度超過零,我們將字典附加到table_details列表。 您可以打印table_details列表進行檢查。 但是我們會將這些值寫入一個 JSON 文件。 讓我們看一下代碼,
with open('table.json', 'w') as f: json.dump(table_details, f, indent=2) print('Data saved to json file...') 我們在這裡使用json.dump方法將值寫入名為table.json的 JSON 文件。 寫入完成後,我們Data saved to json file...打印到控制台。
現在,使用以下命令運行該文件,
python run main.py一段時間後,您將能夠在控制台中看到 Data saved to JSON file... 文本。 您還會在工作文件目錄中看到一個名為 table.json 的新文件。 該文件將類似於以下 JSON 文件:
[ { "Date": "2022-11-27", "Market Cap": "$145,222,050,633", "Volume": "$5,271,100,860", "Open": "$1,205.66", "Close": "N/A" }, { "Date": "2022-11-26", "Market Cap": "$144,810,246,845", "Volume": "$5,823,202,533", "Open": "$1,198.98", "Close": "$1,205.66" }, { "Date": "2022-11-25", "Market Cap": "$145,091,739,838", "Volume": "$6,955,523,718", "Open": "$1,204.21", "Close": "$1,198.98" }, // ... // ... ]您已經使用 Python 成功地實現了一個網絡抓取工具。 要查看完整代碼,您可以訪問此 GitHub 存儲庫。
結論
本文討論瞭如何實現簡單的 Python 抓取。 我們討論瞭如何使用 BeautifulSoup 從網站快速抓取數據。 我們還討論了其他可用的庫,以及為什麼 Python 是許多開發人員抓取網站的首選。
您還可以查看這些網絡抓取框架。