
Парсинг веб-страниц с использованием Python: пошаговое руководство
Опубликовано: 2022-11-28Веб-скрапинг — это идея извлечения информации с веб-сайта и использования ее для определенного варианта использования.
Допустим, вы пытаетесь извлечь таблицу с веб-страницы, преобразовать ее в файл JSON и использовать файл JSON для создания некоторых внутренних инструментов. С помощью веб-скрапинга вы можете извлекать нужные данные, ориентируясь на определенные элементы на веб-странице. Веб-скрапинг с использованием Python — очень популярный выбор, поскольку Python предоставляет несколько библиотек, таких как BeautifulSoup или Scrapy, для эффективного извлечения данных.

Навык эффективного извлечения данных также очень важен для разработчика или специалиста по данным. Эта статья поможет вам понять, как эффективно очищать веб-сайт и получать необходимый контент, чтобы манипулировать им в соответствии с вашими потребностями. В этом уроке мы будем использовать пакет BeautifulSoup. Это модный пакет для очистки данных в Python.
Зачем использовать Python для парсинга веб-страниц?
Python — это первый выбор для многих разработчиков при создании парсеров. Есть много причин, по которым Python является первым выбором, но в этой статье давайте обсудим три основные причины, по которым Python используется для очистки данных.
Библиотека и поддержка сообщества: существует несколько замечательных библиотек, таких как BeautifulSoup, Scrapy, Selenium и т. д., которые предоставляют отличные функции для эффективного парсинга веб-страниц. Он создал отличную экосистему для веб-скрапинга, а также, поскольку многие разработчики по всему миру уже используют Python, вы можете быстро получить помощь, если застряли.
Автоматизация: Python славится своими возможностями автоматизации. Если вы пытаетесь создать сложный инструмент, основанный на парсинге, требуется нечто большее, чем парсинг веб-страниц. Например, если вы хотите создать инструмент, который отслеживает цены на товары в интернет-магазине, вам нужно добавить некоторые возможности автоматизации, чтобы он мог ежедневно отслеживать цены и добавлять их в свою базу данных. Python дает вам возможность легко автоматизировать такие процессы.
Визуализация данных: веб-скрапинг активно используется учеными, занимающимися данными. Специалистам по данным часто приходится извлекать данные с веб-страниц. Благодаря таким библиотекам, как Pandas, Python упрощает визуализацию данных из необработанных данных.
Библиотеки для парсинга веб-страниц в Python
В Python есть несколько библиотек, упрощающих просмотр веб-страниц. Давайте обсудим здесь три самые популярные библиотеки.
№1. КрасивыйСуп
Одна из самых популярных библиотек для парсинга веб-страниц. BeautifulSoup помогает разработчикам парсить веб-страницы с 2004 года. Он предоставляет простые методы для навигации, поиска и изменения дерева синтаксического анализа. Сам Beautifulsoup также выполняет кодирование входящих и исходящих данных. Он в хорошем состоянии и имеет большое сообщество.
№ 2. Скрапи
Еще один популярный фреймворк для извлечения данных. Scrapy имеет более 43000 звезд на GitHub. Его также можно использовать для извлечения данных из API. Он также имеет несколько интересных встроенных функций, таких как отправка электронных писем.
№3. Селен
Selenium — это не только библиотека веб-скрейпинга. Вместо этого это пакет автоматизации браузера. Но мы можем легко расширить его функциональность для парсинга веб-страниц. Он использует протокол WebDriver для управления различными браузерами. Selenium существует на рынке уже почти 20 лет. Но с помощью Selenium вы можете легко автоматизировать и собирать данные с веб-страниц.
Проблемы с парсингом веб-страниц Python
При попытке собрать данные с веб-сайтов можно столкнуться со многими проблемами. Существуют такие проблемы, как медленные сети, инструменты для защиты от парсинга, блокировка на основе IP, блокировка по капче и т. д. Эти проблемы могут вызвать серьезные проблемы при попытке парсинга веб-сайта.
Но вы можете эффективно обойти проблемы, следуя некоторым способам. Например, в большинстве случаев IP-адрес блокируется веб-сайтом, когда за определенный интервал времени отправляется больше определенного количества запросов. Чтобы избежать блокировки по IP-адресу, вам нужно запрограммировать парсер так, чтобы он «остывал» после отправки запросов.

Разработчики также склонны ставить ловушки-ловушки для скребков. Эти ловушки обычно невидимы невооруженным глазом, но их можно проползти скребком. Если вы очищаете веб-сайт, который ставит такую ловушку-ловушку, вам нужно соответствующим образом закодировать свой парсер.
Captcha — еще одна серьезная проблема со скребками. В настоящее время большинство веб-сайтов используют капчу для защиты доступа ботов к своим страницам. В таком случае вам может понадобиться использовать решатель капчи.
Парсинг веб-сайта с помощью Python
Как мы уже говорили, мы будем использовать BeautifulSoup для удаления веб-сайта. В этом руководстве мы соберем исторические данные Ethereum из Coingecko и сохраним данные таблицы в виде файла JSON. Приступаем к созданию скребка.
Первый шаг — установить BeautifulSoup и Requests. В этом уроке я буду использовать Pipenv. Pipenv — это менеджер виртуальной среды для Python. Вы также можете использовать Venv, если хотите, но я предпочитаю Pipenv. Обсуждение Pipenv выходит за рамки этого руководства. Но если вы хотите узнать, как можно использовать Pipenv, следуйте этому руководству. Или, если вы хотите понять виртуальные среды Python, следуйте этому руководству.
Запустите оболочку Pipenv в каталоге вашего проекта, выполнив команду pipenv shell . Он запустит подоболочку в вашей виртуальной среде. Теперь, чтобы установить BeautifulSoup, выполните следующую команду:
pipenv install beautifulsoup4И для установки запросов выполните команду, аналогичную приведенной выше:
pipenv install requests После завершения установки импортируйте необходимые пакеты в основной файл. Создайте файл с именем main.py и импортируйте пакеты, как показано ниже:

from bs4 import BeautifulSoup import requests import jsonСледующий шаг — получить содержимое страницы исторических данных и проанализировать его с помощью анализатора HTML, доступного в BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel') soup = BeautifulSoup(r.content, 'html.parser') В приведенном выше коде доступ к странице осуществляется с помощью метода get , доступного в библиотеке запросов. Затем проанализированное содержимое сохраняется в переменной с именем soup .
Оригинальная часть очистки начинается сейчас. Во-первых, вам нужно правильно идентифицировать таблицу в DOM. Если вы откроете эту страницу и просмотрите ее с помощью инструментов разработчика, доступных в браузере, вы увидите, что в таблице есть эти классы table table-striped text-sm text-lg-normal .
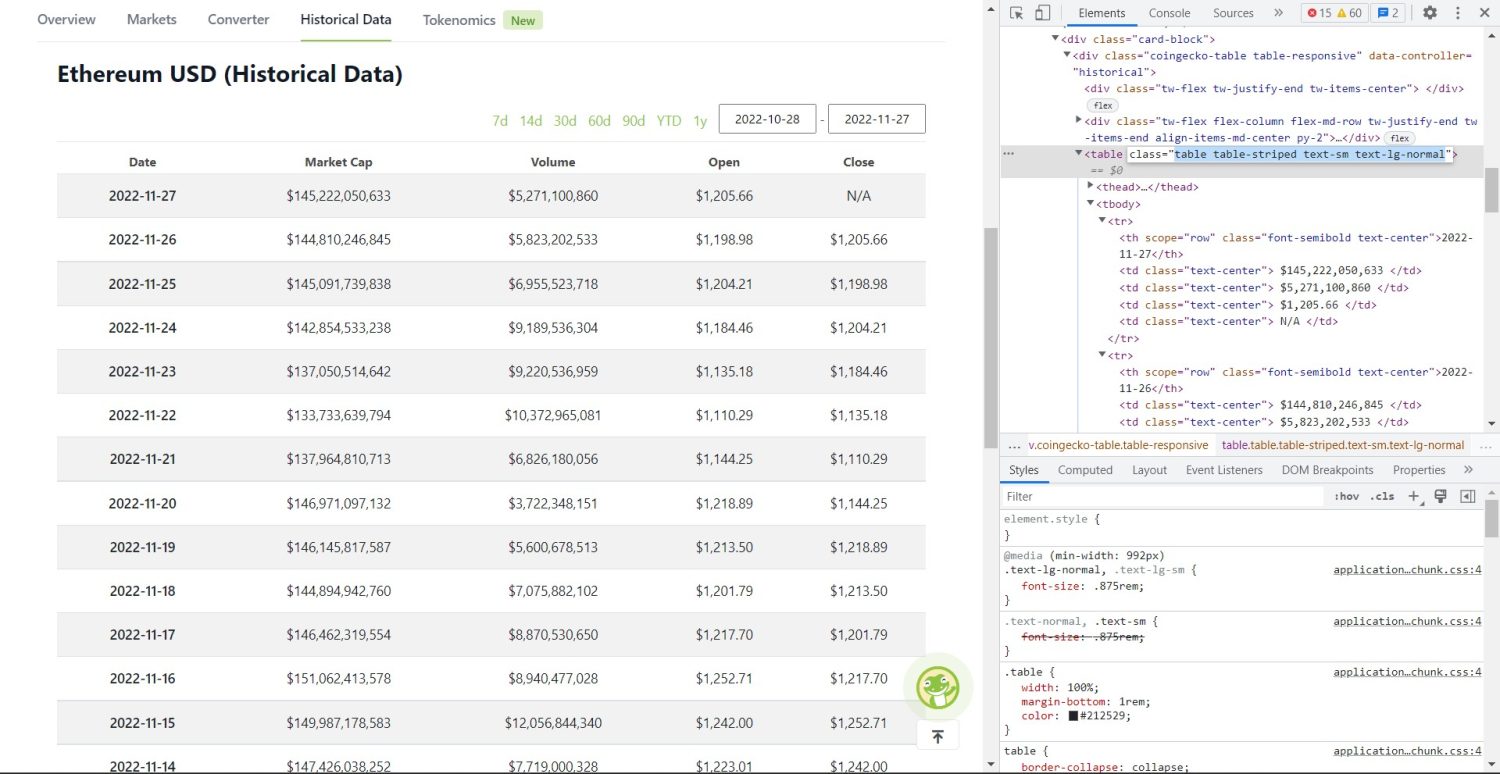
Чтобы правильно настроить таргетинг на эту таблицу, вы можете использовать метод find .
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'}) table_data = table.find_all('tr') table_headings = [] for th in table_data[0].find_all('th'): table_headings.append(th.text) В приведенном выше коде сначала выполняется поиск таблицы с помощью метода soup.find , затем с помощью метода find_all выполняется поиск всех элементов tr внутри таблицы. Эти элементы tr хранятся в переменной с именем table_data . В таблице есть несколько th для заголовка. Новая переменная table_headings инициализируется для хранения заголовков в списке.
Затем запускается цикл for для первой строки таблицы. В этой строке ищутся все элементы с th , и их текстовое значение добавляется в список table_headings . Текст извлекается с помощью text метода. Если вы напечатаете переменную table_headings сейчас, вы сможете увидеть следующий вывод:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']Следующий шаг — очистить остальные элементы, создать словарь для каждой строки, а затем добавить строки в список.
for tr in table_data: th = tr.find_all('th') td = tr.find_all('td') data = {} for i in range(len(td)): data.update({table_headings[0]: th[0].text}) data.update({table_headings[i+1]: td[i].text.replace('\n', '')}) if data.__len__() > 0: table_details.append(data) Это основная часть кода. Для каждого tr в переменной table_data сначала ищутся элементы th . Элементы th представляют собой дату, показанную в таблице. Эти элементы th хранятся внутри переменной th . Точно так же все элементы td хранятся в переменной td .
Инициализируются пустые data словаря. После инициализации мы перебираем диапазон элементов td . Для каждой строки сначала мы обновляем первое поле словаря первым элементом th . Код table_headings[0]: th[0].text назначает пару ключ-значение даты и первого элемента th .
После инициализации первого элемента остальные элементы назначаются с помощью data.update({table_headings[i+1]: td[i].text.replace('\\n', '')}) . Здесь текст элементов td сначала извлекается с помощью метода text , а затем все \\n заменяется с помощью метода replace . Затем значение присваивается i+1 -му элементу списка table_headings поскольку i -й элемент уже назначен.
Затем, если длина словаря data больше нуля, мы добавляем словарь в список table_details . Вы можете распечатать список table_details для проверки. Но мы будем записывать значения в файл JSON. Давайте посмотрим на код для этого,
with open('table.json', 'w') as f: json.dump(table_details, f, indent=2) print('Data saved to json file...') Здесь мы используем метод json.dump для записи значений в файл JSON с именем table.json . После завершения записи мы печатаем Data saved to json file... в консоль.
Теперь запустите файл с помощью следующей команды:
python run main.pyЧерез некоторое время вы сможете увидеть данные, сохраненные в файле JSON… текст в консоли. Вы также увидите новый файл с именем table.json в рабочем каталоге файлов. Файл будет похож на следующий файл JSON:
[ { "Date": "2022-11-27", "Market Cap": "$145,222,050,633", "Volume": "$5,271,100,860", "Open": "$1,205.66", "Close": "N/A" }, { "Date": "2022-11-26", "Market Cap": "$144,810,246,845", "Volume": "$5,823,202,533", "Open": "$1,198.98", "Close": "$1,205.66" }, { "Date": "2022-11-25", "Market Cap": "$145,091,739,838", "Volume": "$6,955,523,718", "Open": "$1,204.21", "Close": "$1,198.98" }, // ... // ... ]Вы успешно реализовали парсер веб-страниц с помощью Python. Чтобы просмотреть полный код, вы можете посетить этот репозиторий GitHub.
Вывод
В этой статье обсуждалось, как реализовать простую очистку Python. Мы обсудили, как можно использовать BeautifulSoup для быстрого извлечения данных с веб-сайта. Мы также обсудили другие доступные библиотеки и то, почему многие разработчики выбирают Python для парсинга веб-сайтов.
Вы также можете посмотреть на эти веб-фреймворки.