
تجريف الويب باستخدام Python: دليل خطوة بخطوة
نشرت: 2022-11-28تجريف الويب هو فكرة استخراج المعلومات من موقع الويب واستخدامها لحالة استخدام معينة.
لنفترض أنك تحاول استخراج جدول من صفحة ويب ، وتحويله إلى ملف JSON واستخدام ملف JSON لبناء بعض الأدوات الداخلية. بمساعدة تجريف الويب ، يمكنك استخراج البيانات التي تريدها عن طريق استهداف عناصر محددة في صفحة ويب. يعد تجريف الويب باستخدام Python خيارًا شائعًا للغاية حيث توفر Python مكتبات متعددة مثل BeautifulSoup أو Scrapy لاستخراج البيانات بشكل فعال.

إن امتلاك مهارة استخراج البيانات بكفاءة أمر مهم أيضًا كمطور أو عالم بيانات. ستساعدك هذه المقالة على فهم كيفية التخلص من موقع ويب بشكل فعال والحصول على المحتوى الضروري للتلاعب به وفقًا لحاجتك. في هذا البرنامج التعليمي ، سنستخدم حزمة BeautifulSoup. إنها حزمة عصرية لكشط البيانات في بايثون.
لماذا تستخدم Python في Web Scraping؟
Python هو الخيار الأول للعديد من المطورين عند إنشاء كاشطات الويب. هناك العديد من الأسباب التي تجعل Python هي الخيار الأول ، ولكن بالنسبة لهذه المقالة ، دعنا نناقش ثلاثة أسباب رئيسية لاستخدام Python في تجريف البيانات.
دعم المكتبات والمجتمع: هناك العديد من المكتبات الرائعة ، مثل BeautifulSoup و Scrapy و Selenium وما إلى ذلك ، والتي توفر وظائف رائعة لإلغاء صفحات الويب بشكل فعال. لقد أنشأ نظامًا بيئيًا ممتازًا لكشط الويب ، وأيضًا نظرًا لأن العديد من المطورين في جميع أنحاء العالم يستخدمون Python بالفعل ، يمكنك الحصول على المساعدة بسرعة عندما تكون عالقًا.
الأتمتة: تشتهر Python بقدرات الأتمتة. مطلوب أكثر من تجريف الويب إذا كنت تحاول إنشاء أداة معقدة تعتمد على الكشط. على سبيل المثال ، إذا كنت ترغب في إنشاء أداة تتعقب أسعار العناصر في متجر عبر الإنترنت ، فستحتاج إلى إضافة بعض إمكانيات التشغيل الآلي حتى تتمكن من تتبع الأسعار يوميًا وإضافتها إلى قاعدة البيانات الخاصة بك. تمنحك Python القدرة على أتمتة مثل هذه العمليات بسهولة.
تصور البيانات: يستخدم علماء البيانات تجريف الويب بشكل كبير. غالبًا ما يحتاج علماء البيانات إلى استخراج البيانات من صفحات الويب. باستخدام مكتبات مثل Pandas ، تجعل Python تصور البيانات أبسط من البيانات الأولية.
مكتبات تجريف الويب في بايثون
هناك العديد من المكتبات المتاحة في Python لتسهيل تجريف الويب. دعونا نناقش أكثر ثلاث مكتبات شعبية هنا.
# 1. شوربة جميلة
إحدى المكتبات الأكثر شيوعًا لإلغاء بيانات الويب. تساعد BeautifulSoup المطورين في كشط صفحات الويب منذ عام 2004. وهي توفر طرقًا بسيطة للتنقل والبحث وتعديل شجرة التحليل. تقوم Beautifulsoup نفسها أيضًا بتشفير البيانات الواردة والصادرة. إنه مصان جيدًا وله مجتمع كبير.
# 2. سكرابى
إطار عمل شائع آخر لاستخراج البيانات. لدى Scrapy أكثر من 43000 نجمة على GitHub. يمكن استخدامه أيضًا لكشط البيانات من واجهات برمجة التطبيقات. كما أن لديها بعض الدعم المدمج المثير للاهتمام ، مثل إرسال رسائل البريد الإلكتروني.
# 3. السيلينيوم
السيلينيوم ليس مكتبة كشط على الويب بشكل أساسي. بدلاً من ذلك ، إنها حزمة أتمتة للمتصفح. ولكن يمكننا بسهولة توسيع وظائفه لإلغاء صفحات الويب. يستخدم بروتوكول WebDriver للتحكم في المتصفحات المختلفة. السيلينيوم موجود في السوق منذ ما يقرب من 20 عامًا حتى الآن. ولكن باستخدام السيلينيوم ، يمكنك بسهولة أتمتة البيانات وكشطها من صفحات الويب.
التحديات مع كشط ويب بايثون
يمكن للمرء أن يواجه العديد من التحديات عند محاولة كشط البيانات من مواقع الويب. هناك مشكلات مثل الشبكات البطيئة ، وأدوات مكافحة التجريف ، والحظر المستند إلى IP ، وحظر captcha ، وما إلى ذلك. يمكن أن تتسبب هذه المشكلات في حدوث مشكلات هائلة عند محاولة كشف موقع ويب.
ولكن يمكنك تجاوز التحديات بشكل فعال باتباع بعض الطرق. على سبيل المثال ، في معظم الحالات ، يتم حظر عنوان IP بواسطة موقع ويب عندما يكون هناك أكثر من عدد معين من الطلبات المرسلة في فترة زمنية محددة. لتجنب حظر IP ، ستحتاج إلى ترميز الكاشط الخاص بك بحيث يبرد بعد إرسال الطلبات.

يميل المطورون أيضًا إلى وضع مصائد مواضع الجذب للكاشطات. عادة ما تكون هذه المصائد غير مرئية للعين البشرية ولكن يمكن الزحف إليها بواسطة مكشطة. إذا كنت تقوم بإلغاء موقع ويب يضع مثل هذا المصيدة لشبكة الإنترنت ، فستحتاج إلى ترميز الكاشطة وفقًا لذلك.
Captcha هي مشكلة خطيرة أخرى مع الكاشطات. تستخدم معظم مواقع الويب في الوقت الحاضر رمز التحقق (captcha) لحماية وصول الروبوت إلى صفحاتهم. في مثل هذه الحالة ، قد تحتاج إلى استخدام برنامج captcha solver.
تجريف موقع ويب باستخدام Python
كما ناقشنا ، سنستخدم BeautifulSoup لإلغاء موقع ويب. في هذا البرنامج التعليمي ، سنقوم بكشط البيانات التاريخية لـ Ethereum من Coingecko وحفظ بيانات الجدول كملف JSON. دعنا ننتقل إلى بناء الكاشطة.
الخطوة الأولى هي تثبيت BeautifulSoup وطلبات. في هذا البرنامج التعليمي ، سأستخدم Pipenv. Pipenv هو مدير بيئة افتراضية لبايثون. يمكنك أيضًا استخدام Venv إذا كنت تريد ، لكنني أفضل Pipenv. مناقشة Pipenv خارج نطاق هذا البرنامج التعليمي. ولكن إذا كنت تريد معرفة كيفية استخدام Pipenv ، فاتبع هذا الدليل. أو ، إذا كنت تريد فهم بيئات Python الافتراضية ، فاتبع هذا الدليل.
قم بتشغيل Pipenv shell في دليل المشروع الخاص بك عن طريق تشغيل الأمر pipenv shell . سيطلق قشرة فرعية في بيئتك الافتراضية. الآن ، لتثبيت BeautifulSoup ، قم بتشغيل الأمر التالي:
pipenv install beautifulsoup4ولتثبيت الطلبات ، قم بتشغيل الأمر المماثل لما سبق:
pipenv install requests بمجرد اكتمال التثبيت ، قم باستيراد الحزم الضرورية إلى الملف الرئيسي. قم بإنشاء ملف يسمى main.py واستيراد الحزم كما يلي:
from bs4 import BeautifulSoup import requests import jsonالخطوة التالية هي الحصول على محتويات صفحة البيانات التاريخية وتحليلها باستخدام محلل HTML المتاح في BeautifulSoup.

r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel') soup = BeautifulSoup(r.content, 'html.parser') في الكود أعلاه ، يتم الوصول إلى الصفحة باستخدام طريقة get المتوفرة في مكتبة الطلبات. ثم يتم تخزين المحتوى الذي تم تحليله في متغير يسمى soup .
يبدأ جزء الكشط الأصلي الآن. أولاً ، ستحتاج إلى تحديد الجدول بشكل صحيح في DOM. إذا فتحت هذه الصفحة وفحصتها باستخدام أدوات المطور المتوفرة في المستعرض ، فسترى أن الجدول يحتوي على جدول الفئات table table-striped text-sm text-lg-normal .
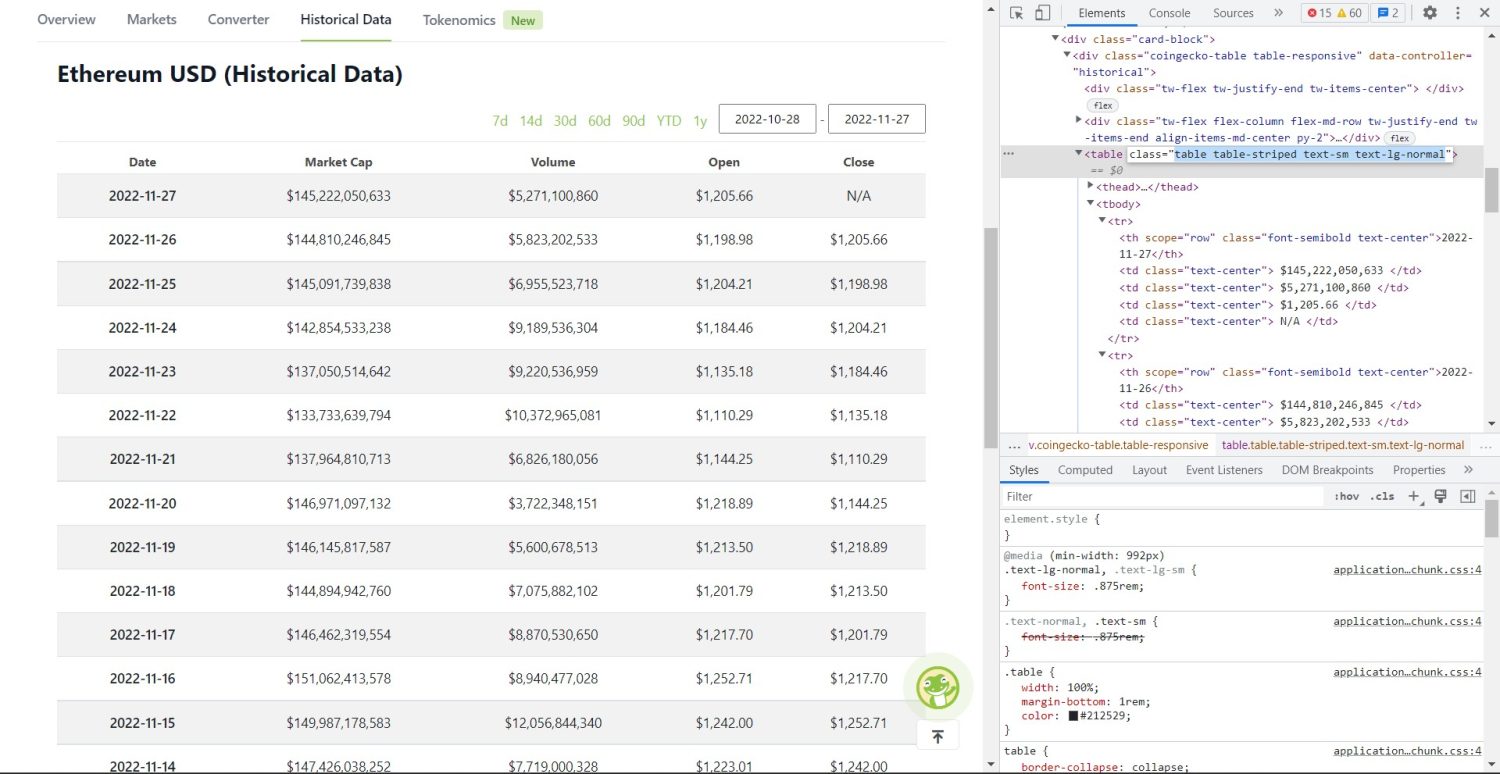
لاستهداف هذا الجدول بشكل صحيح ، يمكنك استخدام طريقة find .
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'}) table_data = table.find_all('tr') table_headings = [] for th in table_data[0].find_all('th'): table_headings.append(th.text) في الكود أعلاه ، أولاً ، تم العثور على الجدول باستخدام طريقة soup.find ، ثم باستخدام طريقة find_all ، يتم البحث عن جميع عناصر tr داخل الجدول. يتم تخزين هذه العناصر tr في متغير يسمى table_data . يحتوي الجدول على عدد th من العناصر الخاصة بالعنوان. تمت تهيئة متغير جديد يسمى table_headings للاحتفاظ بالعناوين في قائمة.
ثم يتم تشغيل حلقة for للصف الأول من الجدول. في هذا الصف ، يتم البحث في جميع العناصر التي تحتوي على th ، وتضاف قيمتها النصية إلى قائمة table_headings . يتم استخراج النص باستخدام طريقة text . إذا قمت بطباعة متغير table_headings الآن ، فستتمكن من رؤية الإخراج التالي:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']الخطوة التالية هي حذف باقي العناصر ، وإنشاء قاموس لكل صف ، ثم إلحاق الصفوف بقائمة.
for tr in table_data: th = tr.find_all('th') td = tr.find_all('td') data = {} for i in range(len(td)): data.update({table_headings[0]: th[0].text}) data.update({table_headings[i+1]: td[i].text.replace('\n', '')}) if data.__len__() > 0: table_details.append(data) هذا هو الجزء الأساسي من الكود. لكل tr في متغير table_data ، يتم البحث أولاً عن العناصر th . العناصر th هي التاريخ المبين في الجدول. يتم تخزين هذه العناصر داخل th th وبالمثل ، يتم تخزين جميع عناصر td في متغير td .
يتم تهيئة data القاموس الفارغة. بعد التهيئة ، نقوم بعمل حلقة عبر نطاق عناصر td . لكل صف ، أولاً ، نقوم بتحديث الحقل الأول من القاموس بالعنصر الأول من th . الكود table_headings[0]: th[0].text يعين زوج القيمة الرئيسية للتاريخ والعنصر th .
بعد تهيئة العنصر الأول ، يتم تعيين العناصر الأخرى باستخدام data.update({table_headings[i+1]: td[i].text.replace('\\n', '')}) . هنا ، يتم أولاً استخراج نص عناصر td باستخدام طريقة text ، ثم يتم استبدال all \\n باستخدام طريقة replace . ثم يتم تعيين القيمة للعنصر i i+1 من قائمة table_headings لأنه تم تعيين العنصر الأول بالفعل.
ثم ، إذا تجاوز طول قاموس data الصفر ، فإننا نلحق القاموس بقائمة table_details . يمكنك طباعة قائمة table_details للتحقق. لكننا سنكتب القيم في ملف JSON. دعنا نلقي نظرة على رمز هذا ،
with open('table.json', 'w') as f: json.dump(table_details, f, indent=2) print('Data saved to json file...') نحن نستخدم طريقة json.dump هنا لكتابة القيم في ملف JSON يسمى table.json . بمجرد اكتمال الكتابة ، نقوم بطباعة Data saved to json file... في وحدة التحكم.
الآن ، قم بتشغيل الملف باستخدام الأمر التالي ،
python run main.pyبعد مرور بعض الوقت ، ستتمكن من رؤية البيانات المحفوظة في ملف JSON ... نص في وحدة التحكم. سترى أيضًا ملفًا جديدًا يسمى table.json في دليل ملفات العمل. سيبدو الملف مشابهًا لملف JSON التالي:
[ { "Date": "2022-11-27", "Market Cap": "$145,222,050,633", "Volume": "$5,271,100,860", "Open": "$1,205.66", "Close": "N/A" }, { "Date": "2022-11-26", "Market Cap": "$144,810,246,845", "Volume": "$5,823,202,533", "Open": "$1,198.98", "Close": "$1,205.66" }, { "Date": "2022-11-25", "Market Cap": "$145,091,739,838", "Volume": "$6,955,523,718", "Open": "$1,204.21", "Close": "$1,198.98" }, // ... // ... ]لقد نجحت في تنفيذ برنامج مكشطة ويب باستخدام Python. لعرض الكود الكامل ، يمكنك زيارة GitHub repo.
استنتاج
ناقش هذا المقال كيف يمكنك تنفيذ كشط بسيط من لغة بايثون. ناقشنا كيف يمكن استخدام BeautifulSoup لجمع البيانات بسرعة من موقع الويب. ناقشنا أيضًا المكتبات الأخرى المتاحة ولماذا تعد Python الخيار الأول للعديد من المطورين لإلغاء مواقع الويب.
يمكنك أيضًا إلقاء نظرة على أطر تجريف الويب هذه.