
การขูดเว็บโดยใช้ Python: คำแนะนำทีละขั้นตอน
เผยแพร่แล้ว: 2022-11-28การขูดเว็บเป็นแนวคิดในการดึงข้อมูลจากเว็บไซต์และใช้สำหรับกรณีการใช้งานเฉพาะ
สมมติว่าคุณกำลังพยายามแยกตารางออกจากหน้าเว็บ แปลงเป็นไฟล์ JSON และใช้ไฟล์ JSON เพื่อสร้างเครื่องมือภายใน ด้วยความช่วยเหลือของการขูดเว็บ คุณสามารถแยกข้อมูลที่คุณต้องการโดยกำหนดเป้าหมายองค์ประกอบเฉพาะในหน้าเว็บ การขูดเว็บโดยใช้ Python เป็นตัวเลือกยอดนิยม เนื่องจาก Python มีไลบรารี่หลายตัว เช่น BeautifulSoup หรือ Scrapy เพื่อดึงข้อมูลอย่างมีประสิทธิภาพ

การมีทักษะในการดึงข้อมูลอย่างมีประสิทธิภาพเป็นสิ่งสำคัญมากในฐานะนักพัฒนาหรือนักวิทยาศาสตร์ข้อมูล บทความนี้จะช่วยให้คุณเข้าใจวิธีการขูดเว็บไซต์อย่างมีประสิทธิภาพและรับเนื้อหาที่จำเป็นเพื่อจัดการตามความต้องการของคุณ สำหรับบทช่วยสอนนี้ เราจะใช้แพ็คเกจ BeautifulSoup เป็นแพ็คเกจที่ทันสมัยสำหรับการคัดลอกข้อมูลใน Python
เหตุใดจึงต้องใช้ Python สำหรับการขูดเว็บ
Python เป็นตัวเลือกแรกสำหรับนักพัฒนาจำนวนมากเมื่อสร้างเว็บสแครปเปอร์ มีเหตุผลหลายประการที่ Python เป็นตัวเลือกแรก แต่สำหรับบทความนี้ เราจะมาพูดถึงเหตุผลหลัก 3 ประการว่าทำไม Python ถึงใช้สำหรับการขูดข้อมูล
การสนับสนุนห้องสมุดและชุมชน: มีห้องสมุดที่ยอดเยี่ยมหลายแห่ง เช่น BeautifulSoup, Scrapy, Selenium เป็นต้น ซึ่งมีฟังก์ชันที่ยอดเยี่ยมสำหรับการคัดลอกหน้าเว็บอย่างมีประสิทธิภาพ มันได้สร้างระบบนิเวศที่ยอดเยี่ยมสำหรับการขูดเว็บ และเนื่องจากนักพัฒนาจำนวนมากทั่วโลกใช้ Python อยู่แล้ว คุณจึงสามารถขอความช่วยเหลือได้อย่างรวดเร็วเมื่อคุณติดขัด
ระบบอัตโนมัติ: Python มีชื่อเสียงในด้านความสามารถในการทำงานอัตโนมัติ จำเป็นต้องมีมากกว่าการขูดเว็บหากคุณพยายามสร้างเครื่องมือที่ซับซ้อนซึ่งต้องอาศัยการขูด ตัวอย่างเช่น หากคุณต้องการสร้างเครื่องมือที่ติดตามราคาของสินค้าในร้านค้าออนไลน์ คุณจะต้องเพิ่มความสามารถการทำงานอัตโนมัติบางอย่างเพื่อให้สามารถติดตามอัตรารายวันและเพิ่มลงในฐานข้อมูลของคุณได้ Python ช่วยให้คุณสามารถทำให้กระบวนการดังกล่าวเป็นไปโดยอัตโนมัติได้อย่างง่ายดาย
การแสดงข้อมูล: การ ขูดเว็บถูกใช้อย่างมากโดยนักวิทยาศาสตร์ข้อมูล นักวิทยาศาสตร์ข้อมูลมักจะต้องดึงข้อมูลจากหน้าเว็บ ด้วยไลบรารีเช่น Pandas ทำให้ Python ทำให้การแสดงข้อมูลง่ายขึ้นจากข้อมูลดิบ
ไลบรารีสำหรับการขูดเว็บใน Python
มีไลบรารีมากมายใน Python เพื่อให้การขูดเว็บง่ายขึ้น เรามาพูดถึงห้องสมุดยอดนิยมสามแห่งที่นี่
#1. ซุปที่สวยงาม
หนึ่งในไลบรารียอดนิยมสำหรับการขูดเว็บ BeautifulSoup ช่วยนักพัฒนาในการขูดหน้าเว็บมาตั้งแต่ปี 2547 โดยมีวิธีการง่ายๆ ในการนำทาง ค้นหา และแก้ไขแผนผังการวิเคราะห์ Beautifulsoup เองยังเข้ารหัสข้อมูลขาเข้าและขาออกอีกด้วย ได้รับการดูแลเป็นอย่างดีและมีชุมชนที่ยอดเยี่ยม
#2. กระท่อนกระแท่น
อีกเฟรมเวิร์กยอดนิยมสำหรับการดึงข้อมูล Scrapy มีดาวมากกว่า 43,000 ดวงบน GitHub นอกจากนี้ยังสามารถใช้เพื่อขูดข้อมูลจาก API นอกจากนี้ยังมีการสนับสนุนในตัวที่น่าสนใจเช่นการส่งอีเมล
#3. ซีลีเนียม
ซีลีเนียมไม่ใช่ห้องสมุดขูดเว็บเป็นหลัก แต่เป็นแพ็คเกจการทำงานอัตโนมัติของเบราว์เซอร์แทน แต่เราสามารถขยายฟังก์ชันการทำงานสำหรับการขูดหน้าเว็บได้อย่างง่ายดาย ใช้โปรโตคอล WebDriver เพื่อควบคุมเบราว์เซอร์ต่างๆ ซีลีเนียมอยู่ในตลาดมาเกือบ 20 ปีแล้ว แต่เมื่อใช้ Selenium คุณสามารถทำให้ข้อมูลอัตโนมัติและขูดข้อมูลจากหน้าเว็บได้อย่างง่ายดาย
ความท้าทายกับ Python Web Scraping
หนึ่งอาจเผชิญกับความท้าทายมากมายเมื่อพยายามขูดข้อมูลจากเว็บไซต์ มีปัญหาต่างๆ เช่น เครือข่ายช้า เครื่องมือป้องกันการขูด การบล็อกตาม IP การบล็อก captcha ฯลฯ ปัญหาเหล่านี้อาจทำให้เกิดปัญหาใหญ่เมื่อพยายามขูดเว็บไซต์
แต่คุณสามารถหลีกเลี่ยงความท้าทายได้อย่างมีประสิทธิภาพโดยทำตามวิธีต่างๆ ตัวอย่างเช่น ในกรณีส่วนใหญ่ ที่อยู่ IP จะถูกบล็อกโดยเว็บไซต์เมื่อมีการร้องขอมากกว่าจำนวนที่กำหนดในช่วงเวลาหนึ่งๆ เพื่อหลีกเลี่ยงการปิดกั้น IP คุณจะต้องเขียนโค้ดมีดโกนเพื่อให้เครื่องเย็นลงหลังจากส่งคำขอ

นักพัฒนามักจะวางกับดัก honeypot สำหรับเครื่องขูด กับดักเหล่านี้มักจะมองไม่เห็นด้วยตาเปล่า แต่สามารถคลานได้ด้วยมีดโกน หากคุณกำลังขูดเว็บไซต์ที่วางกับดักน้ำผึ้ง คุณจะต้องเขียนโค้ดมีดโกนของคุณตามนั้น
แคปต์ชาเป็นอีกหนึ่งปัญหาที่รุนแรงเกี่ยวกับเครื่องขูด ปัจจุบันเว็บไซต์ส่วนใหญ่ใช้ captcha เพื่อป้องกันการเข้าถึงหน้าของบอท ในกรณีเช่นนี้ คุณอาจต้องใช้ตัวแก้ไขแคปต์ชา
การขูดเว็บไซต์ด้วย Python
อย่างที่เราคุยกัน เราจะใช้ BeautifulSoup เพื่อทิ้งเว็บไซต์ ในบทช่วยสอนนี้ เราจะคัดลอกข้อมูลประวัติของ Ethereum จาก Coingecko และบันทึกข้อมูลตารางเป็นไฟล์ JSON เรามาสร้างมีดโกนกันต่อ
ขั้นตอนแรกคือการติดตั้ง BeautifulSoup และคำขอ สำหรับบทช่วยสอนนี้ ฉันจะใช้ Pipenv Pipenv เป็นผู้จัดการสภาพแวดล้อมเสมือนสำหรับ Python คุณสามารถใช้ Venv ได้หากต้องการ แต่ฉันชอบ Pipenv มากกว่า การสนทนาเกี่ยวกับ Pipenv อยู่นอกเหนือขอบเขตของบทช่วยสอนนี้ แต่ถ้าคุณต้องการเรียนรู้วิธีใช้ Pipenv ให้ทำตามคำแนะนำนี้ หรือถ้าคุณต้องการเข้าใจสภาพแวดล้อมเสมือนของ Python ให้ทำตามคำแนะนำนี้
เปิดใช้เชลล์ Pipenv ในไดเร็กทอรีโครงการของคุณโดยเรียกใช้คำสั่ง pipenv shell มันจะเปิดตัว subshell ในสภาพแวดล้อมเสมือนของคุณ ตอนนี้เพื่อติดตั้ง BeautifulSoup ให้รันคำสั่งต่อไปนี้:
pipenv install beautifulsoup4และสำหรับการร้องขอการติดตั้ง ให้รันคำสั่งที่คล้ายกับด้านบน:
pipenv install requests เมื่อการติดตั้งเสร็จสิ้น ให้อิมพอร์ตแพ็คเกจที่จำเป็นลงในไฟล์หลัก สร้างไฟล์ชื่อ main.py และนำเข้าแพ็คเกจดังต่อไปนี้:
from bs4 import BeautifulSoup import requests import jsonขั้นตอนต่อไปคือการรับเนื้อหาของหน้าข้อมูลประวัติและแยกวิเคราะห์โดยใช้ตัวแยกวิเคราะห์ HTML ที่มีอยู่ใน BeautifulSoup
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel') soup = BeautifulSoup(r.content, 'html.parser') ในโค้ดด้านบน เพจสามารถเข้าถึงได้โดยใช้เมธอด get ที่มีอยู่ในไลบรารีคำขอ จากนั้นเนื้อหาที่แยกวิเคราะห์จะถูกเก็บไว้ในตัวแปรที่เรียกว่า soup

ส่วนการขูดต้นฉบับเริ่มต้นขึ้นแล้ว ก่อนอื่น คุณจะต้องระบุตารางให้ถูกต้องใน DOM หากคุณเปิดหน้านี้และตรวจสอบโดยใช้เครื่องมือสำหรับนักพัฒนาที่มีในเบราว์เซอร์ คุณจะเห็นว่าตารางมีคลาสเหล่านี้ table table-striped text-sm text-lg-normal
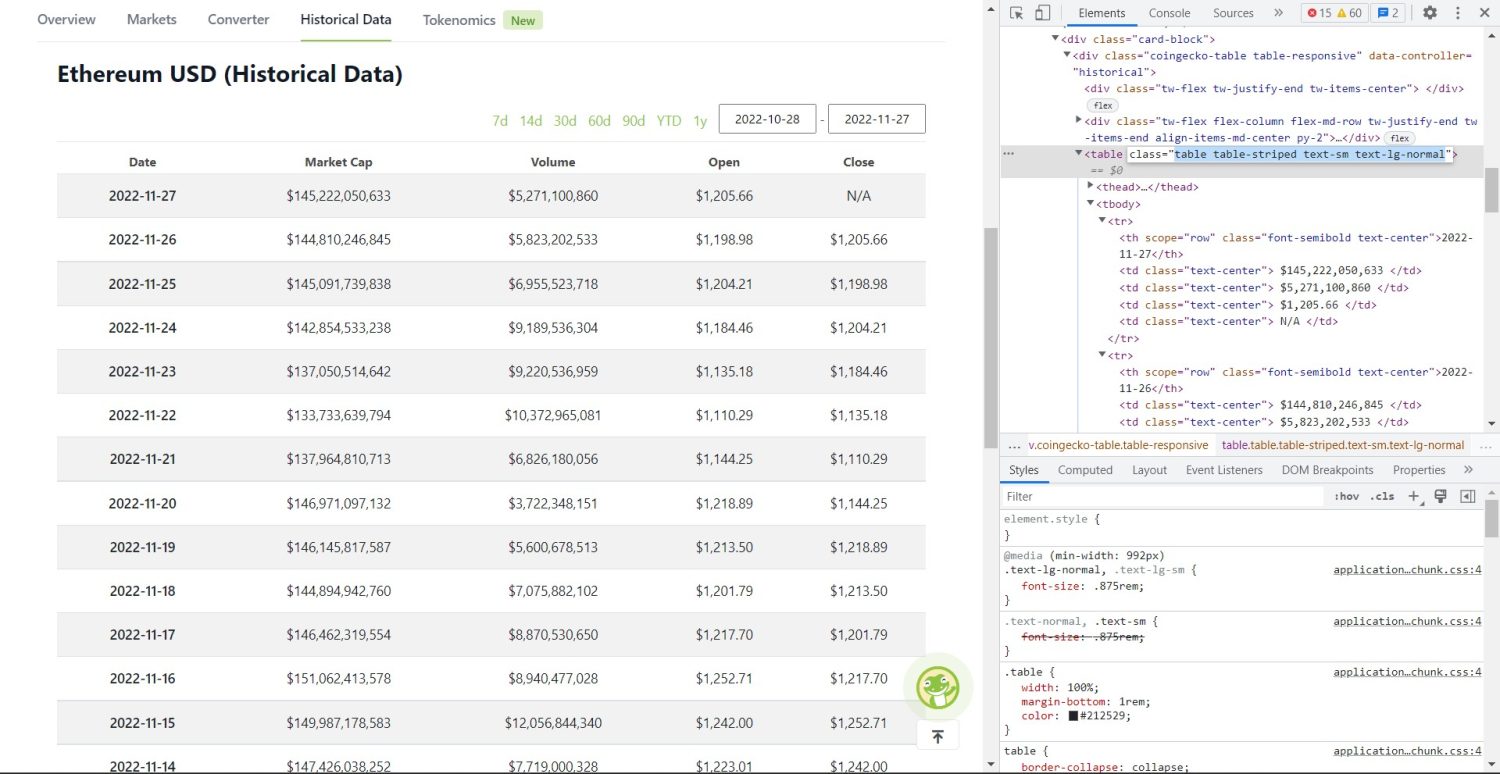
หากต้องการกำหนดเป้าหมายตารางนี้อย่างถูกต้อง คุณสามารถใช้วิธี find
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'}) table_data = table.find_all('tr') table_headings = [] for th in table_data[0].find_all('th'): table_headings.append(th.text) ในโค้ดข้างต้น ขั้นแรก ค้นหาตารางโดยใช้เมธอด soup.find จากนั้นใช้เมธอด find_all ค้นหาองค์ประกอบ tr ทั้งหมดภายในตาราง องค์ประกอบ tr เหล่านี้ถูกเก็บไว้ในตัวแปรชื่อ table_data ตารางมีองค์ประกอบ th เล็กน้อยสำหรับชื่อเรื่อง ตัวแปรใหม่ที่ชื่อว่า table_headings ถูกเตรียมใช้งานเพื่อเก็บหัวเรื่องไว้ในรายการ
จากนั้น a for loop จะถูกเรียกใช้สำหรับแถวแรกของตาราง ในแถวนี้ องค์ประกอบทั้งหมดที่มี th จะถูกค้นหา และเพิ่มค่าข้อความลงในรายการ table_headings ข้อความถูกดึงออกมาโดยใช้เมธอด text หากคุณพิมพ์ตัวแปร table_headings ตอนนี้ คุณจะเห็นผลลัพธ์ต่อไปนี้:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']ขั้นตอนต่อไปคือการขูดองค์ประกอบที่เหลือ สร้างพจนานุกรมสำหรับแต่ละแถว แล้วผนวกแถวลงในรายการ
for tr in table_data: th = tr.find_all('th') td = tr.find_all('td') data = {} for i in range(len(td)): data.update({table_headings[0]: th[0].text}) data.update({table_headings[i+1]: td[i].text.replace('\n', '')}) if data.__len__() > 0: table_details.append(data) นี่เป็นส่วนสำคัญของรหัส สำหรับแต่ละ tr ในตัวแปร table_data อันดับแรก องค์ประกอบ th จะถูกค้นหา องค์ประกอบที่ th คือวันที่ที่แสดงในตาราง องค์ประกอบ th เหล่านี้ถูกเก็บไว้ภายในตัวแปร th ในทำนองเดียวกัน องค์ประกอบ td ทั้งหมดจะถูกเก็บไว้ในตัวแปร td
data พจนานุกรมที่ว่างเปล่าถูกเตรียมใช้งาน หลังจากการเริ่มต้น เราจะวนซ้ำช่วงขององค์ประกอบ td สำหรับแต่ละแถว อันดับแรก เราจะอัปเดตฟิลด์แรกของพจนานุกรมด้วยรายการแรกของ th โค้ด table_headings[0]: th[0].text th คู่คีย์-ค่าของวันที่และองค์ประกอบที่ 1 ตัวแรก
หลังจากเริ่มต้นองค์ประกอบแรก องค์ประกอบอื่นๆ จะถูกกำหนดโดยใช้ data.update({table_headings[i+1]: td[i].text.replace('\\n', '')}) ที่นี่ ข้อความองค์ประกอบ td จะถูกดึงออกมาก่อนโดยใช้เมธอด text จากนั้น \\n ทั้งหมดจะถูกแทนที่โดยใช้เมธอด replace ค่านี้ถูกกำหนดให้กับอิลิเมนต์ i+1 ของรายการ table_headings เนื่องจากอิลิเมนต์ i นั้นถูกกำหนดไว้แล้ว
จากนั้น หากความยาวของพจนานุกรม data เกินศูนย์ เราจะผนวกพจนานุกรมนั้นเข้ากับรายการ table_details คุณสามารถพิมพ์รายการ table_details เพื่อตรวจสอบได้ แต่เราจะเขียนค่าเป็นไฟล์ JSON ลองมาดูรหัสสำหรับสิ่งนี้
with open('table.json', 'w') as f: json.dump(table_details, f, indent=2) print('Data saved to json file...') เราใช้เมธอด json.dump ที่นี่เพื่อเขียนค่าลงในไฟล์ JSON ชื่อ table.json เมื่อเขียนเสร็จแล้ว เราก็พิมพ์ Data saved to json file... ลงใน Console
ตอนนี้ให้เรียกใช้ไฟล์โดยใช้คำสั่งต่อไปนี้
python run main.pyหลังจากนั้นสักครู่ คุณจะเห็นข้อความที่บันทึกลงในไฟล์ JSON… ในคอนโซล คุณจะเห็นไฟล์ใหม่ชื่อ table.json ในไดเร็กทอรีไฟล์ที่ใช้งานได้ ไฟล์จะมีลักษณะคล้ายกับไฟล์ JSON ต่อไปนี้:
[ { "Date": "2022-11-27", "Market Cap": "$145,222,050,633", "Volume": "$5,271,100,860", "Open": "$1,205.66", "Close": "N/A" }, { "Date": "2022-11-26", "Market Cap": "$144,810,246,845", "Volume": "$5,823,202,533", "Open": "$1,198.98", "Close": "$1,205.66" }, { "Date": "2022-11-25", "Market Cap": "$145,091,739,838", "Volume": "$6,955,523,718", "Open": "$1,204.21", "Close": "$1,198.98" }, // ... // ... ]คุณติดตั้งโปรแกรมขูดเว็บโดยใช้ Python สำเร็จแล้ว หากต้องการดูรหัสที่สมบูรณ์ คุณสามารถไปที่ repo GitHub นี้
บทสรุป
บทความนี้กล่าวถึงวิธีการใช้ Python Scrape อย่างง่าย เราได้พูดคุยกันถึงวิธีการใช้ BeautifulSoup ในการดึงข้อมูลอย่างรวดเร็วจากเว็บไซต์ นอกจากนี้ เรายังกล่าวถึงไลบรารี่อื่น ๆ ที่มีอยู่ และเหตุใด Python จึงเป็นตัวเลือกแรกสำหรับนักพัฒนาจำนวนมากสำหรับการคัดลอกเว็บไซต์
คุณอาจดูที่กรอบการขูดเว็บเหล่านี้