
Scraping Web utilizzando Python: guida passo passo
Pubblicato: 2022-11-28Il web scraping è l'idea di estrarre informazioni da un sito Web e utilizzarle per un particolare caso d'uso.
Supponiamo che tu stia tentando di estrarre una tabella da una pagina Web, convertirla in un file JSON e utilizzare il file JSON per creare alcuni strumenti interni. Con l'aiuto del web scraping, puoi estrarre i dati che desideri prendendo di mira gli elementi specifici in una pagina web. Il web scraping con Python è una scelta molto popolare poiché Python fornisce più librerie come BeautifulSoup o Scrapy per estrarre i dati in modo efficace.

Avere l'abilità di estrarre i dati in modo efficiente è anche molto importante come sviluppatore o data scientist. Questo articolo ti aiuterà a capire come raschiare un sito Web in modo efficace e ottenere il contenuto necessario per manipolarlo in base alle tue esigenze. Per questo tutorial, useremo il pacchetto BeautifulSoup. È un pacchetto alla moda per lo scraping dei dati in Python.
Perché usare Python per il web scraping?
Python è la prima scelta per molti sviluppatori durante la creazione di web scraper. Ci sono molte ragioni per cui Python è la prima scelta, ma per questo articolo, discutiamo tre motivi principali per cui Python viene utilizzato per lo scraping dei dati.
Libreria e supporto della comunità: ci sono diverse fantastiche librerie, come BeautifulSoup, Scrapy, Selenium, ecc., che forniscono ottime funzioni per raschiare efficacemente le pagine web. Ha creato un eccellente ecosistema per il web scraping e anche perché molti sviluppatori in tutto il mondo usano già Python, puoi ottenere rapidamente aiuto quando sei bloccato.
Automazione: Python è famoso per le sue capacità di automazione. È necessario qualcosa di più del web scraping se stai cercando di creare uno strumento complesso che si basi sullo scraping. Ad esempio, se desideri creare uno strumento che tenga traccia del prezzo degli articoli in un negozio online, dovrai aggiungere alcune funzionalità di automazione in modo che possa tenere traccia delle tariffe quotidianamente e aggiungerle al tuo database. Python ti dà la possibilità di automatizzare tali processi con facilità.
Visualizzazione dei dati: il web scraping è ampiamente utilizzato dai data scientist. I data scientist hanno spesso bisogno di estrarre dati dalle pagine web. Con librerie come Pandas, Python semplifica la visualizzazione dei dati dai dati grezzi.
Librerie per il web scraping in Python
Ci sono diverse librerie disponibili in Python per semplificare il web scraping. Discutiamo le tre librerie più popolari qui.
#1. Zuppa Bella
Una delle librerie più popolari per il web scraping. BeautifulSoup aiuta gli sviluppatori a raschiare le pagine Web dal 2004. Fornisce metodi semplici per navigare, cercare e modificare l'albero di analisi. Beautifulsoup stesso esegue anche la codifica dei dati in entrata e in uscita. È ben tenuto e ha una grande comunità.
#2. Raschiante
Un altro framework popolare per l'estrazione dei dati. Scrapy ha più di 43000 stelle su GitHub. Può anche essere utilizzato per raccogliere dati dalle API. Ha anche alcuni interessanti supporti integrati, come l'invio di e-mail.
#3. Selenio
Selenium non è principalmente una libreria di web scraping. Invece, è un pacchetto di automazione del browser. Ma possiamo facilmente estendere le sue funzionalità per lo scraping di pagine web. Utilizza il protocollo WebDriver per controllare diversi browser. Il selenio è sul mercato da quasi 20 anni. Ma usando Selenium, puoi facilmente automatizzare e raschiare i dati dalle pagine web.
Sfide con Python Web Scraping
Si possono affrontare molte sfide quando si tenta di estrarre dati dai siti Web. Ci sono problemi come reti lente, strumenti anti-scraping, blocco basato su IP, blocco captcha, ecc. Questi problemi possono causare enormi problemi quando si tenta di eseguire lo scraping di un sito Web.
Ma puoi aggirare efficacemente le sfide seguendo alcuni modi. Ad esempio, nella maggior parte dei casi, un indirizzo IP viene bloccato da un sito web quando c'è più di un certo numero di richieste inviate in uno specifico intervallo di tempo. Per evitare il blocco dell'IP, dovrai codificare il tuo scraper in modo che si raffreddi dopo l'invio delle richieste.

Gli sviluppatori tendono anche a mettere trappole honeypot per raschietti. Queste trappole sono generalmente invisibili agli occhi umani nudi, ma possono essere strisciate da un raschietto. Se stai eseguendo lo scraping di un sito Web che mette una trappola del genere, dovrai codificare il tuo scraper di conseguenza.
Captcha è un altro grave problema con gli scraper. La maggior parte dei siti Web al giorno d'oggi utilizza un captcha per proteggere l'accesso dei bot alle proprie pagine. In tal caso, potrebbe essere necessario utilizzare un risolutore di captcha.
Scraping di un sito Web con Python
Come abbiamo discusso, useremo BeautifulSoup per demolire un sito web. In questo tutorial, estrarremo i dati storici di Ethereum da Coingecko e salveremo i dati della tabella come file JSON. Passiamo alla costruzione del raschietto.
Il primo passo è installare BeautifulSoup e Requests. Per questo tutorial, userò Pipenv. Pipenv è un gestore di ambienti virtuali per Python. Puoi anche usare Venv se vuoi, ma preferisco Pipenv. La discussione su Pipenv va oltre lo scopo di questo tutorial. Ma se vuoi sapere come utilizzare Pipenv, segui questa guida. Oppure, se vuoi capire gli ambienti virtuali Python, segui questa guida.
Avvia la shell Pipenv nella directory del tuo progetto eseguendo il comando pipenv shell . Lancerà una subshell nel tuo ambiente virtuale. Ora, per installare BeautifulSoup, esegui il seguente comando:
pipenv install beautifulsoup4E, per installare le richieste, eseguire il comando simile al precedente:
pipenv install requests Una volta completata l'installazione, importare i pacchetti necessari nel file principale. Crea un file chiamato main.py e importa i pacchetti come il seguente:
from bs4 import BeautifulSoup import requests import jsonIl passaggio successivo consiste nell'ottenere i contenuti della pagina dei dati storici e analizzarli utilizzando il parser HTML disponibile in BeautifulSoup.

r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel') soup = BeautifulSoup(r.content, 'html.parser') Nel codice precedente, si accede alla pagina utilizzando il metodo get disponibile nella libreria delle richieste. Il contenuto analizzato viene quindi archiviato in una variabile chiamata soup .
La parte di raschiatura originale inizia ora. Innanzitutto, dovrai identificare correttamente la tabella nel DOM. Se apri questa pagina e la controlli usando gli strumenti per sviluppatori disponibili nel browser, vedrai che la tabella ha queste classi table table-striped text-sm text-lg-normal .
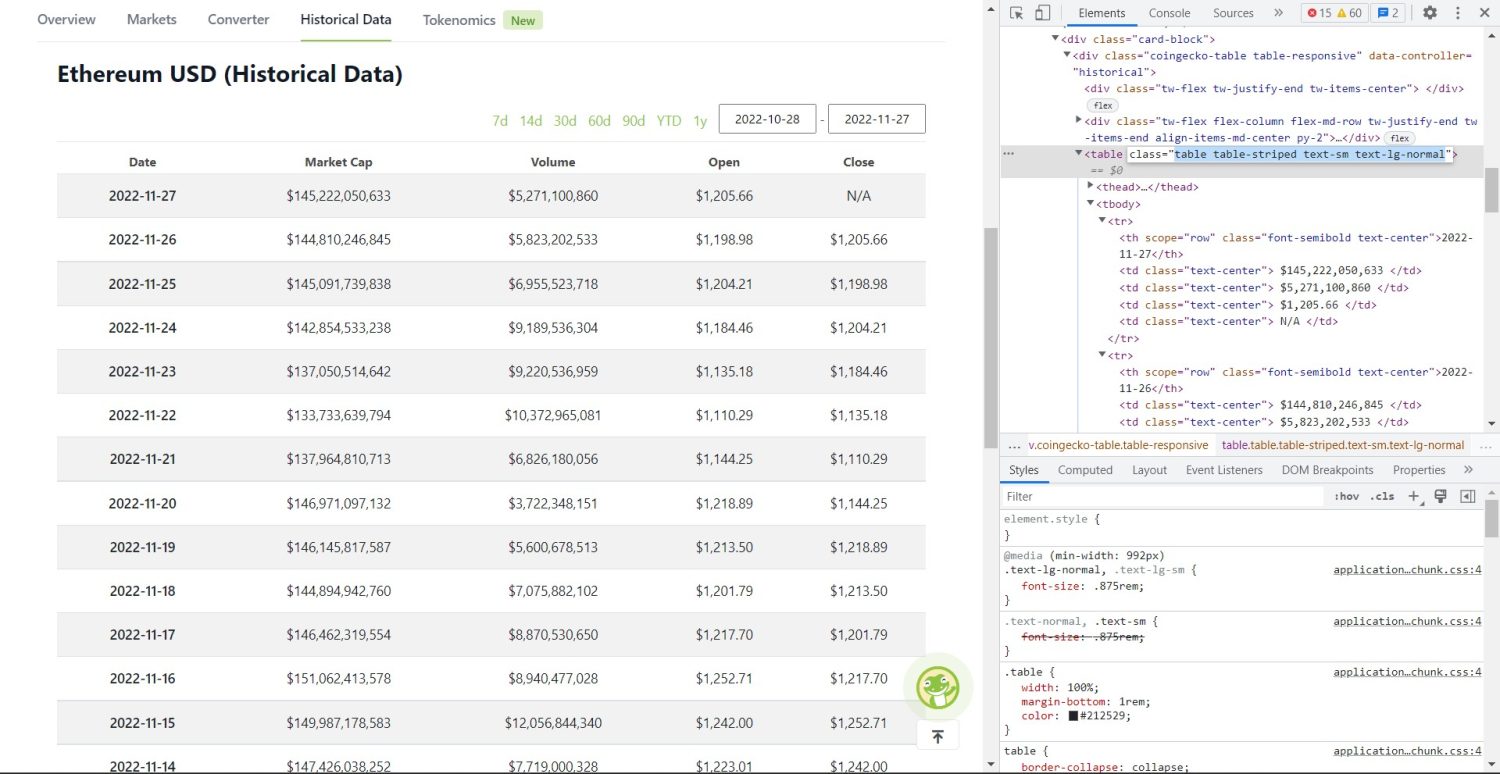
Per indirizzare correttamente questa tabella, puoi utilizzare il metodo find .
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'}) table_data = table.find_all('tr') table_headings = [] for th in table_data[0].find_all('th'): table_headings.append(th.text) Nel codice precedente, per prima cosa, la tabella viene trovata utilizzando il metodo soup.find , quindi utilizzando il metodo find_all , vengono cercati tutti gli elementi tr all'interno della tabella. Questi elementi tr sono memorizzati in una variabile chiamata table_data . La tabella ha pochi th per il titolo. Viene inizializzata una nuova variabile chiamata table_headings per mantenere i titoli in un elenco.
Viene quindi eseguito un ciclo for per la prima riga della tabella. In questa riga, vengono cercati tutti gli elementi con th e il loro valore di testo viene aggiunto all'elenco table_headings . Il testo viene estratto utilizzando il metodo del text . Se stampi ora la variabile table_headings , sarai in grado di vedere il seguente output:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']Il passaggio successivo consiste nello raschiare il resto degli elementi, generare un dizionario per ogni riga e quindi aggiungere le righe in un elenco.
for tr in table_data: th = tr.find_all('th') td = tr.find_all('td') data = {} for i in range(len(td)): data.update({table_headings[0]: th[0].text}) data.update({table_headings[i+1]: td[i].text.replace('\n', '')}) if data.__len__() > 0: table_details.append(data) Questa è la parte essenziale del codice. Per ogni tr nella variabile table_data , prima vengono cercati gli elementi th . Gli elementi th sono la data mostrata nella tabella. Questi th elementi sono memorizzati all'interno di una variabile th . Allo stesso modo, tutti gli elementi td sono memorizzati nella variabile td .
Vengono inizializzati i data un dizionario vuoto. Dopo l'inizializzazione, eseguiamo un ciclo attraverso l'intervallo di elementi td . Per ogni riga, per prima cosa, aggiorniamo il primo campo del dizionario con il primo elemento di th . Il codice table_headings[0]: th[0].text assegna una coppia chiave-valore data e il primo elemento th .
Dopo aver inizializzato il primo elemento, gli altri elementi vengono assegnati utilizzando data.update({table_headings[i+1]: td[i].text.replace('\\n', '')}) . Qui, il testo degli elementi td viene prima estratto utilizzando il metodo text , quindi tutto \\n viene sostituito utilizzando il metodo replace . Il valore viene quindi assegnato i+1 ° elemento dell'elenco table_headings perché l' i ° elemento è già assegnato.
Quindi, se la lunghezza del dizionario dei data supera lo zero, aggiungiamo il dizionario all'elenco table_details . È possibile stampare l'elenco table_details da controllare. Ma scriveremo i valori in un file JSON. Diamo un'occhiata al codice per questo,
with open('table.json', 'w') as f: json.dump(table_details, f, indent=2) print('Data saved to json file...') Stiamo usando il metodo json.dump qui per scrivere i valori in un file JSON chiamato table.json . Una volta completata la scrittura, stampiamo i Data saved to json file... nella console.
Ora, esegui il file usando il seguente comando,
python run main.pyDopo qualche tempo, sarai in grado di vedere i dati salvati nel file JSON... testo nella console. Vedrai anche un nuovo file chiamato table.json nella directory dei file di lavoro. Il file sarà simile al seguente file JSON:
[ { "Date": "2022-11-27", "Market Cap": "$145,222,050,633", "Volume": "$5,271,100,860", "Open": "$1,205.66", "Close": "N/A" }, { "Date": "2022-11-26", "Market Cap": "$144,810,246,845", "Volume": "$5,823,202,533", "Open": "$1,198.98", "Close": "$1,205.66" }, { "Date": "2022-11-25", "Market Cap": "$145,091,739,838", "Volume": "$6,955,523,718", "Open": "$1,204.21", "Close": "$1,198.98" }, // ... // ... ]Hai implementato con successo un web scraper utilizzando Python. Per visualizzare il codice completo, puoi visitare questo repository GitHub.
Conclusione
Questo articolo ha discusso di come implementare un semplice scrape Python. Abbiamo discusso di come BeautifulSoup potrebbe essere utilizzato per raschiare rapidamente i dati dal sito web. Abbiamo anche discusso di altre librerie disponibili e del motivo per cui Python è la prima scelta per molti sviluppatori per lo scraping di siti Web.
Puoi anche guardare questi framework di web scraping.