
LinkedIn 的停留時間解釋
已發表: 2020-07-23LinkedIn 的 Dwell Time有點像青春期前青少年之間的性討論:每個人都在談論它,但沒有人真正知道它是什麼。
是時候澄清一下了。 並告訴你它的真正含義!

到目前為止該算法是如何工作的?
在談論“停留時間”之前,有必要先談談算法的工作原理。 我已經寫了一篇關於這個主題的詳細文章,但這裡是一個總結。
每天都有成千上萬的人在 LinkedIn 上發帖。
每天在 LinkedIn 上都會看到數百萬條帖子。
將兩者聯繫起來:一種算法將決定誰應該看到誰的帖子。
由於 Linkedin 從廣告中賺錢,並且每 5 個帖子顯示一次,因此有必要滾動盡可能多的帖子以使用戶產生最大收入。
這意味著顯示最有趣的帖子。
但由於該算法不夠智能,無法理解帖子的內容並確定它是否“有趣”,因此它將基於用戶與帖子的互動(以及其他標準,如外部鏈接、視頻、圖像等……可能會影響覆蓋範圍)。
到目前為止,該算法研究的交互與參與度相對應:收到的點贊數和帖子生命週期開始時發表的評論數。 評論的權重遠高於點贊。
然後是停留時間……
為什麼停留時間?
停留時間有兩個主要原因。 第一個是最重要的官方版本。
第二個是次要的和非官方的。
您應該知道,在社交網絡上,我們觀察到以下分佈:
- 1% 的用戶發布,
- 10% 的用戶參與(點贊或評論),
- 90% 的用戶在沒有交互的情況下消費內容。
因此,LinkedIn 提出了一個問題:如何考慮 90% 不互動的人的意見? 我們如何獲得 90% 的行為來幫助我們確定帖子的質量?

另一方面,參與行動是二元的。 這帶來了兩個問題:
- 它們不是線性的。 1贊抵1贊,1評論抵1評論。 但是,我會為讓我微笑的內容或我一生中讀過的最好的帖子點贊。 ️
- 它們很容易偽造:我可以讓我認識的人發佈點贊或評論,或者使用廣告連播來人為地提高我的內容的覆蓋面。
這第二點對應於非官方原因:限制 pod 的影響。
因此,通過 LinkedIn 工程師所謂的“病毒式傳播”來衡量帖子的質量並因此定義其有機覆蓋面是一種過於粗略的近似。
他們還解釋說,點擊鏈接或“查看更多”帖子可能會產生誤導,因為用戶可能會立即離開打開的頁面或不閱讀帖子的其餘部分。
同樣,分享等指標也不是很可靠,因為無法客觀地分析與分享相關的評論。 分享是為了譴責某人還是突出優質內容?
是時候找到其他指標並在所有這些中加入一點人工智能了。

停留時間 = 花在帖子上的時間?
你可能不是偶然出現在這篇文章中的。 對您來說,停留時間當然是“花在崗位上的時間”的代名詞。

這是一個幾乎正確的近似值。 讓我解釋。
為了給不互動的用戶行為賦予權重,得到一個更可靠的線性指標,LinkedIn 的工程師試圖研究另一種互動:發帖所花費的時間。
事實上,他們測量了我們在帖子上花費的時間越多,發表評論或類似內容的可能性就越高。
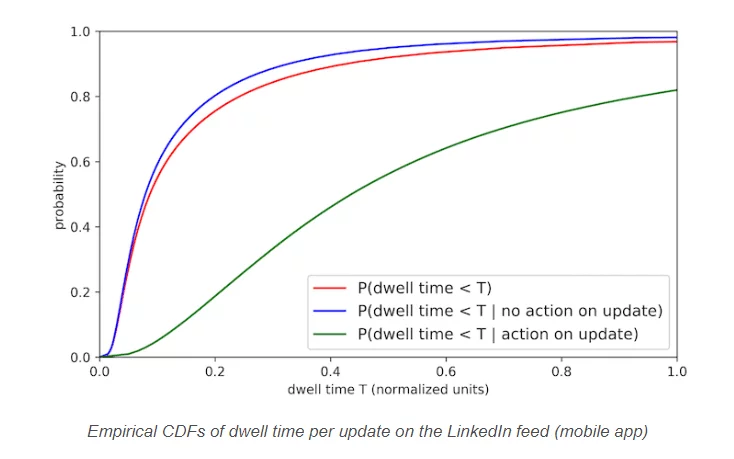
思路是:
“由於我花在帖子上的時間越多,我參與該帖子的可能性就越高,而參與是對內容感興趣的主要標誌,可以說我花在帖子上的時間越多,更多我感興趣。
(這是一個非常基本和合乎邏輯的推理,但在所有這些背後都有漂亮的算法和可怕的數學函數)。
工程師們把花在崗位上的時間分為兩部分:
- 當我們滾動 LinkedIn 新聞提要時,從一半帖子可見的那一刻起
- 點擊“查看更多”後的那個
因此,花在帖子上的時間會對算法產生積極或消極的影響,從而影響發布的範圍。
這一切的背後是什麼?
這篇文章的想法是簡化由 LinkedIn 的工程團隊製作的文章。 所以我不會向你展示它背後的所有數學公式。
但了解停留時間背後的內容仍然很有趣,因為它比簡單的“花在帖子上的時間”更複雜。

在他們的文章中,工程師們展示了一個他們研究過的具體案例,以將花在帖子上的時間整合到算法中。 這表明這不是唯一起作用的模型。
因此,他們整合了“帖子在沒有被閱讀的情況下通過的概率”。 這是一個相當短的時間段,低於該時間段參與帖子的可能性接近於零。
換句話說,這段時間對應於我的大腦定義我是否會對帖子感興趣的必要時間。 如果我少呆在這段時間裡,我就沒有機會從事這個職位。
因此,他們整合了“跳過帖子”的概念,這也會影響算法。
請注意,這段時間在不同類型的帖子(視頻、圖像、文章、pdf 文件……)上幾乎相同,這有助於該指標的建模和使用。
這個造型在帖子外觀上的使用
應該理解,LinkedIn 不會在“這篇文章值得被看到嗎?”方面工作。 但是“向該用戶顯示的最相關的帖子是什麼?”
因此,該算法將整合不同的標準,例如用戶資料、帖子的病毒式傳播(喜歡和評論的數量)、用戶與帖子作者的親和力以及其他指標(例如一天中的時間)。
通過結合這些標準,它將確定您閱讀給定帖子的可能性,然後優先考慮最有可能讓您停下來閱讀它們的帖子。
該算法的更新將通過減少“跳過”帖子的數量顯著提高新聞提要的質量,從而增加所提供內容的相關性。
本文是根據 LinkedIn 負責發布算法和 Dwell Time 的工程師團隊撰寫的文章編寫的。 我試圖通過繪製最重要的信息來綜合它,同時根據他們的解釋盡可能清楚。 不幸的是,它是關於該主題的唯一官方 LinkedIn 資源。
該算法的工作方式以及將停留時間準確整合到出版物的範圍內並未完全公開。 該建模集成了複雜的數學函數和機器學習。
所以它比二進制的東西複雜得多。
工程團隊表示,這個算法會不斷更新,完善建議,讓建議更貼切。
面對這些發展,成功的關鍵仍然是內容的質量。 算法越了解用戶對內容的欣賞程度,後者的質量在算法中的優先級就越高。
但是,有一些好的做法可以幫助您利用停留時間。 我很快就會在一篇文章中告訴你。
同時,請隨時在 LinkedIn 上聯繫我討論這篇文章,如果有什麼不清楚的地方請告訴我。