
LinkedIn の滞留時間の説明
公開: 2020-07-23LinkedIn の Dwell Timeは、思春期前の 10 代の若者の間のセックス ディスカッションに少し似ています。
これを少し明確にする時が来ました。 そして、その本当の意味を教えてください!

これまでのところ、アルゴリズムはどのように機能していますか?
「滞留時間」について話す前に、アルゴリズムがどのように機能するかについて話すことが重要です。 この件についてはすでに詳細な記事を書いていますが、ここで要約します。
毎日何千人もの人々が LinkedIn に投稿しています。
LinkedIn では、毎日何百万もの投稿が見られます。
この 2 つを結び付けるには、誰が誰の投稿を表示するかを決定するアルゴリズムが必要です。
Linkedin は広告から収益を得ており、これらは 5 つの投稿ごとに表示されるため、ユーザーが最大の収入を得るには、できるだけ多くの投稿をスクロールする必要があります。
これは、最も興味深い投稿を表示することを意味します。
しかし、アルゴリズムは投稿の内容を理解し、それが「面白い」かどうかを判断するほどスマートではないため、投稿に対するユーザーのインタラクションに基づいて判断されます (外部リンク、ビデオ、リーチに影響を与える可能性のある画像など)。
これまで、アルゴリズムによって調査されたインタラクションはエンゲージメントに対応していました。つまり、受信したいいねの数と、投稿の開始時に公開されたコメントの数です。 いいねよりもはるかに重みのあるコメント。
そしてドウェルタイム…
なぜ滞留時間?
Dwell Time には主に 2 つの理由があります。 1 つ目は、最も重要な公式バージョンです。
2 つ目は二次的で非公式です。
ソーシャルネットワークでは、次の分布が観察されることを知っておく必要があります。
- ユーザーの 1% が公開し、
- ユーザーの 10% がエンゲージメント (いいね! またはコメント)、
- ユーザーの 90% は、インタラクションなしでコンテンツを消費しています。
したがって、LinkedIn は次のように質問しました: 対話しない 90% の意見をどのように考慮に入れるか? 投稿の質を判断するのに役立つ 90% の行動をどのように取得しますか?

一方、エンゲージメントアクションはバイナリです。 これにより、次の 2 つの問題が生じます。
- それらは線形ではありません。 1 いいねは 1 いいねの価値があり、1 コメントは 1 コメントの価値があります。 ただし、私を笑顔にさせたコンテンツや、これまで読んだ中で最高の投稿には同じように「いいね!」を付けます。 ️
- 簡単に偽装できます。知り合いにいいねやコメントを投稿してもらったり、ポッドを使用して人為的にコンテンツのリーチを拡大したりできます。
この 2 番目のポイントは、ポッドの影響を制限するという非公式の理由に対応しています。
したがって、投稿の質を測定し、LinkedIn のエンジニアが「バイラル アクション」と呼ぶものによってオーガニック リーチを定義することは、あまりにも粗雑な概算です。
また、投稿のリンクや「もっと見る」をクリックすると、ユーザーが開いているページをすぐに離れたり、投稿の残りの部分を読まなかったりする可能性があるため、誤解を招く可能性があることも説明しています。
同様に、共有に関連するコメントを客観的に分析することは不可能であるため、共有などの指標はあまり信頼できません。 誰かを非難したり、質の高いコンテンツを強調したりするために共有していますか?
他の指標を見つけて、これらすべてに人工知能を少し投入する時が来ました.

滞在時間 = 投稿に費やされた時間?
あなたはおそらく、偶然この投稿に参加していません。 そしてあなたにとって、滞在時間は確かに「投稿に費やされた時間」と同義です.

これは、ほぼ正しい近似値です。 説明させてください。
リンクトインのエンジニアは、インタラクションを行わないユーザーの行動に重みを付け、より信頼性の高い直線的な指標を得るために、別のタイプのインタラクション、つまり投稿に費やされた時間の調査を試みました。
実際、投稿に費やす時間が長いほど、コメントなどを投稿する可能性が高くなることが測定されました。
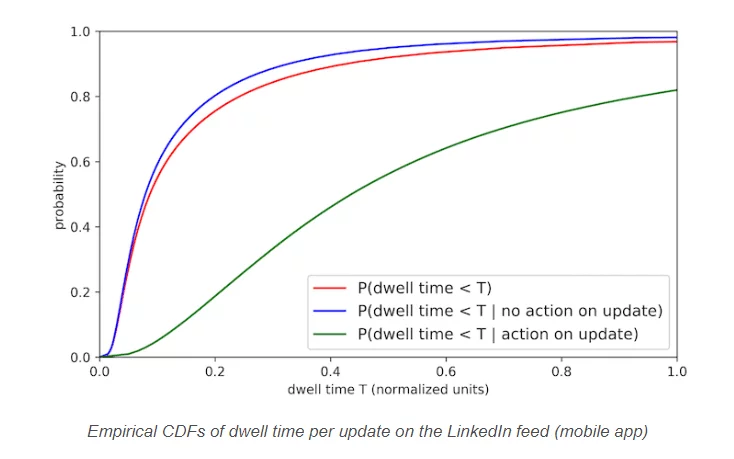
考え方は次のとおりです。
「投稿に費やす時間が長いほど、投稿に関与する可能性が高くなり、エンゲージメントはコンテンツへの関心の主要な兆候であるため、投稿に費やす時間が長いほど、もっと興味があります。」
(これは非常に基本的で論理的な推論ですが、その背後には美しいアルゴリズムと恐ろしい数学関数があります)。
エンジニアは投稿に費やした時間を 2 つの部分に分けました。
- 投稿の半分が表示された瞬間から、LinkedIn ニュース フィードをスクロールしたときのもの
- 「もっと見る」をクリックした後のもの
したがって、投稿に費やされた時間は、アルゴリズムにプラスまたはマイナスの影響を与え、したがって公開の範囲に影響を与えます。
このすべての背後にあるものは何ですか?
この記事のアイデアは、LinkedIn のエンジニアリング チームによって作成されたものを単純化することです。 そのため、その背後にあるすべての数式をお見せするつもりはありません。
しかし、滞留時間は単に「投稿に費やした時間」よりも複雑であるため、滞留時間の背後にあるものを理解することは依然として興味深いことです。

彼らの記事では、エンジニアは投稿に費やされた時間をアルゴリズムに統合するために研究した特定のケースを提示しています。 これは、これが唯一のモデリングではないことを示唆しています。
したがって、「投稿が読まれずに通過する確率」を統合します。 これはかなり短い期間であり、それ以下では投稿でエンゲージメントを行う可能性はゼロに近くなります。
言い換えれば、この期間は、私の脳が投稿に興味があるかどうかを判断するのに必要な期間に対応しています。 この期間が短くなると、そのポストに携わる機会がなくなります。
したがって、アルゴリズムにも影響を与える「スキップされた投稿」の概念を統合します。
この期間は、さまざまな種類の投稿 (ビデオ、画像、記事、PDF ファイルなど) でほぼ同じであることに注意してください。これにより、このインジケーターのモデル化と使用が容易になります。
ポストの外観におけるこのモデリングの使用
LinkedIn は「この投稿は見られるに値するか」という点では機能しないことを理解する必要があります。 しかし、 「このユーザーに表示する最も関連性の高い投稿は何ですか?」
したがって、アルゴリズムは、ユーザー プロファイル、投稿のバイラリティ (いいね! とコメントの数)、ユーザーと投稿の作成者との親和性、および時刻などの他の指標など、さまざまな基準を統合します。
これらの基準を組み合わせることで、特定の投稿を読む確率を決定し、読むのをやめさせる可能性が最も高い投稿に優先順位を付けます。
このアルゴリズムの更新により、「スキップされた」投稿の数が減るため、ニュース フィードの品質が大幅に向上し、提供されるコンテンツの関連性が向上します。
この記事は、公開アルゴリズムと滞留時間を担当する LinkedIn のエンジニア チームによって書かれた記事に基づいて書かれています。 彼らの説明をもとに、最も重要な情報を可能な限り明確にしようとしながら、それを描くことによってそれを合成しようとしました. 残念ながら、このテーマに関する公式の LinkedIn リソースはこれだけです。
アルゴリズムがどのように機能するか、およびドウェルタイムを出版物に正確に統合する方法は、完全には明らかにされていません。 モデリングは、複雑な数学関数と機械学習を統合します。
したがって、バイナリよりもはるかに複雑です。
エンジニアリング チームは、提案を改善し、より関連性の高いものにするために、このアルゴリズムが継続的に更新されると述べました。
これらの開発に直面して、成功への鍵は依然としてコンテンツの品質です。 ユーザーがコンテンツをどれだけ高く評価しているかをアルゴリズムが理解すればするほど、後者の品質がアルゴリズムで優先されます。
ただし、滞留時間を活用するのに役立ついくつかの優れた方法があります。 近いうちに記事でお伝えします。
それまでの間、LinkedIn で遠慮なく私に連絡して、この記事について議論し、不明な点があれば教えてください。