
LinkedIn 的停留时间解释
已发表: 2020-07-23LinkedIn 的 Dwell Time有点像青春期前青少年之间的性讨论:每个人都在谈论它,但没有人真正知道它是什么。
是时候澄清一下了。 并告诉你它的真正含义!

到目前为止该算法是如何工作的?
在谈论“停留时间”之前,有必要先谈谈算法的工作原理。 我已经写了一篇关于这个主题的详细文章,但这里是一个总结。
每天都有成千上万的人在 LinkedIn 上发帖。
每天在 LinkedIn 上都会看到数百万条帖子。
将两者联系起来:一种算法将决定谁应该看到谁的帖子。
由于 Linkedin 从广告中赚钱,并且每 5 个帖子显示一次,因此有必要滚动尽可能多的帖子以使用户产生最大收入。
这意味着显示最有趣的帖子。
但由于该算法不够智能,无法理解帖子的内容并确定它是否“有趣”,因此它将基于用户与帖子的互动(以及其他标准,如外部链接、视频、图像等……可能会影响覆盖范围)。
到目前为止,该算法研究的交互与参与度相对应:收到的点赞数和帖子生命周期开始时发表的评论数。 评论的权重远高于点赞。
然后是停留时间……
为什么停留时间?
停留时间有两个主要原因。 第一个是最重要的官方版本。
第二个是次要的和非官方的。
您应该知道,在社交网络上,我们观察到以下分布:
- 1% 的用户发布,
- 10% 的用户参与(点赞或评论),
- 90% 的用户在没有交互的情况下消费内容。
因此,LinkedIn 提出了一个问题:如何考虑 90% 不互动的人的意见? 我们如何获得 90% 的行为来帮助我们确定帖子的质量?

另一方面,参与行动是二元的。 这带来了两个问题:
- 它们不是线性的。 1赞抵1赞,1评论抵1评论。 但是,我会为让我微笑的内容或我一生中读过的最好的帖子点赞。 ️
- 它们很容易伪造:我可以让我认识的人发布点赞或评论,或者使用广告连播来人为地提高我的内容的覆盖面。
这第二点对应于非官方原因:限制 pod 的影响。
因此,通过 LinkedIn 工程师所谓的“病毒式传播”来衡量帖子的质量并因此定义其有机覆盖面是一种过于粗略的近似。
他们还解释说,点击链接或“查看更多”帖子可能会产生误导,因为用户可能会立即离开打开的页面或不阅读帖子的其余部分。
同样,分享等指标也不是很可靠,因为无法客观地分析与分享相关的评论。 分享是为了谴责某人还是突出优质内容?
是时候找到其他指标并在所有这些中加入一点人工智能了。

停留时间 = 花在帖子上的时间?
你可能不是偶然出现在这篇文章中的。 对您来说,停留时间当然是“花在岗位上的时间”的代名词。

这是一个几乎正确的近似值。 让我解释。
为了给不互动的用户行为赋予权重,得到一个更可靠的线性指标,LinkedIn 的工程师试图研究另一种互动:发帖所花费的时间。
事实上,他们测量了我们在帖子上花费的时间越多,发表评论或类似内容的可能性就越高。
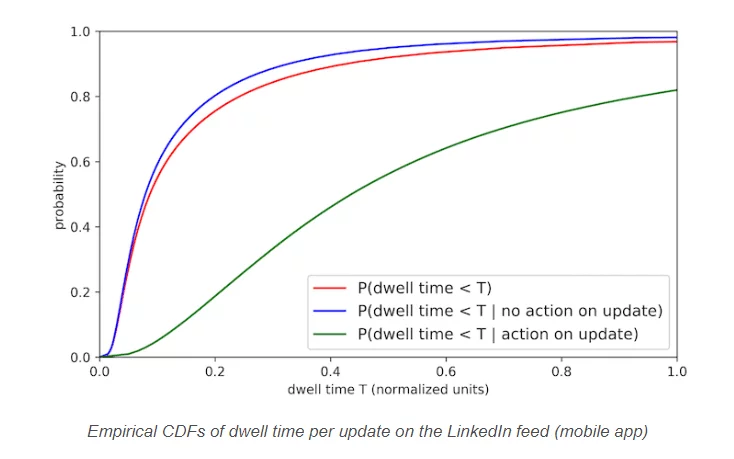
思路是:
“由于我花在帖子上的时间越多,我参与该帖子的可能性就越高,而参与是对内容感兴趣的主要标志,可以说我花在帖子上的时间越多,更多我感兴趣。
(这是一个非常基本和合乎逻辑的推理,但在所有这些背后都有漂亮的算法和可怕的数学函数)。
工程师们把花在岗位上的时间分为两部分:
- 当我们滚动 LinkedIn 新闻提要时,从一半帖子可见的那一刻起
- 点击“查看更多”后的那个
因此,花在帖子上的时间会对算法产生积极或消极的影响,从而影响发布的范围。
这一切的背后是什么?
这篇文章的想法是简化由 LinkedIn 的工程团队制作的文章。 所以我不会向你展示它背后的所有数学公式。
但了解停留时间背后的内容仍然很有趣,因为它比简单的“花在帖子上的时间”更复杂。

在他们的文章中,工程师们展示了一个他们研究过的具体案例,以将花在帖子上的时间整合到算法中。 这表明这不是唯一起作用的模型。
因此,他们整合了“帖子在没有被阅读的情况下通过的概率”。 这是一个相当短的时间段,低于该时间段参与帖子的可能性接近于零。
换句话说,这段时间对应于我的大脑定义我是否会对帖子感兴趣的必要时间。 如果我少呆在这段时间里,我就没有机会从事这个职位。
因此,他们整合了“跳过帖子”的概念,这也会影响算法。
请注意,这段时间在不同类型的帖子(视频、图像、文章、pdf 文件……)上几乎相同,这有助于该指标的建模和使用。
这个造型在帖子外观上的使用
应该理解,LinkedIn 不会在“这篇文章值得被看到吗?”方面工作。 但是“向该用户显示的最相关的帖子是什么?”
因此,该算法将整合不同的标准,例如用户资料、帖子的病毒式传播(喜欢和评论的数量)、用户与帖子作者的亲和力以及其他指标(例如一天中的时间)。
通过结合这些标准,它将确定您阅读给定帖子的可能性,然后优先考虑最有可能让您停下来阅读它们的帖子。
该算法的更新将通过减少“跳过”帖子的数量显着提高新闻提要的质量,从而提高所提供内容的相关性。
本文是根据 LinkedIn 负责发布算法和 Dwell Time 的工程师团队撰写的文章编写的。 我试图通过绘制最重要的信息来综合它,同时根据他们的解释尽可能清楚。 不幸的是,它是关于该主题的唯一官方 LinkedIn 资源。
该算法的工作方式以及将停留时间准确整合到出版物的范围内并未完全公开。 该建模集成了复杂的数学函数和机器学习。
所以它比二进制的东西复杂得多。
工程团队表示,这个算法会不断更新,完善建议,让建议更贴切。
面对这些发展,成功的关键仍然是内容的质量。 算法越了解用户对内容的欣赏程度,后者的质量在算法中的优先级就越高。
但是,有一些好的做法可以帮助您利用停留时间。 我很快就会在一篇文章中告诉你。
同时,请随时在 LinkedIn 上联系我讨论这篇文章,如果有什么不清楚的地方请告诉我。