
如何在 R 中進行探索性數據分析 (EDA)(附示例)
已發表: 2022-11-11了解您需要了解的有關探索性數據分析的所有信息,這是一個用於發現趨勢和模式並藉助統計摘要和圖形表示總結數據集的關鍵過程。
與任何項目一樣,數據科學項目是一個漫長的過程,需要時間、良好的組織以及對幾個步驟的嚴格尊重。 探索性數據分析 (EDA) 是此過程中最重要的步驟之一。
因此,在本文中,我們將簡要介紹什麼是探索性數據分析以及如何使用 R!
什麼是探索性數據分析?
探索性數據分析在將數據集提交給應用程序之前檢查和研究數據集的特徵,無論是專門的業務、統計還是機器學習。

這種對信息性質及其主要特性的總結通常是通過視覺方法完成的,例如圖形表示和表格。 該實踐是提前進行的,以準確評估這些數據的潛力,這些數據將在未來得到更複雜的處理。
因此,EDA 允許:
- 制定使用這些信息的假設;
- 探索數據結構中隱藏的細節;
- 識別缺失值、異常值或異常行為;
- 發現整體趨勢和相關變量;
- 丟棄不相關的變量或與他人相關的變量;
- 確定要使用的正式建模。
描述性數據分析和探索性數據分析有什麼區別?
儘管目標不同,但有兩種類型的數據分析,描述性分析和探索性數據分析,它們是齊頭並進的。
而第一個側重於描述變量的行為,例如均值、中位數、眾數等。
探索性分析旨在識別變量之間的關係,提取初步見解並將建模引導到最常見的機器學習範式:分類、回歸和聚類。
通常,兩者都可以處理圖形表示; 然而,只有探索性分析才尋求帶來可操作的見解,即激發決策者採取行動的見解。
最後,雖然探索性數據分析旨在解決問題並帶來指導建模步驟的解決方案,但描述性分析,顧名思義,僅旨在對相關數據集進行詳細描述。
| 描述性分析 | 探索性數據分析 |
| 分析行為 | 分析行為和關係 |
| 提供摘要 | 導致規範和行動 |
| 以表格和圖表的形式組織數據 | 以表格和圖表的形式組織數據 |
| 沒有顯著的解釋力 | 是否具有顯著的解釋力 |
EDA的一些實際用例
#1。 數字營銷
數字營銷已經從一個創造性的過程演變為一個數據驅動的過程。 營銷組織使用探索性數據分析來確定活動或努力的結果,並指導消費者投資和目標決策。
人口統計研究、客戶細分和其他技術允許營銷人員使用大量的消費者購買、調查和麵板數據來理解和傳達戰略營銷。
Web 探索性分析允許營銷人員收集有關網站交互的會話級信息。 谷歌分析是營銷人員為此目的使用的免費和流行的分析工具的一個例子。
營銷中經常使用的探索性技術包括營銷組合建模、定價和促銷分析、銷售優化和探索性客戶分析,例如細分。
#2。 探索性投資組合分析
探索性數據分析的一個常見應用是探索性投資組合分析。 銀行或貸款機構擁有一系列不同價值和風險的賬戶。
賬戶可能會因持有人的社會地位(富人、中產階級、窮人等)、地理位置、淨資產和許多其他因素而有所不同。 貸方必須平衡每筆貸款的貸款回報與違約風險。 那麼問題就變成瞭如何對整個投資組合進行估值。
最低風險的貸款可能適用於非常富有的人,但富人的數量非常有限。 另一方面,許多窮人可以藉錢,但風險更大。
探索性數據分析解決方案可以將時間序列分析與許多其他問題結合起來,以決定何時向這些不同的借款人細分或貸款利率。 向投資組合部分的成員收取利息,以彌補該部分成員之間的損失。
#3。 探索性風險分析
銀行業的預測模型正在開發中,以提供有關個人客戶風險評分的確定性。 信用評分旨在預測個人的違法行為,並廣泛用於評估每個申請人的信用度。
此外,科學界和保險業也進行風險分析。 它還廣泛用於金融機構,如在線支付網關公司,用於分析交易是真實的還是欺詐的。
為此,他們使用客戶的交易歷史。 它更常用於信用卡購買; 當客戶交易量突然激增時,如果客戶發起交易,則會收到確認電話。 它還有助於減少由於這種情況造成的損失。
使用 R 進行探索性數據分析
使用 R 執行 EDA 所需的第一件事是下載 R base 和 R Studio (IDE),然後安裝和加載以下包:
#Installing Packages install.packages("dplyr") install.packages("ggplot2") install.packages("magrittr") install.packages("tsibble") install.packages("forecast") install.packages("skimr") #Loading Packages library(dplyr) library(ggplot2) library(magrittr) library(tsibble) library(forecast) library(skimr)在本教程中,我們將使用 R 內置的經濟數據集,並提供美國經濟的年度經濟指標數據,為簡單起見將其名稱更改為 econ:
econ <- ggplot2::economics 
為了進行描述性分析,我們將使用skimr包,它以一種簡單且呈現良好的方式計算這些統計數據:
#Descriptive Analysis skimr::skim(econ) 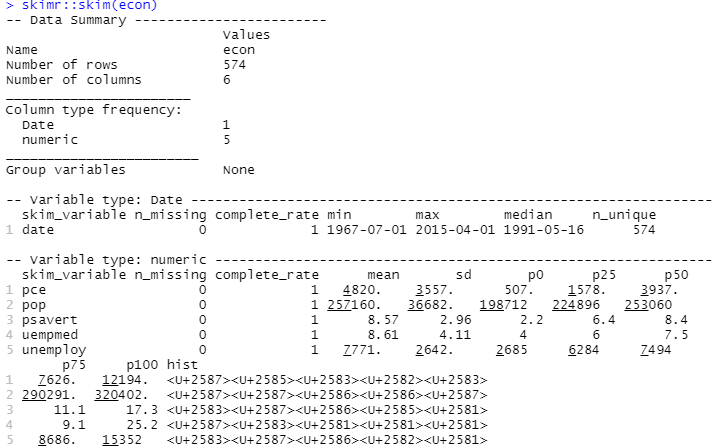
您還可以使用summary函數進行描述性分析:

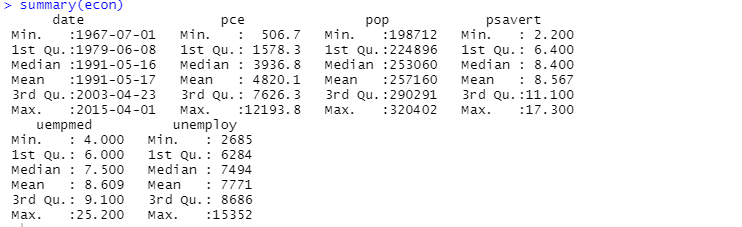
這裡的描述性分析顯示數據集中有 547 行和 6 列。 最小值為 1967-07-01,最大值為 2015-04-01。 同樣,它還顯示平均值和標準偏差。
現在您對 econ 數據集中的內容有了基本的了解。 讓我們繪製變量uempmed的直方圖,以便更好地查看數據:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015") 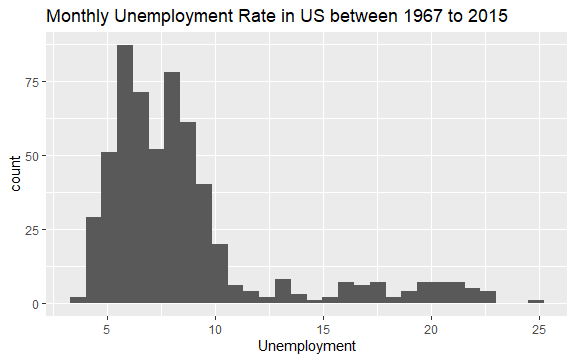
直方圖的分佈顯示它的右側有一條拉長的尾巴; 也就是說,可能有一些對該變量的觀察具有更多“極端”值。 問題來了:這些數值發生在什麼時期,變量的趨勢是什麼?
識別變量趨勢的最直接方法是通過折線圖。 下面我們生成一個折線圖並添加一條平滑線:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth() 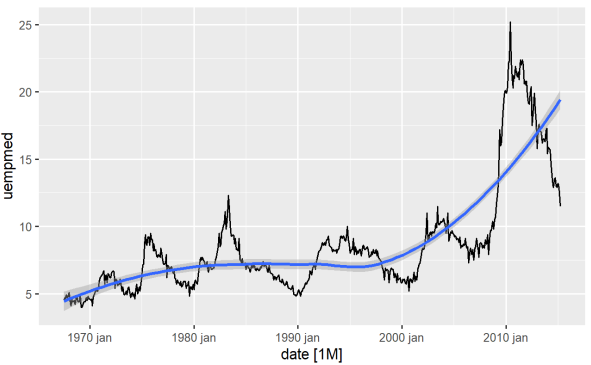
使用該圖,我們可以確定,在最近一段時間,即 2010 年的最後一次觀察中,失業率有上升的趨勢,超過了前幾十年觀察到的歷史。
另一個重要的點,特別是在計量經濟學建模環境中,是序列的平穩性; 也就是說,均值和方差是否隨時間保持不變?
當這些假設在變量中不成立時,我們說該序列具有單位根(非平穩),因此該變量遭受的衝擊會產生永久性影響。
所討論的變量,即失業持續時間,似乎就是這種情況。 我們已經看到,變量的波動發生了很大變化,這對處理週期的經濟理論有很強的影響。 但是,脫離理論,我們如何實際檢查變量是否是平穩的?
預測包具有出色的功能,允許應用測試,例如 ADF、KPSS 等,這些測試已經返回序列平穩所需的差異數量:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")
這裡 p 值大於 0.05 表明數據是非平穩的。
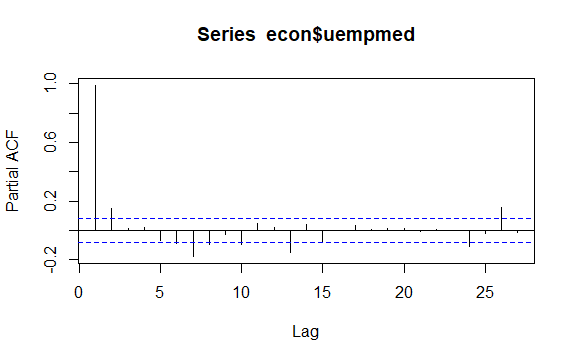
時間序列中的另一個重要問題是識別序列滯後值之間可能的相關性(線性關係)。 ACF 和 PACF 相關圖有助於識別它。
由於該序列沒有季節性但具有一定的趨勢,因此初始自相關往往較大且為正,因為時間接近的觀測值也接近。
因此,趨勢時間序列的自相關函數(ACF)往往具有正值,隨著滯後的增加而緩慢減小。
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed) 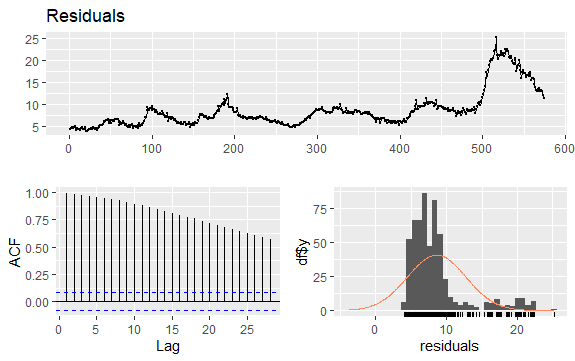
結論
當我們得到或多或少干淨的數據時,也就是說,已經清洗過的數據,我們會立即潛入模型構建階段以得出第一個結果。 您必須抵制這種誘惑並開始進行探索性數據分析,這很簡單,但可以幫助我們對數據產生強大的洞察力。
您還可以探索一些最佳資源來學習數據科學的統計數據。