
Cómo hacer Análisis Exploratorio de Datos (EDA) en R (Con Ejemplos)
Publicado: 2022-11-11Aprenda todo lo que necesita saber sobre el análisis exploratorio de datos, un proceso crítico utilizado para descubrir tendencias y patrones y resumir conjuntos de datos con la ayuda de resúmenes estadísticos y representaciones gráficas.
Como cualquier proyecto, un proyecto de ciencia de datos es un proceso largo que requiere tiempo, buena organización y respeto escrupuloso por varios pasos. El análisis exploratorio de datos (EDA) es uno de los pasos más importantes en este proceso.
Por lo tanto, en este artículo, veremos brevemente qué es el análisis exploratorio de datos y cómo puede realizarlo con R.
¿Qué es el análisis exploratorio de datos?
El análisis exploratorio de datos examina y estudia las características de un conjunto de datos antes de enviarlo a una aplicación, ya sea exclusivamente comercial, estadística o de aprendizaje automático.

Esta síntesis de la naturaleza de la información y sus principales particularidades se suele realizar por métodos visuales, como representaciones gráficas y tablas. La práctica se realiza con antelación precisamente para evaluar el potencial de estos datos, que recibirán un tratamiento más complejo en el futuro.
Por lo tanto, la EDA permite:
- Formular hipótesis para el uso de esta información;
- Explore detalles ocultos en la estructura de datos;
- Identifique valores faltantes, valores atípicos o comportamientos anormales;
- Descubre tendencias y variables relevantes en su conjunto;
- Descartar variables irrelevantes o variables correlacionadas con otras;
- Determinar el modelo formal a utilizar.
¿Cuál es la diferencia entre el análisis de datos descriptivo y exploratorio?
Hay dos tipos de análisis de datos, el análisis descriptivo y el análisis exploratorio de datos, que van de la mano, a pesar de tener objetivos diferentes.
Mientras que el primero se enfoca en describir el comportamiento de las variables, por ejemplo, media, mediana, moda, etc.
El análisis exploratorio tiene como objetivo identificar relaciones entre variables, extraer información preliminar y dirigir el modelado a los paradigmas de aprendizaje automático más comunes: clasificación, regresión y agrupación.
En común, ambos pueden ocuparse de la representación gráfica; sin embargo, solo el análisis exploratorio busca aportar conocimientos procesables, es decir, conocimientos que provoquen la acción por parte del tomador de decisiones.
Finalmente, mientras que el análisis exploratorio de datos busca resolver problemas y brindar soluciones que guiarán los pasos del modelado, el análisis descriptivo, como su nombre lo indica, solo tiene como objetivo producir una descripción detallada del conjunto de datos en cuestión.
| Análisis descriptivo | Análisis exploratorio de datos |
| Analiza el comportamiento | Analiza el comportamiento y la relación. |
| Proporciona un resumen | Conduce a especificaciones y acciones. |
| Organiza los datos en tablas y gráficos. | Organiza los datos en tablas y gráficos. |
| No tiene un poder explicativo significativo. | Tiene un poder explicativo significativo. |
Algunos casos prácticos de uso de EDA
#1. Publicidad digital
El marketing digital ha evolucionado de un proceso creativo a un proceso basado en datos. Las organizaciones de marketing utilizan el análisis exploratorio de datos para determinar los resultados de las campañas o los esfuerzos y para guiar las decisiones de inversión y orientación de los consumidores.
Los estudios demográficos, la segmentación de clientes y otras técnicas permiten a los especialistas en marketing utilizar grandes cantidades de datos de panel, encuestas y compras de consumidores para comprender y comunicar la estrategia de marketing.
El análisis exploratorio web permite a los especialistas en marketing recopilar información a nivel de sesión sobre las interacciones en un sitio web. Google Analytics es un ejemplo de una herramienta de análisis gratuita y popular que utilizan los especialistas en marketing para este propósito.
Las técnicas exploratorias que se utilizan con frecuencia en marketing incluyen el modelado de la mezcla de marketing, los análisis de precios y promociones, la optimización de ventas y el análisis exploratorio de clientes, por ejemplo, la segmentación.
#2. Análisis Exploratorio de Cartera
Una aplicación común del análisis exploratorio de datos es el análisis exploratorio de cartera. Un banco o agencia de crédito tiene una colección de cuentas de valor y riesgo variable.
Las cuentas pueden diferir según el estatus social del titular (rico, clase media, pobre, etc.), la ubicación geográfica, el patrimonio neto y muchos otros factores. El prestamista debe equilibrar el rendimiento del préstamo con el riesgo de incumplimiento de cada préstamo. La pregunta entonces es cómo valorar la cartera en su conjunto.
El préstamo de menor riesgo puede ser para personas muy ricas, pero hay un número muy limitado de personas ricas. Por otro lado, mucha gente pobre puede prestar, pero con mayor riesgo.
La solución de análisis exploratorio de datos puede combinar el análisis de series temporales con muchos otros problemas para decidir cuándo prestar dinero a estos diferentes segmentos de prestatarios o la tasa de préstamo. Se cargan intereses a los miembros de un segmento de cartera para cubrir las pérdidas entre los miembros de ese segmento.
#3. Análisis Exploratorio de Riesgos
Se están desarrollando modelos predictivos en la banca para brindar certeza sobre las puntuaciones de riesgo para clientes individuales. Los puntajes de crédito están diseñados para predecir el comportamiento delictivo de un individuo y se usan ampliamente para evaluar la solvencia de cada solicitante.
Además, se realizan análisis de riesgos en el mundo científico y en la industria aseguradora. También se usa ampliamente en instituciones financieras como las empresas de pasarelas de pago en línea para analizar si una transacción es genuina o fraudulenta.
Para ello, utilizan el historial de transacciones del cliente. Se usa más comúnmente en compras con tarjeta de crédito; cuando hay un aumento repentino en el volumen de transacciones del cliente, el cliente recibe una llamada de confirmación si inició la transacción. También ayuda a reducir las pérdidas debido a tales circunstancias.
Análisis exploratorio de datos con R
Lo primero que necesita para realizar EDA con R es descargar R base y R Studio (IDE), luego instalar y cargar los siguientes paquetes:

#Installing Packages install.packages("dplyr") install.packages("ggplot2") install.packages("magrittr") install.packages("tsibble") install.packages("forecast") install.packages("skimr") #Loading Packages library(dplyr) library(ggplot2) library(magrittr) library(tsibble) library(forecast) library(skimr)Para este tutorial, usaremos un conjunto de datos económicos que viene integrado con R y proporciona datos de indicadores económicos anuales de la economía de EE. UU., y cambiaremos su nombre a econ para simplificar:
econ <- ggplot2::economics 
Para realizar el análisis descriptivo, utilizaremos el paquete skimr , que calcula estas estadísticas de una forma sencilla y bien presentada:
#Descriptive Analysis skimr::skim(econ) 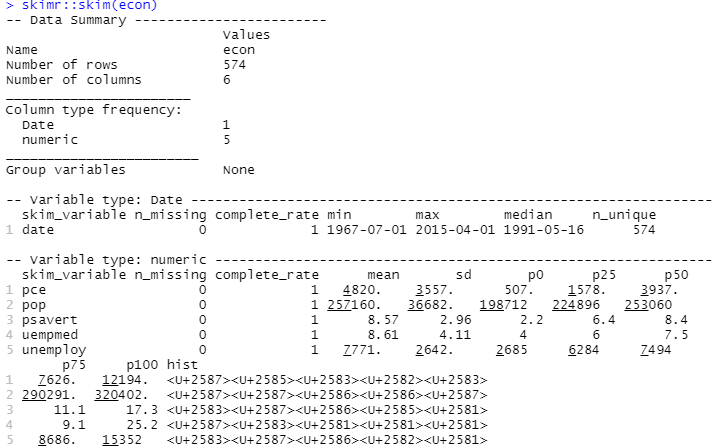
También puede utilizar la función de summary para el análisis descriptivo:
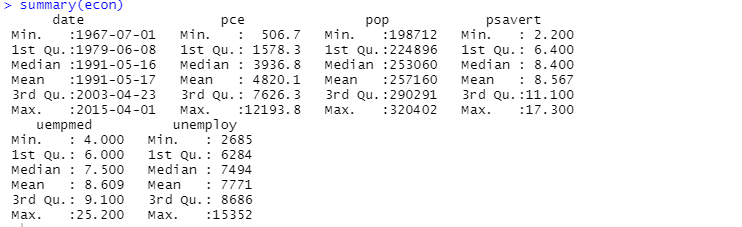
Aquí el análisis descriptivo muestra 547 filas y 6 columnas en el conjunto de datos. El valor mínimo es para 1967-07-01 y el máximo es para 2015-04-01. Del mismo modo, también muestra el valor medio y la desviación estándar.
Ahora tiene una idea básica de lo que hay dentro del conjunto de datos económicos. Tracemos un histograma de la variable uempmed para ver mejor los datos:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015") 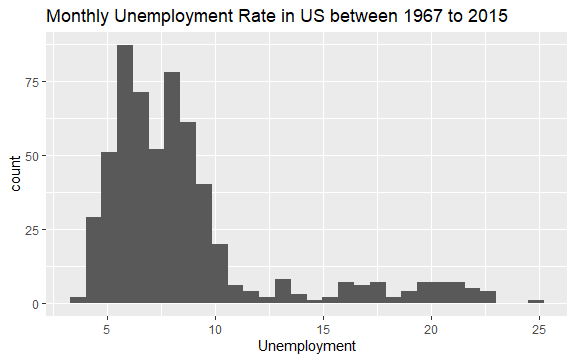
La distribución del histograma muestra que tiene una cola alargada a la derecha; es decir, posiblemente haya algunas observaciones de esta variable con valores más “extremos”. Surge la pregunta: ¿en qué período se produjeron estos valores y cuál es la tendencia de la variable?
La forma más directa de identificar la tendencia de una variable es a través de un gráfico de líneas. A continuación, generamos un gráfico de líneas y agregamos una línea de suavizado:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth() 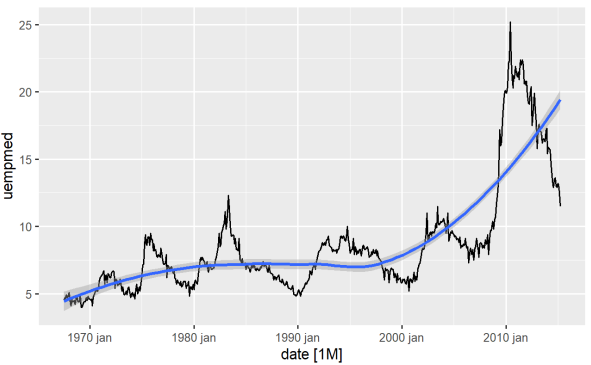
Mediante este gráfico, podemos identificar que en el período más reciente, en las últimas observaciones de 2010, existe una tendencia al aumento del desempleo, superando el histórico observado en décadas anteriores.
Otro punto importante, especialmente en contextos de modelado econométrico, es la estacionariedad de la serie; es decir, ¿la media y la varianza son constantes en el tiempo?
Cuando estos supuestos no se cumplen en una variable, decimos que la serie tiene raíz unitaria (no estacionaria) por lo que los choques que sufre la variable generan un efecto permanente.
Parece que ha sido el caso de la variable en cuestión, la duración del desempleo. Hemos visto que las fluctuaciones de la variable han cambiado considerablemente, lo que tiene fuertes implicaciones relacionadas con las teorías económicas que tratan de ciclos. Pero, partiendo de la teoría, ¿cómo comprobamos en la práctica si la variable es estacionaria?
El paquete de pronóstico tiene una excelente función que permite aplicar pruebas, como ADF, KPSS y otras, que ya devuelven la cantidad de diferencias necesarias para que la serie sea estacionaria:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")
Aquí, el valor p superior a 0,05 muestra que los datos no son estacionarios.
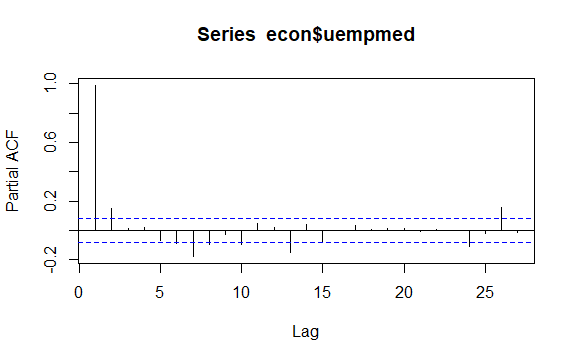
Otro tema importante en las series de tiempo es la identificación de posibles correlaciones (la relación lineal) entre los valores rezagados de la serie. Los correlogramas ACF y PACF ayudan a identificarlo.
Como la serie no tiene estacionalidad pero sí una cierta tendencia, las autocorrelaciones iniciales tienden a ser grandes y positivas porque las observaciones cercanas en el tiempo también lo son en valor.
Así, la función de autocorrelación (ACF) de una serie de tiempo con tendencia tiende a tener valores positivos que disminuyen lentamente a medida que aumentan los rezagos.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed) 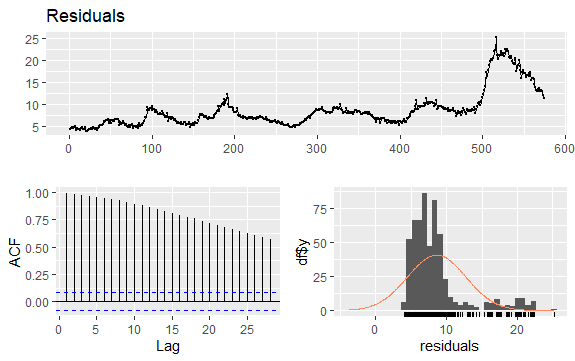
Conclusión
Cuando tenemos en nuestras manos datos más o menos limpios, es decir, ya limpios, estamos inmediatamente tentados de sumergirnos en la etapa de construcción del modelo para extraer los primeros resultados. Debe resistir esta tentación y comenzar a realizar un análisis exploratorio de datos, que es simple pero nos ayuda a obtener información valiosa sobre los datos.
También puede explorar algunos de los mejores recursos para aprender estadísticas para Data Science.