
Bagaimana melakukan Analisis Data Eksplorasi (EDA) di R (Dengan Contoh)
Diterbitkan: 2022-11-11Pelajari semua yang perlu Anda ketahui tentang analisis data eksplorasi, proses kritis yang digunakan untuk menemukan tren dan pola serta meringkas kumpulan data dengan bantuan ringkasan statistik dan representasi grafis.
Seperti proyek apa pun, proyek ilmu data adalah proses panjang yang membutuhkan waktu, organisasi yang baik, dan rasa hormat yang cermat untuk beberapa langkah. Analisis data eksplorasi (EDA) adalah salah satu langkah terpenting dalam proses ini.
Oleh karena itu, dalam artikel ini, kita akan melihat secara singkat apa itu analisis data eksplorasi dan bagaimana Anda dapat melakukannya dengan R!
Apa itu Analisis Data Eksplorasi?
Analisis data eksplorasi memeriksa dan mempelajari karakteristik kumpulan data sebelum diserahkan ke aplikasi, baik secara eksklusif bisnis, statistik, atau pembelajaran mesin.

Ringkasan sifat informasi dan kekhususan utamanya biasanya dilakukan dengan metode visual, seperti representasi grafis dan tabel. Praktik dilakukan terlebih dahulu secara tepat untuk menilai potensi data-data tersebut, yang akan mendapat perlakuan yang lebih kompleks di masa mendatang.
Oleh karena itu, EDA mengizinkan:
- Merumuskan hipotesis untuk penggunaan informasi ini;
- Jelajahi detail tersembunyi dalam struktur data;
- Mengidentifikasi nilai-nilai yang hilang, outlier, atau perilaku abnormal;
- Temukan tren dan variabel yang relevan secara keseluruhan;
- Buang variabel yang tidak relevan atau variabel yang berkorelasi dengan yang lain;
- Tentukan model formal yang akan digunakan.
Apa Perbedaan Antara Analisis Data Deskriptif dan Eksplorasi?
Ada dua jenis analisis data, analisis deskriptif, dan analisis data eksplorasi, yang berjalan beriringan, meskipun memiliki tujuan yang berbeda.
Sedangkan yang pertama berfokus pada pendeskripsian perilaku variabel, misalnya mean, median, modus, dll.
Analisis eksplorasi bertujuan untuk mengidentifikasi hubungan antar variabel, mengekstrak wawasan awal, dan mengarahkan pemodelan ke paradigma pembelajaran mesin yang paling umum: klasifikasi, regresi, dan pengelompokan.
Secara umum, keduanya mungkin berhubungan dengan representasi grafis; namun, hanya analisis eksplorasi yang berusaha menghadirkan wawasan yang dapat ditindaklanjuti, yaitu, wawasan yang memicu tindakan oleh pembuat keputusan.
Akhirnya, sementara analisis data eksplorasi berusaha untuk memecahkan masalah dan membawa solusi yang akan memandu langkah-langkah pemodelan, analisis deskriptif, seperti namanya, hanya bertujuan untuk menghasilkan deskripsi rinci dari dataset yang bersangkutan.
| Analisis Deskriptif | Analisis Data Eksplorasi |
| Menganalisis perilaku | Menganalisis perilaku dan hubungan |
| Memberikan ringkasan | Mengarah ke spesifikasi dan tindakan |
| Mengatur data dalam tabel dan grafik | Mengatur data dalam tabel dan grafik |
| Tidak memiliki kekuatan penjelas yang signifikan | Apakah memiliki kekuatan penjelas yang signifikan |
Beberapa Kasus Penggunaan Praktis EDA
#1. Pemasaran Digital
Pemasaran Digital telah berevolusi dari proses kreatif menjadi proses berbasis data. Organisasi pemasaran menggunakan analisis data eksplorasi untuk menentukan hasil kampanye atau upaya dan untuk memandu keputusan investasi dan penargetan konsumen.
Studi demografis, segmentasi pelanggan, dan teknik lainnya memungkinkan pemasar menggunakan sejumlah besar pembelian konsumen, survei, dan data panel untuk memahami dan mengomunikasikan strategi pemasaran.
Analisis eksplorasi web memungkinkan pemasar mengumpulkan informasi tingkat sesi tentang interaksi di situs web. Google Analytics adalah contoh alat analisis gratis dan populer yang digunakan pemasar untuk tujuan ini.
Teknik eksplorasi yang sering digunakan dalam pemasaran meliputi pemodelan bauran pemasaran, analisis harga dan promosi, optimisasi penjualan, dan analisis pelanggan eksplorasi, misalnya segmentasi.
#2. Analisis Portofolio Eksplorasi
Aplikasi umum dari analisis data eksplorasi adalah analisis portofolio eksplorasi. Sebuah bank atau lembaga pemberi pinjaman memiliki kumpulan rekening dari berbagai nilai dan risiko.
Akun mungkin berbeda tergantung pada status sosial pemegang (kaya, kelas menengah, miskin, dll.), lokasi geografis, kekayaan bersih, dan banyak faktor lainnya. Pemberi pinjaman harus menyeimbangkan pengembalian pinjaman dengan risiko gagal bayar untuk setiap pinjaman. Pertanyaannya kemudian menjadi bagaimana menilai portofolio secara keseluruhan.
Pinjaman dengan risiko terendah mungkin untuk orang yang sangat kaya, tetapi jumlah orang kaya yang sangat terbatas. Di sisi lain, banyak orang miskin dapat meminjamkan, tetapi dengan risiko yang lebih besar.
Solusi analisis data eksplorasi dapat menggabungkan analisis deret waktu dengan banyak masalah lain untuk memutuskan kapan meminjamkan uang ke segmen peminjam yang berbeda ini atau tingkat pinjaman. Bunga dibebankan kepada anggota segmen portofolio untuk menutupi kerugian di antara anggota segmen tersebut.
#3. Analisis Risiko Eksplorasi
Model prediktif dalam perbankan sedang dikembangkan untuk memberikan kepastian tentang skor risiko bagi nasabah individu. Skor kredit dirancang untuk memprediksi perilaku tunggakan individu dan digunakan secara luas untuk menilai kelayakan kredit setiap pemohon.
Selain itu, analisis risiko dilakukan di dunia ilmiah dan industri asuransi. Ini juga banyak digunakan di lembaga keuangan seperti perusahaan gateway pembayaran online untuk menganalisis apakah transaksi itu asli atau penipuan.
Untuk tujuan ini, mereka menggunakan riwayat transaksi pelanggan. Ini lebih umum digunakan dalam pembelian kartu kredit; ketika ada lonjakan tiba-tiba dalam volume transaksi klien, klien menerima panggilan konfirmasi jika dia memulai transaksi. Ini juga membantu mengurangi kerugian karena keadaan seperti itu.
Analisis Data Eksplorasi dengan R
Hal pertama yang Anda perlukan untuk melakukan EDA dengan R adalah mengunduh R base dan R Studio (IDE), diikuti dengan menginstal dan memuat paket-paket berikut:
#Installing Packages install.packages("dplyr") install.packages("ggplot2") install.packages("magrittr") install.packages("tsibble") install.packages("forecast") install.packages("skimr") #Loading Packages library(dplyr) library(ggplot2) library(magrittr) library(tsibble) library(forecast) library(skimr)Untuk tutorial ini, kita akan menggunakan dataset ekonomi yang dilengkapi dengan R dan menyediakan data indikator ekonomi tahunan dari ekonomi AS, dan mengubah namanya menjadi econ untuk kesederhanaan:

econ <- ggplot2::economics 
Untuk melakukan analisis deskriptif, kami akan menggunakan paket skimr , yang menghitung statistik ini dengan cara yang sederhana dan disajikan dengan baik:
#Descriptive Analysis skimr::skim(econ) 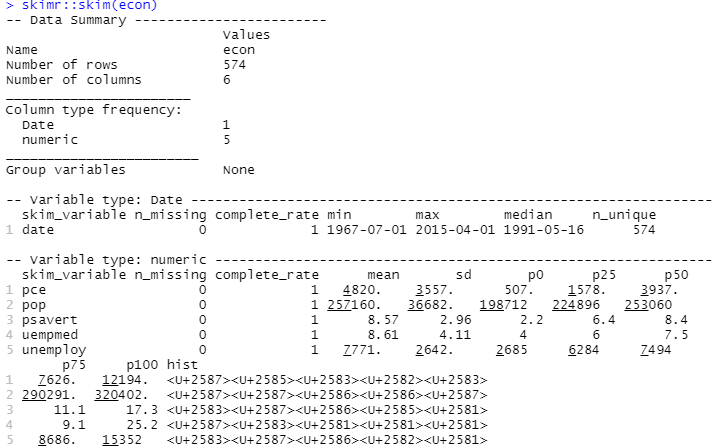
Anda juga dapat menggunakan fungsi summary untuk analisis deskriptif:
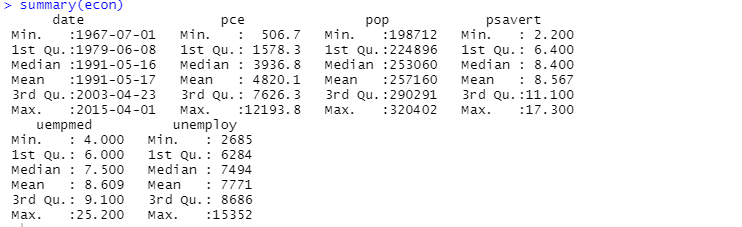
Di sini analisis deskriptif menunjukkan 547 baris dan 6 kolom dalam kumpulan data. Nilai minimum adalah untuk tahun 1967-07-01, dan maksimum adalah untuk 04-01-2015. Demikian pula, itu juga menunjukkan nilai rata-rata dan standar deviasi.
Sekarang Anda memiliki ide dasar tentang apa yang ada di dalam dataset econ. Mari kita plot histogram dari variabel uempmed untuk melihat data dengan lebih baik:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015") 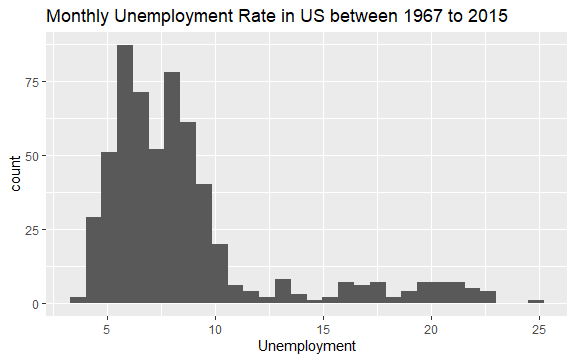
Distribusi histogram menunjukkan bahwa ia memiliki ekor memanjang di sebelah kanan; yaitu, mungkin ada beberapa pengamatan terhadap variabel ini dengan nilai yang lebih “ekstrim”. Timbul pertanyaan: pada periode berapa nilai-nilai ini terjadi, dan bagaimana tren variabelnya?
Cara paling langsung untuk mengidentifikasi tren suatu variabel adalah melalui grafik garis. Di bawah ini kami membuat grafik garis dan menambahkan garis pemulusan:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth() 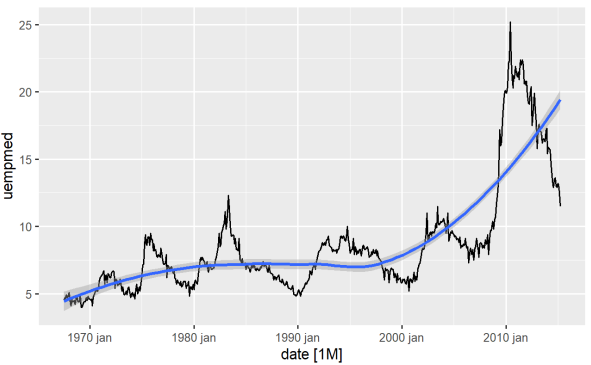
Dengan menggunakan grafik ini, kita dapat mengidentifikasi bahwa pada periode terakhir, pada pengamatan terakhir dari tahun 2010, ada kecenderungan peningkatan pengangguran, melampaui sejarah yang diamati pada dekade sebelumnya.
Poin penting lainnya, terutama dalam konteks pemodelan ekonometrika, adalah stasioneritas deret; yaitu, apakah mean dan varians konstan dari waktu ke waktu?
Ketika asumsi ini tidak benar dalam suatu variabel, kita katakan bahwa deret tersebut memiliki akar unit (non-stasioner) sehingga guncangan yang dialami variabel tersebut menghasilkan efek permanen.
Tampaknya menjadi kasus untuk variabel yang dimaksud, durasi pengangguran. Kita telah melihat bahwa fluktuasi variabel telah banyak berubah, yang memiliki implikasi kuat terkait dengan teori-teori ekonomi yang berhubungan dengan siklus. Tapi, berangkat dari teori, bagaimana kita secara praktis memeriksa apakah variabel itu stasioner?
Paket prakiraan memiliki fungsi luar biasa yang memungkinkan penerapan pengujian, seperti ADF, KPSS, dan lainnya, yang telah mengembalikan jumlah perbedaan yang diperlukan agar rangkaian tetap stasioner:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")
Disini p-value yang lebih besar dari 0,05 menunjukkan bahwa data tersebut non-stasioner.
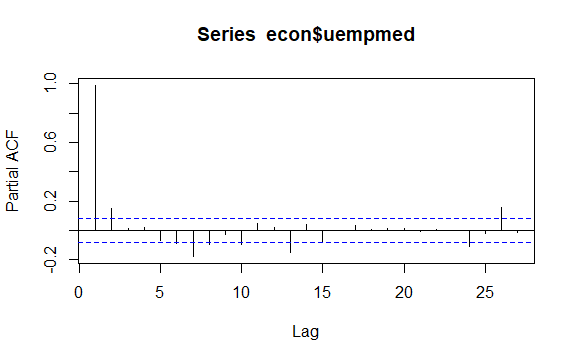
Isu penting lainnya dalam deret waktu adalah identifikasi kemungkinan korelasi (hubungan linier) antara nilai-nilai lag dari deret tersebut. Korelogram ACF dan PACF membantu mengidentifikasinya.
Karena deret tersebut tidak memiliki musim tetapi memiliki tren tertentu, maka autokorelasi awal cenderung besar dan positif karena pengamatan yang dekat dalam waktu juga bernilai dekat.
Dengan demikian, fungsi autokorelasi (ACF) dari deret waktu yang sedang tren cenderung memiliki nilai positif yang perlahan-lahan menurun seiring bertambahnya lag.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed) 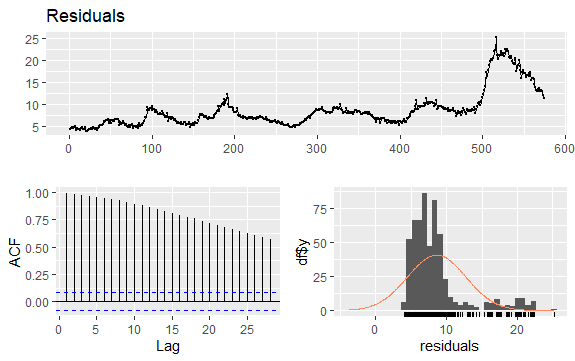
Kesimpulan
Ketika kami mendapatkan data yang kurang lebih bersih, artinya sudah dibersihkan, kami langsung tergoda untuk terjun ke tahap konstruksi model untuk menggambar hasil pertama. Anda harus menahan godaan ini dan mulai melakukan analisis data eksplorasi, yang sederhana namun membantu kami menarik wawasan yang kuat ke dalam data.
Anda juga dapat menjelajahi beberapa sumber daya terbaik untuk mempelajari statistik untuk Ilmu Data.