
R'de Keşifsel Veri Analizi (EDA) Nasıl Yapılır (Örneklerle)
Yayınlanan: 2022-11-11Trendleri ve kalıpları keşfetmek ve istatistiksel özetler ve grafik gösterimler yardımıyla veri kümelerini özetlemek için kullanılan kritik bir süreç olan keşif amaçlı veri analizi hakkında bilmeniz gereken her şeyi öğrenin.
Herhangi bir proje gibi, bir veri bilimi projesi de zaman, iyi organizasyon ve birkaç adıma titizlikle saygı gösterilmesini gerektiren uzun bir süreçtir. Keşfedici veri analizi (EDA) bu süreçteki en önemli adımlardan biridir.
Bu nedenle bu yazımızda, keşifsel veri analizinin ne olduğuna ve R ile nasıl gerçekleştirebileceğinize kısaca değineceğiz!
Keşfedici Veri Analizi Nedir?
Keşfedici veri analizi, bir uygulamaya sunulmadan önce, yalnızca iş, istatistiksel veya makine öğrenimi olsun, bir veri kümesinin özelliklerini inceler ve inceler.

Bilginin doğasına ve temel özelliklerine ilişkin bu özet, genellikle grafik gösterimler ve tablolar gibi görsel yöntemlerle yapılır. Uygulama, gelecekte daha karmaşık bir işleme tabi tutulacak olan bu verilerin potansiyelini tam olarak değerlendirmek için önceden gerçekleştirilir.
EDA bu nedenle şunları sağlar:
- Bu bilgilerin kullanımı için hipotezler formüle edin;
- Veri yapısındaki gizli ayrıntıları keşfedin;
- Eksik değerleri, aykırı değerleri veya anormal davranışları belirleyin;
- Trendleri ve ilgili değişkenleri bir bütün olarak keşfedin;
- Alakasız değişkenleri veya diğerleriyle ilişkili değişkenleri atın;
- Kullanılacak resmi modellemeyi belirleyin.
Tanımlayıcı ve Keşfedici Veri Analizi Arasındaki Fark Nedir?
Farklı hedeflere sahip olmalarına rağmen el ele giden iki tür veri analizi, betimleyici analiz ve keşifsel veri analizi vardır.
İlki, örneğin ortalama, medyan, mod vb. değişkenlerin davranışını tanımlamaya odaklanırken.
Keşfedici analiz, değişkenler arasındaki ilişkileri tanımlamayı, ön öngörüleri çıkarmayı ve modellemeyi en yaygın makine öğrenimi paradigmalarına yönlendirmeyi amaçlar: sınıflandırma, regresyon ve kümeleme.
Ortak olarak, her ikisi de grafik gösterimle ilgili olabilir; bununla birlikte, yalnızca keşif analizi, eyleme geçirilebilir içgörüler, yani karar vericinin eylemini tetikleyen içgörüler getirmeye çalışır.
Son olarak, keşifsel veri analizi, modelleme adımlarına rehberlik edecek sorunları çözmeyi ve çözümler getirmeyi amaçlarken, betimsel analiz, adından da anlaşılacağı gibi, yalnızca söz konusu veri kümesinin ayrıntılı bir tanımını üretmeyi amaçlar.
| Açıklayıcı analiz | Keşfedici Veri Analizi |
| Davranışı analiz eder | Davranış ve ilişkiyi analiz eder |
| Bir özet sağlar | Spesifikasyona ve eylemlere yol açar |
| Verileri tablolar ve grafikler halinde düzenler | Verileri tablolar ve grafikler halinde düzenler |
| Önemli bir açıklayıcı güce sahip değil | Önemli bir açıklayıcı güce sahip mi? |
EDA'nın Bazı Pratik Kullanım Örnekleri
#1. Dijital Pazarlama
Dijital Pazarlama, yaratıcı bir süreçten veriye dayalı bir sürece dönüşmüştür. Pazarlama kuruluşları, kampanyaların veya çabaların sonuçlarını belirlemek ve tüketici yatırımlarına ve hedefleme kararlarına rehberlik etmek için keşifsel veri analizini kullanır.
Demografik çalışmalar, müşteri segmentasyonu ve diğer teknikler, pazarlamacıların strateji pazarlamasını anlamak ve iletmek için büyük miktarlarda tüketici satın alma, anket ve panel verilerini kullanmalarına olanak tanır.
Web keşif analitiği, pazarlamacıların bir web sitesindeki etkileşimler hakkında oturum düzeyinde bilgi toplamasına olanak tanır. Google Analytics, pazarlamacıların bu amaçla kullandığı ücretsiz ve popüler bir analiz aracı örneğidir.
Pazarlamada sıklıkla kullanılan keşif teknikleri arasında pazarlama karması modellemesi, fiyatlandırma ve promosyon analizleri, satış optimizasyonu ve keşifsel müşteri analizi, örneğin segmentasyon bulunur.
#2. Keşif Portföy Analizi
Keşfedici veri analizinin yaygın bir uygulaması, keşifsel portföy analizidir. Bir banka veya kredi kuruluşu, değişen değer ve riske sahip bir hesap koleksiyonuna sahiptir.
Hesaplar, sahibinin sosyal statüsüne (zengin, orta sınıf, fakir vb.), coğrafi konuma, net değere ve diğer birçok faktöre bağlı olarak farklılık gösterebilir. Borç veren, kredinin getirisini her bir kredi için temerrüt riski ile dengelemelidir. O zaman soru, portföyün bir bütün olarak nasıl değerleneceği olur.
En düşük riskli kredi, çok varlıklı insanlar için olabilir, ancak çok sınırlı sayıda varlıklı insan vardır. Öte yandan, birçok yoksul insan borç verebilir, ancak daha büyük risk altındadır.
Keşfedici veri analizi çözümü, borç alanların bu farklı kesimlerine ne zaman borç verileceğine veya borç verme oranına karar vermek için zaman serisi analizini diğer birçok sorunla birleştirebilir. Bir portföy segmentinin üyelerine, o segmentin üyeleri arasındaki kayıpları karşılamak için faiz uygulanır.
#3. Keşifsel Risk Analizi
Bireysel müşteriler için risk puanları hakkında kesinlik sağlamak için bankacılıkta tahmin modelleri geliştirilmektedir. Kredi puanları, bir bireyin kusurlu davranışını tahmin etmek için tasarlanmıştır ve her başvuru sahibinin kredi itibarını değerlendirmek için yaygın olarak kullanılır.
Ayrıca bilim dünyasında ve sigorta sektöründe risk analizi yapılmaktadır. Ayrıca, bir işlemin gerçek mi yoksa sahte mi olduğunu analiz etmek için çevrimiçi ödeme ağ geçidi şirketleri gibi finans kurumlarında da yaygın olarak kullanılmaktadır.
Bu amaçla müşterinin işlem geçmişini kullanırlar. Daha çok kredi kartıyla yapılan alışverişlerde kullanılır; müşteri işlem hacminde ani bir artış olduğunda, müşteri işlemi başlattıysa bir onay çağrısı alır. Bu gibi durumlardan kaynaklanan kayıpların azaltılmasına da yardımcı olur.
R ile Keşfedici Veri Analizi
EDA'yı R ile gerçekleştirmeniz gereken ilk şey, R base ve R Studio'yu (IDE) indirmek, ardından aşağıdaki paketleri kurmak ve yüklemek:
#Installing Packages install.packages("dplyr") install.packages("ggplot2") install.packages("magrittr") install.packages("tsibble") install.packages("forecast") install.packages("skimr") #Loading Packages library(dplyr) library(ggplot2) library(magrittr) library(tsibble) library(forecast) library(skimr)Bu öğretici için, R ile yerleşik olarak gelen ve ABD ekonomisinin yıllık ekonomik gösterge verilerini sağlayan bir ekonomi veri kümesini kullanacağız ve basitlik için adını econ olarak değiştireceğiz:

econ <- ggplot2::economics 
Tanımlayıcı analizi gerçekleştirmek için, bu istatistikleri basit ve iyi sunulmuş bir şekilde hesaplayan skimr paketini kullanacağız:
#Descriptive Analysis skimr::skim(econ) 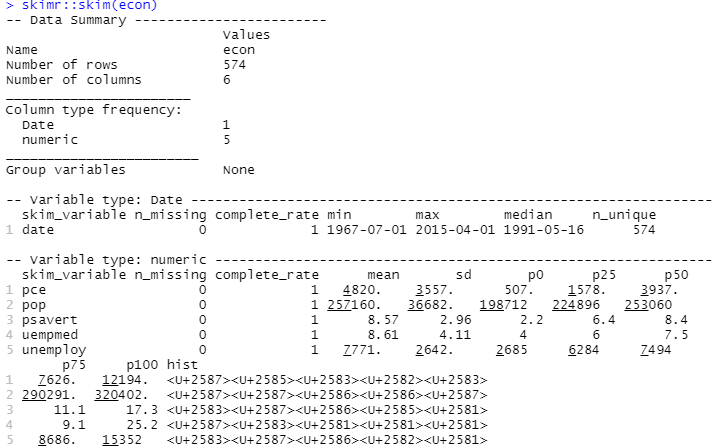
Tanımlayıcı analiz için summary işlevini de kullanabilirsiniz:
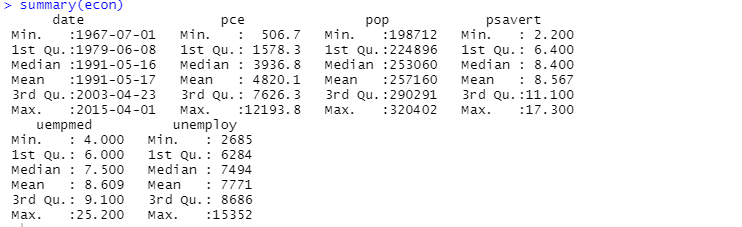
Burada tanımlayıcı analiz, veri kümesindeki 547 satır ve 6 sütunu gösterir. Minimum değer 1967-07-01 ve maksimum değer 2015-04-01 içindir. Benzer şekilde, ortalama değeri ve standart sapmayı da gösterir.
Artık econ veri setinin içinde ne olduğuna dair temel bir fikriniz var. Verilere daha iyi bakmak için uempmed değişkeninin bir histogramını çizelim:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015") 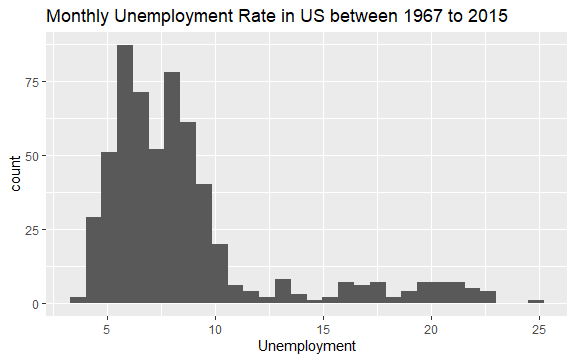
Histogramın dağılımı, sağda uzun bir kuyruğu olduğunu gösterir; yani, muhtemelen bu değişkenin daha "aşırı" değerlere sahip birkaç gözlemi vardır. Soru ortaya çıkıyor: Bu değerler hangi dönemde gerçekleşti ve değişkenin eğilimi nedir?
Bir değişkenin trendini belirlemenin en doğrudan yolu çizgi grafiği kullanmaktır. Aşağıda bir çizgi grafiği oluşturuyoruz ve bir yumuşatma çizgisi ekliyoruz:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth() 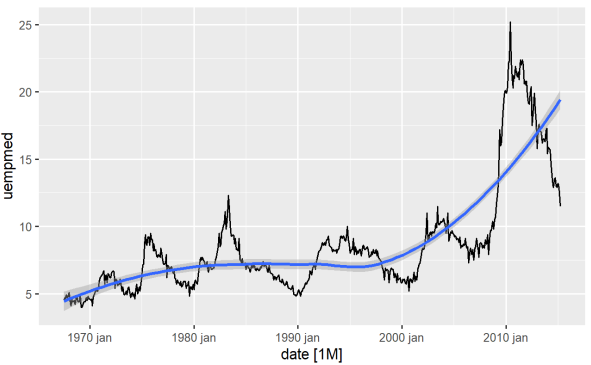
Bu grafiği kullanarak, en son dönemde, 2010'dan itibaren yapılan son gözlemlerde, işsizlikte önceki on yıllarda gözlenen tarihi aşan bir artış eğilimi olduğunu tespit edebiliriz.
Özellikle ekonometrik modelleme bağlamında bir diğer önemli nokta ise serilerin durağanlığıdır; yani, ortalama ve varyans zaman içinde sabit midir?
Bir değişkende bu varsayımlar doğru olmadığında, serinin birim kökü (durağan olmayan) olduğunu ve böylece değişkenin maruz kaldığı şokların kalıcı bir etki yarattığını söylüyoruz.
Söz konusu değişken olan işsizlik süresi için de durum aynı gibi görünüyor. Değişkenin dalgalanmalarının önemli ölçüde değiştiğini ve bunun döngülerle ilgilenen ekonomik teorilerle ilgili güçlü etkileri olduğunu gördük. Ancak teoriden yola çıkarak, değişkenin durağan olup olmadığını pratikte nasıl kontrol ederiz?
Tahmin paketi, ADF, KPSS ve serinin durağan olması için gereken fark sayısını zaten döndüren diğerleri gibi testlerin uygulanmasına izin veren mükemmel bir işleve sahiptir:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")
Burada 0,05'ten büyük p değeri, verilerin durağan olmadığını gösterir.
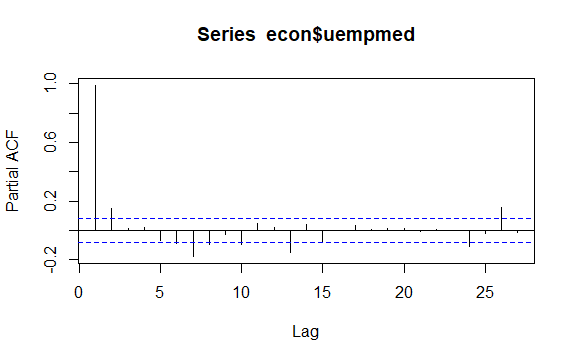
Zaman serilerinde bir diğer önemli konu ise serilerin gecikmeli değerleri arasındaki olası korelasyonların (doğrusal ilişkinin) belirlenmesidir. ACF ve PACF korelogramları onu tanımlamaya yardımcı olur.
Serinin mevsimselliği olmadığı ancak belirli bir eğilimi olduğu için, başlangıçtaki otokorelasyonlar büyük ve pozitif olma eğilimindedir, çünkü zaman içinde yakın olan gözlemler de değer olarak yakındır.
Böylece, trend olan bir zaman serisinin otokorelasyon fonksiyonu (ACF), gecikmeler arttıkça yavaş yavaş azalan pozitif değerlere sahip olma eğilimindedir.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed) 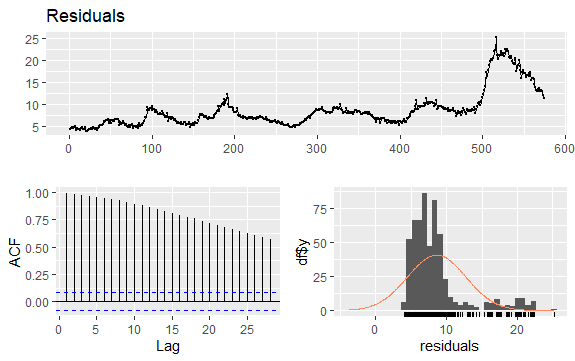
Çözüm
Az ya da çok temiz, yani zaten temizlenmiş verilere ulaştığımızda, ilk sonuçları çıkarmak için hemen model oluşturma aşamasına dalmaya başlarız. Bu cazibeye direnmeli ve verilere güçlü içgörüler kazandırmamıza yardımcı olan basit ama keşifsel veri analizi yapmaya başlamalısınız.
Veri Bilimi istatistiklerini öğrenmek için en iyi kaynakları da keşfedebilirsiniz.