
Порядковые данные: определение, примеры, сбор и анализ
Опубликовано: 2023-03-24Компании вкладывают больше средств в инструменты обработки данных, чтобы помочь своим маркетинговым командам принимать более обоснованные решения.
Но для реализации эффективной маркетинговой стратегии маркетингу нужно нечто большее, чем просто инструменты данных и аналитики. Им также необходимо понимать, какой тип данных они собирают, и как их анализировать, чтобы получить ценную информацию.
Это предполагает возвращение к основам и понимание порядковых данных, одного из ключевых типов маркетинговых данных. В этой статье будут рассмотрены порядковые данные и то, как они влияют на маркетинговые решения, основанные на данных.
Что такое порядковые данные?
Порядковые данные — это количественные данные, в которых переменные организованы в упорядоченные категории, такие как ранжирование от 1 до 10. Однако между переменными отсутствует четкий интервал, и значения в порядковых данных не всегда имеют равномерное распределение.
Уровень удовлетворенности клиентов является примером порядковых данных. Его переменными могут быть:
- очень доволен
- Удовлетворен
- Нейтральный
- Неудовлетворенный
- Очень Недовольный
Используя порядковые данные, вы можете рассчитать частоту, распределение, моду, медиану и диапазон переменных.
Определив порядковые данные, вы можете задаться вопросом о других типах данных, таких как номинальные, интервальные или относительные данные. Чем они отличаются от порядковых данных? Вот несколько быстрых определений:
- Номинальные данные — это классификация данных, переменные которых имеют конечный набор значений и неупорядоченных категорий. С помощью номинальных данных вы измеряете такие переменные, как тип занятости, которая имеет несколько результатов, таких как фриланс, полный рабочий день или смешанная работа.
- Интервальные данные — это тип данных, в которых интервал между двумя значениями не является постоянным. Интервальные данные возникают разными способами, например, при измерении временных интервалов или когда разница между двумя измерениями различается. Наиболее распространенный способ представления интервальных данных — использование таблицы со столбцами для верхней и нижней границ каждого диапазона.
- Данные отношения — это тип данных, используемых для статистического анализа. Данные отношения не предоставляют никакой информации о значениях, которые они представляют. Эта информация должна быть получена из других источников, на которые ссылаются данные коэффициента. Он часто используется при анализе финансовой информации, но может применяться и к другим типам данных.
5 примеров порядковых данных
Порядковые данные встречаются в разных форматах. Вот несколько примеров порядковых данных и способов их синхронизации с вашей бизнес-стратегией, чтобы улучшить ваши усилия по управлению данными.
1. Уровень интереса
Независимо от того, выпустили ли вы свой продукт на рынок или добавили новые функции в свой существующий продукт, вам необходимо провести исследование рынка, чтобы задать вопросы, чтобы оценить интерес вашей целевой аудитории.
Исследование рынка включает в себя анализ как качественных, так и количественных данных, чтобы понять потребности клиентов, их партнеров по покупке и то, что мотивирует их покупать у вас. Эти идеи могут помочь улучшить ваши маркетинговые кампании в будущем.
Например, если вы регулярно проводите конференции, опросы могут помочь вам узнать, насколько хорошо вы выступили и хотят ли ваши участники снова посетить конференцию. Вот пример данных об уровне интереса:

Источник: SurveyMonkey.
Вопросы, которые вы зададите, покажут уровень интереса потенциальных клиентов к вашему продукту или услуге. Уровни интереса варьируются от «не заинтересован», «слегка заинтересован», «нейтрально» и «очень заинтересован».
2. Уровень образования
Этот тип порядковых данных дает представление об уровне знаний вашей целевой аудитории.
Уровень образования может выяснить, получила ли ваша целевая аудитория различные уровни формального образования, такие как средняя школа, колледж и аспирантура. Вы можете собрать эти данные, присвоив номера каждому уровню, например, 1 для отсутствия формального образования, 2 для начального образования и т. д., вплоть до 10 для докторской университетской степени.
Данные об уровне образования пригодятся при использовании аналитики в процессе найма, чтобы помочь вам оценить заявления о приеме на работу потенциальных кандидатов.
Данные образовательного уровня могут помочь вам сделать точные прогнозы о том, кого нанять в будущем для поддержки роста компании, на чем сосредоточить свои усилия по подбору персонала и найти подходящих кандидатов на определенные должности.
Если вы управляете отделом продаж, оценка уровня образования членов вашей команды позволит вам узнать, как поддержать их цели карьерного роста. Таким образом, вы сможете создать высокоэффективную команду по продажам и улучшить удержание клиентов.
3. Социально-экономический статус
Понимание социально-экономического статуса вашей целевой аудитории помогает создавать и уточнять сегменты ваших клиентов на основе их демографических и психографических профилей.
Затем вы можете положиться на эти сегменты при проведении персонализированных маркетинговых кампаний, отвечающих их потребностям и желаниям. Порядковые данные о социально-экономическом статусе целевой аудитории B2C включают пол, местонахождение, доход домохозяйства, семейное положение и возраст.
С другой стороны, данные для целевой аудитории B2B включают валовой годовой доход, стадию роста бизнеса, количество сотрудников, положение на рынке и тип отрасли.
4. Уровень удовлетворенности
Уровень удовлетворенности отражает, насколько ваши клиенты довольны различными взаимодействиями с брендом. Например, ваш процесс адаптации клиентов или то, насколько хорошо вы решаете различные проблемы клиентов.
Удовлетворенность клиентов может быть выражена как «чрезвычайно удовлетворенный», «удовлетворенный», «неудовлетворенный» или «крайне неудовлетворенный». Данные об уровне удовлетворенности помогают вам оценить уровень обслуживания клиентов и удовлетворенность продажами, чтобы определить области для улучшения.
Вот пример данных об уровне удовлетворенности из исследования соответствия продукта рынку, проведенного Buffer:
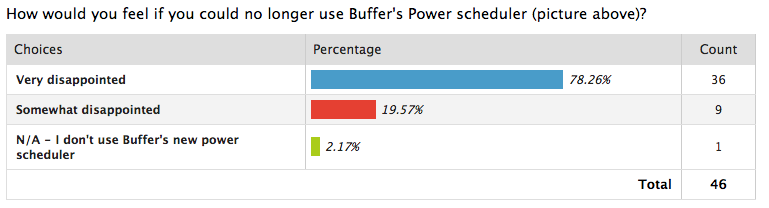
Источник: Буфер
С помощью этих данных компания могла сказать, насколько полезен планировщик Power от Buffer для своих клиентов, а это означает, что продукт подходит для их пользователей.
5. Сравнение
Это включает в себя задавание вопросов, которые выявляют сходства или различия между двумя или более точками данных. Как только вы определите сходства или различия, вы сможете узнать, какие характеристики похожи, какие отличаются и в какой степени они отличаются или похожи.
Например, вы можете сравнить показатели дохода с 2021 по 2022 год. Ваше сравнение даст значительно меньше, примерно столько же, больше и значительно больше для дохода за каждый год.
Благодаря этому вы можете отслеживать макроэкономические и отраслевые тенденции и корректировать свою стратегию в соответствии с процессом составления бюджета, чтобы контролировать расходы. Вы даже можете пойти дальше и сравнить отраслевые тенденции, чтобы создавать отчеты и писать передовой контент для повышения узнаваемости бренда.
Как собирать порядковые данные
Если вы попросите кого-нибудь оценить уровень своего удовлетворения по шкале от 1 до 5, его ответ будет порядковым. Вы можете собирать эти данные с помощью опросов или шкал Лайкерта, используя программное обеспечение для опросов.
Опросы — один из старейших методов сбора порядковых данных. Вы можете использовать опросы, чтобы определить отношение вашей целевой аудитории к продуктам, темам или конкретным проблемам, связанным с вашим брендом, продуктом или услугой. Вы можете проводить опросы разными способами, в том числе лично, по телефону или через Интернет.

Однако при проведении опросов сложно собрать точные данные от людей, которые не хотят честно отвечать на вопросы или понимать их. Опросы также требуют много времени со стороны исследователя для их создания, проверки и анализа.
Шкала Лайкерта — это опрос, в котором участников просят согласиться или не согласиться с каждым утверждением в опросе, например, «Я категорически не согласен». Затем участники назначают себе ответ, основываясь на своих чувствах по отношению к утверждению и уровне своего согласия с ним.
Шкалы Лайкерта улучшают наглядность анализа, поскольку респонденты оценивают себя по упорядоченной шкале с четко определенными интервалами, например, по шкале от 1 до 7.
Для сбора порядковых данных необходимо проводить опросы с вопросами, ранжирующими ответы по неявной или явной шкале. Например, если на веб-сайт вашей компании поступает много трафика, вы можете использовать инструмент обратной связи корпоративного веб-сайта для сбора отзывов с вашего веб-сайта. Просить:
«Насколько вы довольны сообщением в блоге, которое вы только что прочитали?»
Возможные ответы могут быть:
- Счастливый
- Несчастный
- Удовлетворен
- Неудовлетворенный
Тесты для проведения с порядковыми данными
Вы можете провести несколько тестов на порядковых данных, чтобы измерить разницу между двумя или более группами. Эти тесты включают в себя:
- Тест Краскела-Уоллиса
- U-критерий Манна-Уитни
- Критерий суммы рангов Уилкоксона
- Медианный тест настроения
Порядковые данные — это тип данных, ранжирующий значения от наименьшего к наибольшему. Другими словами, порядковые данные ранжированы или упорядочены.
H-тест Крускала – Уоллиса
Критерий Крускала-Уоллиса — это непараметрический критерий, используемый для сравнения медиан трех или более независимых групп. Он используется, когда данные не распределены нормально, а дисперсия между группами неодинакова. Тест Крускала-Уоллиса также позволяет сравнивать две зависимые группы — изображения до и после редизайна веб-сайта.
U-критерий Манна-Уитни
Критерий Манна-Уитни — это непараметрический критерий, используемый для сравнения медианы двух независимых выборок. Его можно использовать при наличии порядковых данных, таких как оценки по шкале от 1 до 5, или когда в данных нет четких групп.
Критерий знакового ранга Уилкоксона
Критерий знакового ранга Уилкоксона — это непараметрический критерий, который можно использовать для наборов данных с нормальным распределением или без него. Это альтернатива t-тесту в случаях, когда данные не имеют нормального распределения.
При выполнении t-теста предполагается, что базовое распределение данных является нормальным, но это предположение может быть ошибочным.
Например, при тестировании разницы в росте между двумя группами предположим, что в одной группе средний рост составляет 180 см, а в другой — 170 см. Вы не увидите существенной разницы в их росте.
Однако, используя знаковый ранговый критерий Уилкоксона, вы можете увидеть не только обычную разницу в их росте.
Средний тест настроения
Тест основан на предположении, что настроения людей группируются вокруг средней точки, причем некоторые из них более позитивны или негативны, чем другие. Медианный тест Mood часто измеряет, как люди относятся к проблеме или идее, например, мнение вашего клиента о ваших продуктах или услугах. Он может предсказать поведение на основе их настроения, например, будут ли ваши клиенты покупать у вас или у ваших конкурентов.
Как анализировать порядковые данные
Существует два способа анализа порядковых данных: выводная и описательная статистика.
Описательная статистика обобщает характеристики набора данных и выявляет закономерности. Вот описательная статистика для порядковых данных:
- Распределение частоты
- Меры центральной тенденции
- Диапазон (меры изменчивости)
Логическая статистика , с другой стороны, предсказывает, что может произойти в будущем, на основе имеющихся у вас данных. Вы можете использовать порядковые данные для сбора информации, создания гипотез или даже выводов с помощью четырех тестов, описанных выше.
Критерии Крускала-Уоллиса, Манна-Уитни U и критерия суммы знаковых рангов Уилкоксона анализируют порядковые данные. Все они являются непараметрическими тестами, что означает, что они не полагаются на какие-либо предположения о распределении данных.
Описательная аналитика
Описательная аналитика собирает, анализирует и сообщает данные об уже произошедших событиях. Это отличается от прогнозной аналитики, которая предсказывает будущие события на основе исторических данных. Описательная аналитика помогает компаниям выявлять модели прошлого, чтобы улучшить процесс принятия решений в будущем.
В описательной аналитике цель состоит в том, чтобы найти закономерности в существующих данных, а не предсказать, что произойдет в будущем. Описательная аналитика направлена на поиск причинно-следственных связей между прошлыми событиями и использование этих связей для прогнозирования будущих событий.
В отличие от других методов анализа, описательную аналитику можно использовать в любое время с любыми доступными данными. Это делает его более доступным для небольших компаний, у которых недостаточно ресурсов для прогностических моделей или больших наборов данных, необходимых для других методов.
Графики
Столбцы и графики представляют данные в удобном для понимания виде. Они полезны, когда данные слишком велики или сложны для отображения в таблице. Тип графика, который вы выбираете, зависит от объема информации, которую вы хотите передать, размеров данных и вашей аудитории.
Гистограммы отображают информацию в виде столбцов, длина которых пропорциональна их значениям. Они используются, когда данные являются категориальными, то есть они попадают в определенные группы. Вот гистограмма для колл-центра, показывающая время, необходимое для ответа в каждый будний день:
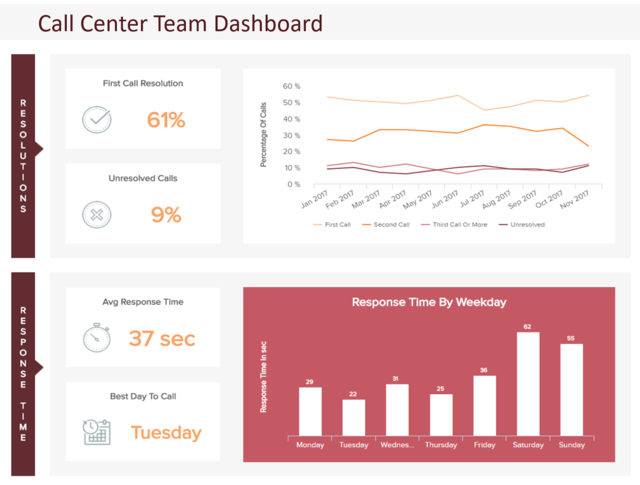
Источник: Датапин
Это хороший выбор, если вы хотите, чтобы ваша аудитория могла легко сравнивать значения. Гистограммы более интуитивно понятны и их легче понять по сравнению с числами. Также можно использовать полосы в сочетании с линиями или другой графикой, такой как точечные диаграммы, гистограммы или круговые диаграммы.
Линейные графики используются, когда данные имеют упорядоченное значение. Эти графики используют линии для соединения точек на двух осях с одинаковым масштабом с обеих сторон. Эти линии могут быть сплошными или пунктирными и начинаться в любой точке на любой оси.
Линии отображают изменения во времени, например ежедневные колебания фондового рынка или годовые изменения стоимости энергии. Вот пример ежемесячных входящих лидов за 12 месяцев, визуализированных с помощью линейного графика:

Меры центральной тенденции
Центральная тенденция представляет собой среднее значение набора чисел. Он измеряет, насколько близко числа в наборе данных сгруппированы вокруг их среднего значения.
Три основных типа центральной тенденции — это среднее значение, медиана и мода. Наиболее распространенной мерой центральной тенденции является среднее арифметическое, вычисляемое путем сложения всех значений в наборе данных и деления этой суммы на количество значений в этом наборе данных.
Медиану также можно использовать в качестве альтернативы вычислению центральной тенденции, просто найдя среднее значение в наборе данных после упорядочивания всех чисел от меньшего к большему. Мода является наиболее часто встречающимся значением в наборе.
Основные выводы
Порядковые данные более сложны, чем номинальные данные, и обычно используются для измерения интереса. Шкала Лайкерта — популярный пример порядковых данных.
Используйте некоторые из реальных примеров, представленных здесь, чтобы вдохновить вас на сбор данных для собственного опроса. Заодно узнайте больше об опросе и о том, как он помогает собирать данные.