
Dane porządkowe: definicja, przykłady, zbieranie i analiza
Opublikowany: 2023-03-24Firmy inwestują więcej w narzędzia danych, aby pomóc swoim zespołom marketingowym podejmować lepsze decyzje.
Jednak marketing potrzebuje czegoś więcej niż tylko danych i narzędzi analitycznych do wdrożenia skutecznej strategii marketingowej. Muszą również zrozumieć, jakiego rodzaju dane gromadzą i jak je analizować, aby uzyskać sensowne spostrzeżenia.
Wiąże się to z powrotem do podstaw i zrozumieniem danych porządkowych, jednego z kluczowych typów danych marketingowych. W tym artykule zbadamy dane porządkowe i sposób, w jaki wpływają one na decyzje marketingowe oparte na danych.
Co to są dane porządkowe?
Dane porządkowe to dane ilościowe, w których zmienne są uporządkowane w uporządkowane kategorie, takie jak ranking od 1 do 10. Jednak między zmiennymi brakuje wyraźnego odstępu, a wartości w danych porządkowych nie zawsze mają równomierny rozkład.
Poziom satysfakcji klienta jest przykładem danych porządkowych. Jego zmiennymi mogą być:
- Bardzo zadowolony
- Zadowolona
- Neutralny
- Niezadowolony
- Bardzo nieusatysfakcjonowany
Używając danych porządkowych, możesz obliczyć częstotliwość, rozkład, tryb, medianę i zakres zmiennych.
Po zdefiniowaniu danych porządkowych możesz zastanawiać się nad innymi typami danych, takimi jak dane nominalne, przedziałowe lub ilorazowe. Czym różnią się od danych porządkowych? Oto kilka szybkich definicji:
- Dane nominalne to klasyfikacja danych, których zmienne mają skończony zestaw wartości i kategorii, które nie są uporządkowane. Za pomocą danych nominalnych mierzysz zmienne, takie jak rodzaj zatrudnienia, który ma kilka wyników, takich jak praca na zlecenie, praca w pełnym wymiarze godzin lub praca hybrydowa.
- Dane interwałowe to typ danych, w których odstęp między dwiema wartościami nie jest stały. Dane interwałowe powstają na wiele sposobów, na przykład podczas pomiaru interwałów czasowych lub gdy różnica między dwoma pomiarami jest różna. Najczęstszym sposobem przedstawiania danych interwałowych jest użycie tabeli z kolumnami dla górnych i dolnych granic każdego zakresu.
- Dane ilorazowe to rodzaj danych wykorzystywanych do analizy statystycznej. Dane wskaźnikowe nie dostarczają żadnych informacji o wartościach, które reprezentują. Informacje te należy uzyskać z innych źródeł, do których odwołują się dane wskaźnikowe. Jest często używany w analizie informacji finansowych, ale może być również stosowany do innych typów danych.
5 przykładów danych porządkowych
Dane porządkowe występują w różnych formatach. Oto kilka przykładów danych porządkowych oraz sposobów synchronizacji ich ze strategią biznesową w celu usprawnienia zarządzania danymi.
1. Poziom zainteresowania
Niezależnie od tego, czy wprowadziłeś już swój produkt na rynek, czy wprowadzasz nowe funkcje do istniejącego produktu, musisz przeprowadzić badanie rynku, aby zadać pytania, aby ocenić zainteresowanie docelowych odbiorców.
Badanie rynku obejmuje analizę zarówno danych jakościowych, jak i ilościowych w celu zrozumienia potrzeb klientów, ich partnerów zakupowych oraz tego, co motywuje ich do kupowania od Ciebie. Te spostrzeżenia mogą pomóc w ulepszeniu Twoich kampanii marketingowych w przyszłości.
Na przykład, jeśli regularnie organizujesz konferencje, ankiety pomogą Ci dowiedzieć się, jak Ci poszło i czy Twoi uczestnicy chcą ponownie wziąć udział w konferencji. Oto przykład danych na poziomie zainteresowań:

źródło: SurveyMonkey
Zadawane pytania ujawnią poziom zainteresowania potencjalnych klientów Twoim produktem lub usługą. Poziomy zainteresowania wahają się od braku zainteresowania, niewielkiego zainteresowania, neutralnego do bardzo zainteresowanego.
2. Poziom wykształcenia
Ten typ danych porządkowych zapewnia wgląd w poziom biegłości odbiorców docelowych.
Poziom wykształcenia może pytać, czy Twoi odbiorcy docelowi uzyskali różne poziomy formalnego wykształcenia, takie jak szkoła średnia, studia wyższe i studia podyplomowe. Możesz zbierać te dane, przypisując każdemu poziomowi numery, na przykład 1 dla braku formalnego wykształcenia, 2 dla szkoły podstawowej i tak dalej, aż do 10 dla stopnia doktora.
Dane na poziomie wykształcenia są przydatne, gdy wykorzystujesz analitykę w procesie rekrutacji, aby pomóc Ci ocenić podania o pracę potencjalnych kandydatów.
Dane na poziomie edukacyjnym mogą pomóc w formułowaniu trafnych prognoz dotyczących tego, kogo zatrudnić w przyszłości, aby wspierać rozwój firmy, gdzie skoncentrować wysiłki rekrutacyjne i znaleźć odpowiednich kandydatów na określone stanowiska.
Jeśli prowadzisz zespół sprzedażowy, ocena poziomu wykształcenia członków Twojego zespołu pozwoli Ci wiedzieć, jak wspierać ich cele rozwoju zawodowego. W ten sposób możesz zbudować skuteczny zespół sprzedaży i poprawić retencję.
3. Status społeczno-ekonomiczny
Zrozumienie statusu społeczno-ekonomicznego odbiorców docelowych pomaga tworzyć i udoskonalać segmenty klientów na podstawie ich profili demograficznych i psychograficznych.
Następnie możesz polegać na tych segmentach podczas prowadzenia spersonalizowanych kampanii marketingowych, które spełniają ich potrzeby i życzenia. Porządkowe dane dotyczące statusu społeczno-ekonomicznego dla docelowych odbiorców B2C obejmują płeć, lokalizację, dochód gospodarstwa domowego, stan cywilny i wiek.
Z drugiej strony dane dla grupy docelowej B2B obejmują roczne przychody brutto, etap rozwoju biznesu, liczbę pracowników, pozycję na rynku i rodzaj branży.
4. Poziom satysfakcji
Poziom satysfakcji odzwierciedla stopień zadowolenia klientów z interakcji z różnymi markami. Na przykład proces wdrażania klienta lub to, jak dobrze rozwiązujesz różne problemy klientów.
Zadowolenie klienta można wyrazić jako bardzo zadowolony, zadowolony, niezadowolony lub bardzo niezadowolony. Dane dotyczące poziomu zadowolenia pomagają mierzyć zadowolenie z obsługi klienta i obsługi sprzedaży w celu zidentyfikowania obszarów wymagających poprawy.
Oto przykład danych dotyczących poziomu zadowolenia z badania dopasowania produktu do rynku przeprowadzonego przez firmę Buffer:
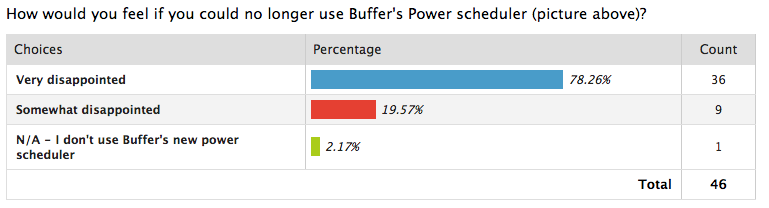
źródło: bufor
Dzięki tym danym firma mogła stwierdzić, jak przydatny jest program do planowania zasilania firmy Buffer dla swoich klientów, co oznacza, że produkt był odpowiedni dla ich użytkowników.
5. Porównanie
Obejmuje to zadawanie pytań, które ujawniają podobieństwa lub różnice między dwoma lub więcej punktami danych. Po zidentyfikowaniu podobieństw lub różnic możesz dowiedzieć się, jakie cechy są podobne, a które różne i w jakim stopniu są różne lub podobne.
Na przykład możesz chcieć porównać wyniki w zakresie przychodów w latach 2021-2022. Twoje porównanie da znacznie mniej, mniej więcej to samo, więcej i znacznie więcej dla każdego roku.
Dzięki temu możesz mierzyć trendy makroekonomiczne i branżowe oraz dostosowywać swoją strategię do procesu budżetowania, aby kontrolować wydatki. Możesz nawet zdecydować się pójść dalej i porównać trendy w branży, aby móc tworzyć raporty i pisać treści dotyczące przywództwa w celu zwiększenia świadomości marki.
Jak zbierać dane porządkowe
Jeśli poprosiłbyś kogoś o ocenę poziomu zadowolenia w skali od 1 do 5, jego odpowiedź byłaby porządkowa. Możesz zbierać te dane za pomocą ankiet lub skal Likerta za pomocą oprogramowania do ankiet.
Ankiety są jedną z najstarszych metod zbierania danych porządkowych. Możesz użyć ankiet, aby określić odczucia odbiorców docelowych na temat produktów, tematów lub konkretnych problemów związanych z Twoją marką, produktem lub usługą. Możesz ankietować na wiele sposobów, w tym osobiście, przez telefon lub online.
Jednak w przypadku ankiet zbieranie dokładnych danych od osób, które nie chcą szczerze odpowiadać na pytania lub ich rozumieć, jest trudne. Ankiety wymagają również dużo czasu ze strony badacza, aby je stworzyć, zweryfikować i przeanalizować.

Skala Likerta to ankieta, w której prosi się uczestników o wyrażenie zgody lub niezgody z każdym stwierdzeniem w ankiecie, na przykład „Zdecydowanie się nie zgadzam”. Następnie uczestnicy przydzielają sobie odpowiedź na podstawie swoich odczuć w stosunku do tego stwierdzenia i stopnia, w jakim się z nim zgadzają.
Skale Likerta poprawiają przejrzystość podczas analizy, ponieważ respondenci oceniają siebie na uporządkowanej skali z jasno określonymi przedziałami, na przykład w skali 1-7.
Aby zebrać dane porządkowe, należy uruchomić ankiety z pytaniami, które klasyfikują odpowiedzi przy użyciu jawnej lub jawnej skali. Na przykład, jeśli witryna Twojej firmy jest odwiedzana przez dużą liczbę osób, możesz użyć narzędzia do zbierania opinii o witrynach firmowych, aby zebrać opinie ze swojej witryny. Zapytać:
„Jak bardzo jesteś zadowolony z posta na blogu, który właśnie przeczytałeś?”
Możliwe odpowiedzi mogą być następujące:
- Szczęśliwy
- Nieszczęśliwy
- Zadowolona
- Niezadowolony
Testy do przeprowadzenia z danymi porządkowymi
Możesz przeprowadzić kilka testów na danych porządkowych, aby zmierzyć różnicę między dwiema lub więcej grupami. Testy te obejmują:
- Test Kruskala-Wallisa
- Test U Manna-Whitneya
- Test sumy rang Wilcoxona
- Test mediany nastroju
Dane porządkowe to typ danych, który szereguje wartości od najmniejszej do największej. Innymi słowy, dane porządkowe są uszeregowane lub uporządkowane.
Test Kruskala-Wallisa H
Test Kruskala-Wallisa jest testem nieparametrycznym stosowanym do porównywania median trzech lub więcej niezależnych grup. Jest używany, gdy dane nie mają rozkładu normalnego, a wariancja między grupami jest nierówna. Test Kruskala-Wallisa pozwala również na porównanie dwóch zależnych grup – zdjęć przed i po redesignie strony internetowej.
Test U Manna-Whitneya
Test Manna-Whitneya jest testem nieparametrycznym używanym do porównania mediany dwóch niezależnych próbek. Można go użyć, gdy istnieją dane porządkowe, takie jak oceny w skali od 1 do 5, lub gdy w danych nie ma wyraźnych grup.
Test rang podpisanych Wilcoxona
Test rang ze znakiem Wilcoxona jest testem nieparametrycznym, którego można używać do zestawów danych z rozkładem normalnym lub bez niego. Jest to alternatywa dla testu t w przypadkach, gdy dane nie mają rozkładu normalnego.
Podczas przeprowadzania testu t zakłada się, że bazowy rozkład danych jest normalny, ale to założenie może być błędne.
Na przykład, testując różnicę wzrostu między dwiema grupami, powiedzmy, że jedna grupa ma średni wzrost 180 cm, a druga 170 cm. Nie zobaczysz żadnej znaczącej różnicy w ich wysokości.
Jednak stosując test rangi podpisanej Wilcoxona, możesz zobaczyć poza zwykłą różnicą w ich wysokościach.
Mediana testu nastroju
Test opiera się na założeniu, że nastroje ludzi skupiają się wokół punktu środkowego, przy czym niektórzy są bardziej pozytywni lub negatywni niż inni. Mediana testu Mood's często mierzy, jak ludzie myślą o danym problemie lub pomyśle, na przykład o opinii klienta na temat twoich produktów lub usług. Może przewidywać zachowanie na podstawie ich nastrojów, na przykład, czy Twoi klienci będą kupować od Ciebie, czy od konkurencji.
Jak analizować dane porządkowe
Istnieją dwa sposoby analizy danych porządkowych: statystyka wnioskowania i statystyka opisowa.
Statystyki opisowe podsumowują cechy zbioru danych i identyfikują wzorce. Oto statystyki opisowe dla danych porządkowych:
- Dystrybucja częstotliwości
- Miary tendencji centralnej
- Zakres (miary zmienności)
Z drugiej strony statystyki wnioskowania przewidują, co może się wydarzyć w przyszłości na podstawie posiadanych danych. Możesz używać danych porządkowych do zbierania spostrzeżeń, tworzenia hipotez, a nawet wyciągania wniosków za pomocą czterech opisanych powyżej testów.
Wszystkie testy Kruskala-Wallisa, U Manna Whitneya i Wilcoxona analizują dane porządkowe. Wszystkie są testami nieparametrycznymi, co oznacza, że nie opierają się na żadnych założeniach dotyczących dystrybucji danych.
Analityka opisowa
Analityka opisowa gromadzi, analizuje i raportuje dane o zdarzeniach, które już miały miejsce. Różni się to od analizy predykcyjnej, która przewiduje przyszłe zdarzenia na podstawie danych historycznych. Analityka opisowa pomaga firmom identyfikować wzorce w przeszłości, aby usprawnić podejmowanie decyzji w przyszłości.
W analityce opisowej celem jest znalezienie wzorców w istniejących danych, a nie przewidywanie, co stanie się w przyszłości. Analityka opisowa ma na celu znalezienie związków przyczynowo-skutkowych między przeszłymi zdarzeniami i wykorzystanie tych związków do przewidywania przyszłych zdarzeń.
W przeciwieństwie do innych metod analitycznych, analizy opisowej można używać w dowolnym momencie, z dowolnymi dostępnymi danymi. Dzięki temu jest bardziej dostępny dla mniejszych firm, które nie mają wystarczających zasobów na modele predykcyjne lub duże zbiory danych wymagane innymi metodami.
Wykresy
Słupki i wykresy przedstawiają dane w sposób łatwy do zrozumienia. Są przydatne, gdy dane są zbyt duże lub skomplikowane, aby można je było wyświetlić w tabeli. Typ wykresu, który wybierzesz, zależy od ilości informacji, które chcesz przekazać, wymiarów danych i odbiorców.
Wykresy słupkowe przedstawiają informacje w postaci słupków o długości proporcjonalnej do ich wartości. Są używane, gdy dane są kategoryczne, co oznacza, że należą do określonych grup. Oto wykres słupkowy dla call center, pokazujący czas potrzebny na odpowiedź każdego dnia tygodnia:
źródło: Datapin
To dobry wybór, gdy chcesz, aby Twoi odbiorcy mogli łatwo porównywać wartości. Wykresy słupkowe są bardziej intuicyjne i łatwiejsze do zrozumienia w porównaniu z liczbami. Możliwe jest również użycie słupków w połączeniu z liniami lub innymi elementami graficznymi, takimi jak wykresy punktowe, histogramy lub wykresy kołowe.
Wykresy liniowe są używane, gdy dane mają uporządkowaną wartość. Te wykresy wykorzystują linie do łączenia punktów na dwóch osiach z tą samą skalą po obu stronach. Linie te mogą być ciągłe lub kropkowane i rozpoczynać się w dowolnym punkcie na dowolnej osi.
Linie reprezentują zmiany w czasie, takie jak codzienne wahania giełdy lub zmiany kosztów energii z roku na rok. Oto przykład miesięcznych przychodzących potencjalnych klientów w ciągu 12 miesięcy zwizualizowanych za pomocą wykresu liniowego:

Miary tendencji centralnej
Tendencja centralna to średnia zbioru liczb. Mierzy, jak blisko liczby w zbiorze danych są skupione wokół ich średniej.
Trzy główne typy tendencji centralnej to średnia, mediana i tryb. Najczęstszą miarą tendencji centralnej jest średnia arytmetyczna, obliczana przez dodanie wszystkich wartości w zbiorze danych i podzielenie tej sumy przez liczbę wartości w tym zbiorze danych.
Mediany można również użyć jako alternatywy dla obliczania tendencji centralnej, po prostu znajdując średnią wartość w zbiorze danych po ułożeniu wszystkich liczb od najniższej do najwyższej. Tryb jest najczęściej występującą wartością w zestawie.
Kluczowe dania na wynos
Dane porządkowe są bardziej złożone niż dane nominalne i są powszechnie używane do mierzenia zainteresowania. Skala Likerta jest popularnym przykładem danych porządkowych.
Wykorzystaj niektóre z przedstawionych tutaj prawdziwych przykładów, aby zainspirować się do własnego zbierania danych ankietowych. Przy okazji dowiedz się więcej o sondowaniu i o tym, jak pomaga ono zbierać dane.