
Données ordinales : définition, exemples, collecte et analyse
Publié: 2023-03-24Les entreprises investissent davantage dans les outils de données pour aider leurs équipes marketing à prendre de meilleures décisions.
Mais le marketing a besoin de plus que de simples outils de données et d'analyse pour mettre en œuvre une stratégie marketing efficace. Ils doivent également comprendre le type de données qu'ils collectent et comment les analyser pour obtenir des informations significatives.
Cela implique de revenir aux bases et de comprendre les données ordinales, l'un des principaux types de données marketing. Cet article explorera les données ordinales et comment elles éclairent les décisions marketing basées sur les données.
Qu'est-ce qu'une donnée ordinale ?
Les données ordinales sont des données quantitatives dans lesquelles les variables sont organisées en catégories ordonnées, comme un classement de 1 à 10. Cependant, les variables n'ont pas d'intervalle clair entre elles et les valeurs des données ordinales n'ont pas toujours une distribution égale.
Le niveau de satisfaction client est un exemple de données ordinales. Ses variables pourraient être :
- Très satisfait
- Satisfait
- Neutre
- Mécontent
- Très insatisfait
À l'aide de données ordinales, vous pouvez calculer la fréquence, la distribution, le mode, la médiane et la plage de variables.
Après avoir défini les données ordinales, vous pouvez vous poser des questions sur d'autres types de données, telles que les données nominales, d'intervalle ou de ratio. En quoi diffèrent-elles des données ordinales ? Voici quelques définitions rapides :
- Les données nominales sont une classification de données dont les variables ont un ensemble fini de valeurs et de catégories qui ne sont pas ordonnées. Avec les données nominales, vous mesurez des variables telles que le type d'emploi, qui a plusieurs résultats, tels que le travail indépendant, à temps plein ou hybride.
- Les données d'intervalle sont un type de données où l'intervalle entre deux valeurs n'est pas constant. Les données d'intervalle apparaissent de plusieurs manières, par exemple lors de la mesure d'intervalles de temps ou lorsque la différence entre deux mesures varie. La manière la plus courante de représenter les données d'intervalle consiste à utiliser un tableau avec des colonnes pour les limites supérieure et inférieure de chaque plage.
- Les données de ratio sont un type de données utilisé pour l'analyse statistique. Les données de ratio ne fournissent aucune information sur les valeurs qu'elles représentent. Ces informations doivent être obtenues à partir d'autres sources référencées par les données de ratio. Il est souvent utilisé dans l'analyse d'informations financières mais peut également être appliqué à d'autres types de données.
5 exemples de données ordinales
Les données ordinales se présentent sous différents formats. Voici quelques exemples de données ordinales et comment les synchroniser avec votre stratégie commerciale pour améliorer vos efforts de gestion des données.
1. Niveau d'intérêt
Que vous ayez déjà lancé votre produit sur le marché ou introduit de nouvelles fonctionnalités dans votre produit existant, vous devrez effectuer une étude de marché pour poser des questions afin d'évaluer l'intérêt de votre public cible.
L'étude de marché consiste à analyser des données qualitatives et quantitatives pour comprendre les besoins des clients, leurs partenaires d'achat et ce qui les motive à acheter chez vous. Ces informations peuvent vous aider à améliorer vos campagnes marketing à l'avenir.
Par exemple, si vous organisez régulièrement des conférences, les sondages peuvent vous aider à savoir si vous avez bien réussi et si vos participants souhaitent assister à nouveau à la conférence. Voici un exemple de données sur les centres d'intérêt :

Source : SurveyMonkey
Les questions que vous posez révéleront le niveau d'intérêt des clients potentiels pour votre produit ou service. Les niveaux d'intérêt vont de pas intéressé, peu intéressé, neutre à très intéressé.
2. Niveau d'éducation
Ce type de données ordinales fournit des informations sur le niveau de compétence de votre public cible.
Le niveau d'éducation peut demander si votre public cible a acquis différents niveaux d'éducation formelle, comme le lycée, l'université et les études supérieures. Vous pouvez collecter ces données en attribuant des numéros à chaque niveau, comme 1 pour aucune éducation formelle, 2 pour l'enseignement primaire, etc., jusqu'à 10 pour un doctorat universitaire.
Les données au niveau de l'éducation sont utiles lorsque vous utilisez des analyses dans votre processus de recrutement pour vous aider à évaluer les candidatures de candidats potentiels.
Les données de niveau éducatif peuvent vous aider à faire de puissantes prédictions sur qui embaucher à l'avenir pour soutenir la croissance de l'entreprise, où concentrer vos efforts de recrutement et trouver des candidats appropriés pour des postes spécifiques.
Si vous dirigez une équipe de vente, évaluer le niveau d'éducation des membres de votre équipe vous permet de savoir comment soutenir leurs objectifs de développement de carrière. De cette façon, vous pouvez constituer une équipe de vente performante et améliorer la fidélisation.
3. Statut socio-économique
Comprendre le statut socio-économique de votre public cible permet de créer et d'affiner vos segments de clientèle en fonction de leurs profils démographiques et psychographiques.
Vous pouvez ensuite compter sur ces segments lors de l'exécution de campagnes marketing personnalisées qui répondent à leurs besoins et désirs. Les données ordinales sur le statut socio-économique d'un public cible B2C incluent le sexe, le lieu, le revenu du ménage, l'état matrimonial et l'âge.
D'autre part, les données pour un public cible B2B comprennent le revenu annuel brut, le stade de croissance de l'entreprise, le nombre d'employés, la position sur le marché et le type d'industrie.
4. Niveau de satisfaction
Le niveau de satisfaction reflète à quel point vos clients sont satisfaits des différentes interactions avec la marque. Par exemple, votre processus d'intégration des clients ou la façon dont vous résolvez les différents problèmes des clients.
La satisfaction du client peut être exprimée comme extrêmement satisfaite, satisfaite, insatisfaite ou extrêmement insatisfaite. Les données sur le niveau de satisfaction vous aident à évaluer la satisfaction du service client et de la gestion des ventes afin d'identifier les domaines à améliorer.
Voici un exemple de données sur le niveau de satisfaction d'une enquête sur l'adéquation produit-marché menée par Buffer :
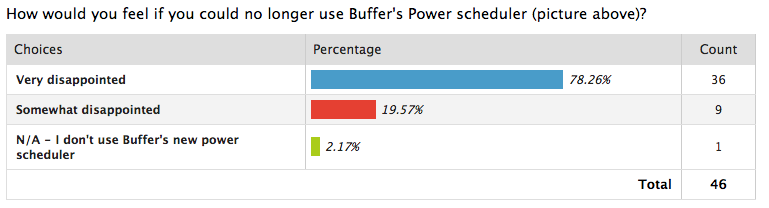
Source : Tampon
Avec ces données, l'entreprise a pu dire à quel point le planificateur d'alimentation de Buffer était utile à ses clients, ce qui signifie que le produit était le bon choix pour leurs utilisateurs.
5. Comparaison
Cela implique de poser des questions qui révèlent les similitudes ou les différences entre deux ou plusieurs points de données. Une fois que vous avez identifié les similitudes ou les différences, vous pouvez savoir quelles caractéristiques sont similaires, lesquelles sont différentes et dans quelle mesure elles sont différentes ou similaires.
Par exemple, vous pouvez comparer les performances des revenus de 2021 à 2022. Votre comparaison produira beaucoup moins, à peu près la même chose, plus et beaucoup plus pour les revenus de chaque année.
Grâce à cela, vous pouvez évaluer les tendances macroéconomiques et sectorielles et ajuster votre stratégie en fonction de votre processus de budgétisation afin de contrôler les dépenses. Vous pouvez même décider d'aller plus loin et de comparer les tendances de l'industrie afin de pouvoir créer des rapports et rédiger du contenu de leadership éclairé pour accroître la notoriété de la marque.
Comment collecter des données ordinales
Si vous demandiez à quelqu'un de classer son niveau de satisfaction sur une échelle de 1 à 5, sa réponse serait ordinale. Vous pouvez collecter ces données via des enquêtes ou des échelles de Likert à l'aide d'un logiciel d'enquête.
Les enquêtes sont l'une des plus anciennes méthodes de collecte de données ordinales. Vous pouvez utiliser des sondages pour déterminer les sentiments de votre public cible à propos de produits, de sujets ou de problèmes spécifiques liés à votre marque, produit ou service. Vous pouvez sonder avec de nombreuses méthodes, y compris en personne, par téléphone ou en ligne.
Avec les enquêtes, cependant, il est difficile de collecter des données précises auprès de personnes qui ne veulent pas répondre honnêtement aux questions ou les comprendre. Les enquêtes demandent également beaucoup de temps de la part du chercheur pour les créer, les valider et les analyser.

Une échelle de Likert est une enquête qui demande aux participants d'être d'accord ou en désaccord avec chaque énoncé de l'enquête, par exemple, « Je ne suis pas du tout d'accord ». Les participants s'attribuent ensuite une réponse en fonction de leurs sentiments à l'égard de l'énoncé et de leur niveau d'accord avec celui-ci.
Les échelles de Likert améliorent la clarté lors de l'analyse car les répondants s'évaluent sur une échelle ordonnée avec des intervalles clairement définis, par exemple, une échelle de 1 à 7.
Pour collecter des données ordinales, vous devez exécuter des enquêtes avec des questions qui classent les réponses à l'aide d'une échelle implicite ou explicite. Par exemple, si vous avez beaucoup de trafic sur le site Web de votre entreprise, vous pouvez utiliser un outil de commentaires sur le site Web de l'entreprise pour recueillir les commentaires de votre site Web. Demander:
"Dans quelle mesure êtes-vous satisfait de l'article de blog que vous venez de lire ?"
Les réponses possibles pourraient être :
- Content
- Malheureux
- Satisfait
- Insatisfait
Tests à réaliser avec des données ordinales
Vous pouvez effectuer plusieurs tests sur des données ordinales pour mesurer la différence entre deux ou plusieurs groupes. Ces épreuves comprennent :
- Le test de Kruskal-Wallis
- Le test U de Mann-Whitney
- Test de somme des rangs de Wilcoxon
- Test médian de l'humeur
Les données ordinales sont un type de données qui classe les valeurs du plus petit au plus grand. En d'autres termes, les données ordinales sont classées ou ordonnées.
Essai de Kruskal-Wallis H
Le test de Kruskal-Wallis est un test non paramétrique utilisé pour comparer les médianes de trois groupes indépendants ou plus. Il est utilisé lorsque les données ne sont pas distribuées normalement et que la variance entre les groupes est inégale. Le test Kruskal-Wallis peut également comparer deux groupes dépendants - avant et après les photos d'une refonte de site Web.
Test U de Mann-Whitney
Le test de Mann-Whitney est un test non paramétrique utilisé pour comparer la médiane de deux échantillons indépendants. Il peut être utilisé lorsqu'il existe des données ordinales, telles que des notes sur une échelle de 1 à 5, ou lorsqu'il n'y a pas de groupes clairs dans les données.
Test de rang signé de Wilcoxon
Le test de rang signé de Wilcoxon est un test non paramétrique qui peut être utilisé pour des ensembles de données avec ou sans distribution normale. C'est une alternative au test t dans les cas où les données n'ont pas une distribution normale.
Lors de l'exécution d'un test t, l'hypothèse est que la distribution sous-jacente des données est normale, mais cette hypothèse peut être erronée.
Par exemple, lorsque vous testez la différence de taille entre deux groupes, disons qu'un groupe a une taille moyenne de 180 cm et l'autre groupe a 170 cm. Vous ne verrez aucune différence significative dans leurs hauteurs.
Cependant, en utilisant le test de classement signé de Wilcoxon, vous pouvez voir au-delà de la différence régulière de leurs hauteurs.
Test médian de l'humeur
Le test est basé sur la prémisse que les humeurs des gens se regroupent autour d'un point médian, certaines étant plus positives ou négatives que d'autres. Le test médian de Mood mesure souvent ce que les individus pensent d'un problème ou d'une idée, comme l'opinion de votre client sur vos produits ou services. Il peut prédire le comportement en fonction de leur humeur, par exemple si vos clients achèteront chez vous ou chez vos concurrents.
Comment analyser des données ordinales
Il existe deux façons d'analyser les données ordinales : les statistiques inférentielles et descriptives.
Les statistiques descriptives résument les caractéristiques d'un ensemble de données et identifient des modèles. Voici les statistiques descriptives pour les données ordinales :
- Répartition des fréquences
- Mesures de tendance centrale
- Gamme (mesures de la variabilité)
Les statistiques inférentielles , quant à elles, prédisent ce qui pourrait se passer dans le futur en fonction des données dont vous disposez. Vous pouvez utiliser des données ordinales pour collecter des informations, créer des hypothèses ou même tirer des conclusions avec les quatre tests décrits ci-dessus.
Les tests de somme des rangs signés de Kruskal-Wallis, Mann Whitney U et Wilcoxon analysent tous les données ordinales. Ce sont tous des tests non paramétriques, ce qui signifie qu'ils ne reposent sur aucune hypothèse concernant la distribution des données.
Analyse descriptive
L'analyse descriptive collecte, analyse et rapporte des données sur les événements qui se sont déjà produits. Cela diffère de l'analyse prédictive, qui prédit les événements futurs sur la base de données historiques. L'analyse descriptive aide les entreprises à identifier des modèles dans le passé pour améliorer leur prise de décision future.
Dans l'analyse descriptive, l'objectif est de trouver des modèles dans les données existantes, et non de prédire ce qui se passera dans le futur. L'analyse descriptive vise à trouver des relations de cause à effet entre des événements passés et à utiliser ces relations pour prédire des événements futurs.
Contrairement à d'autres méthodes d'analyse, l'analyse descriptive peut être utilisée à tout moment avec toutes les données disponibles. Cela le rend plus accessible aux petites entreprises disposant de ressources insuffisantes pour les modèles prédictifs ou de grands ensembles de données requis par d'autres méthodes.
Graphiques
Les barres et les graphiques présentent les données d'une manière facile à comprendre. Ils sont utiles lorsque les données sont trop volumineuses ou compliquées pour être affichées dans un tableau. Le type de graphique que vous choisissez dépend de la quantité d'informations que vous souhaitez transmettre, des dimensions des données et de votre public.
Les graphiques à barres affichent les informations sous forme de barres dont la longueur est proportionnelle à leurs valeurs. Ils sont utilisés lorsque les données sont catégorielles, ce qui signifie qu'elles appartiennent à des groupes spécifiques. Voici un graphique à barres pour un centre d'appels, indiquant le temps nécessaire pour répondre chaque jour de la semaine :
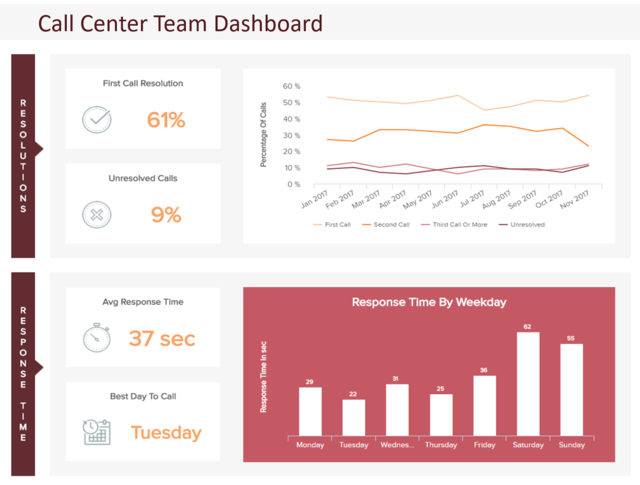
Source : Datapine
C'est un bon choix lorsque vous souhaitez que votre public puisse facilement comparer les valeurs. Les graphiques à barres sont plus intuitifs et plus faciles à comprendre que les chiffres. Il est également possible d'utiliser des barres en combinaison avec des lignes ou d'autres graphiques, comme des nuages de points, des histogrammes ou des camemberts.
Les graphiques linéaires sont utilisés lorsque les données ont une valeur ordonnée. Ces graphiques utilisent des lignes pour relier des points sur deux axes avec la même échelle des deux côtés. Ces lignes peuvent être pleines ou en pointillés et commencer à n'importe quel point sur l'un ou l'autre des axes.
Les lignes représentent les changements au fil du temps, comme la façon dont le marché boursier fluctue quotidiennement ou la façon dont le coût de l'énergie change d'année en année. Voici un exemple de prospects entrants mensuels sur 12 mois visualisés à l'aide d'un graphique linéaire :

Mesures de tendance centrale
La tendance centrale est la moyenne d'un ensemble de nombres. Il mesure à quel point les nombres d'un ensemble de données sont regroupés autour de leur moyenne.
Les trois principaux types de tendance centrale sont la moyenne, la médiane et le mode. La mesure la plus courante de la tendance centrale est la moyenne arithmétique, calculée en additionnant toutes les valeurs de l'ensemble de données et en divisant cette somme par le nombre de valeurs de cet ensemble de données.
La médiane peut également être utilisée comme alternative au calcul de la tendance centrale, en trouvant simplement la valeur médiane dans un ensemble de données après avoir organisé tous les nombres de bas en haut. Le mode est la valeur la plus fréquente dans un ensemble.
Points clés à retenir
Les données ordinales sont plus complexes que les données nominales et couramment utilisées pour évaluer l'intérêt. L'échelle de Likert est un exemple populaire de données ordinales.
Utilisez certains des exemples réels fournis ici pour inspirer votre propre collecte de données d'enquête. Pendant que vous y êtes, apprenez-en plus sur les sondages et comment ils aident à collecter des données.