
Ordinale Daten: Definition, Beispiele, Sammlung und Analyse
Veröffentlicht: 2023-03-24Unternehmen investieren mehr in Datentools, um ihren Marketingteams zu helfen, bessere Entscheidungen zu treffen.
Aber Marketing braucht mehr als nur Daten und Analysetools, um eine effektive Marketingstrategie umzusetzen. Sie müssen auch verstehen, welche Art von Daten sie sammeln und wie sie sie analysieren, um aussagekräftige Erkenntnisse zu gewinnen.
Dazu gehört, zu den Grundlagen zurückzukehren und Ordinaldaten zu verstehen, einen der wichtigsten Marketingdatentypen. In diesem Artikel werden ordinale Daten untersucht und wie sie datengesteuerte Marketingentscheidungen beeinflussen.
Was sind ordinale Daten?
Ordinale Daten sind quantitative Daten, in denen Variablen in geordneten Kategorien organisiert sind, z. B. eine Rangfolge von 1 bis 10. Den Variablen fehlt jedoch ein klares Intervall zwischen ihnen, und Werte in ordinalen Daten sind nicht immer gleichmäßig verteilt.
Der Grad der Kundenzufriedenheit ist ein Beispiel für ordinale Daten. Seine Variablen könnten sein:
- Sehr zufrieden
- Befriedigt
- Neutral
- Unzufrieden
- Sehr unzufrieden
Mit ordinalen Daten können Sie Häufigkeit, Verteilung, Modus, Median und Bereich von Variablen berechnen.
Nachdem Sie ordinale Daten definiert haben, wundern Sie sich vielleicht über andere Datentypen wie Nominal-, Intervall- oder Verhältnisdaten. Wie unterscheiden sie sich von ordinalen Daten? Hier sind einige kurze Definitionen:
- Nominaldaten sind eine Klassifizierung von Daten, deren Variablen einen endlichen Satz von Werten und Kategorien haben, die nicht geordnet sind. Mit nominalen Daten messen Sie Variablen wie die Art der Beschäftigung, die mehrere Ergebnisse hat, z. B. freiberufliche, Vollzeit- oder Mischarbeit.
- Intervalldaten sind ein Datentyp, bei dem das Intervall zwischen zwei Werten nicht konstant ist. Intervalldaten entstehen auf vielfältige Weise, zum Beispiel beim Messen von Zeitintervallen oder wenn die Differenz zwischen zwei Messungen variiert. Die gebräuchlichste Methode zur Darstellung von Intervalldaten ist die Verwendung einer Tabelle mit Spalten für die oberen und unteren Grenzen jedes Bereichs.
- Verhältnisdaten sind ein Datentyp, der für statistische Analysen verwendet wird. Die Verhältnisdaten geben keine Auskunft über die Werte, die sie darstellen. Diese Informationen müssen aus anderen Quellen bezogen werden, auf die die Verhältnisdaten verweisen. Es wird häufig bei der Analyse von Finanzinformationen verwendet, kann aber auch auf andere Arten von Daten angewendet werden.
5 Beispiele für ordinale Daten
Ordinale Daten treten in verschiedenen Formaten auf. Hier sind einige Beispiele für ordinale Daten und wie Sie sie mit Ihrer Geschäftsstrategie synchronisieren können, um Ihre Datenverwaltung zu verbessern.
1. Zinsniveau
Unabhängig davon, ob Sie Ihr Produkt bereits auf den Markt gebracht haben oder neue Funktionen für Ihr vorhandenes Produkt einführen, müssen Sie Marktforschung betreiben, um Fragen zu stellen und das Interesse Ihrer Zielgruppe einzuschätzen.
Marktforschung umfasst die Analyse sowohl qualitativer als auch quantitativer Daten, um die Kundenbedürfnisse, ihre Kaufpartner und ihre Motivation, bei Ihnen zu kaufen, zu verstehen. Diese Erkenntnisse können dazu beitragen, Ihre Marketingkampagnen in Zukunft zu verbessern.
Wenn Sie beispielsweise regelmäßig Konferenzen veranstalten, können Ihnen Umfragen dabei helfen zu wissen, wie gut Sie abgeschnitten haben und ob Ihre Teilnehmer die Konferenz erneut besuchen möchten. Hier ist ein Beispiel für Daten auf Interessenebene:

Quelle: SurveyMonkey
Die Fragen, die Sie stellen, zeigen das Interesse potenzieller Kunden an Ihrem Produkt oder Ihrer Dienstleistung. Das Interesse reicht von nicht interessiert, leicht interessiert, neutral bis sehr interessiert.
2. Bildungsniveau
Diese Art von Ordinaldaten bietet Einblicke in das Leistungsniveau Ihrer Zielgruppe.
Bildungsniveau kann erfragen, ob Ihre Zielgruppe verschiedene Bildungsniveaus erworben hat, z. B. High School, College und Graduate School. Sie können diese Daten sammeln, indem Sie jedem Niveau Nummern zuweisen, z. B. 1 für keine formale Bildung, 2 für Grundschulbildung usw. bis 10 für einen Doktortitel an einer Universität.
Daten auf Bildungsebene sind praktisch, wenn Sie Analysen in Ihrem Rekrutierungsprozess verwenden, um Ihnen bei der Bewertung der Bewerbungen potenzieller Kandidaten zu helfen.
Daten auf Bildungsebene können Ihnen dabei helfen, aussagekräftige Vorhersagen darüber zu treffen, wen Sie in Zukunft einstellen sollten, um das Unternehmenswachstum zu unterstützen, worauf Sie Ihre Rekrutierungsbemühungen konzentrieren und geeignete Kandidaten für bestimmte Positionen finden können.
Wenn Sie ein Vertriebsteam leiten, können Sie durch die Bewertung des Bildungsniveaus Ihrer Teammitglieder wissen, wie Sie ihre Karriereentwicklungsziele unterstützen können. Auf diese Weise können Sie ein leistungsstarkes Vertriebsteam aufbauen und die Kundenbindung verbessern.
3. Sozioökonomischer Status
Das Verständnis des sozioökonomischen Status Ihrer Zielgruppe hilft dabei, Ihre Kundensegmente basierend auf ihren demografischen und psychografischen Profilen zu erstellen und zu verfeinern.
Sie können sich dann auf diese Segmente verlassen, wenn Sie personalisierte Marketingkampagnen durchführen, die ihren Bedürfnissen und Wünschen entsprechen. Ordinale Daten zum sozioökonomischen Status einer B2C-Zielgruppe umfassen Geschlecht, Wohnort, Haushaltseinkommen, Familienstand und Alter.
Auf der anderen Seite umfassen Daten für eine B2B-Zielgruppe den jährlichen Bruttoumsatz, die Phase des Unternehmenswachstums, die Anzahl der Mitarbeiter, die Marktposition und die Art der Branche.
4. Zufriedenheitsgrad
Das Zufriedenheitsniveau spiegelt wider, wie zufrieden Ihre Kunden mit verschiedenen Markeninteraktionen sind. Zum Beispiel Ihr Kunden-Onboarding-Prozess oder wie gut Sie verschiedene Kundenprobleme lösen.
Die Kundenzufriedenheit kann als äußerst zufrieden, zufrieden, unzufrieden oder äußerst unzufrieden ausgedrückt werden. Daten zur Zufriedenheitsstufe helfen Ihnen dabei, die Zufriedenheit mit Kundenservice und Verkaufsabwicklung zu messen, um Bereiche mit Verbesserungspotenzial zu identifizieren.
Hier ist ein Beispiel für Zufriedenheitsdaten aus einer Produkt-Market-Fit-Umfrage, die Buffer durchgeführt hat:
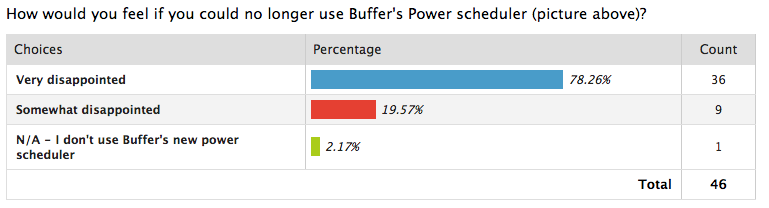
Quelle: Puffer
Anhand dieser Daten konnte das Unternehmen feststellen, wie nützlich der Power Scheduler von Buffer für seine Kunden ist, was bedeutet, dass das Produkt genau das Richtige für seine Benutzer war.
5. Vergleich
Dabei werden Fragen gestellt, die Ähnlichkeiten oder Unterschiede zwischen zwei oder mehr Datenpunkten aufzeigen. Sobald Sie die Ähnlichkeiten oder Unterschiede identifiziert haben, können Sie erfahren, welche Merkmale ähnlich und welche unterschiedlich sind und inwieweit sie unterschiedlich oder ähnlich sind.
Beispielsweise möchten Sie möglicherweise die Umsatzentwicklung von 2021 bis 2022 vergleichen. Ihr Vergleich ergibt deutlich weniger, ungefähr den gleichen, mehr und deutlich mehr Umsatz für jedes Jahr.
Damit können Sie makroökonomische und branchenspezifische Trends einschätzen und Ihre Strategie an Ihren Budgetierungsprozess anpassen, um die Ausgaben zu kontrollieren. Sie können sich sogar dafür entscheiden, dies weiter zu gehen und Branchentrends zu vergleichen, damit Sie Berichte erstellen und Vordenkerinhalte schreiben können, um die Markenbekanntheit zu steigern.
So sammeln Sie ordinale Daten
Wenn Sie jemanden bitten würden, seine Zufriedenheit auf einer Skala von 1 bis 5 einzustufen, wäre seine Antwort ordinal. Sie können diese Daten durch Umfragen oder Likert-Skalen mithilfe von Umfragesoftware sammeln.
Umfragen sind eine der ältesten Methoden zur Erhebung ordinaler Daten. Sie können Umfragen verwenden, um die Meinung Ihrer Zielgruppe zu Produkten, Themen oder bestimmten Problemen im Zusammenhang mit Ihrer Marke, Ihrem Produkt oder Ihrer Dienstleistung zu ermitteln. Sie können mit vielen Methoden Umfragen durchführen, einschließlich persönlich, telefonisch oder online.
Bei Umfragen ist es jedoch schwierig, genaue Daten von Personen zu sammeln, die Fragen nicht ehrlich beantworten oder sie nicht verstehen wollen. Umfragen erfordern auch viel Zeit auf Seiten des Forschers, um sie zu erstellen, zu validieren und zu analysieren.

Eine Likert-Skala ist eine Umfrage, bei der die Teilnehmer aufgefordert werden, jeder Aussage in der Umfrage zuzustimmen oder nicht zuzustimmen, z. B. „Ich stimme überhaupt nicht zu“. Die Teilnehmer weisen sich dann eine Antwort zu, die auf ihren Gefühlen gegenüber der Aussage und ihrer Zustimmung zu ihr basiert.
Likert-Skalen verbessern die Übersichtlichkeit bei der Analyse, da die Befragten sich selbst auf einer geordneten Skala mit klar definierten Intervallen bewerten, beispielsweise einer Skala von 1-7.
Um ordinale Daten zu sammeln, müssen Sie Umfragen mit Fragen durchführen, die Antworten anhand einer impliziten oder expliziten Skala ordnen. Wenn Sie beispielsweise viele Zugriffe auf die Website Ihres Unternehmens haben, können Sie ein Feedback-Tool für Unternehmenswebsites verwenden, um Feedback von Ihrer Website zu sammeln. Fragen:
„Wie zufrieden sind Sie mit dem Blogbeitrag, den Sie gerade gelesen haben?“
Mögliche Antworten könnten sein:
- Glücklich
- Unzufrieden
- Befriedigt
- Nicht zufrieden
Durchzuführende Tests mit ordinalen Daten
Sie können mehrere Tests mit ordinalen Daten durchführen, um den Unterschied zwischen zwei oder mehr Gruppen zu messen. Diese Tests umfassen:
- Der Kruskal-Wallis-Test
- Der Mann-Whitney-U-Test
- Wilcoxon-Rangsummentest
- Moods Median-Test
Ordinale Daten sind ein Datentyp, der Werte vom kleinsten zum größten ordnet. Mit anderen Worten, ordinale Daten werden geordnet oder geordnet.
Kruskal-Wallis-H-Test
Der Kruskal-Wallis-Test ist ein nichtparametrischer Test, der verwendet wird, um die Mediane von drei oder mehr unabhängigen Gruppen zu vergleichen. Es wird verwendet, wenn die Daten nicht normalverteilt sind und die Varianz zwischen den Gruppen ungleich ist. Der Kruskal-Wallis-Test kann auch zwei abhängige Gruppen vergleichen – Vorher- und Nachher-Bilder einer Website-Umgestaltung.
Mann-Whitney-U-Test
Der Mann-Whitney-Test ist ein nichtparametrischer Test, der verwendet wird, um den Median zweier unabhängiger Stichproben zu vergleichen. Es kann verwendet werden, wenn ordinale Daten vorhanden sind, z. B. Bewertungen auf einer Skala von 1 bis 5, oder wenn die Daten keine eindeutigen Gruppen enthalten.
Wilcoxon-Vorzeichen-Rang-Test
Der Wilcoxon-Vorzeichen-Rang-Test ist ein nichtparametrischer Test, der für Datensätze mit oder ohne Normalverteilung verwendet werden kann. Es ist eine Alternative zum t-Test in Fällen, in denen die Daten keine Normalverteilung aufweisen.
Beim Ausführen eines t-Tests wird davon ausgegangen, dass die zugrunde liegende Verteilung der Daten normal ist, aber diese Annahme kann falsch sein.
Wenn Sie beispielsweise den Größenunterschied zwischen zwei Gruppen testen, nehmen wir an, dass eine Gruppe eine durchschnittliche Größe von 180 cm und die andere Gruppe 170 cm hat. Sie werden keinen signifikanten Unterschied in ihrer Höhe feststellen.
Mit dem Wilcoxon-Vorzeichen-Rang-Test können Sie jedoch über den regulären Unterschied in ihrer Höhe hinaussehen.
Stimmungsmediantest
Der Test basiert auf der Prämisse, dass sich die Stimmungen der Menschen um einen Medianpunkt gruppieren, wobei einige positiver oder negativer sind als andere. Der Mood's Median Test misst oft, wie Einzelpersonen zu einem Thema oder einer Idee stehen, wie z. B. die Meinung Ihrer Kunden zu Ihren Produkten oder Dienstleistungen. Es kann das Verhalten basierend auf ihrer Stimmung vorhersagen, z. B. ob Ihre Kunden bei Ihnen oder bei Ihren Konkurrenten kaufen werden.
So analysieren Sie ordinale Daten
Es gibt zwei Möglichkeiten, ordinale Daten zu analysieren: Inferenzstatistik und deskriptive Statistik.
Deskriptive Statistiken fassen die Merkmale eines Datensatzes zusammen und identifizieren Muster. Hier sind die deskriptiven Statistiken für ordinale Daten:
- Häufigkeitsverteilung
- Maße der zentralen Tendenz
- Bereich (Maße der Variabilität)
Inferenzstatistiken hingegen sagen auf der Grundlage der Ihnen vorliegenden Daten voraus, was in Zukunft passieren könnte. Mit den vier oben beschriebenen Tests können Sie ordinale Daten verwenden, um Erkenntnisse zu sammeln, Hypothesen zu erstellen oder sogar Schlussfolgerungen zu ziehen.
Die Vorzeichen-Rangsummen-Tests von Kruskal-Wallis, Mann Whitney U und Wilcoxon analysieren alle ordinale Daten. Sie sind alle nichtparametrische Tests, was bedeutet, dass sie sich nicht auf Annahmen über die Datenverteilung verlassen.
Beschreibende Analytik
Descriptive Analytics sammelt, analysiert und meldet Daten über bereits eingetretene Ereignisse. Dies unterscheidet sich von Predictive Analytics, die zukünftige Ereignisse auf der Grundlage historischer Daten vorhersagen. Descriptive Analytics hilft Unternehmen, Muster in der Vergangenheit zu erkennen, um ihre zukünftige Entscheidungsfindung zu verbessern.
Bei der deskriptiven Analytik besteht das Ziel darin, Muster in vorhandenen Daten zu finden, nicht vorherzusagen, was in der Zukunft passieren wird. Descriptive Analytics zielt darauf ab, Ursache-Wirkungs-Beziehungen zwischen vergangenen Ereignissen zu finden und diese Beziehungen zu nutzen, um zukünftige Ereignisse vorherzusagen.
Im Gegensatz zu anderen Analysemethoden kann die deskriptive Analytik jederzeit mit allen verfügbaren Daten verwendet werden. Dies macht es für kleinere Unternehmen mit unzureichenden Ressourcen für Vorhersagemodelle oder große Datensätze, die für andere Methoden erforderlich sind, zugänglicher.
Grafiken
Balken und Diagramme stellen Daten leicht verständlich dar. Sie sind nützlich, wenn die Daten zu groß oder zu kompliziert sind, um sie in einer Tabelle anzuzeigen. Welchen Diagrammtyp Sie wählen, hängt von der Informationsmenge ab, die Sie vermitteln möchten, den Datendimensionen und Ihrer Zielgruppe.
Balkendiagramme zeigen Informationen als Balken an, deren Länge proportional zu ihren Werten ist. Sie werden verwendet, wenn die Daten kategorial sind, d. h. sie in bestimmte Gruppen fallen. Hier ist ein Balkendiagramm für ein Callcenter, das die Antwortzeit an jedem Wochentag zeigt:
Quelle: Datapine
Sie sind eine gute Wahl, wenn Sie möchten, dass Ihr Publikum Werte einfach vergleichen kann. Balkendiagramme sind im Vergleich zu Zahlen intuitiver und leichter zu verstehen. Es ist auch möglich, Balken in Kombination mit Linien oder anderen Grafiken wie Streudiagrammen, Histogrammen oder Tortendiagrammen zu verwenden.
Liniendiagramme werden verwendet, wenn die Daten einen geordneten Wert haben. Diese Diagramme verwenden Linien, um Punkte auf zwei Achsen mit demselben Maßstab auf beiden Seiten zu verbinden. Diese Linien können durchgezogen oder gepunktet sein und an jedem Punkt auf jeder Achse beginnen.
Die Linien stellen Veränderungen im Laufe der Zeit dar, z. B. wie der Aktienmarkt täglich schwankt oder wie sich die Energiekosten von Jahr zu Jahr ändern. Hier ist ein Beispiel für monatlich eingehende Leads über 12 Monate, die mithilfe eines Liniendiagramms visualisiert werden:

Maße der zentralen Tendenz
Die zentrale Tendenz ist der Durchschnitt einer Reihe von Zahlen. Er misst, wie eng die Zahlen in einem Datensatz um ihren Mittelwert gruppiert sind.
Drei Haupttypen der zentralen Tendenz sind Mittelwert, Median und Modus. Das gebräuchlichste Maß für die zentrale Tendenz ist das arithmetische Mittel, das berechnet wird, indem alle Werte im Datensatz addiert und diese Summe durch die Anzahl der Werte in diesem Datensatz geteilt wird.
Der Median kann auch als Alternative zur Berechnung der zentralen Tendenz verwendet werden, indem einfach der Mittelwert in einem Datensatz gefunden wird, nachdem alle Zahlen von niedrig nach hoch angeordnet wurden. Der Modus ist der häufigste Wert in einem Satz.
Die zentralen Thesen
Ordinale Daten sind komplexer als nominale Daten und werden häufig verwendet, um das Interesse zu messen. Die Likert-Skala ist ein beliebtes Beispiel für ordinale Daten.
Verwenden Sie einige der hier bereitgestellten realen Beispiele, um Ihre eigene Erhebung von Umfragedaten zu inspirieren. Erfahren Sie dabei mehr über Umfragen und wie sie beim Sammeln von Daten helfen.