
序数データ: 定義、例、収集、および分析
公開: 2023-03-24企業は、マーケティング チームがより適切な意思決定を行えるように、データ ツールへの投資を増やしています。
しかし、マーケティングには、効果的なマーケティング戦略を実施するためのデータや分析ツール以上のものが必要です。 また、収集するデータの種類と、それを分析して有意義な洞察を得る方法を理解する必要もあります。
これには、基本に戻って、主要なマーケティング データ タイプの 1 つである序数データを理解することが含まれます。 この記事では、序数データと、それがデータ駆動型のマーケティング決定にどのように役立つかについて説明します。
順序データとは
順序データは、変数が 1 から 10 までのランキングなど、順序付けられたカテゴリで編成された定量的データです。ただし、変数間に明確な間隔がなく、順序データの値が常に均等に分布しているわけではありません。
顧客満足度は序数データの一例です。 その変数は次のとおりです。
- 非常に満足
- 満足
- 中性
- 不満
- 非常に不満
順序データを使用すると、変数の度数、分布、最頻値、中央値、および範囲を計算できます。
順序データを定義すると、名義データ、間隔データ、比率データなど、他のデータ型について疑問に思うかもしれません。 それらは序数データとどう違うのですか? 簡単な定義を次に示します。
- 名義データは、順序付けされていない有限の値セットとカテゴリを持つ変数を持つデータの分類です。 名義データを使用して、雇用形態などの変数を測定します。雇用形態には、フリーランス、フルタイム、ハイブリッド ワークなど、いくつかの結果があります。
- 間隔データは、 2 つの値の間の間隔が一定でないタイプのデータです。 間隔データは、時間間隔を測定する場合や、2 つの測定値の差が変化する場合など、さまざまな方法で発生します。 間隔データを表す最も一般的な方法は、各範囲の上限と下限の列を含むテーブルを使用することです。
- 比率データは、統計分析に使用されるデータの一種です。 比率データは、それが表す値に関する情報を提供しません。 この情報は、比率データによって参照される他の情報源から取得する必要があります。 財務情報の分析によく使用されますが、他の種類のデータにも適用できます。
順序データの 5 つの例
序数データはさまざまな形式で発生します。 ここでは、序数データの例と、それをビジネス戦略と同期させてデータ管理の取り組みを改善する方法を示します。
1. 関心度
すでに製品を市場に投入している場合でも、既存の製品に新機能を導入している場合でも、市場調査を実施して質問を行い、ターゲット ユーザーの関心を測る必要があります。
市場調査では、定性的データと定量的データの両方を分析して、顧客のニーズ、購入パートナー、および顧客が購入する動機を理解します。 これらの洞察は、将来のマーケティング キャンペーンの改善に役立ちます。
たとえば、会議を定期的に主催している場合、アンケートは、会議の成果や出席者が再び会議に参加したいかどうかを知るのに役立ちます。 関心度データの例を次に示します。

出典: サーベイモンキー
あなたが尋ねる質問は、あなたの製品やサービスに対する潜在的な顧客の関心度を明らかにします。 関心のレベルは、関心がない、少し関心がある、どちらでもない、非常に関心がある、の範囲です。
2.教育レベル
このタイプの序数データは、対象視聴者の習熟度に関する洞察を提供します。
教育レベルでは、対象視聴者が高校、大学、大学院など、さまざまなレベルの正式な教育を受けているかどうかを調べることができます。 このデータは、正規の教育を受けていない場合は 1、初等教育の場合は 2、博士課程の場合は 10 など、各レベルに番号を割り当てることで収集できます。
教育レベルのデータは、採用プロセスで分析を使用して潜在的な候補者の求人応募を評価するのに役立ちます。
教育レベルのデータは、企業の成長をサポートするために将来誰を採用するか、どこに採用活動を集中すべきか、特定のポジションに適した候補者を見つけるかについて強力な予測を行うのに役立ちます。
営業チームを運営している場合、チーム メンバーの教育レベルを評価することで、彼らのキャリア開発目標をサポートする方法を知ることができます。 このようにして、パフォーマンスの高い営業チームを構築し、定着率を向上させることができます。
3. 社会経済的地位
ターゲットオーディエンスの社会経済的ステータスを理解することは、人口統計学的および心理学的プロファイルに基づいて顧客セグメントを作成および改善するのに役立ちます。
これらのセグメントは、ニーズと欲求を満たすパーソナライズされたマーケティング キャンペーンを実行する際に利用できます。 B2C ターゲット オーディエンスの社会経済的地位に関する序数データには、性別、場所、世帯収入、婚姻状況、年齢が含まれます。
一方、B2B ターゲット オーディエンスのデータには、総年間収益、ビジネスの成長段階、従業員数、市場での地位、および業種が含まれます。
4.満足度
満足度は、さまざまなブランド インタラクションに対する顧客の満足度を反映しています。 たとえば、顧客のオンボーディング プロセスや、さまざまな顧客の問題をどの程度うまく解決できるかなどです。
顧客満足度は、非常に満足、満足、不満足、または非常に不満足で表される場合があります。 満足度データは、顧客サービスと販売処理の満足度を測定して、改善すべき領域を特定するのに役立ちます。
以下は、Buffer が実施した製品/市場適合性調査の満足度データの例です。
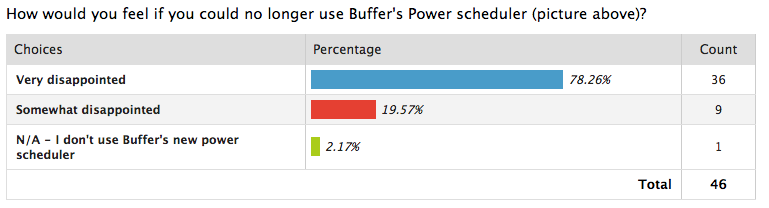
ソース:バッファ
このデータを使用して、同社は Buffer の Power スケジューラが顧客にとってどれほど有用であるかを知ることができました。つまり、この製品は顧客にとって適切であったということです。
5. 比較
これには、2 つ以上のデータ ポイント間の類似点または相違点を明らかにする質問をすることが含まれます。 類似点または相違点を特定すると、どの特性が類似しているか、どの特性が異なるか、どの程度異なるかまたは類似しているかを知ることができます。
たとえば、2021 年と 2022 年の収益実績を比較するとします。この比較では、各年の収益について、大幅に少ない、ほぼ同じ、多い、大幅に多いなどの結果が得られます。
これにより、マクロ経済と業界の傾向を把握し、予算編成プロセスに合わせて戦略を調整して支出を管理できます。 これをさらに進めて業界の傾向を比較し、レポートを作成したり、ソート リーダーシップのコンテンツを書いたりして、ブランドの認知度を高めることもできます。
序数データの収集方法
誰かに満足度を 1 から 5 のスケールでランク付けするように依頼した場合、その回答は序数になります。 このデータは、調査ソフトウェアを使用して調査またはリッカート尺度を通じて収集できます。
調査は、序数データを収集するための最も古い方法の 1 つです。 アンケートを使用して、製品、トピック、またはブランド、製品、またはサービスに関連する特定の問題についてのターゲット オーディエンスの感情を判断できます。 対面、電話、オンラインなど、さまざまな方法で調査できます。
しかし、アンケートでは、質問に正直に答えたくない、または質問を理解したくない人から正確なデータを収集することは困難です。 調査はまた、研究者が調査を作成、検証、分析するために多くの時間を必要とします。

リッカート尺度は、参加者に調査の各ステートメントに同意するか反対するかを尋ねる調査です。たとえば、「私は強く反対します」などです。 次に、参加者は、ステートメントに対する感情とそれに対する同意のレベルに基づいて、自分自身に答えを割り当てます。
リッカート尺度は、回答者が明確に定義された間隔 (1 ~ 7 の尺度など) で順序付けられた尺度で自分自身を評価するため、分析中の明確さを向上させます。
序数データを収集するには、暗黙的または明示的なスケールを使用して回答をランク付けする質問で調査を実行する必要があります。 たとえば、会社の Web サイトに大量のトラフィックが来る場合は、エンタープライズ Web サイト フィードバック ツールを使用して Web サイトからフィードバックを収集できます。 聞く:
「今読んだブログ記事にどの程度満足していますか?」
考えられる答えは次のとおりです。
- ハッピー
- 不幸
- 満足
- 不満
順序データで実行するテスト
序数データに対して複数の検定を実行して、2 つ以上のグループ間の差を測定できます。 これらのテストには次のものが含まれます。
- クラスカル・ウォリス検定
- マン・ホイットニーの U 検定
- ウィルコクソン順位和検定
- ムードの中央値検定
序数データは、値を最小から最大にランク付けするデータ型です。 つまり、序数データはランク付けまたは順序付けされます。
クラスカル・ウォリスのH検定
Kruskal-Wallis 検定は、3 つ以上の独立したグループの中央値を比較するために使用されるノンパラメトリック検定です。 データが正規分布しておらず、グループ間の分散が等しくない場合に使用されます。 Kruskal-Wallis 検定では、2 つの従属グループ (Web サイトの再設計の前後の写真) を比較することもできます。
マン・ホイットニーの U 検定
マン・ホイットニー検定は、2 つの独立したサンプルの中央値を比較するために使用されるノンパラメトリック検定です。 1 から 5 までの評価などの序数データがある場合、またはデータに明確なグループがない場合に使用できます。
ウィルコクソンの符号順位検定
ウィルコクソンの符号順位検定は、正規分布の有無にかかわらずデータセットに使用できるノンパラメトリック検定です。 これは、データが正規分布を持たない場合の t 検定の代替手段です。
t 検定を実行する場合、データの基になる分布は正規分布であると仮定されますが、この仮定は間違っている可能性があります。
たとえば、2 つのグループの身長差をテストする場合、一方のグループの平均身長が 180 cm で、もう一方のグループの平均身長が 170 cm だとします。 高さに大きな違いはありません。
ただし、ウィルコクソンの符号付き順位検定を使用すると、身長の通常の違いを超えて見ることができます。
ムードの中央値検定
このテストは、人々の気分が中央値付近に集まっており、ある人は他の人よりもポジティブまたはネガティブであるという前提に基づいています. ムードの中央値検定は、多くの場合、製品やサービスに関する顧客の意見など、問題やアイデアについて個人がどのように感じているかを測定します。 顧客が自社または競合他社から購入するかどうかなど、気分に基づいて行動を予測できます。
序数データの分析方法
順序データを分析するには、推論統計と記述統計の 2 つの方法があります。
記述統計は、データセットの特性を要約し、パターンを識別します。 序数データの記述統計は次のとおりです。
- 頻度分布
- 中心傾向の測定
- 範囲 (変動性の尺度)
一方、推論統計は、手元にあるデータに基づいて将来何が起こるかを予測します。 順序データを使用して、洞察を収集したり、仮説を作成したり、上記の 4 つのテストで結論を導き出すことさえできます。
Kruskal-Wallis、Mann Whitney U、および Wilcoxon の符号付き順位和検定はすべて、順序データを分析します。 これらはすべてノンパラメトリック検定です。つまり、データ分布に関する仮定に依存していません。
記述的分析
記述的分析は、すでに発生したイベントに関するデータを収集、分析、および報告します。 これは、履歴データに基づいて将来のイベントを予測する予測分析とは異なります。 記述的分析は、企業が過去のパターンを特定して将来の意思決定を改善するのに役立ちます。
記述的分析の目標は、将来何が起こるかを予測することではなく、既存のデータのパターンを見つけることです。 記述的分析は、過去の出来事間の因果関係を見つけ、これらの関係を使用して将来の出来事を予測することを目的としています。
他の分析方法とは異なり、記述的分析は、利用可能なデータをいつでも使用できます。 これにより、予測モデルや他の方法で必要な大規模なデータセットのリソースが不足している小規模企業にとって、よりアクセスしやすくなります。
グラフ
棒とグラフは、理解しやすい方法でデータを表示します。 データが大きすぎたり複雑すぎてテーブルに表示できない場合に役立ちます。 選択するグラフのタイプは、伝えたい情報の量、データの次元、対象者によって異なります。
棒グラフは、値に比例した長さの棒として情報を表示します。 これらは、データがカテゴリカルである場合、つまり特定のグループに分類される場合に使用されます。 これはコール センターの棒グラフで、平日ごとの対応時間を示しています。
出典:データパイン
聴衆が値を簡単に比較できるようにする場合に適しています。 棒グラフは、数値よりも直感的で分かりやすいです。 散布図、ヒストグラム、円グラフなど、線やその他のグラフィックスと組み合わせてバーを使用することもできます。
折れ線グラフは、データに順序付けられた値がある場合に使用されます。 これらのグラフは、線を使用して、両側が同じ目盛りの 2 つの軸上の点を結びます。 これらの線は実線または点線で、いずれかの軸上の任意の点から始まります。
線は、株式市場が日々どのように変動するか、エネルギーのコストが年々どのように変化するかなど、時間の経過に伴う変化を表しています。 折れ線グラフを使用して視覚化された 12 か月にわたる毎月のインバウンド リードの例を次に示します。

中心傾向の測定
中心傾向は、一連の数値の平均です。 これは、データセット内の数値が平均値の周りにどれだけ密集しているかを測定します。
中心傾向の主な 3 つのタイプは、平均値、中央値、最頻値です。 中心傾向の最も一般的な尺度は、データ セット内のすべての値を合計し、この合計をそのデータ セット内の値の数で割ることによって計算される算術平均です。
中央値は、中心傾向を計算する代わりに使用することもできます。すべての数値を低いものから高いものに並べた後、データセットの中間値を見つけるだけです。 モードは、セット内で最も頻度の高い値です。
重要ポイント
順序データは、名義データよりも複雑で、関心度を測定するためによく使用されます。 リッカート尺度は、一般的な順序データの例です。
ここに記載されている実際の例のいくつかを使用して、独自の調査データ収集を刺激してください。 その間、ポーリングとそれがデータ収集にどのように役立つかについて学びます。